文章全部内容在个人站点内的置顶文章中,访问密码:AIIT
小凯的宝库
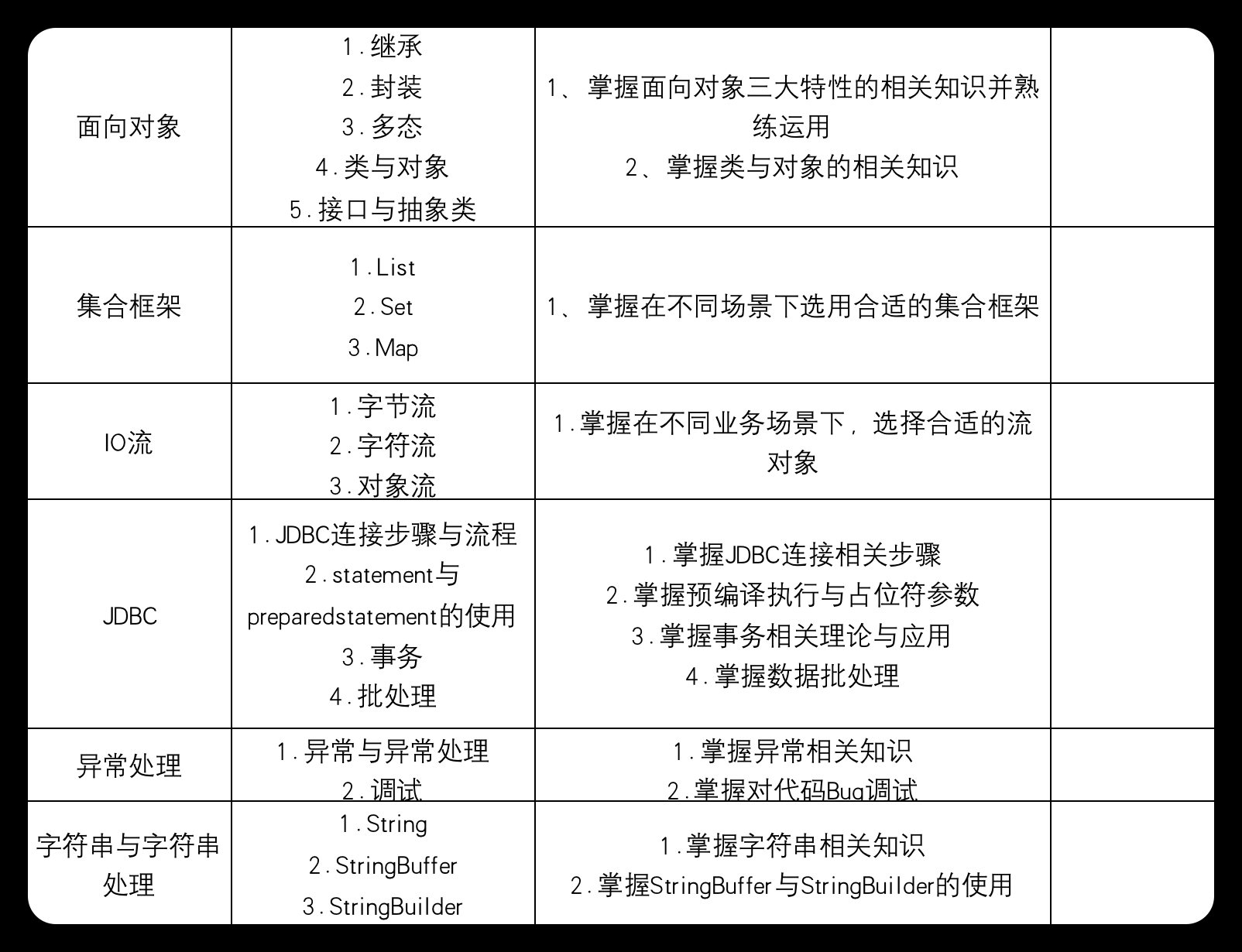
模块三、面向对象
-
继承:
a. 单继承:Java只支持单继承,即一个子类只能有一个直接父类。但子类可以间接地继承多个父类。
b. 构造方法与继承:在子类中可以通过
super()关键字调用父类的构造方法。如果子类没有显式地调用父类的构造方法,Java会自动调用父类的无参构造方法。c. 方法重写(Override):子类可以覆盖父类的方法,以实现不同的行为。重写方法的访问修饰符、返回类型、方法名和参数列表必须与父类相同,同时子类方法的访问权限不能低于父类方法。
d. final关键字:使用
final修饰的类不能被继承,使用final修饰的方法不能被重写。 -
封装:
a. 访问修饰符:Java中有四种访问修饰符,分别是public(公共的)、protected(受保护的)、private(私有的)和默认(包内可见)。它们分别限制了类、属性和方法的可见性范围。
b. Getter和Setter方法:通过提供公共的获取(get)和设置(set)方法,可以实现对私有属性的访问和修改。这样可以对属性值的修改加以控制,保证数据的完整性和安全性。
-
多态:
a. 方法重写(Override):子类覆盖父类的方法,以实现不同的行为。多态的体现之一。
b. 接口实现(Implements):一个类可以实现多个接口,从而实现多态。接口定义了一组行为规范,但不包含实现。实现接口的类必须实现接口中的所有抽象方法。
c. 向上转型(Upcasting):子类的对象可以被当作父类的对象来使用。这允许我们在运行时动态地改变对象的行为。
d. 向下转型(Downcasting):将父类对象强制转换为子类对象。在进行向下转型之前,需要先判断对象是否为目标子类的实例,可以使用
instanceof关键字进行判断。 -
类与对象:
a. 实例变量和类变量:实例变量是每个对象实例独有的,存储在堆内存中;类变量是所有对象实例共享的,使用
static关键字修饰,存储在方法区中。b. 实例方法和类方法:实例方法属于对象实例,可以访问实例变量;类方法属于类,使用
static关键字修饰,不能直接访问实例变量,只能访问类变量。c. 构造方法:用于创建对象实例并初始化实例变量的特殊方法。构造方法的名称与类名相同,没有返回值类型。一个类可以有多个构造方法,通过参数列表的不同进行区分。
d. 匿名对象:没有显式声明变量引用的对象。匿名对象在创建后可以立即使用,但只能使用一次。
-
接口与抽象类:
a. 接口:
- 使用
interface关键字定义。 - 可以包含抽象方法和默认方法(使用
default关键字修饰,具有默认实现)。 - 不能包含实例变量,但可以包含静态常量。
- 一个类可以实现多个接口,接口之间可以多重继承。
b. 抽象类:
- 使用
abstract关键字定义。 - 可以包含抽象方法和具体实现。
- 可以包含实例变量。
- 一个类只能继承一个抽象类。
- 抽象类可以包含构造方法,但不能直接实例化。只能通过继承后的子类进行实例化。
- 使用
模块四、集合框架
-
List:
List是一个有序集合,允许存储重复元素。List接口的主要实现类有:a. ArrayList:基于动态数组实现,支持随机访问。插入和删除元素的时间复杂度可能较高,因为需要移动数组元素。
b. LinkedList:基于双向链表实现,适合在列表的头部和尾部进行插入和删除操作。不支持高效的随机访问,因为需要遍历链表。
-
Set:
Set是一个不允许存储重复元素的无序集合。Set接口的主要实现类有:a. HashSet:基于哈希表实现,具有很好的查找和插入性能。元素在集合中的顺序是不确定的。
b. LinkedHashSet:基于链表和哈希表实现,保持了插入顺序。性能略低于HashSet,但在某些场景下有序性可能是需要的。
c. TreeSet:基于红黑树实现,元素按照排序顺序存储。支持高效的查找和排序操作,但插入和删除操作相对较慢。
-
Map:
Map是一个存储键值对的无序集合,键不允许重复。Map接口的主要实现类有:a. HashMap:基于哈希表实现,具有很好的查找和插入性能。键值对在Map中的顺序是不确定的。
