Label-consistent UDTL(unsupervised deep transfer learning)
本文内容:赵志斌UDTL开源代码的backbone实现
代码github链接:https://github.com/HappyBoy-cmd/UDTL
backbone主干网络模型组成
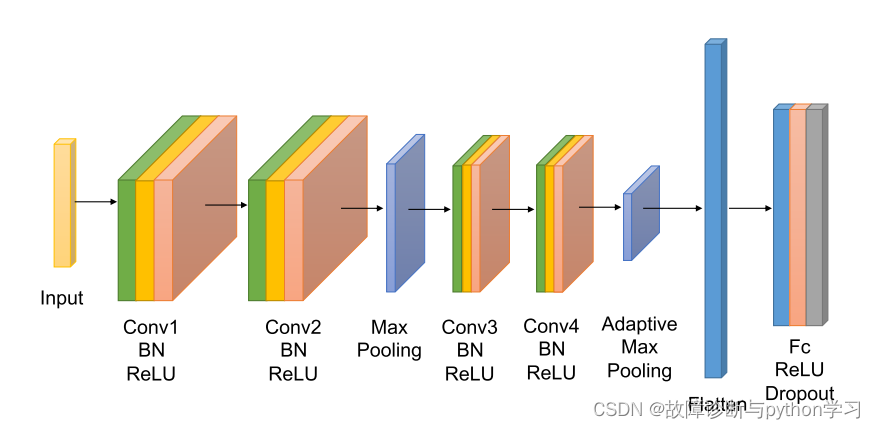
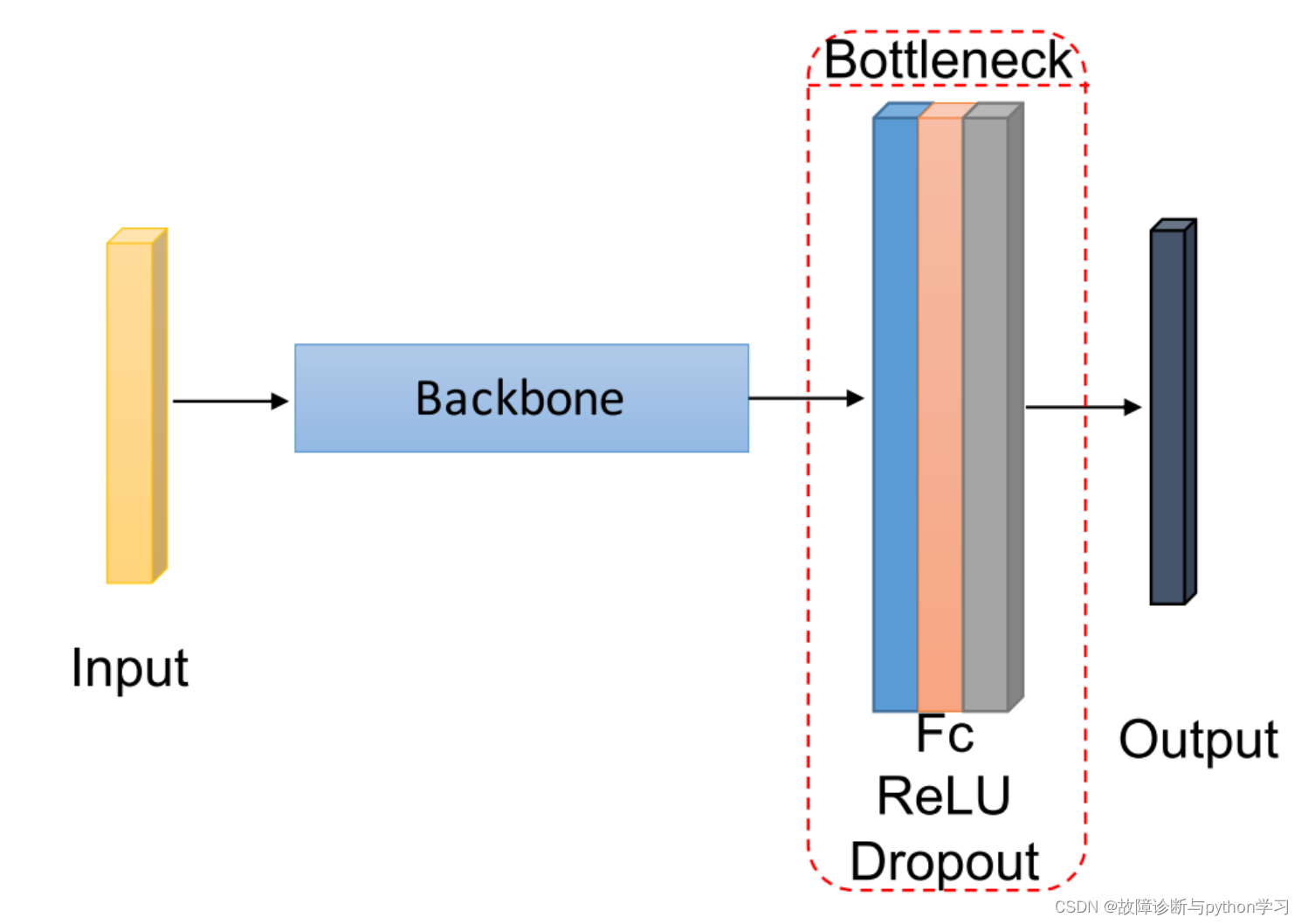
网络模型
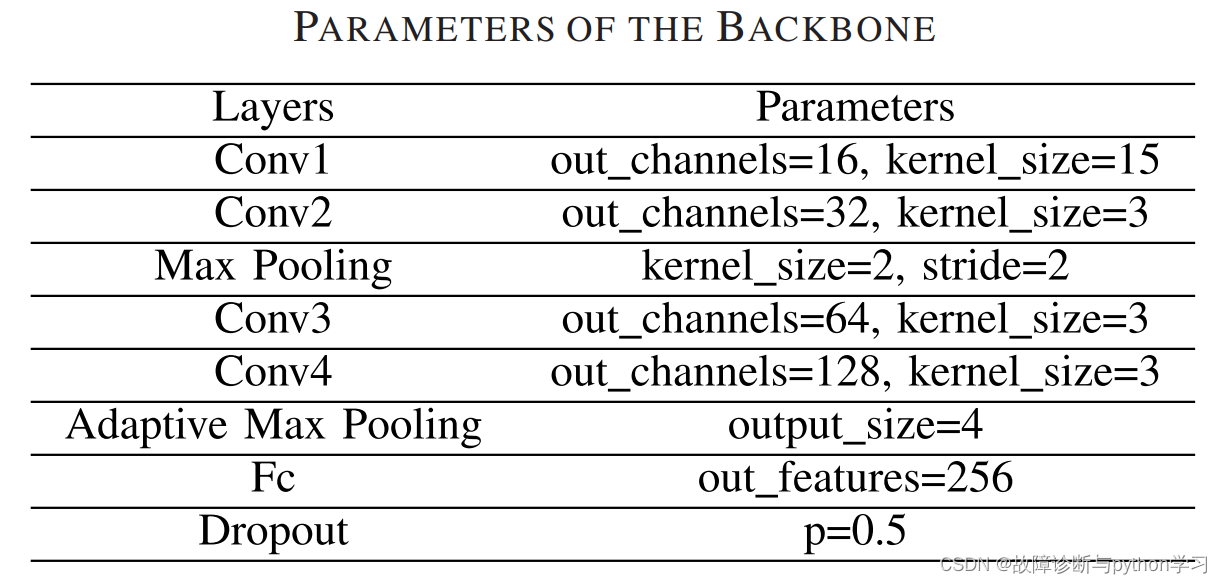
网络模型参数
模型pytorch代码
#!/usr/bin/python
# -*- coding:utf-8 -*-
from torch import nn
import warnings
# ----------------------------inputsize >=28-------------------------------------------------------------------------
class CNN(nn.Module):
def __init__(self, pretrained=False, in_channel=1, out_channel=10):
super(CNN, self).__init__()
if pretrained == True:
warnings.warn("Pretrained model is not available")
self.layer1 = nn.Sequential(
nn.Conv1d(in_channel, 16, kernel_size=15), # 16, 26 ,26
nn.BatchNorm1d(16),
nn.ReLU(inplace=True))
self.layer2 = nn.Sequential(
nn.Conv1d(16, 32, kernel_size=3), # 32, 24, 24
nn.BatchNorm1d(32),
nn.ReLU(inplace=True),
nn.MaxPool1d(kernel_size=2, stride=2),
