欠定方程组的最小范数解(超曲面和原点的距离,原点球心球面和超曲面的切点)
今天小白问了我一个问题,我觉得颇有意思,做个记录。
问题描述
小白:插入一个问题,这个切点怎么求?就是固定超平面Ax=b 怎么求它的最小二范数。
她说得不是很清楚,我再翻译一下。几何的提法是,超平面 A x = b Ax=b Ax=b 到圆心距离是多少?代数的提法是,欠定方程组 A x = b Ax=b Ax=b 的最小范数解是什么?
问题建模
我喜欢代数这个提法。重新描述一下,我们考虑
y = A x y=A x y=Ax
这里的 A ∈ R m × n A \in \mathbf{R}^{m \times n} A∈Rm×n 是个 胖矩阵,即 m < n m<n m<n。我们不妨假定 A A A 是行满秩的。
对于这个问题,我们知道这里未知量的个数比方程的个数多,也就是解是存在不唯一的。代数学知识告诉我们,它的解集是
{ x ∣ A x = y } = { x p + z ∣ z ∈ N ( A ) } \{x \mid A x=y\}=\left\{x_{p}+z \mid z \in \mathcal{N}(A)\right\} {
x∣Ax=y}={
xp+z∣z∈N(A)}
这里 x p x_p xp 是个特解。零空间的维数 N ( A ) = n − m \mathcal{N}(A)=n-m N(A)=n−m 刻画了自由度的数目。那么,我们能否选择一个 z z z ,使得 x p + z x_p+z xp+z 的二范数最小呢?
问题解答
这是个经典的计算数学问题了,如果是低于三维的情况,高中的知识很快就能解出来了。高维情况,答案也很简单,他就是
x ln = A T ( A A T ) − 1 y x_{\ln }=A^{T}\left(A A^{T}\right)^{-1} y xln=AT(AAT)−1y
因为 A 是行满秩的,所以 A A T AA^T AAT 是可逆的。怎么得到的这个解?对于
A x = b Ax = b Ax=b
我们令 x = A T x ˉ x = A^T\bar x x=ATxˉ, x ˉ \bar x xˉ 是个 m 维的。则有
x = A T x ˉ = A T ( A A T ) − 1 b . x = A^T\bar x = A^T(AA^T)^{-1}b. x=ATxˉ=AT(AAT)−1b.
事实上,这个 x ln x_{\ln} xln 就是最小范数解,它极小化了如下的优化问题,
minimize ∥ x ∥ \|x\| ∥x∥
subject to A x = y \quad A x=y Ax=y
其中, x ∈ R n x \in \mathbf{R}^{n} x∈Rn。证明如下:
假定其它解满足 A x = y A x=y Ax=y,那么 A ( x − x ln ) = 0 A\left(x-x_{\ln }\right)=0 A(x−xln)=0,且
( x − x ln ) T x ln = ( x − x ln ) T A T ( A A T ) − 1 y = ( A ( x − x ln ) ) T ( A A T ) − 1 y = 0 \begin{aligned} \left(x-x_{\ln }\right)^{T} x_{\ln } &=\left(x-x_{\ln }\right)^{T} A^{T}\left(A A^{T}\right)^{-1} y \\ &=\left(A\left(x-x_{\ln }\right)\right)^{T}\left(A A^{T}\right)^{-1} y \\ &=0 \end{aligned} (x−xln)Txln=(x−xln)TAT(AAT)−1y=(A(x−xln))T(AAT)−1y=0
也就是说, ( x − x ln ) ⊥ x ln \left(x-x_{\ln }\right) \perp x_{\ln } (x−xln)⊥xln,那么
∥ x ∥ 2 = ∥ x ln + x − x ln ∥ 2 = ∥ x ln ∥ 2 + ∥ x − x ln ∥ 2 ≥ ∥ x ln ∥ 2 \|x\|^{2}=\left\|x_{\ln }+x-x_{\ln }\right\|^{2}=\left\|x_{\ln }\right\|^{2}+\left\|x-x_{\ln }\right\|^{2} \geq\left\|x_{\ln }\right\|^{2} ∥x∥2=∥xln+x−xln∥2=∥xln∥2+∥x−xln∥2≥∥xln∥2
