人类对于大型语言模型的两种不同的期待——领域专家or万事通
 vs
vs 
近年来,随着人工智能技术的不断发展,大型语言模型的应用越来越广泛,人们对于这类技术也有着不同的期待。
从技术手段的角度来看,人们主要期待大型语言模型能够通过finetune和prompt两种技术,成为专家或者通才,以更好地满足人们的需求。

Finetune和Prompt:是让大模型变成 特定领域专家 or 通才 的两种技术手段
Finetune和Prompt是大型语言模型中常用的两种技术:
Finetune本质上就是梯度下降方法来改变参数;
Prompt则是用人类语言操纵的指令,可以让大型语言模型更好地适应人类的需求。
人类对于大模型的两种期待
期待一:成为专家
人们对于大型语言模型的期望之一就是能够成为专家,解决某一特定任务。
例如,翻译任务需要大型语言模型能够精准地翻译不同语言之间的文本,而这就需要专业的语言知识和技能。
通过Finetune技术,大型语言模型可以针对特定任务进行微调,提高其在特定领域的表现,更有可能在特定方面赢过万事通。
期待二:成为通才
另一方面,人们更希望大型语言模型成为通才,什么都会。这也是人类对ChatGPT的期望。为了实现这一目标,需要对预训练模型进行改造,以适应不同的任务。除了Finetune技术,还可以使用Adapter技术。
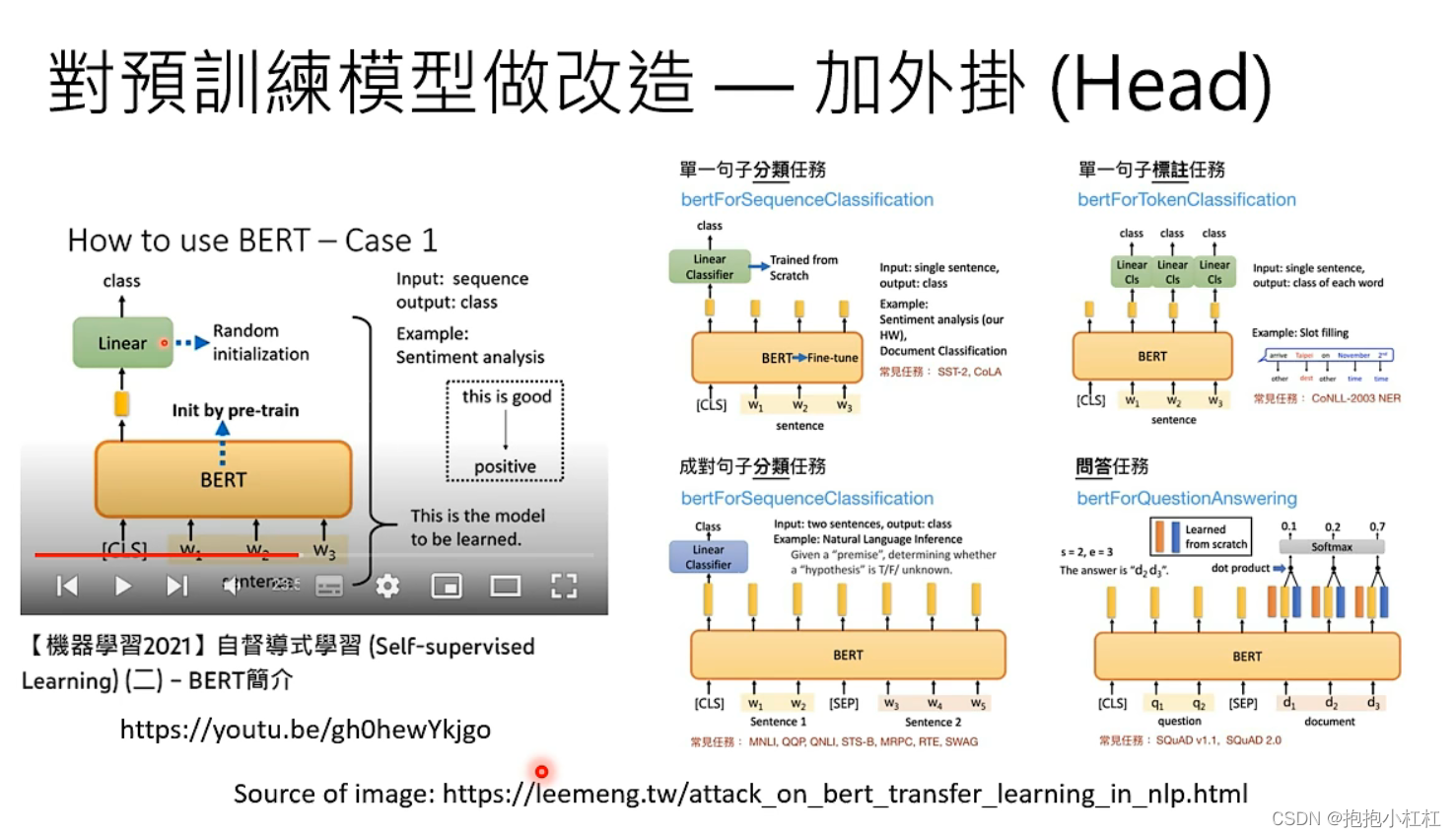
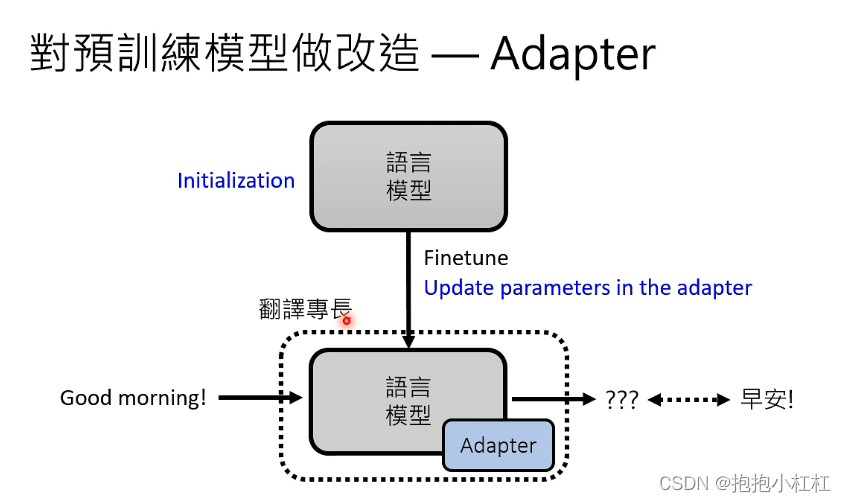
