文章目录
1 论文阅读
1.1 论文摘要
Our main contribution is a thorough evaluation of networks of increasing depth using an architecture with very small (3 × 3) convolution filters, which shows that a significant improvement on the prior-art configurations can be achieved by pushing the depth to 16–19 weight layers.
我们的主要贡献是对使用非常小(3 × 3)卷积滤波器的体系结构增加深度的网络进行了全面评估,结果表明,通过将深度推至16-19个权值层,可以实现对现有技术配置的显著改进。
1.2 论文创新点
-
VGG使用 2个3X3的卷积核 来代替 5X5的卷积核,3个3X3的卷积核 代替7X7的卷积核。这样做的好处是:
①引入了多个非线性校正层而不是一个非线性校正层,使决策函数更具鉴别性。
②减少了参数的数量。 例如三层3 × 3卷积核的输入和输出都有C个通道,堆栈的参数化为3*(3C)²=27C²;同时,单个7 × 7卷积核需要(7C)²=49C²参数。
③在保证相同感受野的情况下,多个小卷积层堆积可以提升网络深度,增加特征提取能力。 -
引入1 × 1卷积层是增加决策函数非线性而不影响卷积层接受域的一种方法。
-
增加网络的深度。 我们固定了体系结构的其他参数,并通过增加更多的卷积层来稳步增加网络的深度,这是可行的,因为在所有层中都使用了非常小的(3 × 3)卷积滤波器。
1.3 学习细节
- 在训练过程中,我们的ConvNets的输入是一个固定大小的224 × 224 RGB图像。唯一预处理是从每个像素中减去在训练集中计算的平均RGB值。
- 图像经过一堆卷积(conv)层,我们使用一个感受野非常小的过滤器:3 × 3(这是捕获左/右、上/下、中等概念的最小尺寸)。
- 卷积步幅固定为1像素;卷积层输入的空间填充是为了保证卷积后的空间分辨率,即3 × 3的卷积层填充为1像素。
- 在其中一种配置中,我们还使用了1 × 1卷积滤波器,这可以被视为输入通道的线性变换(其次是非线性)。
- 空间池化由五个最大池化层执行,它们遵循一些卷积层(并不是所有卷积层都遵循最大池化)。最大池化在2 × 2像素的窗口上执行,步幅为2。
1.4 小结

2 网络框架分析
这里主要分析VGG-16。即D列。
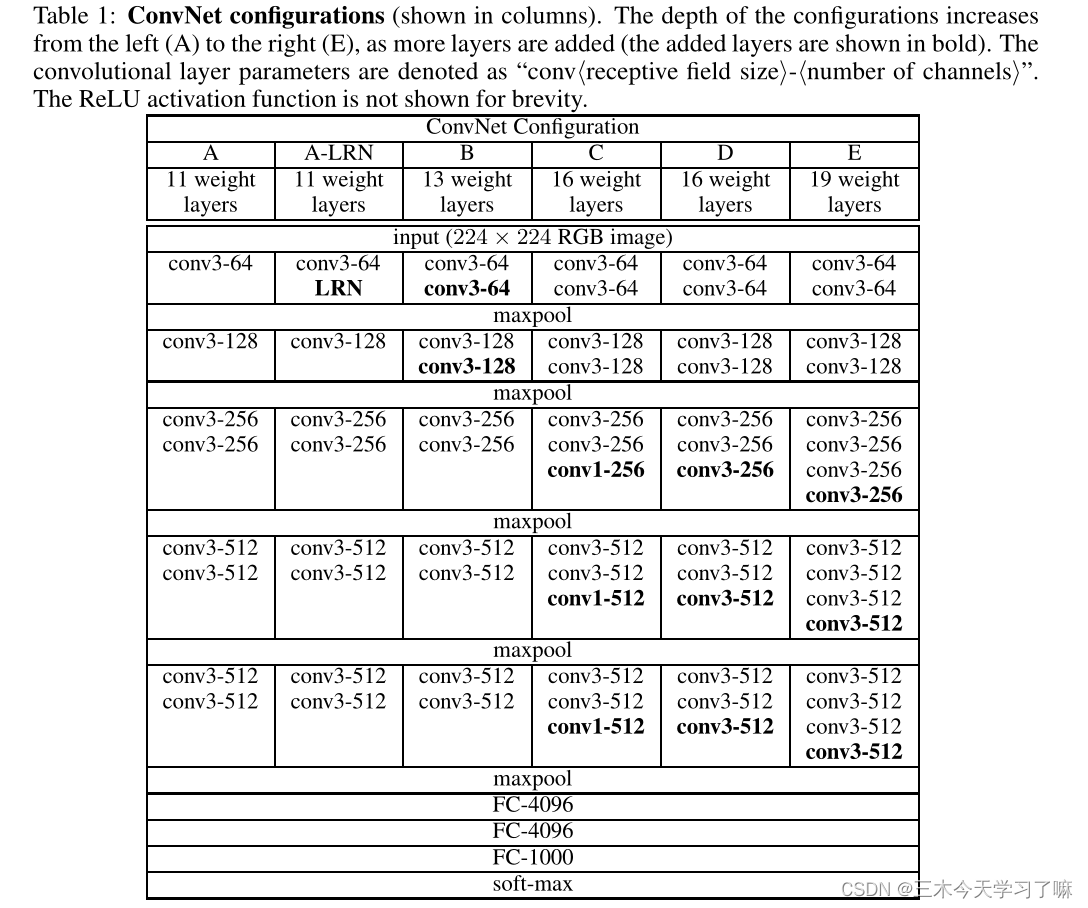
- 卷积块1得到的feature map: (224 - 2 * 3 + 2 * 2 * 1) + 2 = 224
- 最大池化层1得到的feature map:(224 - 2) ÷ 2 + 1 = 112
- 卷积块2得到的feature map: (112 - 2 * 3 + 2 * 2 * 1) + 2 = 112
- 最大池化层2得到的feature map:(112 - 2) ÷ 2 + 1 = 56
- 卷积块3得到的feature map: ( 56 - 3 * 3 + 3 * 2 * 1) + 3 = 56
- 最大池化层3得到的feature map:(56 - 2) ÷ 2 + 1 = 28
- 卷积块4得到的feature map: (28 - 3 * 3 + 3 * 2 * 1) + 3 = 28
- 最大池化层4得到的feature map:(28 - 2) ÷ 2 + 1 = 14
- 卷积层5得到的feature map: ( 14 - 3 * 3 + 3 * 2 * 1) + 3 = 14
- 最大池化层5得到的feature map:(14 - 2) ÷ 2 + 1 = 7
- Flatten展开:7 × 7 × 512 = 25088
- 全连接层1:25088 -> 4096
- 丢弃层:p = 0.5
- 全连接层2:4096 -> 4096
- 丢弃层:p = 0.5
- 全连接层3:4096 -> 1000
Sequential output shape: torch.Size([1, 64, 112, 112])
Sequential output shape: torch.Size([1, 128, 56, 56])
Sequential output shape: torch.Size([1, 256, 28, 28])
Sequential output shape: torch.Size([1, 512, 14, 14])
Sequential output shape: torch.Size([1, 512, 7, 7])
Flatten output shape: torch.Size([1, 25088])
Linear output shape: torch.Size([1, 4096])
ReLU output shape: torch.Size([1, 4096])
Dropout output shape: torch.Size([1, 4096])
Linear output shape: torch.Size([1, 4096])
ReLU output shape: torch.Size([1, 4096])
Dropout output shape: torch.Size([1, 4096])
Linear output shape: torch. Size([1, 1000])
3 网络参数数量
卷积层的参数 = 卷积核大小 x 卷积核的数量+ 偏置数量(即卷积的核数量)
全连接层的参数数量 = 上一层节点数量(pooling之后的) x 下一层节点数量 + 偏置数量(即下一层的节点数量)