b. LinkedHashMap:基于链表和哈希表实现,保持了插入顺序。性能略低于HashMap,但在某些场景下有序性可能是需要的。
c. TreeMap:基于红黑树实现,键按照排序顺序存储。支持高效的查找和排序操作,但插入和删除操作相对较慢。
需要掌握的能力:
-
掌握在不同场景下选用合适的集合框架:
a. 选择List:
- 当需要存储具有顺序的元素并允许重复时。
- 当需要频繁访问元素时,可以选择ArrayList。
- 当需要频繁进行头部和尾部的插入和删除操作时,可以选择LinkedList。
b. 选择Set:
- 当需要存储不允许重复的元素时。
- 当需要快速查找和插入元素时,可以选择HashSet。
- 当需要保持元素的插入顺序时,可以选择LinkedHashSet。
- 当需要对元素进行排序时,可以选择TreeSet。
c. 选择Map:
- 当需要存储键值对数据时。
- 当需要快速查找和插入键值对时,可以选择HashMap。
- 当需要保持键值对的插入顺序时,可以选择LinkedHashMap。
- 当需要对键进行排序时,可以选择TreeMap。
在实际应用中,根据不同的业务场景和性能需求,选择合适的集合框架来优化程序性能。例如,如果需要快速查找元素,可以选择基于哈希表的实现;如果需要对元素进行排序,可以选择基于红黑树的实现。
请注意,Java集合框架中的类和接口还提供了许多其他功能,例如迭代器、比较器、过滤器等。在实际编程中,需要熟练掌握这些功能,以便更有效地操作集合数据。以下我整理了一部分
-
迭代器(Iterator):
- 迭代器是一种遍历集合元素的通用方法。可以用于遍历List、Set和Map等集合。
- 使用
iterator()方法获取集合的迭代器,然后通过hasNext()和next()方法进行遍历。 - Java 1.8引入了
forEachRemaining()方法,可以使用Lambda表达式更简洁地遍历集合。
-
比较器(Comparator):
- Comparator接口用于定义自定义排序规则。在使用TreeSet和TreeMap等需要排序的集合时,可以使用Comparator自定义排序规则。
- 实现Comparator接口的
compare()方法,根据需要对两个对象进行比较。 - Java 1.8引入了
Comparator接口的默认方法,例如reversed()、thenComparing()等,可以方便地对比较器进行组合和修改。
-
过滤器(Predicate):
- Java 1.8引入了Predicate接口,用于表示一个判断条件。可以结合Stream API对集合进行过滤操作。
- 实现Predicate接口的
test()方法,根据需要对元素进行判断。 - Predicate接口提供了一些默认方法,例如
and()、or()、negate()等,可以方便地对过滤条件进行组合和修改。
-
Stream API:
- Java 1.8引入了Stream API,提供了一种新的处理集合数据的方法。可以对集合进行过滤、映射、排序、聚合等操作。
- 使用
stream()方法将集合转换为Stream,然后使用Stream API中提供的方法进行操作。最后使用collect()、toArray()、reduce()等方法将结果转换回集合或其他数据类型。 - Stream API支持串行和并行处理,可以通过
parallelStream()方法获取并行Stream,提高处理大量数据的性能。
-
并发集合:
- Java提供了一些线程安全的并发集合类,例如
CopyOnWriteArrayList、ConcurrentHashMap、ConcurrentLinkedQueue等。它们可以在多线程环境下安全地进行数据操作。 - 并发集合通过内部加锁机制、原子操作等方法实现线程安全。相比于使用
Collections.synchronizedXXX()方法包装的同步集合,它们通常具有更好的性能。
- Java提供了一些线程安全的并发集合类,例如
这些补充功能可以帮助您更灵活、高效地操作集合数据。掌握这些功能对于使用Java集合框架非常重要。
模块五、IO流
-
字节流:
字节流用于处理字节数据(如图像、音频等)和二进制文件。字节流的主要类有:a. InputStream:字节输入流的基类。常用子类包括 FileInputStream(读取文件)、ByteArrayInputStream(读取字节数组)等。
b. OutputStream:字节输出流的基类。常用子类包括 FileOutputStream(写入文件)、ByteArrayOutputStream(写入字节数组)等。
-
字符流:
字符流用于处理字符数据和文本文件。字符流的主要类有:a. Reader:字符输入流的基类。常用子类包括 FileReader(读取文件)、StringReader(读取字符串)等。
b. Writer:字符输出流的基类。常用子类包括 FileWriter(写入文件)、StringWriter(写入字符串)等。
-
对象流:
对象流用于处理序列化的Java对象。对象流的主要类有:a. ObjectInputStream:对象输入流,用于从字节流中读取序列化的对象。
b. ObjectOutputStream:对象输出流,用于将序列化的对象写入字节流。
-
掌握在不同业务场景下,选择合适的流对象:
a. 选择字节流:
- 当处理字节数据(如图像、音频等)和二进制文件时,应使用字节流。
- 当需要高效地读写大量字节数据时,可以考虑使用缓冲字节流(BufferedInputStream 和 BufferedOutputStream)。
b. 选择字符流:
- 当处理字符数据和文本文件时,应使用字符流。
- 当需要高效地读写大量字符数据时,可以考虑使用缓冲字符流(BufferedReader 和 BufferedWriter)。
- 当需要对字符进行转换(如编码、解码)时,可以使用 InputStreamReader 和 OutputStreamWriter。
c. 选择对象流:
- 当需要读写序列化的Java对象时,应使用对象流。
- 请注意,要使用对象流,需要确保对象所属的类实现了 Serializable 接口。
在实际应用中,根据不同的业务场景和需求,选择合适的流对象以优化程序性能。同时,需要注意正确地关闭流资源,以避免资源泄漏。
模块六、JDBC
以下是关于Java JDBC的相关知识点和需要掌握的能力:
知识点:
-
JDBC连接步骤与流程:
a. 加载数据库驱动:通过Class.forName()方法加载数据库驱动类。
b. 建立连接:使用DriverManager.getConnection()方法获取与数据库的连接对象。
c. 创建语句:通过连接对象的createStatement()或prepareStatement()方法创建Statement或PreparedStatement对象。
d. 执行查询:使用executeQuery()方法执行查询操作,返回ResultSet对象;或使用executeUpdate()方法执行更新操作,返回受影响的行数。
e. 处理结果:遍历ResultSet对象,获取查询结果。
f. 关闭资源:关闭ResultSet、Statement(或PreparedStatement)和Connection对象,释放资源。 -
Statement与PreparedStatement的使用:
a. Statement:用于执行静态SQL语句。可能存在SQL注入风险,且性能较低。
b. PreparedStatement:用于执行预编译SQL语句,具有占位符参数。可以防止SQL注入,并提高执行性能。 -
事务:
a. 事务是一组原子操作,要么全部成功,要么全部失败。
b. JDBC默认使用自动提交模式。要使用事务,需要通过Connection.setAutoCommit(false)关闭自动提交。
c. 使用Connection.commit()提交事务,或使用Connection.rollback()回滚事务。 -
批处理:
a. 批处理用于一次执行多条SQL语句,提高执行效率。
b. 通过Statement.addBatch()或PreparedStatement.addBatch()方法添加SQL语句。
c. 使用Statement.executeBatch()或PreparedStatement.executeBatch()方法执行批处理。
需要掌握的能力:
-
掌握JDBC连接相关步骤:了解并熟练掌握JDBC连接数据库的流程,包括加载驱动、建立连接、创建语句、执行查询、处理结果和关闭资源等。