Adapter是一种对预训练模型进行改造的技术——不像Finetune那样调节模型中的所有参数,而是在语言模型中插入额外的插件。
这个插件可能是一个新的层,可以插在各种各样的地方,取决于具体的应用方式。通过Adapter技术,可以在模型外面加不同的Adapter,以适应不同的任务。
通过加外挂的方式来让大模型适应不同的任务,有何好处?
如果希望一个大模型在某个特定功能上表现非常出色的话,我们就需要对这个大模型内部的参数进行有针对性地调节;
那么!如果我想要机器在翻译、绘画、写作几方面,都能有非常优秀的表现,是不是应该训练3套不同的参数呢?这样花费的精力、内存是不是太大了呢?
so,使用对应的n个不同种类外挂的优势就体现出来了!
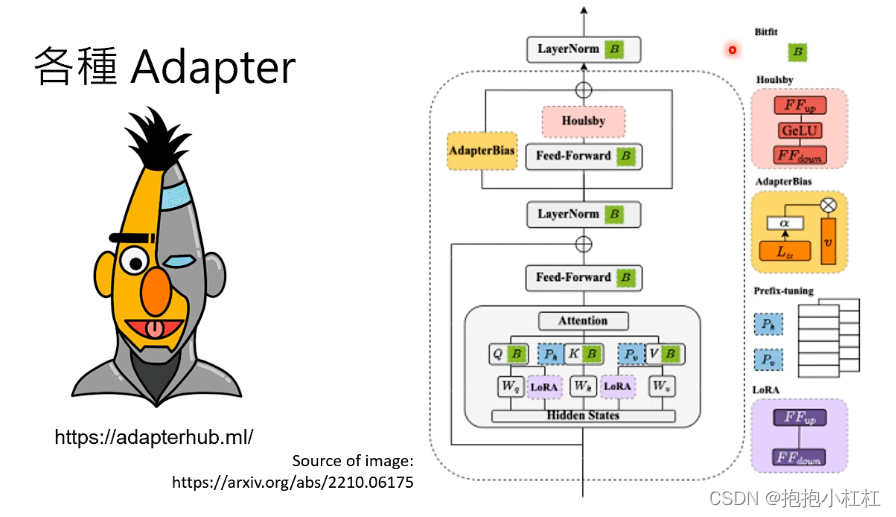
使用Adapter之后,内存中只需存储一个大模型和n个Adapter,
需要微调的就不是大模型本身,而是微调这个外挂!

这就是Adapter的魅力所在:不仅可以降低存储成本,还可以降低训练成本,大大提升了模型解决不同任务的能力。从而变成了通才,满足人们更多的需求~
总结
总的来说,人们对于大型语言模型的期望可以分为两种:成为专家和成为通才。Finetune和Prompt是实现这两种期望的常用技术,而Adapter技术则是一种更加高效的方式——加外挂,可以帮助大型语言模型用更低的成本,更好地适应不同的任务,成为真正的通才。