目录
- 前言
- 一、什么是ElasticSearch?
- 二、安装
- 三、核心概念
-
- 3.1 kibana与es的简单交互
- 3.2 高级查询
-
- 3.2.1 查询所有[match_all]
- 3.2.2 关键词查询(term)
- 3.2.3 范围查询[range]
- 3.2.4 前缀查询[prefix]
- 3.2.5 通配符查询[wildcard]
- 3.2.6 多id查询[ids]
- 3.2.7 模糊查询[fuzzy]
- 3.2.8 布尔查询[bool]
- 3.2.9 多字段查询[multi_match]
- 3.2.10 默认字段分词查询[query_string]
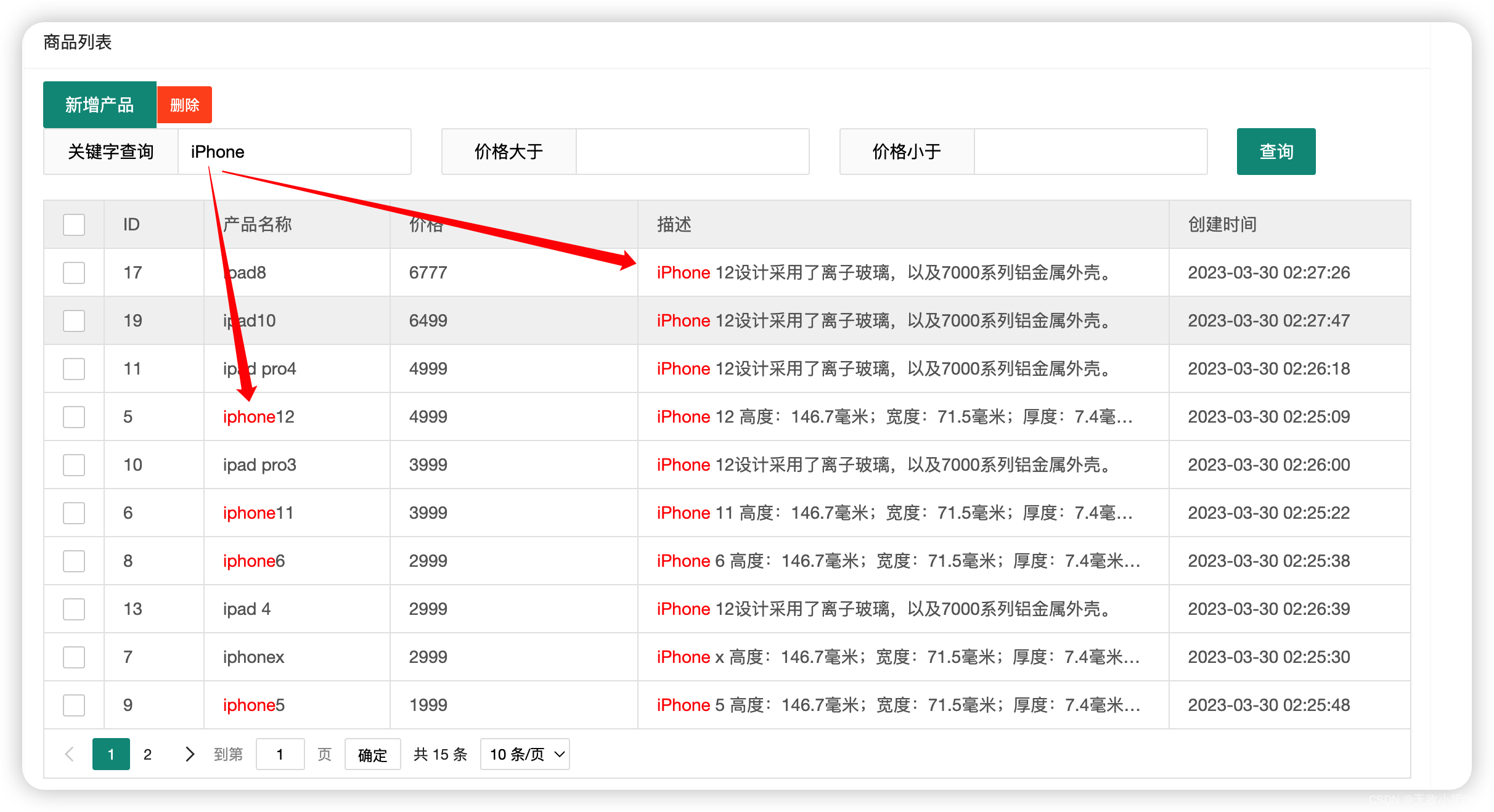
- 3.2.11 高亮查询[highlight]
- 3.2.12 返回指定条数[size]
- 3.2.13 分页查询[form]
- 3.2.14 指定字段排序[sort]
- 3.2.15 返回指定字段[_source]
- 3.3 索引原理
- 3.4 过滤查询「Filter Query」
- 四、整合springboot
- 总结
前言
Elasticsearch 是一个实时的分布式搜索分析引擎,它能让你以前所未有的速度和规模,去探索你的数据。
二话不说,仓库地址。
一、什么是ElasticSearch?
ElasticSearch 简称 ES ,是基于Apache Lucene构建的开源搜索引擎,是当前最流行的企业级搜索引擎。Lucene本身就可以被认为迄今为止性能最好的一款开源搜索引擎工具包,但是lucene的API相对复杂,需要深厚的搜索理论。很难集成到实际的应用中去。ES是采用java语言编写,提供了简单易用的RestFul API,开发者可以使用其简单的RestFul API,开发相关的搜索功能,从而避免lucene的复杂性。
二、安装
下载地址
https://www.elastic.co/cn/downloads/elasticsearch
2.1 docker安装es
1、创建文件夹
-p 若建立目录的上层目录目前尚未建立,则会一并建立上层目录
mkdir -p ~/es/data ~/es/plugins
授权
chmod 777 ~/es/data ~/es/plugins
2、docker启动
docker run -d --name es -p 9200:9200 -p 9300:9300 -v ~/es/data:/usr/share/elasticsearch/data -v ~/es/plugins:/usr/share/elasticsearch/plugins -e ES_JAVA_OPTS="-Xms256m -Xmx256m" -e "discovery.type=single-node" elasticsearch:7.14.0