参数计算可参考:VGG参数计算
接下来梳理一下各层的参数情况:
- 输入层:图片大小:宽高通道(RGB)依次为W * H * C = 224 x 224 x 3, 即150528像素。
- 第1个隐层, 卷积层,使用 2次 64个 3 x 3 x 3的卷积核,
本层参数数量为: (3 * 3 * 3 * 64) + 64 + (3 * 3 * 64 * 64) + 64 = 38720 - 第2个隐层, 卷积层,使用 2次 128个 3 x 3 x 3的卷积核,
本层参数数量为: (3 * 3 * 64 * 128) + 128 + (3 * 3 * 128 * 128) + 128 = 221440 - 第3个隐层, 卷积层,使用 2次 256个 3 x 3 x 3的卷积核,
本层参数数量为: (3 * 3 * 128* 256) + 256 + (3 * 3 * 256 * 256 * 2) + 256 * 2 = 1475328 - 第4个隐层, 卷积层,使用 2次 512个 3 x 3 x 3的卷积核,
本层参数数量为: (3 * 3 * 256 * 512) + 512 + (3 * 3 * 512 * 512 * 2) + 512 * 2 = 5899776 - 第5个隐层, 卷积层,使用 2次 512个 3 x 3 x 3的卷积核,
本层参数数量为: (3 * 3 * 512 * 512) + 512 + (3 * 3 * 512 * 512 * 2) + 512 * 2= 7079424 - 第6个隐层,全连接层,节点数量为: 4096。参数数量为:(7 * 7 * 512) * 4096 + 4096 = 102760944
- 第7个隐层,全连接层,节点数量为: 4096。参数数量为:4096 * 4096 + 4096 = 16781312
- 第8个隐层,全连接层,节点数量为: 1000。参数数量为:1000 * 4096 + 4096 = 4100096
总和:138357040。共1.38亿个参数。

4 网络搭建
4.1 基本架构
import torch
from torch import nn
class VGG(nn.Module):
def __init__(self, num_classes: int = 1000) -> None:
super(VGG, self).__init__()
self.features = nn.Sequential(
# 3×3的卷积层填充为1像素 最大池化在2 × 2像素的窗口上执行,步幅为2
nn.Conv2d(in_channels=3, out_channels=64, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=128, out_channels=128, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=128, out_channels=256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=256, out_channels=512, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
)
self.avgpool = nn.AvgPool2d(2, 2)
self.classifier = nn.Sequential(
nn.Dropout(0.5),
nn.Flatten(7 * 7 * 512, 4096),
nn.Dropout(0.5),
nn.Flatten(4096, 4096),
nn.Dropout(0.5),
nn.Flatten(4096, 1000),
)
def forward(self, x: torch.Tensor) -> torch.Tensor:
x = self.features(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x
4.2 Pytroch官方架构
import torch
import torch.nn as nn
from .utils import load_state_dict_from_url
from typing import Union, List, Dict, Any, cast
__all__ = [
'VGG', 'vgg11', 'vgg11_bn', 'vgg13', 'vgg13_bn', 'vgg16', 'vgg16_bn',
'vgg19_bn', 'vgg19',
]
model_urls = {
'vgg11': 'https://download.pytorch.org/models/vgg11-8a719046.pth',
'vgg13': 'https://download.pytorch.org/models/vgg13-19584684.pth',
'vgg16': 'https://download.pytorch.org/models/vgg16-397923af.pth',
'vgg19': 'https://download.pytorch.org/models/vgg19-dcbb9e9d.pth',
'vgg11_bn': 'https://download.pytorch.org/models/vgg11_bn-6002323d.pth',
'vgg13_bn': 'https://download.pytorch.org/models/vgg13_bn-abd245e5.pth',
'vgg16_bn': 'https://download.pytorch.org/models/vgg16_bn-6c64b313.pth',
