XXL-JOB调度源码学习(一)- 调度器是怎么调度执行器的
带着疑问
- 执行器的阻塞策略是什么回事,调度器的路由策略又是什么情况?
- 单机窜行执行器会不会并发执行任务?
- 报错了是调度器重新调度还是执行器自己调度?
- Xxljob注解后为什么就可以调度了?
测试代码
长耗时代码
/**
* 1、简单任务示例(Bean模式)
*/
@XxlJob("demoJobHandler")
public void demoJobHandler() throws Exception {
XxlJobHelper.log("XXL-JOB, Hello World.");
for (int i = 0; i < 50; i++) {
XxlJobHelper.log("beat at:" + i);
TimeUnit.SECONDS.sleep(5);
}
// default success
}
实验架构
一个调度器,两个执行器

官方特性说明
1. 高级配置:
2. - 路由策略:当执行器集群部署时,提供丰富的路由策略,包括;
3. FIRST(第一个):固定选择第一个机器;
4. LAST(最后一个):固定选择最后一个机器;
5. ROUND(轮询):;
6. RANDOM(随机):随机选择在线的机器;
7. CONSISTENT_HASH(一致性HASH):每个任务按照Hash算法固定选择某一台机器,且所有任务均匀散列在不同机器上。
8. LEAST_FREQUENTLY_USED(最不经常使用):使用频率最低的机器优先被选举;
9. LEAST_RECENTLY_USED(最近最久未使用):最久未使用的机器优先被选举;
10. FAILOVER(故障转移):按照顺序依次进行心跳检测,第一个心跳检测成功的机器选定为目标执行器并发起调度;
11. BUSYOVER(忙碌转移):按照顺序依次进行空闲检测,第一个空闲检测成功的机器选定为目标执行器并发起调度;
