在本文中,让我们了解 Elasticsearch 如何处理数据读取的更多信息。 到本文结束时,你将深入了解 Elasticsearch 中的路由、自适应副本选择 (Adaptive Replica Selection - ARS) 和整体数据读取工作流。更多关于 Elasticsearch 的操作,请详细阅读 “Elasticsearch:彻底理解 Elasticsearch 数据操作”。
路由在此过程中必不可少,但还有其他因素需要考虑。 请记住,我们的演讲将主要围绕阅读单个文档展开,届时我们将深入探讨搜索查询。
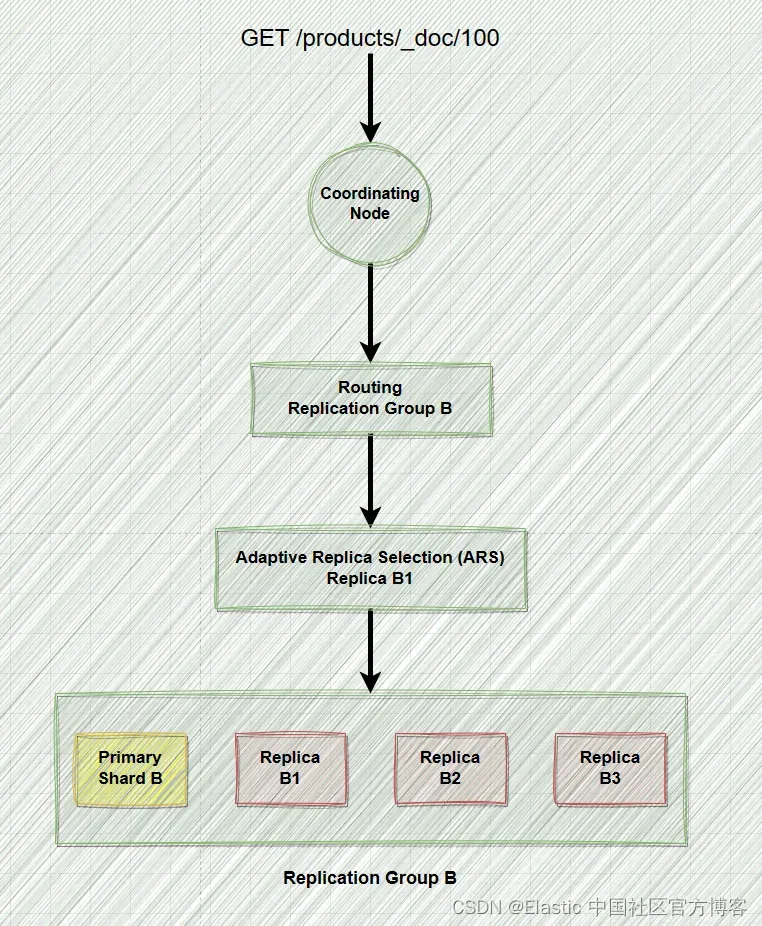
首先,当发出读取请求时,它会被传送到特定节点。 该节点称为协调节点,负责协调请求。

现在,你可能想知道这种协调需要什么。 那么,第一步涉及确定我们要检索的文档的位置。 路由用于此目的。
你之前可能在我们的谈话中指出,路由有助于确定保存特定文档的分片。 这仍然是正确的,但让我们更精确一点。 如果分片已被复制,路由将解析为主分片或复制组(主分片及其副本分片统称为复制组,详细请阅读文章 “Elasticsearch:复制 - replication”)。 由于各种原因,这种复制几乎总是会发生。
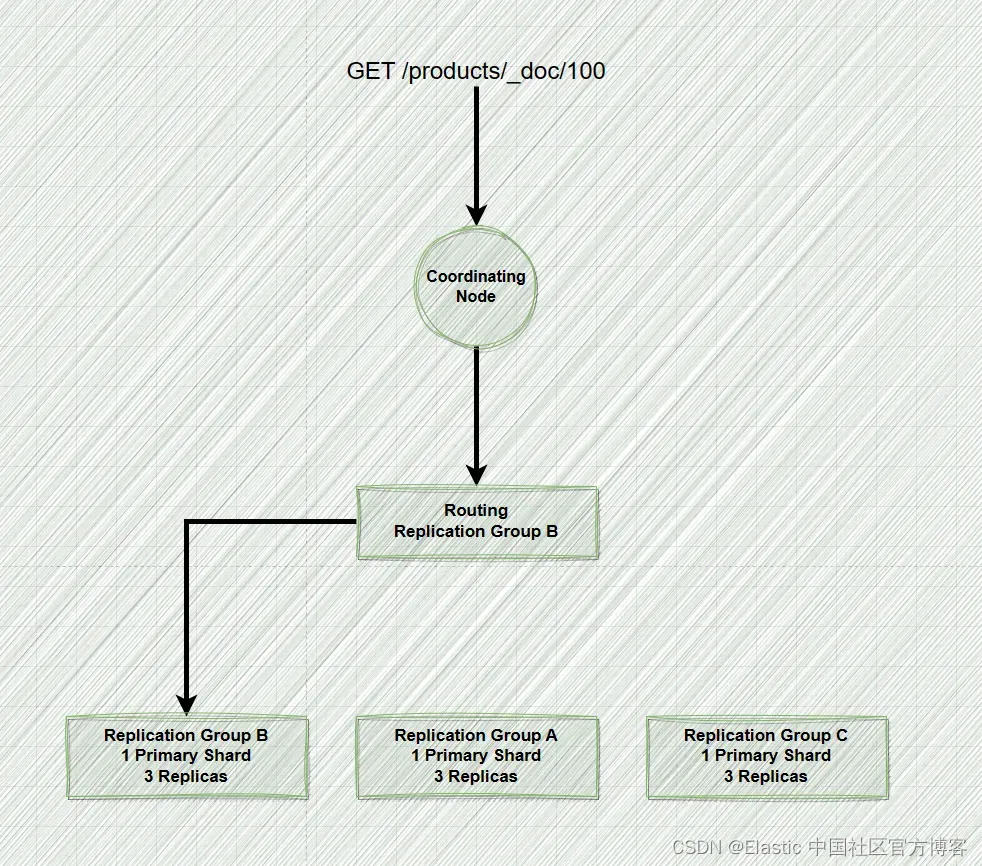
为了确保可伸缩性,Elasticsearch 以某种方式获取文档。 如果每次都只是从主分片中检索文档,那么所有检索都将在同一个分片上结束。 但是,随着工作负载的增长,此策略无法有效扩展。 Elasticsearch 使用一种称为自适应副本选择 (ARS) 的机制来解决这个问题。
ARS 对检索过程至关重要。 它根据各种标准选择最佳分片副本。 虽然我现在不会详细介绍评估公式,但请放心,Elasticsearch 采用综合方法来确定最佳分片副本。