说明了 x ln x_{\ln} xln 是范数最小的解。
A † : = A T ( A A T ) − 1 A^{\dagger}:=A^{T}\left(A A^{T}\right)^{-1} A†:=AT(AAT)−1 叫做行满秩胖矩阵 A A A 的伪逆,实际上是 A A A 的右逆。
几何观点
画个示意图如下,
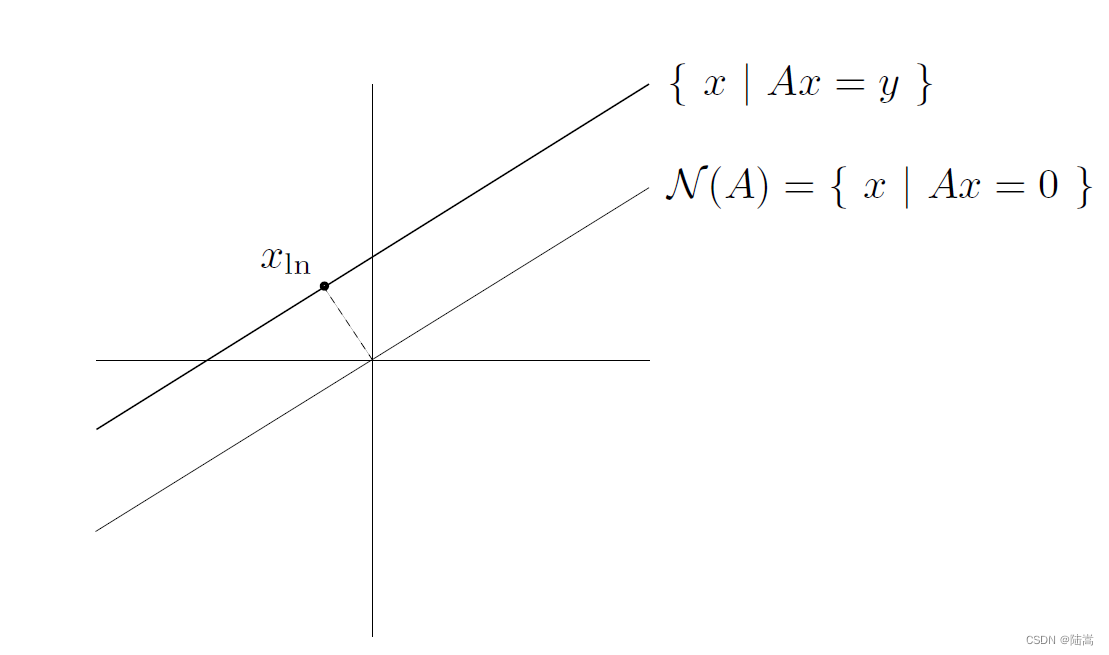
- 这个解垂直于零空间, x ln ⊥ N ( A ) x_{\ln } \perp \mathcal{N}(A) xln⊥N(A)。
- 这个解是 0 在解空间上的投影。
超定方程组的最小范数解
虽然主题是欠定方程组,但对于超定方程组
A x = b Ax = b Ax=b
我们左乘 A T A^T AT,可以得到 A T A x = A T b A^TAx=A^Tb ATAx=ATb,则我们得到胖矩阵的伪逆 A † = ( A T A ) − 1 A T A^{\dagger}=\left(A^{T} A\right)^{-1} A^{T} A†=(ATA)−1AT,它实际上是 A A A 的左逆。容易证明,它也是满足最小二乘误差相同的最小范数解。
QR 分解表示
我们找 A T A^T AT 的 QR 分解,满足 A T = Q R A^{T}=Q R AT=QR,且
- Q ∈ R n × m , Q T Q = I m Q \in \mathbf{R}^{n \times m}, Q^{T} Q=I_{m} Q∈Rn×m,QTQ=Im
- R ∈ R m × m R \in \mathbf{R}^{m \times m} R∈Rm×m 是个非奇异的上三角矩阵,那么,我们得到一个更简单的表达
x ln = A T ( A A T ) − 1 y = Q R − T y x_{\ln }=A^{T}\left(A A^{T}\right)^{-1} y=Q R^{-T} y xln=AT(AAT)−1y=QR−Ty
且 ∥ x ln ∥ = ∥ R − T y ∥ \left\|x_{\ln }\right\|=\left\|R^{-T} y\right\| ∥xln∥=∥ ∥R−Ty∥ ∥。
拉格朗日乘子法推导
除了上述的分裂法推导外,我们也可以用拉格朗日乘子法得到这个最小范数解。
最小范数解无非是求解如下优化问题,
minimize x T x \quad x^{T} x xTx
subject to A x = y A x=y Ax=y
引入拉格朗日乘子,
L ( x , λ ) = x T x + λ T ( A x − y ) L(x, \lambda)=x^{T} x+\lambda^{T}(A x-y) L(x,λ)=xTx+λT(Ax−y)
最优性条件是,
∇ x L = 2 x + A T λ = 0 , ∇ λ L = A x − y = 0 \nabla_{x} L=2 x+A^{T} \lambda=0, \quad \nabla_{\lambda} L=A x-y=0 ∇xL=2x+ATλ=0,∇λL=Ax−y=0
从第一个条件,我们可以得到 x = − A T λ / 2 x=-A^{T} \lambda / 2 x=−ATλ/2,把它代入第二个条件,我们有 λ = − 2 ( A A T ) − 1 y \lambda=-2\left(A A^{T}\right)^{-1} y λ=−2(AAT)−1y,因此
x = A T ( A A T ) − 1 y x=A^{T}\left(A A^{T}\right)^{-1} y x=AT(AAT)−1y
和正则最小二乘的关系
定义 J 1 = ∥ A x − y ∥ 2 , J 2 = ∥ x ∥ 2 J_{1}=\|A x-y\|^{2}, J_{2}=\|x\|^{2} J1=∥Ax−y∥2,J2=∥x∥2,最小化加权目标函数
J 1 + μ J 2 = ∥ A x − y ∥ 2 + μ ∥ x ∥ 2 J_{1}+\mu J_{2}=\|A x-y\|^{2}+\mu\|x\|^{2} J1+μJ2=∥Ax−y∥2+μ∥x∥2