3、访问ES
http://127.0.0.1:9200/
2.2 Kibana
Kibana Navicat是一个针对Elasticsearch mysql的开源分析及可视化平台,使用Kibana可以查询、查看并与存储在ES索引的数据进行交互操作,使用Kibana能执行高级的数据分析,并能以图表、表格和地图的形式查看数据。
下载地址
https://www.elastic.co/cn/downloads/kibana
2.2.1 docker安装Kibana
1、创建文件夹
mkdir -p ~/kibana/data ~/kibana/plugins ~/kibana/config
授权
chmod 777 ~/kibana/data ~/kibana/plugins ~/kibana/config
2、修改配置文件
vim ~/kibana/config/kibana.yml
添加如下代码段:
server.name: kibana
server.host: "0"
# 需要连接的地址
elasticsearch.hosts: [ "http://ip地址:9200" ]
xpack.monitoring.ui.container.elasticsearch.enabled: true
2、docker启动
docker run -d --privileged=true --name kibana -p 5601:5601 -v ~/kibana/config/kibana.yml:/usr/share/kibana/config/kibana.yml -v ~/kibana/data:/usr/share/kibana/data -v ~/kibana/plugins:/usr/share/kibana/plugins kibana:7.14.0
3、访问kibana
http://127.0.0.1:5601/

三、核心概念
索引
一个索引就是一个拥有几分相似特征的文档的集合。比如说,你可以有一个商品数据的索引,一个订单数据的索引,还有一个用户数据的索引。一个索引由一个名字来标识(必须全部是小写字母的)**,**并且当我们要对这个索引中的文档进行索引、搜索、更新和删除的时候,都要使用到这个名字。
映射
映射是定义一个文档和它所包含的字段如何被存储和索引的过程。在默认配置下,ES可以根据插入的数据自动地创建mapping,也可以手动创建mapping。 mapping中主要包括字段名、字段类型等
文档
文档是索引中存储的一条条数据。一条文档是一个可被索引的最小单元。ES中的文档采用了轻量级的JSON格式数据来表示。
3.1 kibana与es的简单交互
3.1.1 索引(index)
创建
语法:
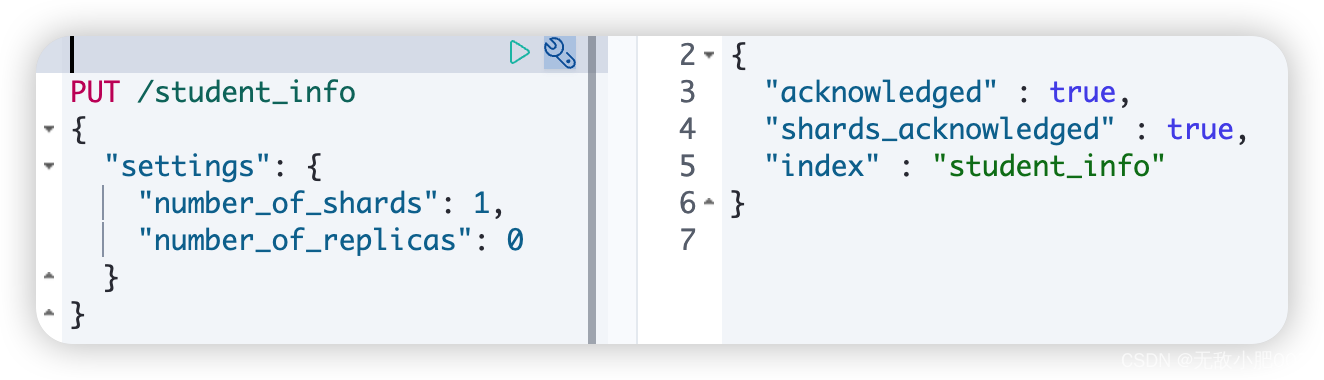
PUT /索引名 ====> PUT /student_info