'vgg19_bn': 'https://download.pytorch.org/models/vgg19_bn-c79401a0.pth',
}
class VGG(nn.Module):
def __init__(
self,
features: nn.Module,
num_classes: int = 1000,
init_weights: bool = True
) -> None:
super(VGG, self).__init__()
self.features = features
self.avgpool = nn.AdaptiveAvgPool2d((7, 7))
self.classifier = nn.Sequential(
nn.Linear(512 * 7 * 7, 4096),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(4096, num_classes),
)
if init_weights:
self._initialize_weights()
def forward(self, x: torch.Tensor) -> torch.Tensor:
x = self.features(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x
def _initialize_weights(self) -> None:
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)
def make_layers(cfg: List[Union[str, int]], batch_norm: bool = False) -> nn.Sequential:
layers: List[nn.Module] = []
in_channels = 3
for v in cfg:
if v == 'M':
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
else:
v = cast(int, v)
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)
if batch_norm:
layers += [conv2d, nn.BatchNorm2d(v), nn.ReLU(inplace=True)]
else:
layers += [conv2d, nn.ReLU(inplace=True)]
in_channels = v
return nn.Sequential(*layers)
cfgs: Dict[str, List[Union[str, int]]] = {
'A': [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'B': [64, 64, 'M', 128, 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'D': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M'],
'E': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', 512, 512, 512, 512, 'M', 512, 512, 512, 512, 'M'],
}
def _vgg(arch: str, cfg: str, batch_norm: bool, pretrained: bool, progress: bool, **kwargs: Any) -> VGG:
if pretrained:
kwargs['init_weights'] = False
model = VGG(make_layers(cfgs[cfg], batch_norm=batch_norm), **kwargs)
if pretrained:
state_dict = load_state_dict_from_url(model_urls[arch],
progress=progress)
model.load_state_dict(state_dict)
return model
def vgg11(pretrained: bool = False, progress: bool = True, **kwargs: Any) -> VGG:
r"""VGG 11-layer model (configuration "A") from
`"Very Deep Convolutional Networks For Large-Scale Image Recognition" <https://arxiv.org/pdf/1409.1556.pdf>`_.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
return _vgg('vgg11', 'A', False, pretrained, progress, **kwargs)
def vgg11_bn(pretrained: bool = False, progress: bool = True, **kwargs: Any) -> VGG:
r"""VGG 11-layer model (configuration "A") with batch normalization
`"Very Deep Convolutional Networks For Large-Scale Image Recognition" <https://arxiv.org/pdf/1409.1556.pdf>`_.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