可得
x μ = ( A T A + μ I ) − 1 A T y x_{\mu}=\left(A^{T} A+\mu I\right)^{-1} A^{T} y xμ=(ATA+μI)−1ATy
那么正则最小二乘解其实是收敛到最小范数解的,即当 μ → 0 \mu \rightarrow 0 μ→0,我们有
( A T A + μ I ) − 1 A T → A T ( A A T ) − 1 \left(A^{T} A+\mu I\right)^{-1} A^{T} \rightarrow A^{T}\left(A A^{T}\right)^{-1} (ATA+μI)−1AT→AT(AAT)−1
更一般的等式约束范数极小化框架
考虑问题
minimize ∥ A x − b ∥ \|A x-b\| ∥Ax−b∥
subject to C x = d C x=d Cx=d
这个问题包含了上述的最小范数和最小二乘问题。它等价于
minimize ( 1 / 2 ) ∥ A x − b ∥ 2 \quad(1 / 2)\|A x-b\|^{2} (1/2)∥Ax−b∥2
subject to C x = d C x=d Cx=d
拉格朗日乘子是
L ( x , λ ) = ( 1 / 2 ) ∥ A x − b ∥ 2 + λ T ( C x − d ) = ( 1 / 2 ) x T A T A x − b T A x + ( 1 / 2 ) b T b + λ T C x − λ T d \begin{aligned} L(x, \lambda) &=(1 / 2)\|A x-b\|^{2}+\lambda^{T}(C x-d) \\ &=(1 / 2) x^{T} A^{T} A x-b^{T} A x+(1 / 2) b^{T} b+\lambda^{T} C x-\lambda^{T} d \end{aligned} L(x,λ)=(1/2)∥Ax−b∥2+λT(Cx−d)=(1/2)xTATAx−bTAx+(1/2)bTb+λTCx−λTd
最优性条件是,
∇ x L = A T A x − A T b + C T λ = 0 , ∇ λ L = C x − d = 0 \nabla_{x} L=A^{T} A x-A^{T} b+C^{T} \lambda=0, \quad \nabla_{\lambda} L=C x-d=0 ∇xL=ATAx−ATb+CTλ=0,∇λL=Cx−d=0
写成块矩阵的形式,
[ A T A C T C 0 ] [ x λ ] = [ A T b d ] \left[\begin{array}{cc} A^{T} A & C^{T} \\ C & 0 \end{array}\right]\left[\begin{array}{l} x \\ \lambda \end{array}\right]=\left[\begin{array}{c} A^{T} b \\ d \end{array}\right] [ATACCT0][xλ]=[ATbd]
如果块矩阵是可逆的,我们有
[ x λ ] = [ A T A C T C 0 ] − 1 [ A T b d ] \left[\begin{array}{l} x \\ \lambda \end{array}\right]=\left[\begin{array}{cc} A^{T} A & C^{T} \\ C & 0 \end{array}\right]^{-1}\left[\begin{array}{c} A^{T} b \\ d \end{array}\right] [xλ]=[ATACCT0]−1[ATbd]
进一步,如果 A T A A^TA ATA 是可逆的,我们有更加漂亮的写法,从第一块我们可以得到
x = ( A T A ) − 1 ( A T b − C T λ ) x=\left(A^{T} A\right)^{-1}\left(A^{T} b-C^{T} \lambda\right) x=(ATA)−1(ATb−CTλ)
代入 C x = d C x=d Cx=d 可得
C ( A T A ) − 1 ( A T b − C T λ ) = d C\left(A^{T} A\right)^{-1}\left(A^{T} b-C^{T} \lambda\right)=d C(ATA)−1(ATb−CTλ)=d