默认创建索引时会为索引创建1个备份索引和一个primary索引
# 创建索引 进行索引分片配置
PUT /student_info
{
"settings": {
"number_of_shards": 1, #指定主分片的数量
"number_of_replicas": 0 #指定副本分片的数量
}
}
查询
语法:
GET /_cat/indices?v

删除
语法:
DELETE /索引名
DELETE /**代表通配符,代表所有索引

3.1.2 映射(mapping)
常见类型:
- 字符串类型: keyword 关键字 关键词 、text 一段文本
- 数字类型:integer long
- 小数类型:float double
- 布尔类型:boolean
- 日期类型:date
超多类型:参见官网文档https://www.elastic.co/guide/en/elasticsearch/reference/7.15/mapping-types.html
创建
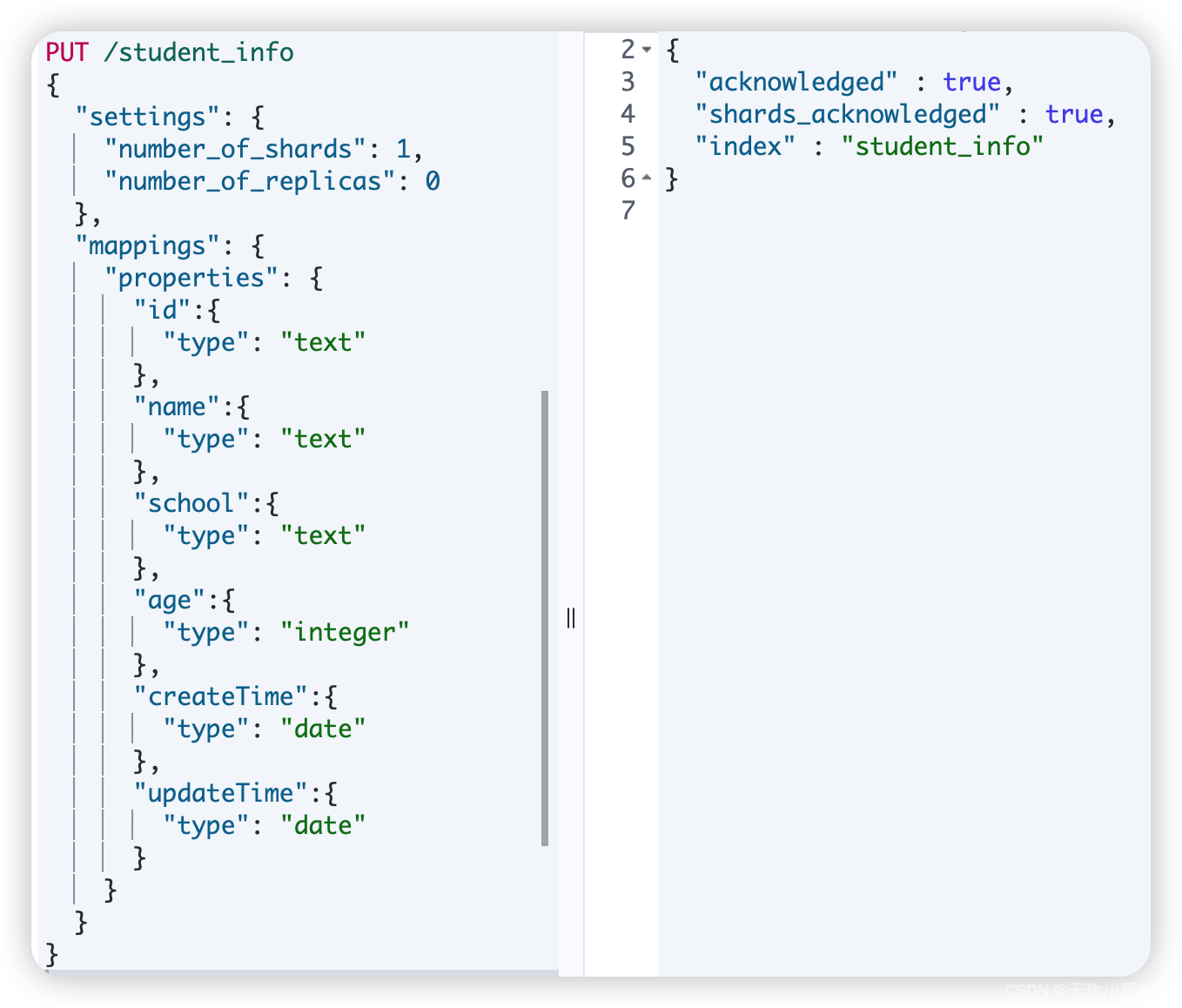
PUT /student_info
{
"settings": {
"number_of_shards": 1,
"number_of_replicas": 0
},
"mappings": {
"properties": {
"id":{
"type": "text"
},
"name":{
"type": "text"
},
"school":{
"type": "text"
},
"age":{
"type": "integer"
},
"createTime":{
"type": "date"
},
"updateTime":{
"type": "date"
}
}
}
}
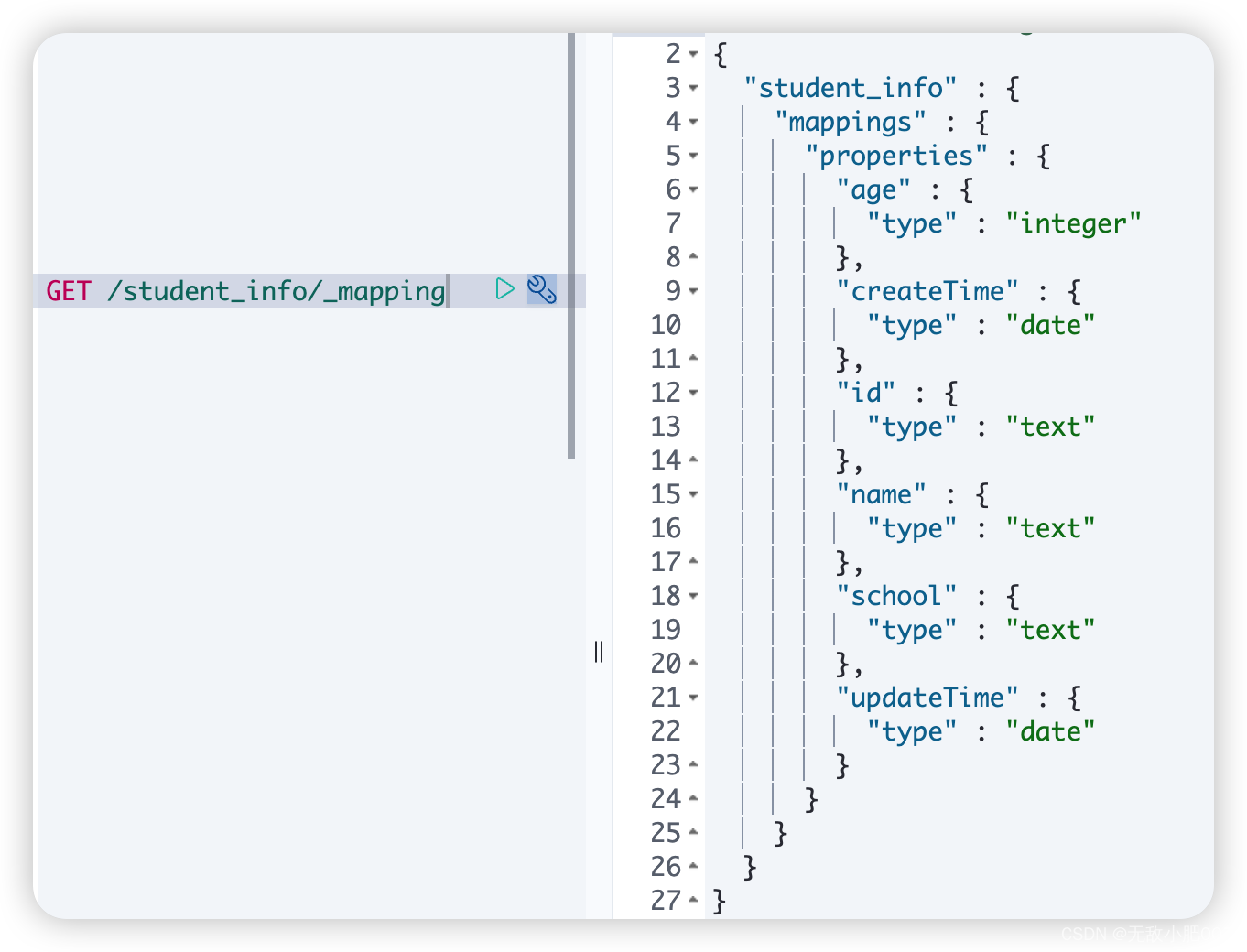
查询-查看某个索引的映射
语法:
GET /索引名/_mapping
3.1.3 文档(document)
添加文档
语法:
POST /索引名/_doc/自动生成文档id
语法:POST /索引名/_doc/文档id指定生成文档id=1默认ID由20个字节的随机UUID(通用唯一识别码)组成
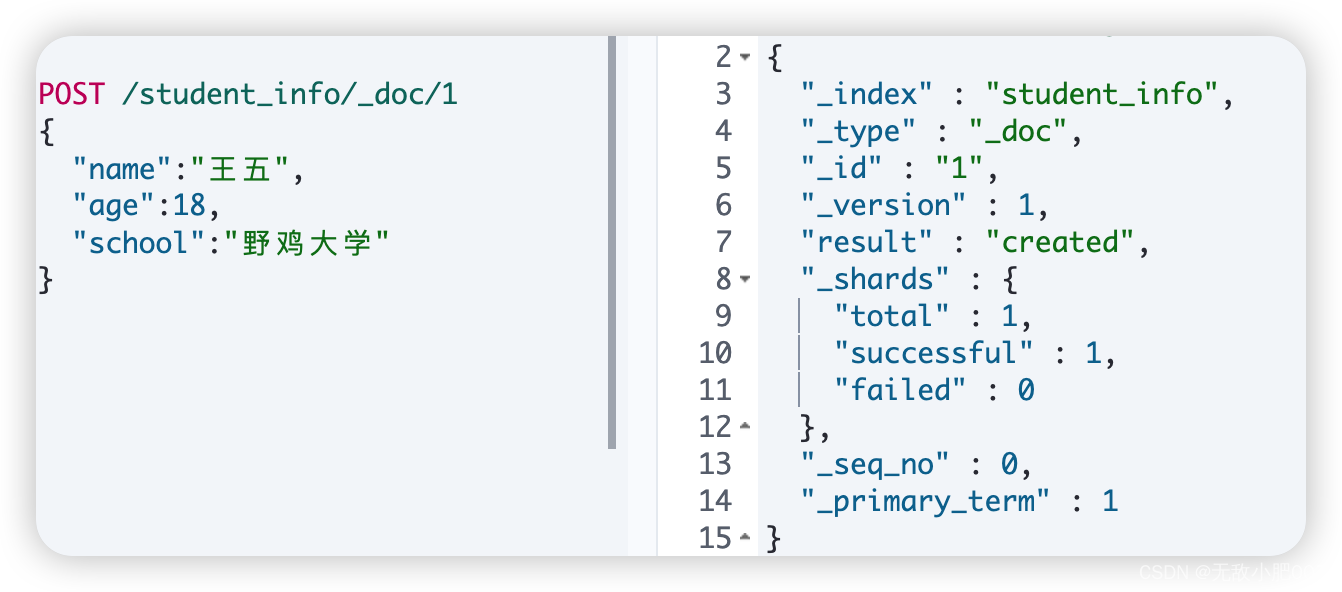

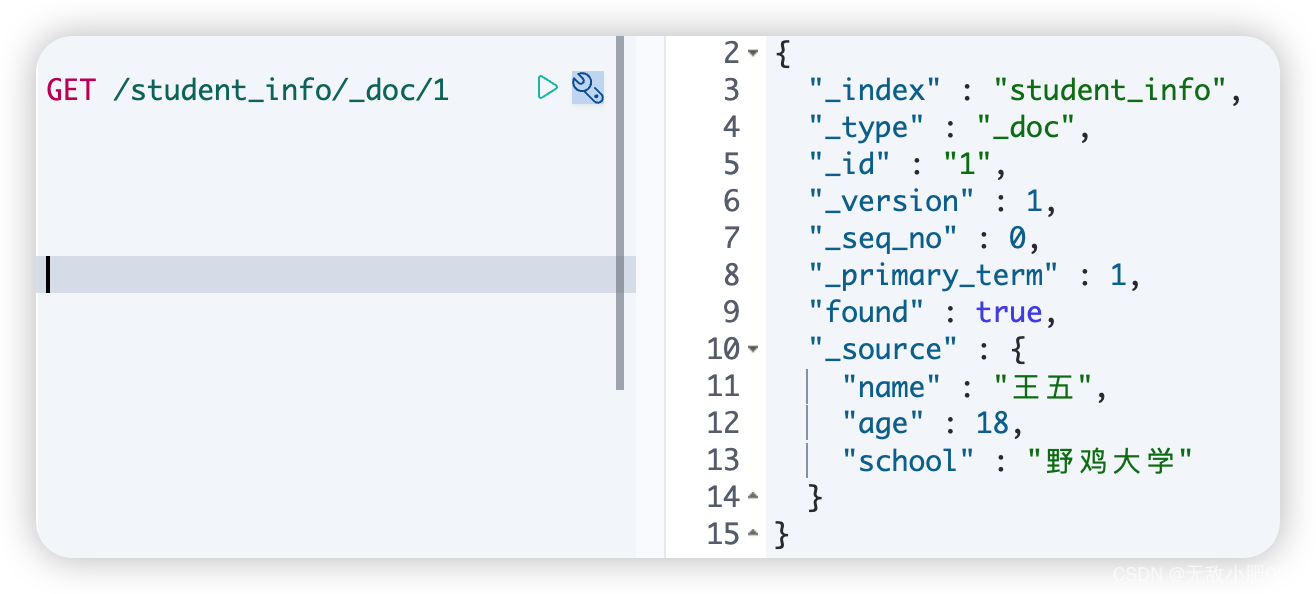
查询文档:
语法:
GET /索引名/_doc/文档id
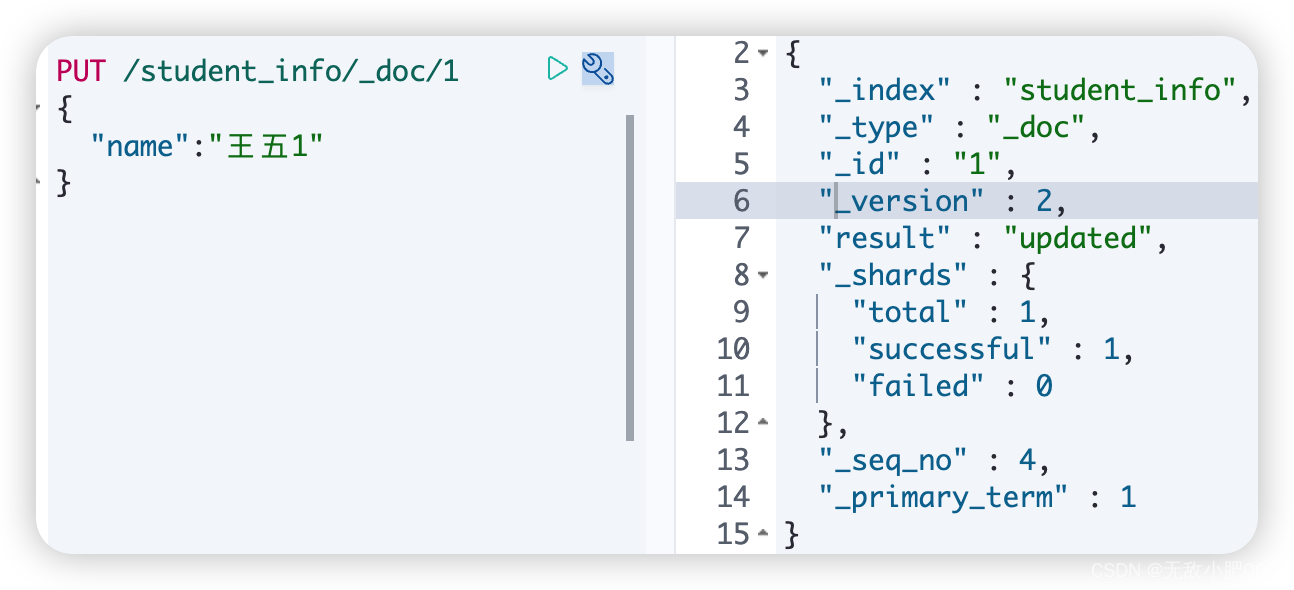
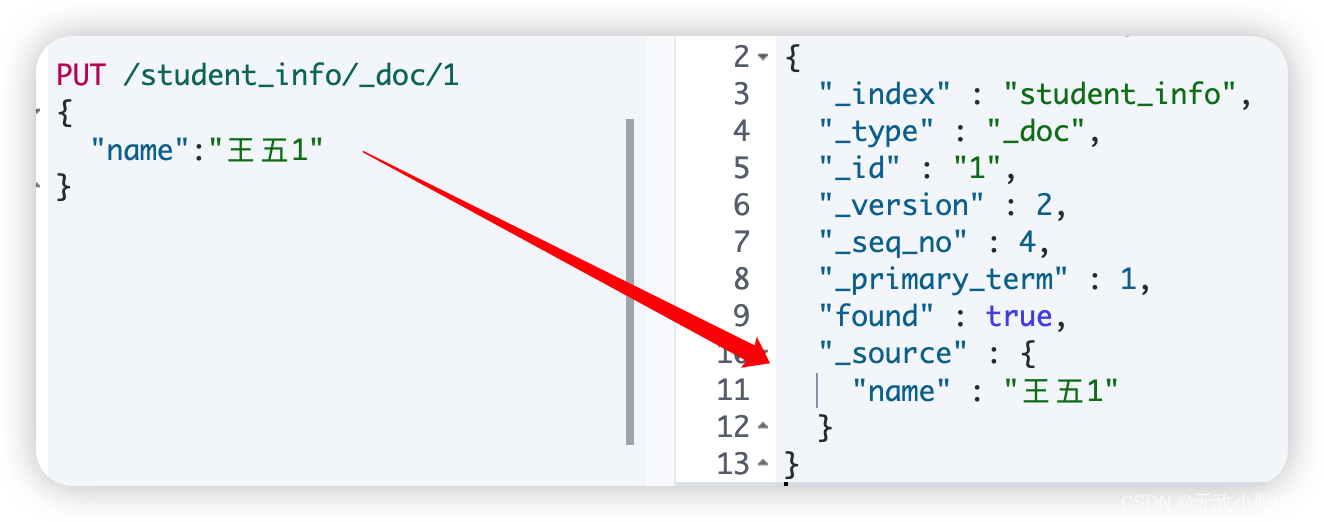
更新文档:
语法1:
PUT /索引名/_doc/文档id { "属性名":"属性值" }
说明: 这种更新方式是先删除原始文档,在将更新文档以新的内容插入。语法2:
POST /索引名/_doc/文档id/_update {"doc" : { "属性名" : "属性值" }}
说明: 这种方式是将数据原始内容保存,再更新。
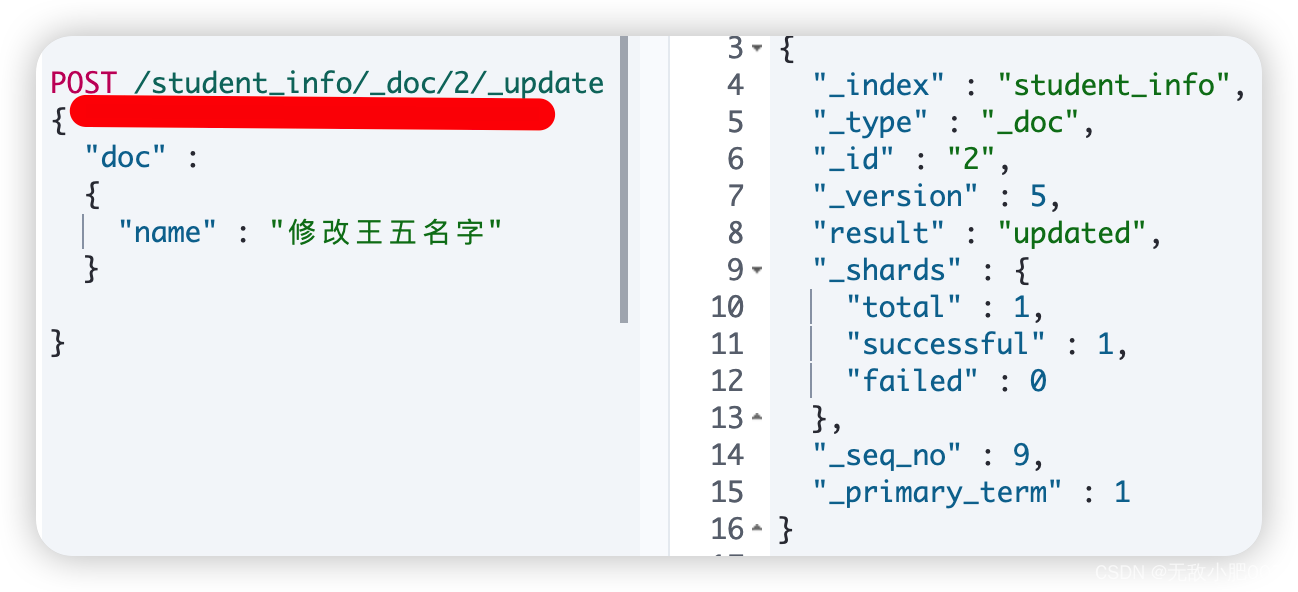
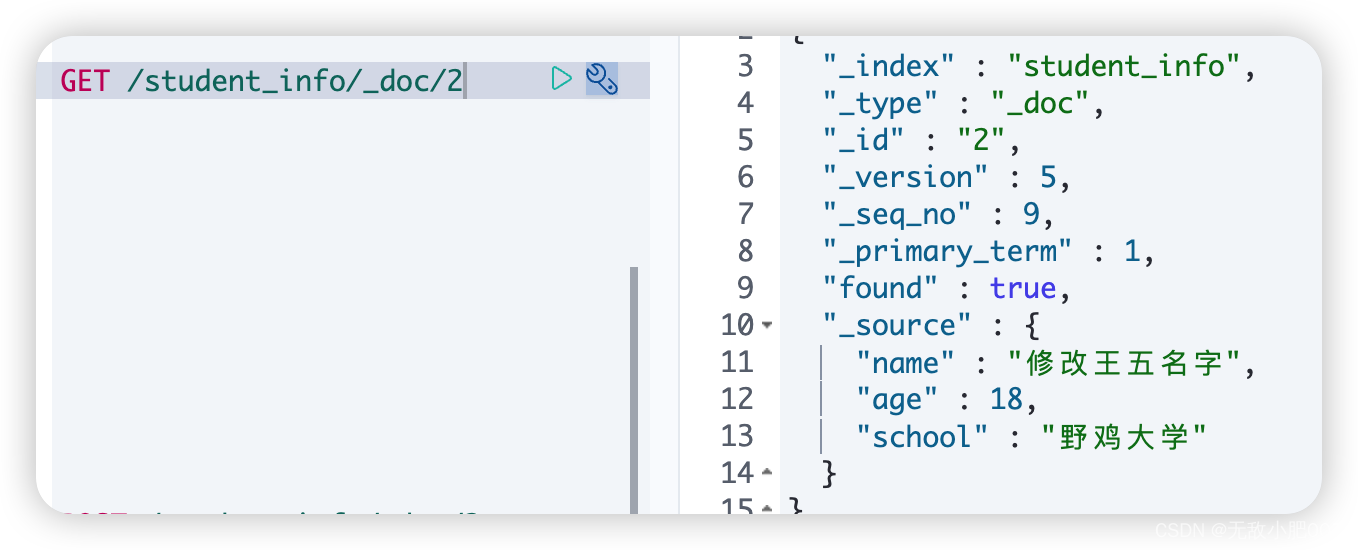
删除文档:
语法:
DELETE /索引名/_doc/文档id
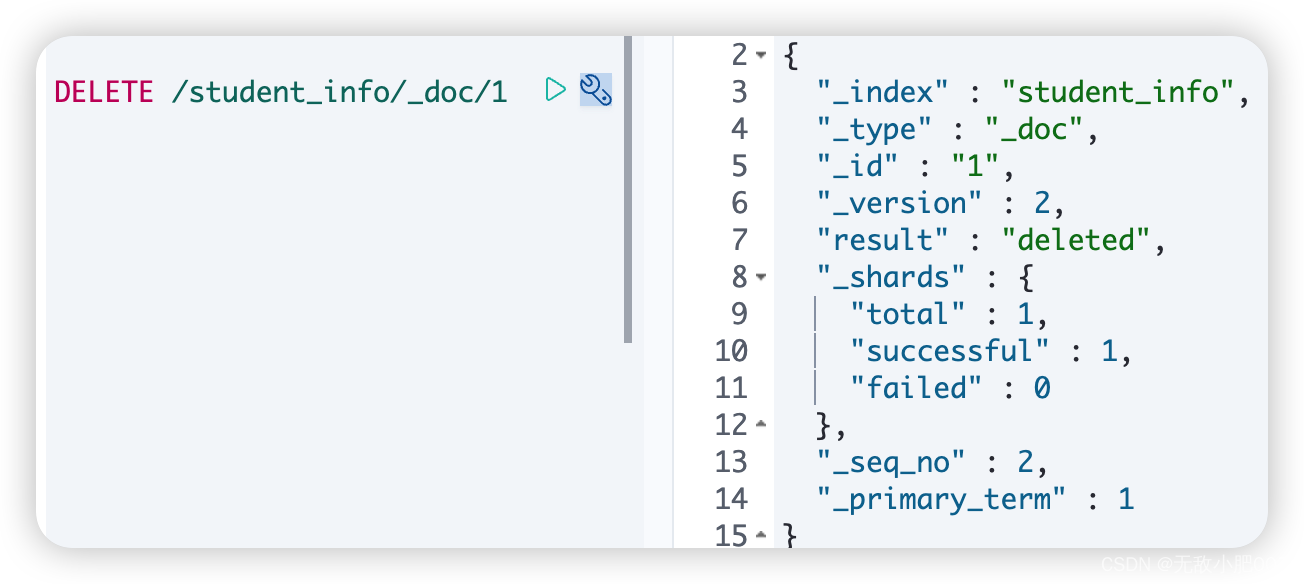
批量操作
-批量操作增删改
# 批量操作增删改
POST /student_info/_doc/_bulk
{
"create": {
"_index": "student_info",
"_type": "_doc",
"_id": "8"
}
}
{
"id": "8",
"nickname": "王者荣耀"
}
{
"update": {
"_id": "7"
}
}
{
"doc": {
"nickname": "赵琪1"
}
}
{
"delete": {
"_id": "5"
}
}
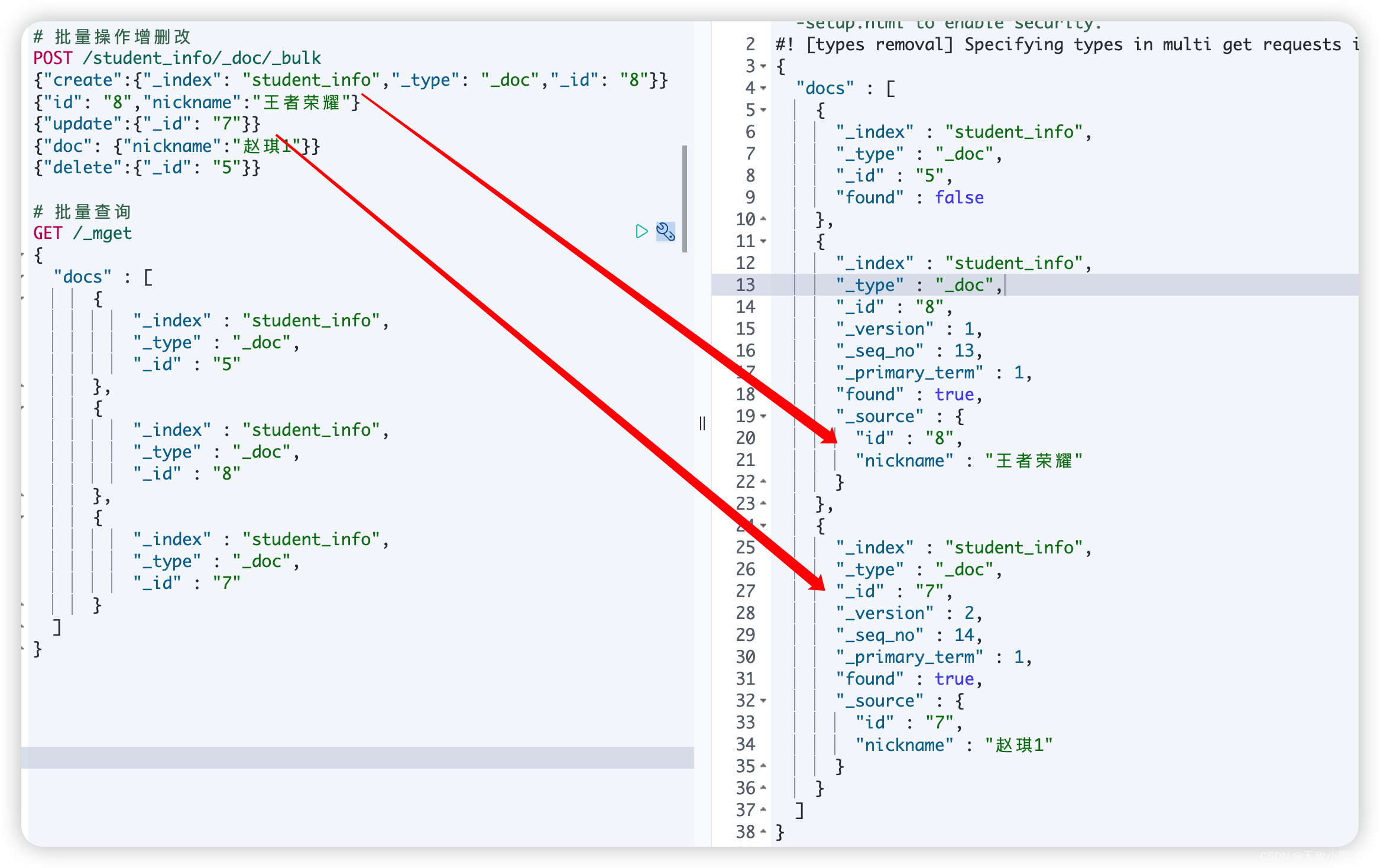
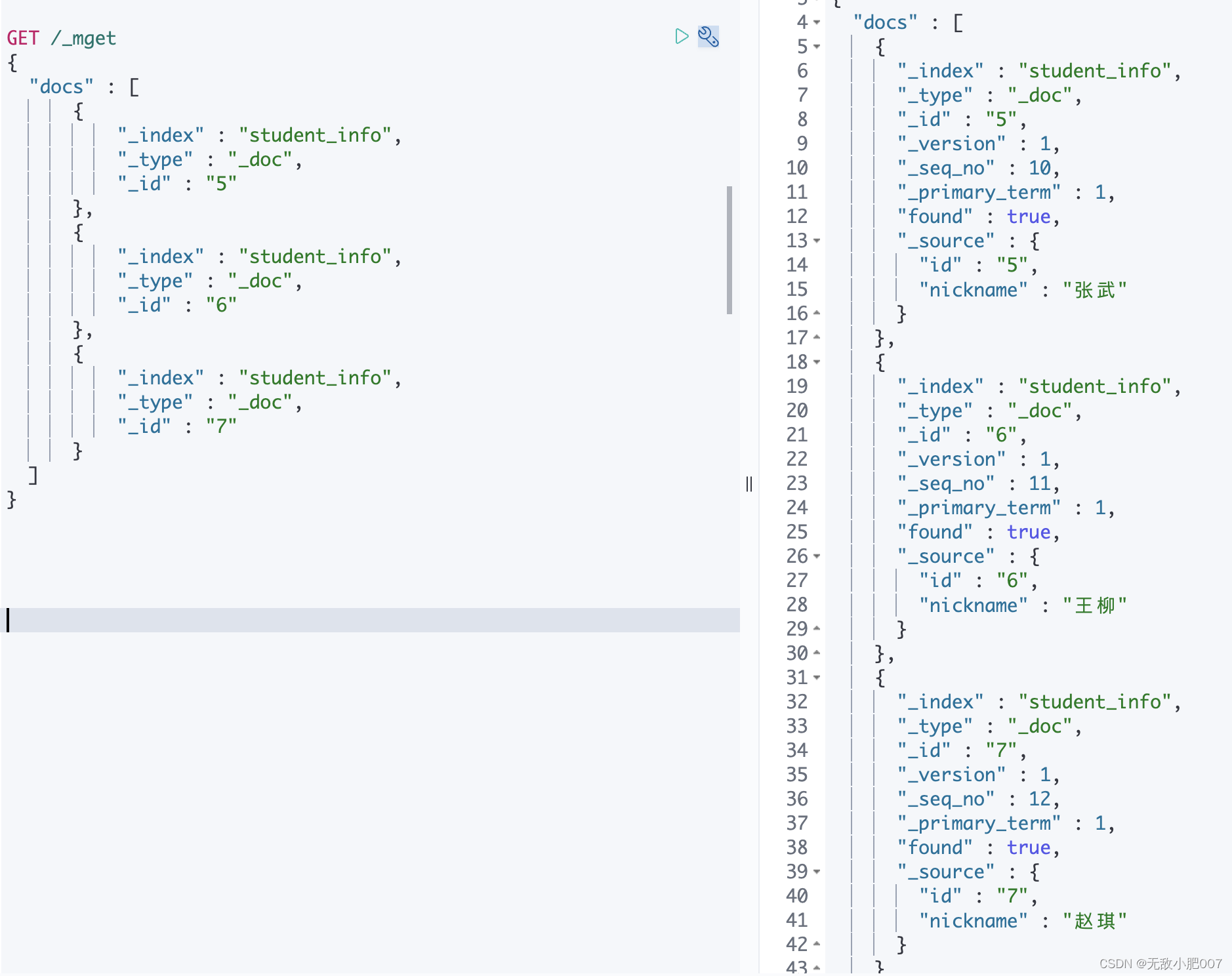
-批量获取
GET /_mget
{
"docs" : [
{
"_index" : "student_info",
"_type" : "_doc",
"_id" : "5"
},
{
"_index" : "student_info",
"_type" : "_doc",
"_id" : "6"
},
{
"_index" : "student_info",
"_type" : "_doc",
"_id" : "7"
}
]
}
3.2 高级查询
ES中提供了一种强大的检索数据方式,这种检索方式称之为Query DSL ,Query DSL是利用Rest API传递JSON格式的请求体(Request Body)数据与ES进行交互,这种方式的丰富查询语法让ES检索变得更强大,更简洁。
测试数据
# 1.创建索引 映射
PUT /products/
{
"mappings": {
"properties": {
"title":{
"type": "keyword"
},
"price":{
"type": "double"
},
"created_at":{
"type":"date"
},
"description":{
"type":"text"
}
}
}
}
# 2.测试数据
PUT /products/_doc/_bulk
{
"index":{
}}
{