-
掌握预编译执行与占位符参数:
a. 预编译执行:PreparedStatement是一种预编译SQL语句的方式,它在数据库端进行预编译,减少了数据库重复编译同一SQL语句的开销,从而提高了执行性能。PreparedStatement允许使用占位符参数,这样可以避免拼接SQL字符串的麻烦,提高代码的可读性和可维护性。
b. 占位符参数:占位符参数是用问号(?)表示的参数,它们用于替换SQL语句中的实际值。在设置占位符参数时,可以使用
PreparedStatement类的setXXX()方法(如setString()、setInt()等),其中XXX表示相应的数据类型。这种方式可以防止SQL注入攻击,因为用户提供的数据将被视为参数值,而不是SQL语句的一部分。c. 示例:以下是使用
PreparedStatement和占位符参数插入数据的示例:
String sql = "INSERT INTO users (username, email) VALUES (?, ?)";
PreparedStatement pstmt = connection.prepareStatement(sql);
pstmt.setString(1, "John Doe");
pstmt.setString(2, "[email protected]");
pstmt.executeUpdate();
-
掌握事务相关理论与应用:
a. 原子性:事务中的一组操作要么全部成功,要么全部失败。如果事务过程中出现异常,需要回滚至事务开始之前的状态。
b. 隔离性:事务之间相互独立,一个事务的执行不会影响其他事务。
c. 持久性:一旦事务提交,对数据库的更改将永久保存。
d. 一致性:事务确保数据库从一个一致性状态转换到另一个一致性状态。
e. 示例:以下是使用JDBC进行事务控制的示例:
try {
connection.setAutoCommit(false);
// 执行一些数据库操作,如插入、更新、删除等
connection.commit();
} catch (Exception e) {
connection.rollback(); // 发生异常时回滚事务
} finally {
connection.setAutoCommit(true); // 恢复自动提交
}
-
掌握数据批处理:
a. 提高性能:批处理允许将多条SQL语句一起发送给数据库,从而减少了与数据库的通信开销,提高了执行效率。
b. 示例:以下是使用JDBC进行批处理操作的示例:
// 使用Statement进行批处理
Statement stmt = connection.createStatement();
stmt.addBatch("INSERT INTO users (username, email) VALUES ('Alice', '[email protected]')");
stmt.addBatch("INSERT INTO users (username, email) VALUES ('Bob', '[email protected]')");
int[] updateCounts = stmt.executeBatch();
// 使用PreparedStatement进行批处理
String sql = "INSERT INTO users (username, email) VALUES (?, ?)";
PreparedStatement pstmt = connection.prepareStatement(sql);
pstmt.setString(1, "Charlie");
pstmt.setString(2, "[email protected]");
pstmt.addBatch();
pstmt.setString(1, "David");
pstmt.setString(2, "[email protected]");
pstmt.addBatch();
int[] updateCounts2 = pstmt.executeBatch();
在实际应用中,使用JDBC技术时,还可以结合其他相关技术或工具来提高开发效率和程序性能。例如:
-
