识别参考循环
当GC启动时,它在第一个链接列表中拥有所有要扫描的容器对象。目标是移动所有无法到达的对象。由于大多数对象都是可访问的,因此移动不可访问的对象要有效得多,因为这需要更少的指针更新。
每个支持垃圾收集的对象都将有一个额外的引用计数字段,该字段在算法启动时初始化为该对象的引用计数(图中的gc_ref)。这是因为算法需要修改引用计数来进行计算,这样解释器就不会修改实际引用计数字段。
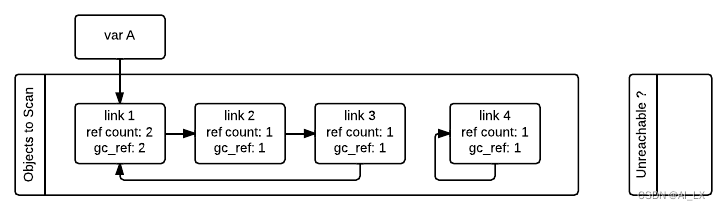
然后,GC遍历第一个列表中的所有容器,并将容器引用的任何其他对象的GC_ref字段减一。这样做可以利用容器类中的tp_traverse槽(使用C API实现或由超类继承)来了解每个容器引用的对象。扫描完所有对象后,只有从“要扫描的对象”列表外部引用的对象的gc_refs>0。
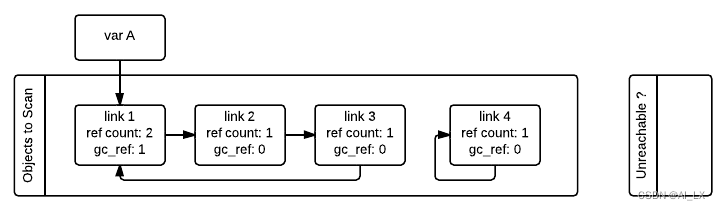
请注意,gc_refs==0并不意味着对象不可访问。这是因为从外部可访问的另一个对象(gc_refs>0)仍然可以引用它。例如,我们示例中的link_2对象以gc_refs==0结尾,但仍然被从外部可到达的link_1对象引用。为了获得一组真正无法访问的对象,垃圾收集器使用tp_traverse槽重新扫描容器对象;这次使用了一个不同的遍历函数,它将gcrefs==0的对象标记为“暂时不可访问”,然后将它们移动到暂时不可到达的列表中。下图描述了当GC处理了link_3和link_4对象但尚未处理link_1和link_2时列表的状态。
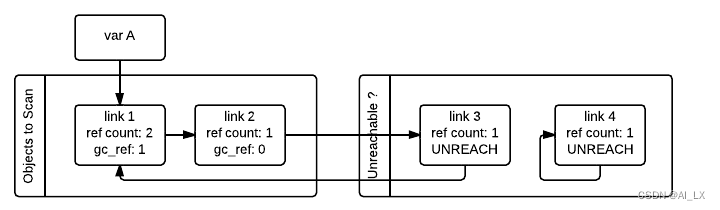
然后GC扫描下一个link_1对象。因为它具有gc_refs==1,gc不会做任何特殊的事情,因为它知道它必须是可访问的(并且已经在可访问列表中):
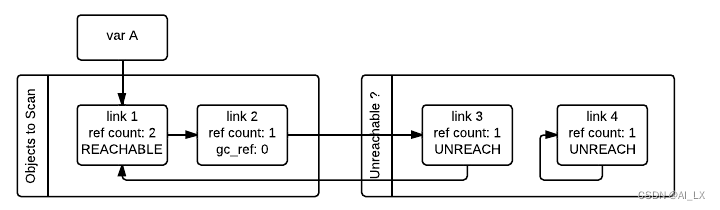
当GC遇到一个可访问的对象(GC_refs>0)时,它使用tp_traverse槽遍历其引用,以找到从它可访问的所有对象,将它们移动到可访问对象列表的末尾(它们最初开始的位置),并将其GC_refs字段设置为1。这是下面链接2和链接3的情况,因为它们可以从链接1访问。从上一个图像中的状态,在检查了link_1引用的对象之后,GC知道link_3毕竟是可访问的,因此它被移回原始列表,其GC_refs字段被设置为1,这样如果GC再次访问它,它就会知道它是可访问。为了避免访问一个对象两次,GC标记所有已经访问过一次的对象(通过取消设置PREV_MASK_COLLECTING标志),这样,如果已经处理过的对象被其他对象引用,GC就不会处理它两次。
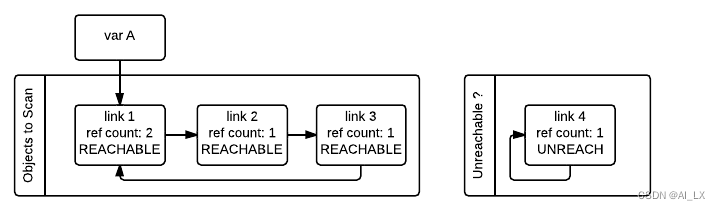 请注意,垃圾收集器将再次访问标记为“暂时不可访问”并随后移回可访问列表的对象,因为现在也需要处理该对象的所有引用。这个过程实际上是对对象图的广度优先搜索。一旦扫描完所有对象,GC就知道暂时无法访问列表中的所有容器对象都是无法访问的,因此可以进行垃圾收集。
请注意,垃圾收集器将再次访问标记为“暂时不可访问”并随后移回可访问列表的对象,因为现在也需要处理该对象的所有引用。这个过程实际上是对对象图的广度优先搜索。一旦扫描完所有对象,GC就知道暂时无法访问列表中的所有容器对象都是无法访问的,因此可以进行垃圾收集。
实际上,需要注意的是,任何一种方法都不需要递归,也不需要与对象数量、指针数量或指针链长度成比例的额外内存。除了满足内部C需求的O(1)存储外,对象本身包含GC算法所需的所有存储。
为什么移动无法访问的对象更好
在大多数对象通常是可访问的前提下移动不可访问的对象听起来很合乎逻辑,直到你想一想:它付出的代价其实并不明显。