) # 32, 12,12 (24-2) /2 +1
self.layer3 = nn.Sequential(
nn.Conv1d(32, 64, kernel_size=3), # 64,10,10
nn.BatchNorm1d(64),
nn.ReLU(inplace=True))
self.layer4 = nn.Sequential(
nn.Conv1d(64, 128, kernel_size=3), # 128,8,8
nn.BatchNorm1d(128),
nn.ReLU(inplace=True),
nn.AdaptiveMaxPool1d(4)) # 128, 4,4
self.layer5 = nn.Sequential(
nn.Linear(128 * 4, 256),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(256, 256),
nn.ReLU(inplace=True),
nn.Dropout(),
)
self.fc = nn.Linear(256, out_channel)
def forward(self, x): # x输入为channel为1,长度为1024
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = x.view(x.size(0), -1)
x = self.layer5(x)
x = self.fc(x)
return x
模型测试:
model = CNN() #加载模型
x = torch.randn([16, 1, 1024]) # batch_size = 16, channel = 1, len = 1024
print(x)
>>>结果输出
tensor([[[ 1.6765e+00, -5.0673e-01, -8.4661e-01, ..., 1.3182e-03,
3.6003e-01, -4.9098e-01]],
[[ 1.8038e-01, 3.3888e+00, -6.2151e-01, ..., 1.8527e-01,