使用连接池:数据库连接池可以有效地管理数据库连接资源,提高应用程序的性能和伸缩性。常见的数据库连接池实现包括Apache DBCP、HikariCP和C3P0等。
-
结合ORM框架:对象关系映射(Object-Relational Mapping,ORM)框架可以将数据库中的表与Java类相映射,简化数据库操作的代码。常见的ORM框架包括Hibernate、MyBatis和JPA(Java Persistence API)等。
-
编写可维护的代码:为了确保代码的可读性和可维护性,需要编写结构清晰、命名规范、逻辑分明的代码。此外,编写注释和文档也有助于他人理解和维护代码。
-
使用Java EE技术:Java EE(Java Platform, Enterprise Edition)是一个用于开发企业级应用程序的平台,提供了许多与JDBC相关的技术和规范,如Java Persistence API(JPA)、Java Transaction API(JTA)等。
-
持续学习和实践:数据库技术和Java生态系统不断发展,掌握最新的技术和工具可以帮助您提高开发效率和解决实际问题。参加培训、阅读文档、订阅博客和论坛、参与开源项目等方式都有助于您提高技能。
以上是关于Java JDBC技术的一些建议和补充说明。希望这些信息对您有所帮助。如果您还有其他问题或需要进一步的解释,请随时在下面的评论中提问,看到后我会添加。
模块七、异常处理
-
异常与异常处理:
a. 异常(Exception)是程序运行过程中出现的错误或异常条件。Java异常分为两大类:受检异常(Checked Exception)和非受检异常(Unchecked Exception,包括运行时异常和错误)。
b. 受检异常需要在方法声明中通过throws关键字声明,或者在方法体内使用try-catch语句进行处理。
c. 非受检异常(如运行时异常)无需在方法声明中声明,也可以不处理,但建议使用try-catch语句进行处理以避免程序意外终止。
d.try-catch-finally语句是Java异常处理的基本结构。可以使用多个catch子句捕获不同类型的异常,并在finally子句中释放资源。 -
调试:
a. 调试是查找和修复代码中错误(Bug)的过程。可以使用集成开发环境(IDE)的调试功能进行调试,如断点、单步执行、查看变量值等。
b. 调试过程中可以使用日志记录(如使用Java标准库的java.util.logging或第三方库如Log4j)来帮助查找问题。
需要掌握的能力:
-
掌握异常相关知识:了解异常的分类,如受检异常和非受检异常;熟悉
try-catch-finally语句的使用;了解常见的Java异常类,如IOException、NullPointerException、ArrayIndexOutOfBoundsException等。 -
掌握对代码Bug调试:熟练使用IDE的调试功能,如设置断点、单步执行、查看变量值等;了解如何使用日志记录来帮助查找问题;学会阅读异常堆栈信息以定位问题。
除了上述关于异常处理的知识点和技能外,还有一些其他相关的概念和实践建议,如: -
自定义异常类:
a. 根据需要,您可以创建自定义异常类,以便更准确地表示特定问题。自定义异常类通常继承自
Exception类(受检异常)或RuntimeException类(非受检异常)。b. 在自定义异常类中,您可以覆盖构造函数以提供自定义的错误消息或其他属性。
-
异常处理最佳实践:
a. 仅捕获您能够处理的异常。对于那些您无法处理的异常,请让它们向上抛出,以便调用者或更高级别的错误处理机制能够处理。
b. 尽量避免“吞掉”异常,即捕获异常后不做任何处理。如果您确实需要忽略某个异常,请在捕获代码中添加注释,解释为什么可以忽略该异常。
c. 不要过度使用
catch (Exception e)这样的通用异常处理语句,因为它可能会捕获到意料之外的异常,导致问题难以定位。d. 及时关闭资源,如文件、数据库连接等。使用
try-with-resources语句可以自动关闭实现了AutoCloseable接口的资源。 -
使用Java 7+提供的多异常捕获功能:
Java 7引入了一种新的异常捕获语法,允许您在一个
catch子句中捕获多个异常类型。这可以简化代码并提高可读性。例如:
try {
// ...