12. SHARDING_BROADCAST(分片广播):广播触发对应集群中所有机器执行一次任务,同时系统自动传递分片参数;可根据分片参数开发分片任务;
13. - 子任务:每个任务都拥有一个唯一的任务ID(任务ID可以从任务列表获取),当本任务执行结束并且执行成功时,将会触发子任务ID所对应的任务的一次主动调度。
14. - 调度过期策略:
15. - 忽略:调度过期后,忽略过期的任务,从当前时间开始重新计算下次触发时间;
16. - 立即执行一次:调度过期后,立即执行一次,并从当前时间开始重新计算下次触发时间;
17. - 阻塞处理策略:调度过于密集执行器来不及处理时的处理策略;
18. 单机串行(默认):调度请求进入单机执行器后,调度请求进入FIFO队列并以串行方式运行;
19. 丢弃后续调度:调度请求进入单机执行器后,发现执行器存在运行的调度任务,本次请求将会被丢弃并标记为失败;
20. 覆盖之前调度:调度请求进入单机执行器后,发现执行器存在运行的调度任务,将会终止运行中的调度任务并清空队列,然后运行本地调度任务;
21. - 任务超时时间:支持自定义任务超时时间,任务运行超时将会主动中断任务;
22. - 失败重试次数;支持自定义任务失败重试次数,当任务失败时将会按照预设的失败重试次数主动进行重试;
下面针对单机串行,先分析执行器如何实现单机串行的
路由策略:第一个,阻塞处理策略:单机串行
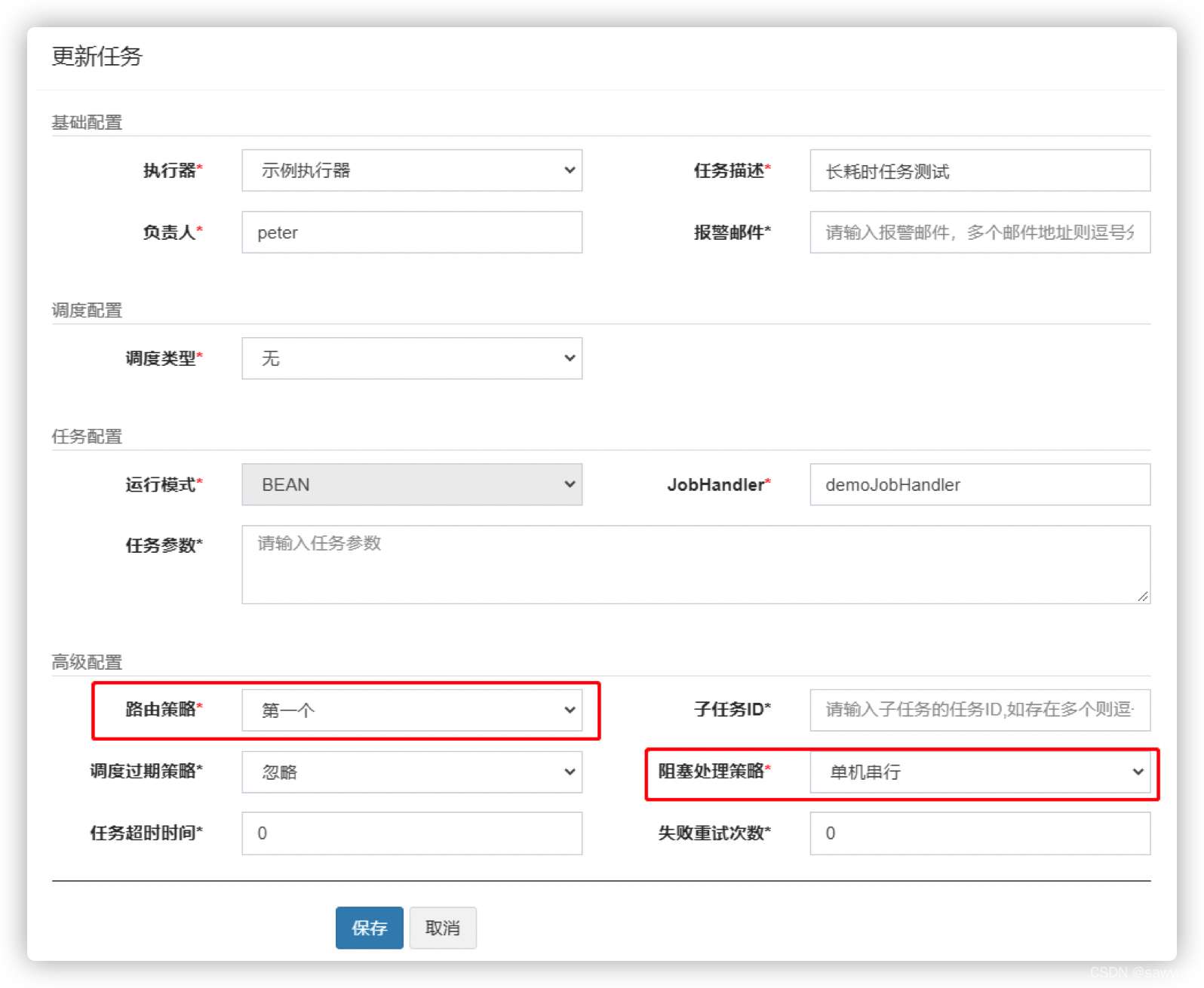
路由策略第一个多次运行任务,永远都是同一个机器实例在执行代码,如果相同的job, 则会队列化FIFO执行

执行器代码分析
调度器是怎么调用执行器的,理解这个,需要先理解执行器是怎么接收运行指令
- 新建
XxlJobConfig项目配置类,new XxlJobSpringExecutor(),初始化配置属性, 返回XxlJobSpringExecutor的bean