8.6888e-01, -3.9862e-01]],
[[-5.1029e-02, -2.7900e+00, 8.7660e-01, ..., -4.1347e-01,
-5.2011e-01, -1.1997e-01]],
...,
[[-1.3845e+00, -9.7379e-01, -1.1276e+00, ..., 4.0277e-01,
-2.1397e+00, 3.9430e-02]],
[[ 4.9035e-01, 1.4926e-01, -2.9260e-01, ..., 3.6087e-01,
5.0232e-01, 1.1382e+00]],
[[-1.3410e+00, -8.0721e-01, -2.4605e+00, ..., -1.5650e+00,
-5.9978e-01, -9.1267e-01]]])``model(x)
y = model(x)
print(y)
tensor([[ 0.0508, -0.2657, 0.0036, -0.8904, 0.4402, -0.2396, -0.0749, -0.8506,
0.0321, -1.0699],
[-0.5058, 0.0264, 1.8257, -1.3112, 0.7088, -0.1765, 0.1929, 0.4886,
0.1973, -0.8568],
[-0.0061, 0.3359, 0.3943, -0.4675, -1.1316, 0.1924, 1.7509, 0.2536,
-0.6900, -0.9577],
[ 0.3317, -0.5512, 0.2652, 0.1834, -0.2543, -0.2176, 0.4419, 0.4914,
1.1083, -0.7718],
...
[-0.1593, -0.8255, -0.2867, -1.0740, -0.8413, 0.2205, 0.5246, -0.0087,
0.0191, -0.9652],
[ 0.1454, -1.6750, 0.3506, -0.1599, -0.2638, 0.5976, 0.0670, -0.7719,
0.0851, 0.0249]], grad_fn=<AddmmBackward0>)