写在前面:根据b站 up主:正月点灯笼 学习,作为个人的学习记录。
目录
案例1:一个输入
输入x,输出x的平方的值。比如:输入2,输出4;输入6,输出36。
正常的方法编写:
def f(x):
return x * x调用:输入6
print(f(6))输出结果为36。
如何使用lambda表达式进行编写:
使用范围:所有只用一行或者一句话就能够表达出来的函数都可以使用lambda表达式。
样式:冒号的左边都是输入,然后使用冒号隔开,右边是表达式。
上面的案例使用lambda表达式进行编写:
f = lambda x: x*x
print(f(6)) # 使用,输入为6.结果应该为36
如果输入是两个参数:
案例2:两个输入
输入x,y,输出x+y的值。
平常的方法:
def g(x, y):
return x + y
print(g(3,5)) # 结果为8使用lambda表达式:
g = lambda x,y: x+y
print(g(4,5)) # 结果为9案例3:使用sort函数进行排序
将数据按照人口数进行排列。
csv表格如https://github.com/tpof314/dataset/tree/master/country所示
使用lambda函数的答案:
countries = []
# 打开本地的某个文件
file = open("D:\\PycharmProjects\\little_pro\\countries_zh.csv",'r',encoding='utf-8')
# 将文件里的数据按行读取
for line in file:
# line代表每一行的值
line = line.strip() # 将每一行中多余的空格删掉
arr = line.split(',') # 每一行根据“,”隔开 。
# 输出的arr是类似于“['http://www.wikidata.org/entity/Q148', '中华人民共和国', '亚洲', '北京市', '1409517397']”
# 将'中华人民共和国'给name,'北京市'给capt,'1409517397'给popu
name, capt, popu = arr[1], arr[3], int(arr[4])
# 将三个值再组成元组形式
countries.append((name, capt, popu))
# 使用sort函数进行排列。其中key是指用于比较的元素。
# lambda cou:cou[2]代表
# 输入的是需要排列的对象countries中的每一个元素(包含name,capt,popu),
# 每一个元素设置形参命名为cou,输出的则是cou[2]
countries.sort(key=lambda cou:cou[2])
for country in countries:
print(country)未使用lambda函数的答案:
def get_populetion(country):
return country[2]
countries = []
# 打开本地的某个文件
file = open("D:\\PycharmProjects\\little_pro\\countries_zh.csv",'r',encoding='utf-8')
# 将文件里的数据按行读取
for line in file:
# line代表每一行的值
line = line.strip() # 将每一行中多余的空格删掉
arr = line.split(',') # 每一行根据“,”隔开 。
# 输出的arr是类似于“['http://www.wikidata.org/entity/Q148', '中华人民共和国', '亚洲', '北京市', '1409517397']”
# 将'中华人民共和国'给name,'北京市'给capt,'1409517397'给popu
name, capt, popu = arr[1], arr[3], int(arr[4])
# 将三个值再组成元组形式
countries.append((name, capt, popu))
# 使用sort函数进行排列。其中key是指用于比较的元素。
# 这里直接指向get_populetion方法
countries.sort(key=get_populetion)
for country in countries:
print(country)结果都是:
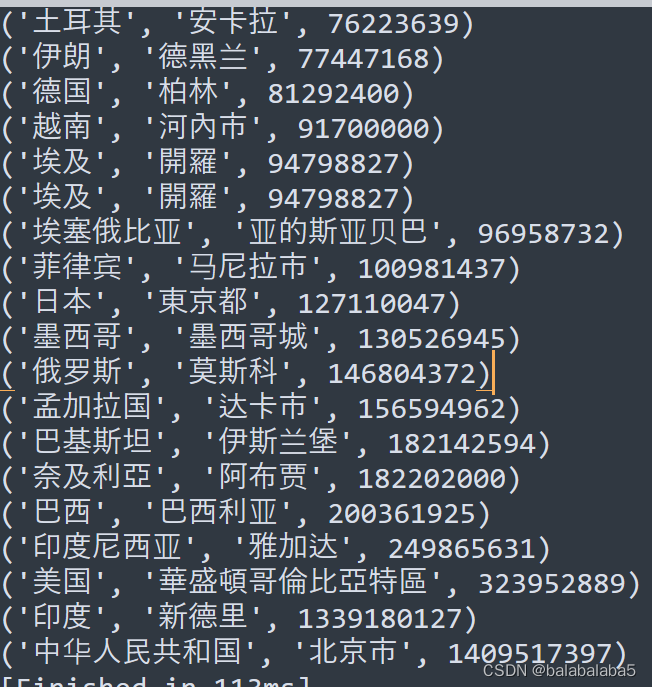
综上:减少了给方法起名字的步骤。
另外:为什么在使用方法get_population的时候,countries.sort(key=get_populetion)这里,没有使用get_population进行传参。
答:在这里更像是一种方法了。在案例里调用get_population函数的目的是 输出 输入变量的 第三个元素。key=get_populetion代表的规则是按照输入变量的第三个元素的大小进行排序,而输入变量就是指.sort之前的数组countries里的每个元素了。
比如:sorted([5,-36,9,-8,11], key=abs)
这个结果是[5, -8, 9, 11, -36]。
本来是对[5,-36,9,-8,11]进行排序的,但后面有个key,key的规则是使用绝对值进行排序,那么最后就是将数组[5,-36,9,-8,11]中的每个元素取绝对值之后再进行排序。
案例4:一元二次方程
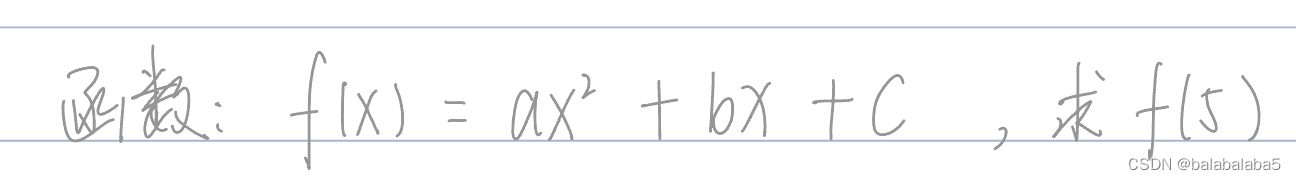
a,b,c代表的都是系数,x代表的是自变量,f(x)是因变量。
a,b,c代表的虽然都是可以改变的量,但含义不相同,放在一起变成一个形参好像不合适。比如:
def han_shu(a,b,c,x):......
肯定不合适。因此使用lambda去改写一下。
代码:
def quadratic(a, b, c):
return lambda x: a*x*x + b*x + c
# 代表的函数
f = quadratic(1,-1,2)
# 输出f(5)
print(f(5))这样的可读性比之前的好很多了。
总结:
写了一个def,但只有一句话的话,那就不用def,直接使用lambda表达式就可以了。