"title":"iphone12 pro","price":8999,"created_at":"2020-10-23","description":"iPhone 12 Pro采用超瓷晶面板和亚光质感玻璃背板,搭配不锈钢边框,有银色、石墨色、金色、海蓝色四种颜色。宽度:71.5毫米,高度:146.7毫米,厚度:7.4毫米,重量:187克"}
{
"index":{
}}
{
"title":"iphone12","price":4999,"created_at":"2020-10-23","description":"iPhone 12 高度:146.7毫米;宽度:71.5毫米;厚度:7.4毫米;重量:162克(5.73盎司) [5] 。iPhone 12设计采用了离子玻璃,以及7000系列铝金属外壳。"}
{
"index":{
}}
{
"title":"iphone13","price":6000,"created_at":"2021-09-15","description":"iPhone 13屏幕采用6.1英寸OLED屏幕;高度约146.7毫米,宽度约71.5毫米,厚度约7.65毫米,重量约173克。"}
{
"index":{
}}
{
"title":"iphone13 pro","price":8999,"created_at":"2021-09-15","description":"iPhone 13Pro搭载A15 Bionic芯片,拥有四种配色,支持5G。有128G、256G、512G、1T可选,售价为999美元起。"}
3.2.1 查询所有[match_all]
match_all关键字: 返回索引中的全部文档
GET /products/_search
{
"query": {
"match_all": {
}
}
}
3.2.2 关键词查询(term)
term 关键字: 用来使用关键词查询
GET /products/_search
{
"query": {
"term": {
"price": {
"value": 4999
}
}
}
}
3.2.3 范围查询[range]
range 关键字: 用来指定查询指定范围内的文档
GET /products/_search
{
"query": {
"range": {
"price": {
"gte": 5000,
"lte": 9999
}
}
}
}
3.2.4 前缀查询[prefix]
prefix 关键字: 用来检索含有指定前缀的关键词的相关文档
GET /products/_search
{
"query": {
"prefix": {
"title": {
"value": "iph"
}
}
}
}
3.2.5 通配符查询[wildcard]
wildcard 关键字: 通配符查询
? 用来匹配一个任意字符 * 用来匹配多个任意字符
GET /products/_search
{
"query": {
"wildcard": {
"title": {
"value": "iphone1?"