} catch (IOException | SQLException e) {
// 处理IOException和SQLException的相同逻辑
}
模块八、字符串与字符串处理
-
String:
a.String类表示字符串,即字符序列。在Java中,字符串是不可变的,这意味着字符串对象的内容在创建后无法更改。
b. 使用+操作符或String.concat()方法连接字符串会创建新的字符串对象,这可能导致性能问题,尤其是在循环中进行大量字符串拼接时。
c.String类提供了许多有用的方法,如length()、charAt()、substring()、indexOf()、equals()等。 -
StringBuffer:
a.StringBuffer类表示可变的字符序列。与String不同,使用StringBuffer进行字符串操作时,不会创建新的对象,从而提高性能。
b.StringBuffer是线程安全的,因为它的大部分方法都是同步的(使用synchronized关键字)。
c.StringBuffer类提供了许多用于字符串操作的方法,如append()、insert()、delete()、replace()等。 -
StringBuilder:
a.StringBuilder类与StringBuffer类似,也表示可变的字符序列,提供了类似的方法进行字符串操作。
b. 与StringBuffer不同,StringBuilder不是线程安全的,因为它的方法没有使用synchronized关键字。因此,在单线程环境下,StringBuilder通常比StringBuffer具有更好的性能。
需要掌握的能力:
-
掌握字符串相关知识:了解
String类的特性,如不可变性;熟悉String类的常用方法;了解字符串拼接的性能影响。 -
掌握StringBuffer与StringBuilder的使用:了解
StringBuffer和StringBuilder的区别,如线程安全性和性能;熟悉StringBuffer和StringBuilder类的常用方法;根据实际需求选择合适的字符串处理类。
以下是StringBuffer和StringBuilder的使用示例:
StringBuffer stringBuffer = new StringBuffer();
stringBuffer.append("Hello, ");
stringBuffer.append("World!");
System.out.println(stringBuffer.toString());
StringBuilder stringBuilder = new StringBuilder();
stringBuilder.append("Hello, ");
stringBuilder.append("World!");
System.out.println(stringBuilder.toString());
-
字符串常量池:
a. 字符串常量池(String Constant Pool)是Java虚拟机中一个特殊的内存区域,用于存储字符串字面量和引用。
b. 当创建一个字符串字面量时,Java虚拟机会首先在字符串常量池中查找是否存在相同内容的字符串。如果存在,则返回对应的引用;否则,创建一个新的字符串并将其存储在字符串常量池中。
c. 使用new关键字创建的字符串对象不会进入字符串常量池。可以使用String.intern()方法将字符串对象添加到字符串常量池中。 -
字符串比较:
a. 使用==操作符比较字符串时,实际上是比较字符串对象的引用。要比较字符串的内容,应使用String.equals()方法。
b. 要忽略大小写比较字符串内容,可以使用String.equalsIgnoreCase()方法。 -
字符串编码与解码:
a. Java字符串内部使用Unicode字符集表示。当与外部系统(如文件、网络)交互时,需要将字符串编码为字节序列或从字节序列解码为字符串。
b. 可以使用String.getBytes(Charset)方法将字符串编码为指定字符集的字节序列;使用new String(byte[], Charset)构造函数将字节序列解码为指定字符集的字符串。 -
正则表达式:
a. Java提供了java.util.regex包,支持正则表达式的处理,如匹配、查找、替换等。
b.String.matches()方法可以检查字符串是否匹配给定的正则表达式。
c.Pattern和Matcher类提供了更高级的正则表达式处理功能,如分组、查找所有匹配等。