假设我们按顺序创建对象A、B、C。他们以同样的顺序出现在年轻一代中。如果B指向A,C指向B,C可以从外部到达,那么在算法运行的第一步之后,调整后的引用计数将分别为0、0和1,因为从外部唯一可以到达的对象是C。
当算法的下一步找到A时,A被移动到不可访问列表。第一次遇到B时也是如此。然后遍历C,将B移回可访问列表。最终遍历B,然后将A移回可访问列表。
因此,可到达的对象B和A都会移动两次,而不是完全不移动。为什么这是一场胜利?相反,移动可到达对象的简单算法将移动A、B和C各一次。关键是这种舞蹈将物体按C、B、A的顺序排列,这与原来的顺序相反。在所有后续扫描中,它们都不会移动。由于大多数对象不在循环中,这可以在以后的集合中节省无限数量的移动。唯一一次成本可能更高的是第一次扫描链条。
正在销毁无法访问的对象
一旦GC知道了不可访问对象的列表,一个非常微妙的过程就开始于完全销毁这些对象的目标。大致上,流程遵循以下步骤:
处理和清理薄弱参考(如有)。如果不可访问集合中的对象将被销毁,并且具有带有回调的弱引用,则需要执行这些回调。这个过程非常微妙,因为任何错误都可能导致处于不一致状态的对象被重新激活或由回调调用的某些Python函数访问。此外,还属于不可访问集的弱引用(对象及其弱引用处于不可访问的循环中)需要立即清除,而不执行回调。否则,它将在稍后调用tp_clear插槽时触发,从而造成破坏。忽略弱引用的回调是可以的,因为对象和weakref都将消失,所以说弱引用将首先消失是合理的。
如果某个对象具有旧的终结器(tp_del槽),请将它们移动到gc.garbage列表中。
调用终结器(tp_finalize slot)并将对象标记为已完成,以避免在它们重新启动或其他终结器已首先删除对象时调用它们两次。
处理复活的物体。如果某些对象已经复活,GC将通过再次运行循环检测算法找到仍然无法访问的新对象子集,并继续执行这些操作。
调用每个对象的tp_clear槽,使所有内部链接断开,引用计数降至0,从而触发所有不可访问对象的销毁。
一旦GC知道了不可访问对象的列表,一个非常微妙的过程就开始于完全销毁这些对象的目标。大致上,流程遵循以下步骤:
处理和清理薄弱参考(如有)。如果不可访问集合中的对象将被销毁,并且具有带有回调的弱引用,则需要执行这些回调。这个过程非常微妙,因为任何错误都可能导致处于不一致状态的对象被重新激活或由回调调用的某些Python函数访问。此外,还属于不可访问集的弱引用(对象及其弱引用处于不可访问的循环中)需要立即清除,而不执行回调。否则,它将在稍后调用tp_clear插槽时触发,从而造成破坏。忽略弱引用的回调是可以的,因为对象和weakref都将消失,所以说弱引用将首先消失是合理的。
如果某个对象具有旧的终结器(tp_del槽),请将它们移动到gc.garbage列表中。
调用终结器(tp_finalize slot)并将对象标记为已完成,以避免在它们重新启动或其他终结器已首先删除对象时调用它们两次。
处理复活的物体。如果某些对象已经复活,GC将通过再次运行循环检测算法找到仍然无法访问的新对象子集,并继续执行这些操作。
调用每个对象的tp_clear槽,使所有内部链接断开,引用计数降至0,从而触发所有不可访问对象的销毁。
优化:世代
为了限制每次垃圾收集所需的时间,GC使用了一种流行的优化:生成。这个概念背后的主要思想是假设大多数对象的寿命很短,因此可以在创建后不久收集。事实证明,这与许多Python程序的实际情况非常接近,因为许多临时对象的创建和销毁速度非常快。对象越老,它越不可能变得无法访问。
为了利用这一事实,所有容器对象都被划分为三个空间/代。每个新对象都从第一代(第0代)开始。上一个算法仅在特定世代的对象上执行,如果某个对象在其世代的集合中存活下来,它将被移动到下一代(第1代),在那里,它将不太频繁地进行收集调查。如果同一个对象在新一代(第1代)的另一轮GC中存活下来,它将被移动到上一代(2代),在那里它将被检查的次数最少。