}
}
}
}
3.2.6 多id查询[ids]
ids 关键字 : 值为数组类型,用来根据一组id获取多个对应的文档
GET /products/_search
{
"query": {
"ids": {
"values": ["pAJg84YBl2A7w00GciqN","pQJg84YBl2A7w00GciqN"]
}
}
}
3.2.7 模糊查询[fuzzy]
fuzzy 关键字: 用来模糊查询含有指定关键字的文档
模糊性-官网地址
注意:fuzzy 模糊查询 最大模糊错误 必须在0-2之间
- 搜索关键词长度为 2 不允许存在模糊
- 搜索关键词长度为3-5 允许一次模糊
- 搜索关键词长度大于5 允许最大2模糊
GET /products/_search
{
"query": {
"fuzzy": {
"description": "phone"
}
}
}
3.2.8 布尔查询[bool]
bool 关键字: 用来组合多个条件实现复杂查询
1、must: 相当于&& 同时成立
2、should: 相当于|| 成立一个就行
3、must_not: 相当于! 不能满足任何一个
GET /products/_search
{
"query": {
"bool": {
"should": [
{
"term": {
"title": {
"value": "iphone12"
}
}
},
{
"term": {
"price": {
"value": 8999
}
}
}
]
}
}
}
3.2.9 多字段查询[multi_match]
注意: 将查询条件分词之后进行查询该字段 如果该字段不分词就会将查询条件作为整体进行查询。
GET /products/_search
{
"query": {
"multi_match": {
"query": "iphone13 OLED屏幕",
"fields": ["title","description"]
}
}
}
3.2.10 默认字段分词查询[query_string]
GET /products/_search
{
"query": {
"query_string": {
"default_field": "description",
"query": "大屏幕银色边"
}
}
}
3.2.11 高亮查询[highlight]
highlight 关键字: 可以让符合条件的文档中的关键词高亮
1、自定义高亮html标签:
----在highlight中使用pre_tags和post_tags
2、 多字段高亮
----使用require_field_match开启多字段高亮
GET /products/_search
{
"query": {
"term": {
"description": {
"value": "iphone"
}
}
},
"highlight": {
"require_field_match": "false",
"post_tags": ["</span>"],
"pre_tags": ["<span style='color:red'>"],
"fields": {
"*":{
}
}
}
}
3.2.12 返回指定条数[size]
size 关键字: 指定查询结果中返回指定条数。 默认返回值10条
GET /products/_search
{
"query": {
"match_all": {
}
},
"size": 5
}
3.2.13 分页查询[form]
from 关键字: 用来指定起始返回位置,和size关键字连用可实现分页效果
GET /products/_search
{
"query": {
"match_all": {
}
},
"size": 5,
"from": 0
}
3.2.14 指定字段排序[sort]
GET /products/_search
{
"query": {
"match_all": {
}
},
"sort": [
{
"price": {
"order": "desc"
}
}
]
}
3.2.15 返回指定字段[_source]
_source 关键字: 是一个数组,在数组中用来指定展示那些字段
GET /products/_search
{
"query": {
"match_all": {
}
},
"_source": ["title","description"]
}
3.3 索引原理
3.3.1 倒排索引
倒排索引(Inverted Index)也叫反向索引,有反向索引必有正向索引。通俗地来讲,正向索引是通过key找value,反向索引则是通过value找key。ES底层在检索时底层使用的就是倒排索引。
3.3.2 索引模型
现有索引和映射如下:
{
"products" : {
"mappings" : {
"properties" : {
"description" : {
"type" : "text"
},
"price" : {
"type" : "float"
},
"title" : {
"type" : "keyword"
}
}
}
}
}
先录入如下数据,有三个字段title、price、description等
| _id | title | price | description |
|---|---|---|---|
| 1 | 蓝月亮洗衣液 | 19.9 |
蓝月亮洗衣液很高效 |
| 2 | iphone13 | 19.9 |
很不错的手机 |
| 3 | 小浣熊干脆面 | 1.5 | 小浣熊很好吃 |
在ES中除了text类型分词,其他类型不分词,因此根据不同字段创建索引如下:
-
title字段:
term _id(文档id) 蓝月亮洗衣液 1 iphone13 2 小浣熊干脆面 3 -
price字段
term _id(文档id) 19.9 [1,2] 1.5 3 -
description字段
term _id term _id term _id 蓝 1 不 2 小 3 月 1 错 2 浣 3 亮 1 的 2 熊 3 洗 1 手 2 好 3 衣 1 机 2 吃 3 液 1 很 [1:1:9,2:1:6,3:1:6] 高 1 效 1
注意: Elasticsearch分别为每个字段都建立了一个倒排索引。因此查询时查询字段的term,就能知道文档ID,就能快速找到文档。
3.3.3 分词器
内置分词器
standardAnalyzer - 默认分词器,英文按单词词切分,并小写处理simpleAnalyzer - 按照单词切分(符号被过滤), 小写处理stopAnalyzer - 小写处理,停用词过滤(the,a,is)whitespaceAnalyzer - 按照空格切分,不转小写keywordAnalyzer - 不分词,直接将输入当作输出
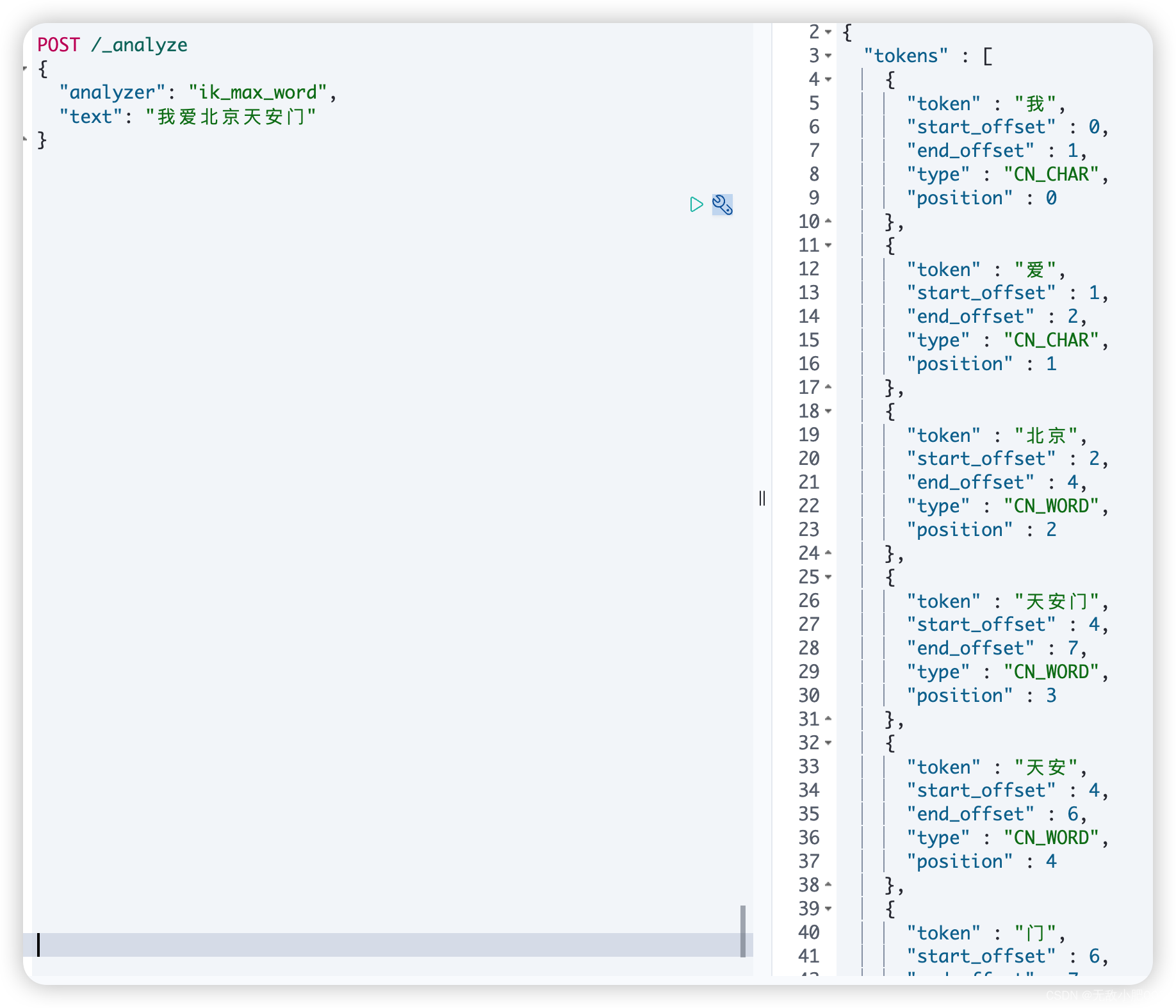
POST /_analyze
{
"analyzer": "standard",
"text": "this is a , good Man 中华人民共和国"
}
3.3.3.2 创建索引设置分词
PUT /索引名
{
"settings": {
},
"mappings": {
"properties": {
"title":{
"type": "text",
"analyzer": "standard" //显式指定分词器
}
}
}
}
3.3.3.3 中文分词器
在ES中支持中文分词器非常多 如 smartCN、IK 等,推荐的就是 IK分词器。
安装IK分词器
开源地址 - Ik分词器-github
开源地址 - Ik分词器-gitee
注意IK分词器的版本要你安装ES的版本一致注意Docker 容器运行 ES 安装插件目录为 /usr/share/elasticsearch/plugins注意如果下载是maven结构,需要maven打包用target下的jar文件移到plugin下
注意仓库下方有使用步骤- 正确的目录
# 1. 下载对应版本
wget https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.14.0/elasticsearch-analysis-ik-7.14.0.zip
# 2. 解压 #先使用yum install -y unzip
unzip elasticsearch-analysis-ik-7.14.0.zip
# 3. 移动解压文件到es的挂载目录下
如:~/es/plugins
# 4. 重启es生效
# 5. 本地安装ik配置目录为
- es安装目录中/plugins/analysis-ik/config/IKAnalyzer.cfg.xml
IK使用
IK有两种颗粒度的拆分:
ik_smart: 会做最粗粒度的拆分
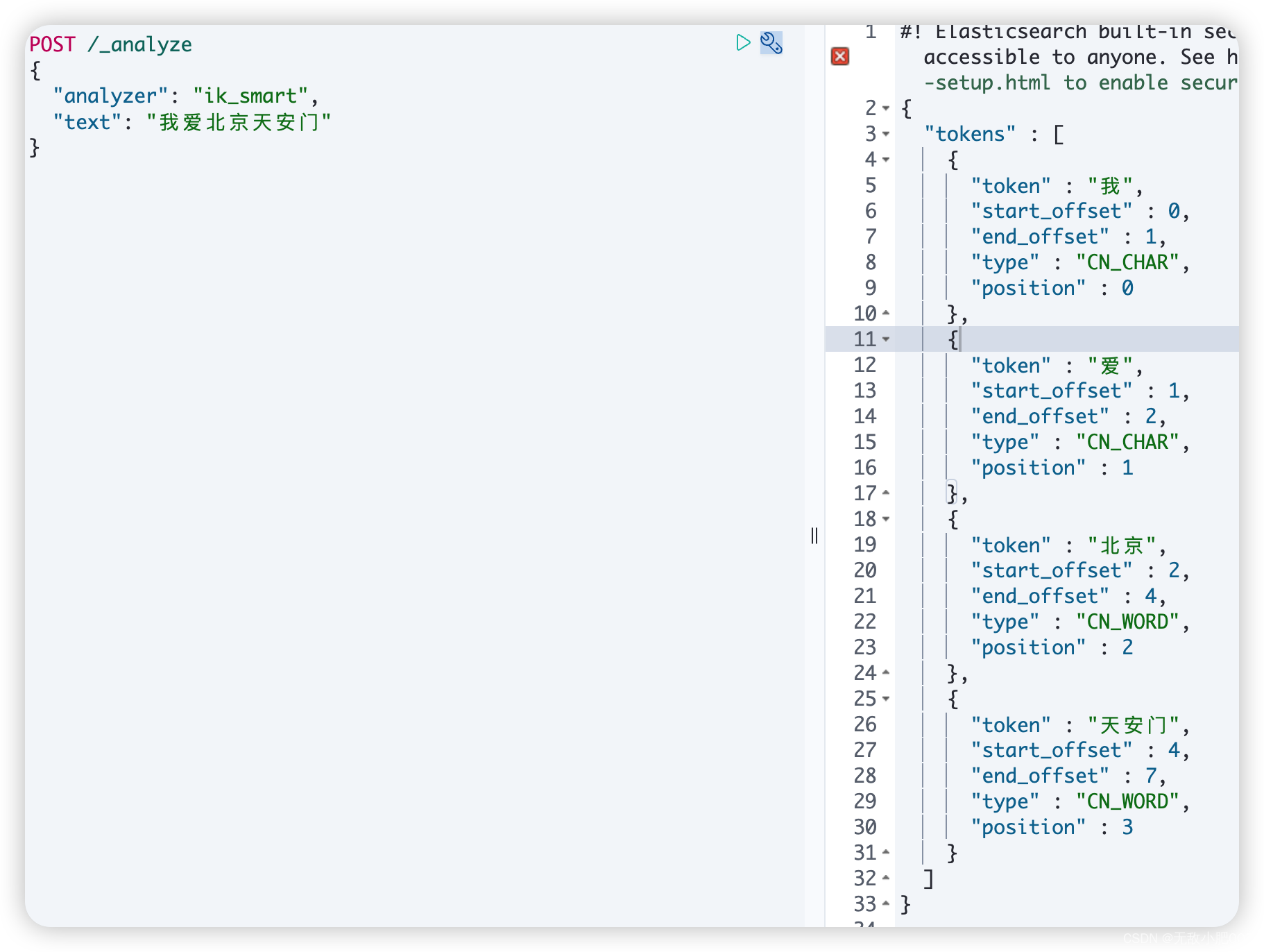
ik_max_word: 会将文本做最细粒度的拆分
扩展词、停用词配置
IK支持自定义扩展词典和停用词典
扩展词典有些词并不是关键词,但是也希望被ES用来作为检索的关键词,可以将这些词加入扩展词典。停用词典有些词是关键词,但是出于业务场景不想使用这些关键词被检索到,可以将这些词放入停用词典。
定义扩展词典和停用词典可以修改IK分词器中config目录中IKAnalyzer.cfg.xml这个文件。