return _vgg('vgg11_bn', 'A', True, pretrained, progress, **kwargs)
def vgg13(pretrained: bool = False, progress: bool = True, **kwargs: Any) -> VGG:
r"""VGG 13-layer model (configuration "B")
`"Very Deep Convolutional Networks For Large-Scale Image Recognition" <https://arxiv.org/pdf/1409.1556.pdf>`_.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
return _vgg('vgg13', 'B', False, pretrained, progress, **kwargs)
def vgg13_bn(pretrained: bool = False, progress: bool = True, **kwargs: Any) -> VGG:
r"""VGG 13-layer model (configuration "B") with batch normalization
`"Very Deep Convolutional Networks For Large-Scale Image Recognition" <https://arxiv.org/pdf/1409.1556.pdf>`_.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
return _vgg('vgg13_bn', 'B', True, pretrained, progress, **kwargs)
def vgg16(pretrained: bool = False, progress: bool = True, **kwargs: Any) -> VGG:
r"""VGG 16-layer model (configuration "D")
`"Very Deep Convolutional Networks For Large-Scale Image Recognition" <https://arxiv.org/pdf/1409.1556.pdf>`_.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
return _vgg('vgg16', 'D', False, pretrained, progress, **kwargs)
def vgg16_bn(pretrained: bool = False, progress: bool = True, **kwargs: Any) -> VGG:
r"""VGG 16-layer model (configuration "D") with batch normalization
`"Very Deep Convolutional Networks For Large-Scale Image Recognition" <https://arxiv.org/pdf/1409.1556.pdf>`_.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
return _vgg('vgg16_bn', 'D', True, pretrained, progress, **kwargs)
def vgg19(pretrained: bool = False, progress: bool = True, **kwargs: Any) -> VGG:
r"""VGG 19-layer model (configuration "E")
`"Very Deep Convolutional Networks For Large-Scale Image Recognition" <https://arxiv.org/pdf/1409.1556.pdf>`_.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
return _vgg('vgg19', 'E', False, pretrained, progress, **kwargs)
def vgg19_bn(pretrained: bool = False, progress: bool = True, **kwargs: Any) -> VGG:
r"""VGG 19-layer model (configuration 'E') with batch normalization
`"Very Deep Convolutional Networks For Large-Scale Image Recognition" <https://arxiv.org/pdf/1409.1556.pdf>`_.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
return _vgg('vgg19_bn', 'E', True, pretrained, progress, **kwargs)
5 总结
VGG的创新点:
- 小卷积核
VGG使用多个小卷积核(3x3)的卷积层代替大的卷积核,一方面可以减少参数,另一方面相当于进行了更多的非线性映射,以增加网络的拟合/表达能力。 - 层数更深
VGG常用结构层数为16层,19层,Alexnet有为8层。层数更深,效果更好。