为了决定何时运行,收集器会跟踪自上次收集以来对象分配和释放的数量。当分配数减去释放数超过threshold_0时,收集开始。最初只检查0代。如果自检查了第1代以来,第0代已检查了超过阈值1次,则也检查第1代。对于第二代来说,事情有点复杂;有关详细信息,请参阅收集最旧的一代。可以使用gc.get_threshold()函数检查这些阈值:
为了限制每次垃圾收集所需的时间,GC使用了一种流行的优化:生成。这个概念背后的主要思想是假设大多数对象的寿命很短,因此可以在创建后不久收集。事实证明,这与许多Python程序的实际情况非常接近,因为许多临时对象的创建和销毁速度非常快。对象越老,它越不可能变得无法访问。
为了利用这一事实,所有容器对象都被划分为三个空间/代。每个新对象都从第一代(第0代)开始。上一个算法仅在特定世代的对象上执行,如果某个对象在其世代的集合中存活下来,它将被移动到下一代(第1代),在那里,它将不太频繁地进行收集调查。如果同一个对象在新一代(第1代)的另一轮GC中存活下来,它将被移动到上一代(2代),在那里它将被检查的次数最少。
为了决定何时运行,收集器会跟踪自上次收集以来对象分配和释放的数量。当分配数减去释放数超过threshold_0时,收集开始。最初只检查0代。如果自检查了第1代以来,第0代已检查了超过阈值1次,则也检查第1代。对于第二代来说,事情有点复杂;有关详细信息,请参阅收集最旧的一代。可以使用gc.get_threshold()函数检查这些阈值:
import gc
gc.get_threshold()
(700, 10, 10)
可以使用gc.get_objects(generation=NUM)函数检查这些代的内容,并且可以通过调用gc.collect(generation=NUM)在一代中专门触发集合。
import gc
class MyObj:
pass
# Move everything to the last generation so it's easier to inspect
# the younger generations.
gc.collect()
0
# Create a reference cycle.
x = MyObj()
x.self = x
# Initially the object is in the youngest generation.
gc.get_objects(generation=0)
[..., <__main__.MyObj object at 0x7fbcc12a3400>, ...]
# After a collection of the youngest generation the object
# moves to the next generation.
gc.collect(generation=0)
0
gc.get_objects(generation=0)
[]
gc.get_objects(generation=1)
[..., <__main__.MyObj object at 0x7fbcc12a3400>, ...]
收集最古老的一代
除了各种可配置阈值之外,如果long_lived_pending/long_lived_total比率高于给定值(硬连线为25%),GC仅触发最旧一代的完整集合。原因是,虽然“非完整”集合(即年轻一代和中年一代的集合)将始终检查大致相同数量的对象(由上述阈值确定),但完整集合的成本与长寿命对象的总数成比例,这实际上是无限的。事实上,有人指出,每创建一个<常量>的对象就进行一次完整的收集,这会导致工作负载的性能急剧下降,因为工作负载包括创建和存储大量的长期对象(例如,构建一个GC跟踪对象的大列表将显示二次性能,而不是预期的线性性能)。相反,使用上述比率,会产生对象总数的摊销线性性能(其效果可以这样总结:“随着对象数量的增加,每次完整的垃圾收集成本越来越高,但我们做的垃圾越来越少”)。