1. 修改vim IKAnalyzer.cfg.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">ext_dict.dic</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords">ext_stopword.dic</entry>
</properties>
2. 在ik分词器目录下config目录中创建ext_dict.dic文件 编码一定要为UTF-8才能生效
vim ext_dict.dic 加入扩展词即可
3. 在ik分词器目录下config目录中创建ext_stopword.dic文件
vim ext_stopword.dic 加入停用词即可
4.重启es生效
3.4 过滤查询「Filter Query」
ES中的查询操作分为2种: 查询(query)和过滤(filter)。query查询默认会计算每个返回文档的得分,然后根据得分排序。而过滤(filter)只会筛选出符合的文档,并不计算 得分,而且它可以缓存文档 。单从性能考虑,过滤比查询更快。 过滤适合在大范围筛选数据,而查询则适合精确匹配数据。一般应用时, 应先使用过滤操作过滤数据, 然后使用查询匹配数据。
使用
GET /products/_search
{
"query": {
"bool": {
"must": [
{
"match_all": {
}} //查询条件
],
"filter": {
....} //过滤条件
}
}
注意:- 在执行 filter 和 query 时,先执行 filter 在执行 query
- Elasticsearch会自动缓存经常使用的过滤器,以加快性能。
类型
常见过滤类型有: term 、 terms 、ranage、exists、ids等filter。
term 、 terms 过滤器(条件)
# 使用term过滤器
GET /products/_search
{
"query": {
"bool": {
"must": [{
"match_all": {
}}],
"filter": {
"term": {
"description":"iphone"
}
}
}
}
}
#使用terms过滤器
GET /products/_search
{
"query": {
"bool": {
"must": [{
"match_all": {
}}],
"filter": {
"terms": {
"description": [
"13",
"宽度"
]
}
}
}
}
}
ranage 过滤器(范围)
GET /products/_search
{
"query": {
"bool": {
"must": [{
"match_all": {
}}],
"filter": {
"range": {
"price": {
"gte": 1000,
"lte": 6666
}
}
}
}
}
}
exists 过滤器(存在)
过滤指定字段为null值的文档,只找特定字段有值的文档
GET /products/_search
{
"query": {
"bool": {
"must": [{
"match_all": {
}}],
"filter": {
"exists": {
"field": "description"
}
}
}
}
}
ids 过滤器
过滤含有指定字段的索引记录
GET /products/_search
{
"query": {
"bool": {
"must": [{
"match_all": {
}}],
"filter": {
"ids": {
"values": ["SsAW94YB8GbnoR-aVwio","TMAW94YB8GbnoR-aVwiw"]
}
}
}
}
}

四、整合springboot
4.1 引入依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
4.2 配置客户端
@Configuration
public class RestClientConfig extends AbstractElasticsearchConfiguration {
@Override
@Bean
public RestHighLevelClient elasticsearchClient() {
final ClientConfiguration clientConfiguration = ClientConfiguration.builder()
.connectedTo("172.16.91.10:9200")
.build();
return RestClients.create(clientConfiguration).rest();
}
}
4.3 客户端对象
- ElasticsearchOperations
RestHighLevelClient推荐
相关注解
@Document(indexName = "es_product")//创建索引的名称
public class ESProduct {
@Id //@Id 用在属性上 作用:将对象id字段与ES中文档的_id对应
@Field(type = FieldType.Text)
private String id;
@Field(type=FieldType.Text,analyzer="ik_max_word") //type: 用来指定字段类型,analyzer:指定分词器
private String title;
@Field(type = FieldType.Double)
private Double price;
@Field(type=FieldType.Text,analyzer="ik_max_word")
private String description;
//格式化时间日期
@Field( type = FieldType.Date,format = DateFormat.custom, pattern = "yyyy-MM-dd HH:mm:ss")
@JsonFormat(shape = JsonFormat.Shape.STRING, pattern ="yyyy-MM-dd HH:mm:ss")
private Date createTime;
@Field( type = FieldType.Date,format = DateFormat.custom, pattern = "yyyy-MM-dd HH:mm:ss")
@JsonFormat(shape = JsonFormat.Shape.STRING, pattern ="yyyy-MM-dd HH:mm:ss")
private Date updateTime;
}
综合查询
public Map<String, Object> searchProduct(QueryReq queryReq) throws IOException {
Map<String, Object> result = new HashMap<>();
// 指定只能在哪些文档库中查询:可以添加多个且没有限制,中间用逗号隔开 --- 默认是去所有文档库中进行查询
SearchRequest searchRequest = new SearchRequest("es_product");
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
sourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS)); //设置超时时间
String[] includeFields = new String[] {
"id","title","price","description","createTime"};
String[] excludeFields = new String[] {
""};
//多字段高亮
HighlightBuilder highlightBuilder = new HighlightBuilder();
HighlightBuilder.Field highlightTitle = new HighlightBuilder.Field("title");
highlightBuilder.field(highlightTitle);
HighlightBuilder.Field highlightDescription = new HighlightBuilder.Field("description");
highlightBuilder.field(highlightDescription);
highlightBuilder.requireFieldMatch(false).preTags("<span style='color:red;'>").postTags("</span>");
sourceBuilder.fetchSource(includeFields, excludeFields);
sourceBuilder
//分页
.from((queryReq.getPage() - 1) * queryReq.getLimit())
.size(queryReq.getLimit())
.sort("price", SortOrder.DESC)
.fetchSource(includeFields, excludeFields)
.highlighter(highlightBuilder);
BoolQueryBuilder all = QueryBuilders.boolQuery()