因而
λ = ( C ( A T A ) − 1 C T ) − 1 ( C ( A T A ) − 1 A T b − d ) \lambda=\left(C\left(A^{T} A\right)^{-1} C^{T}\right)^{-1}\left(C\left(A^{T} A\right)^{-1} A^{T} b-d\right) λ=(C(ATA)−1CT)−1(C(ATA)−1ATb−d)
那么 x x x 就可以不太优雅地表达为
x = ( A T A ) − 1 ( A T b − C T ( C ( A T A ) − 1 C T ) − 1 ( C ( A T A ) − 1 A T b − d ) ) x=\left(A^{T} A\right)^{-1}\left(A^{T} b-C^{T}\left(C\left(A^{T} A\right)^{-1} C^{T}\right)^{-1}\left(C\left(A^{T} A\right)^{-1} A^{T} b-d\right)\right) x=(ATA)−1(ATb−CT(C(ATA)−1CT)−1(C(ATA)−1ATb−d))
复习 KKT
很多人把优化忘记了,我们复习一下 KKT 系统相关。
考虑问题
min x ∈ R n f ( x ) subject to c i ( x ) = 0 , i ∈ E = { 1 , … , m e } c i ( x ) ≥ 0 , i ∈ I = { m e + 1 , … , m } \begin{array}{ll} \min _{x \in \mathbb{R}^{n}} & f(x) \\ \text { subject to } & c_{i}(x)=0, \quad i \in \mathcal{E}=\left\{1, \ldots, m_{e}\right\} \\ & c_{i}(x) \geq 0, \quad i \in \mathcal{I}=\left\{m_{e}+1, \ldots, m\right\} \end{array} minx∈Rn subject to f(x)ci(x)=0,i∈E={
1,…,me}ci(x)≥0,i∈I={
me+1,…,m}
它的拉格朗日函数是,
L ( x , λ ) = f ( x ) − ∑ i ∈ E ∪ I λ i c i ( x ) \mathcal{L}(x, \lambda)=f(x)-\sum_{i \in \mathcal{E} \cup \mathcal{I}} \lambda_{i} c_{i}(x) L(x,λ)=f(x)−i∈E∪I∑λici(x)
那么,它的 KKT 条件可以写为
∇ x L ( x ∗ , λ ∗ ) = 0 , c i ( x ∗ ) = 0 , ∀ i ∈ E c i ( x ∗ ) ≥ 0 , ∀ i ∈ I λ i ∗ ≥ 0 , ∀ i ∈ I λ i ∗ c i ( x ∗ ) = 0 , ∀ i ∈ E ∪ I \begin{aligned} \nabla_{x} \mathcal{L}\left(x^{*}, \lambda^{*}\right) &=0, & & \\ c_{i}\left(x^{*}\right) &=0, & & \forall i \in \mathcal{E} \\ c_{i}\left(x^{*}\right) & \geq 0, & & \forall i \in \mathcal{I} \\ \lambda_{i}^{*} & \geq 0, & & \forall i \in \mathcal{I} \\ \lambda_{i}^{*} c_{i}\left(x^{*}\right) &=0, & & \forall i \in \mathcal{E} \cup \mathcal{I} \end{aligned} ∇xL(x∗,λ∗)ci(x∗)ci(x∗)λi∗λi∗ci(x∗)=0,=0,≥0,≥0,=0,∀i∈E∀i∈I∀i∈I∀i∈E∪I
当然,这些条件都有一些奇奇怪怪的名字,比如“互补性条件”之类的,可以不用管。当然,如果只有等式约束,那么其实只有前两条,很简单,也很好记。如果有不等式约束,需要看一下最后两条的互补性。
代码
no code