.must(QueryBuilders.matchAllQuery());
//检索title和description
if(!StringUtils.isEmpty(queryReq.getKeyword())){
all.filter(QueryBuilders.multiMatchQuery(queryReq.getKeyword(), "description", "title"));
}
//价格
if(queryReq.getMin_price() != null){
all.filter(QueryBuilders.rangeQuery("price").gte(queryReq.getMin_price()));
}
if(queryReq.getMax_price() != null){
all.filter(QueryBuilders.rangeQuery("price").lte(queryReq.getMax_price()));
}
sourceBuilder.query(all);
searchRequest.source(sourceBuilder);
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
//处理结果
SearchHit[] hits = searchResponse.getHits().getHits();
List<ESProduct> list = new ArrayList<>();
ObjectMapper objectMapper = new ObjectMapper();
for (SearchHit hit : hits) {
ESProduct esProduct = objectMapper.readValue(hit.getSourceAsString(), ESProduct.class);
Map<String, HighlightField> highlightFields = hit.getHighlightFields();
if (highlightFields.containsKey("title")) {
esProduct.setTitle(highlightFields.get("title").getFragments()[0].toString());
}
if (highlightFields.containsKey("description")) {
esProduct.setDescription(highlightFields.get("description").getFragments()[0].toString());
}
list.add(esProduct);
}
long totalHits = searchResponse.getHits().getTotalHits().value;
result.put("data",list);
result.put("count",totalHits);
result.put("code",0);
return result;
}
聚合查询(类似 SQL 中的 group by
聚合:英文为Aggregation,是es除搜索功能外提供的针对es数据做统计分析的功能。聚合有助于根据搜索查询提供聚合数据。聚合查询是数据库中重要的功能特性,ES作为搜索引擎兼数据库,同样提供了强大的聚合分析能力。
桶聚合(Bucket Aggregation)
桶聚合是将文档分成多个桶(Bucket)进行统计的聚合方式。例如,可以对文档按照某个字段进行分组,将每个分组内的文档数量、最大值、最小值、平均值等统计结果返回。桶聚合可以嵌套使用,以实现更为复杂的统计和分析。
指标聚合(Metric Aggregation)
指标聚合是对文档集合进行数值计算的聚合方式。例如,可以对文档集合中的数值字段进行求和、求平均值、计算最大值、最小值等操作。
管道聚合(Pipeline Aggregation)
管道聚合是对聚合结果进行再处理的聚合方式。例如,可以对某个桶聚合的结果进行排序、过滤、计算百分位数、计算移动平均值等操作,以便在聚合的基础上对数据进行更深入的分析和理解。
#求和
GET /es_product/_search
{
"size":0,
"aggs":{
"aggs_name=sum_price":{
"sum":{
"field":"price"
}
}
}
}
#最大值
GET /es_product/_search
{
"size":0,
"aggs":{
"max_price":{
"max":{
"field":"price"
}
}
}
}
#最小值(Min)
GET /es_product/_search
{
"size":"0",
"aggs":{
"min_price":{
"min":{
"field":"price"
}
}
}
}
#平均值(Avg)
GET /es_product/_search
{
"size":"0",
"aggs":{
"avg_price":{
"avg":{
"field":"price"
}
}
}
}
#去重数值(cardinality)不同价格的商品件数
GET /es_product/_search
{
"size":0,
"aggs":{
"price_count":{
"cardinality": {
"field": "price"
}
}
}
}
#多值查询-最大最小值和平均值
GET /es_product/_search
{
"size":0,
"aggs":{
"max_price":{
"max":{
"field":"price"
}
},
"min_price":{
"min":{
"field":"price"
}
},
"avg_price":{
"avg":{
"field":"price"
}
}
}
}
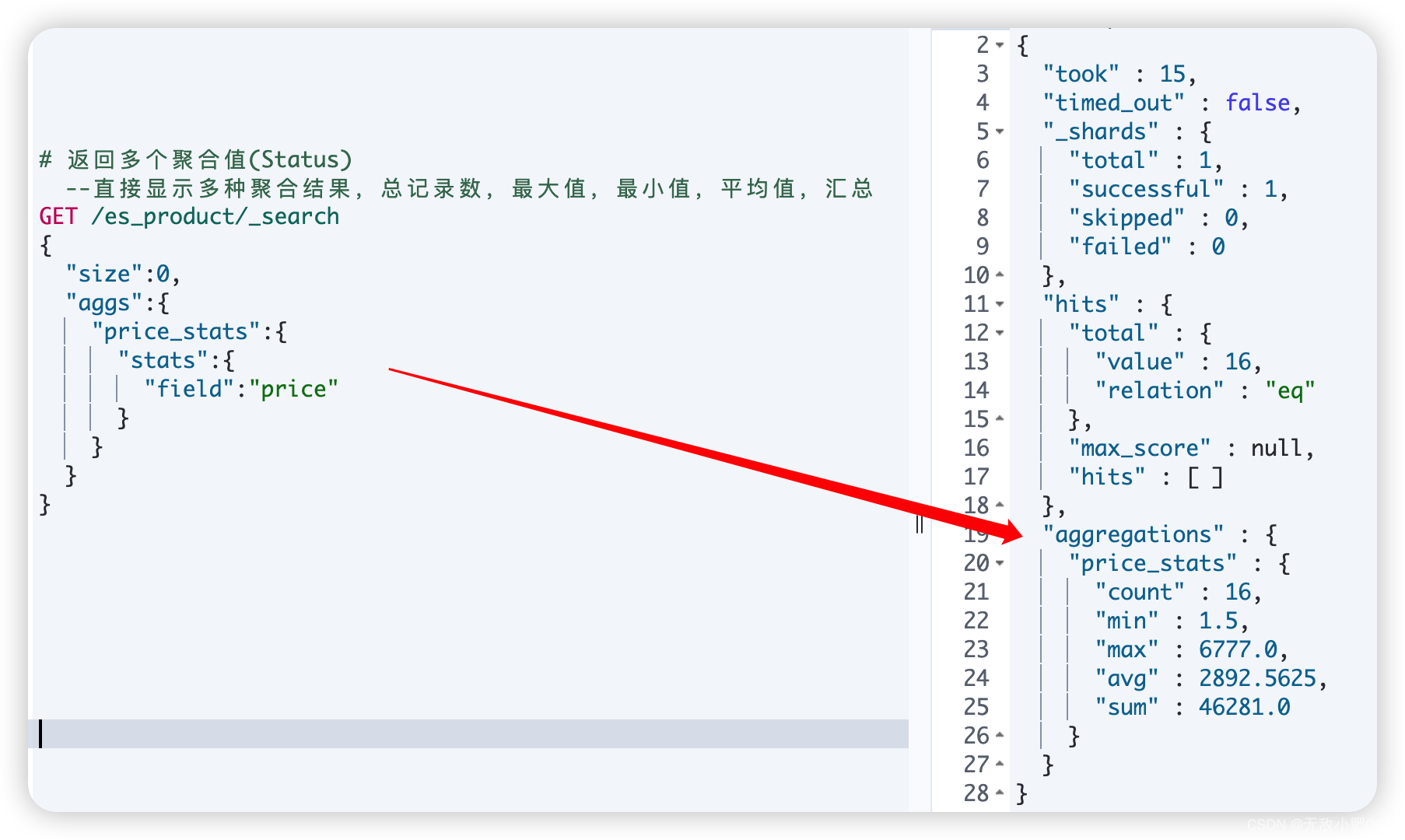
# 返回多个聚合值(Status) --直接显示多种聚合结果,总记录数,最大值,最小值,平均值,汇总
GET /es_product/_search
{
"size":0,
"aggs":{
"price_stats":{
"stats":{
"field":"price"
}
}
}
}
整合应用–返回多个聚合值
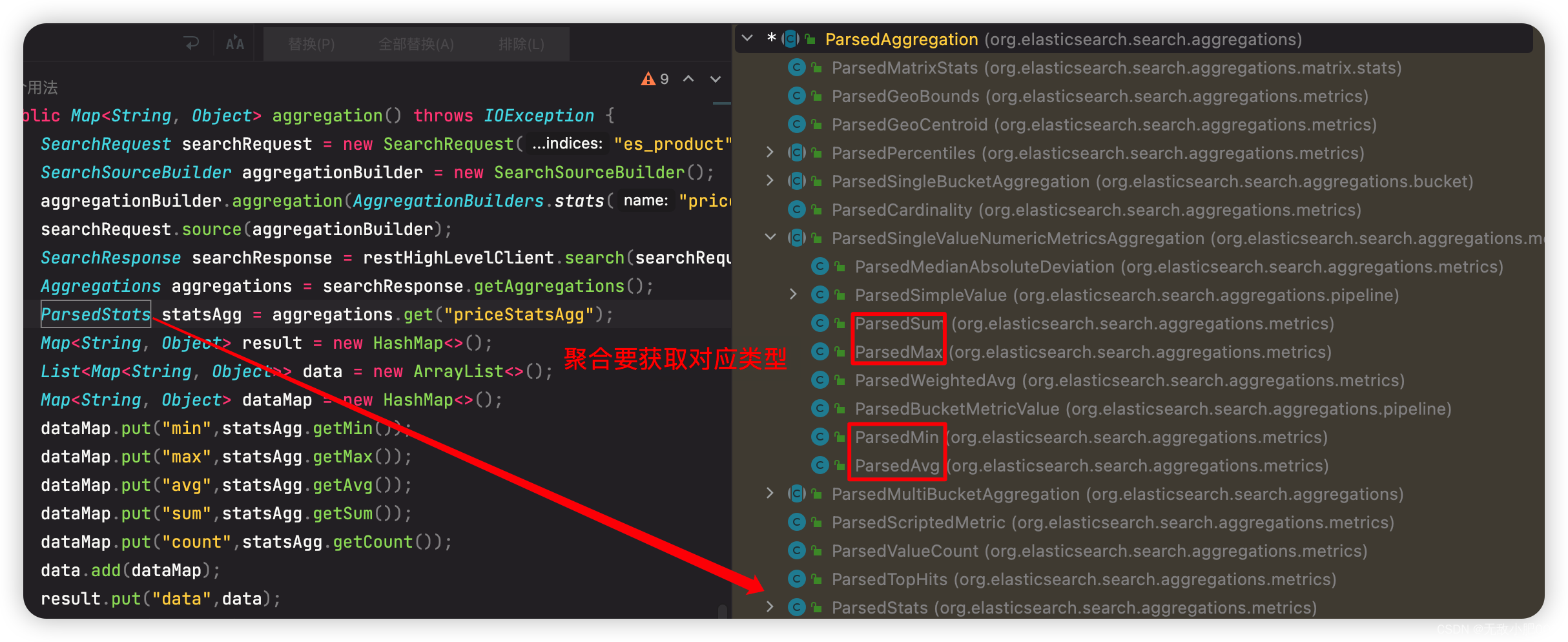
public Map<String, Object> aggregation() throws IOException {
SearchRequest searchRequest = new SearchRequest("es_product");
SearchSourceBuilder aggregationBuilder = new SearchSourceBuilder();
aggregationBuilder.aggregation(AggregationBuilders.stats("priceStatsAgg").field("price"));
searchRequest.source(aggregationBuilder);
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
Aggregations aggregations = searchResponse.getAggregations();
ParsedStats statsAgg = aggregations.get("priceStatsAgg");
Map<String, Object> result = new HashMap<>();
List<Map<String, Object>> data = new ArrayList<>();
Map<String, Object> dataMap = new HashMap<>();
//获取聚合值
dataMap.put("min",statsAgg.getMin());
dataMap.put("max",statsAgg.getMax());
dataMap.put("avg",statsAgg.getAvg());
dataMap.put("sum",statsAgg.getSum());
dataMap.put("count",statsAgg.getCount());
data.add(dataMap);
result.put("data",data);
result.put("code",0);
return result;
}
聚合和查询是同级的,可以在查询的方法里聚合,但是获取到的aggs结果取出来是要获取对应的类型,否则会出现转换错误。
仓库地址:https://gitcode.net/chendi/springboot_elasticsearch_demo
总结
Elasticsearch 是一个基于 Lucene 的分布式搜索引擎,可以实现全文搜索、数据分析、数据挖掘等多种功能。
- 索引「index」类似mysql中的database的概念
- 映射「mapping」类似mysql中的字段名对应字段类型
- 文档「document」类似mysql中的一行记录
- 分词的概念-分词器类型
- 高级查询
- 过滤查询
- 客户端对象-RestHighLevelClient常用
- 聚合查询类似mysql的groupby等函数