2.XxlJobSpringExecutor实现SmartInitializingSingleton接口的afterSingletonsInstantiated方法,执行时机是在bean初始化完毕后执行
3.XxlJobSpringExecutor@afterSingletonsInstantiated初始化任务initJobHandlerMethodRepository,扫描所有的applicationContext中的bean,只要包含了xxljob注解的方法, 最后存入到jobHandlerRepository中,以便调度器后续从中取出回调
4.XxlJobSpringExecutor@afterSingletonsInstantiated调用父类方法XxlJobExecutor@start方法,方法内部会调用EmbedServer@start,该方法会启用一个守护线程,也就是执行器内嵌的netty-http-server,线程服务都由EmbedHttpServerHandler处理
5.EmbedHttpServerHandler继承SimpleChannelInboundHandler,重写channelRead0方法即可处理调度器请求,channelRead0中把请求数据都交给EmbedHttpServerHandler@process方法处理,根据调度器的请求地址和参数执行对应的处理,如心跳检测,任务运行,获取日志等
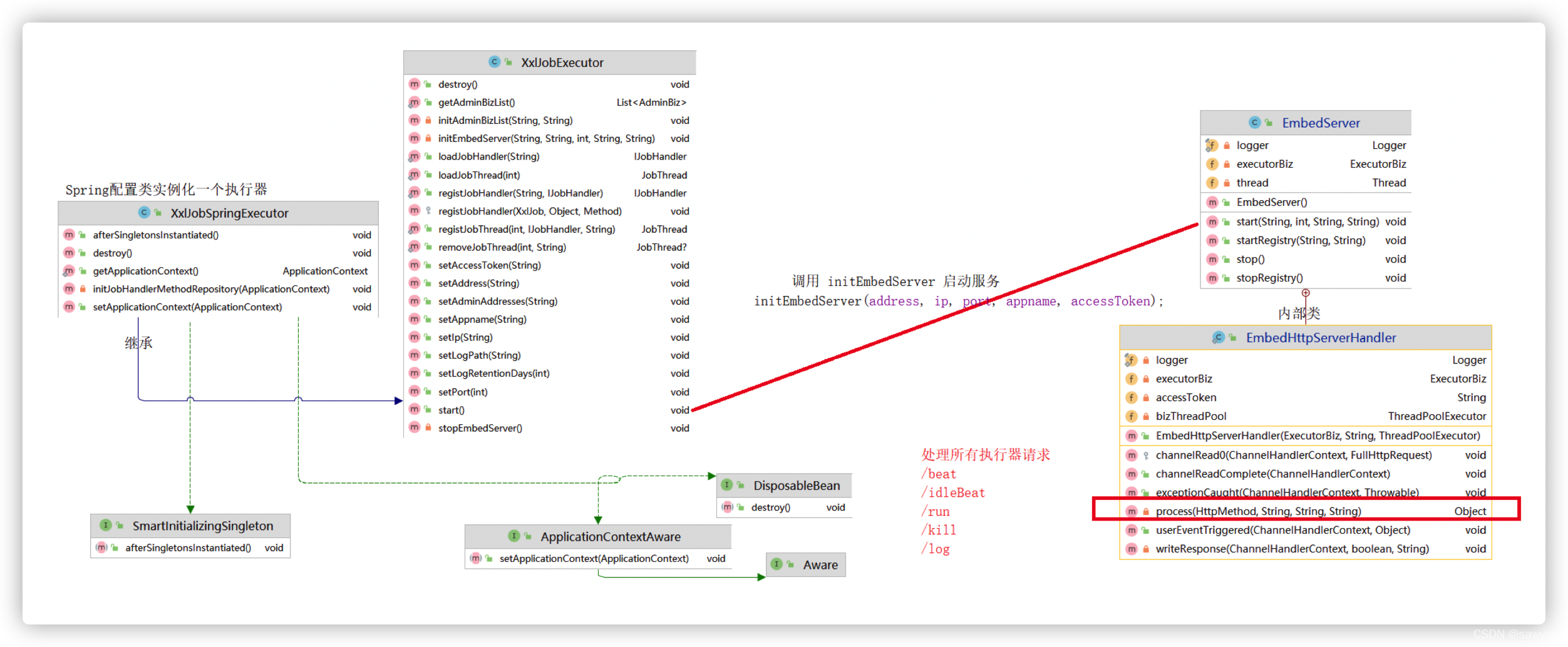
可以看得出来EmbedHttpServerHandler@process就是执行器得核心逻辑了
在这里就可以理解什么阻塞处理策略的单机串行,丢弃后续调度,覆盖之前调度。
说白了,他们不过是单个实例内部的线程操作
现在我们尝试一下理解这个过程
第一步,执行器通过EmbedHttpServerHandler@process接收到调度器的运行指令,从而调用executorBiz@run
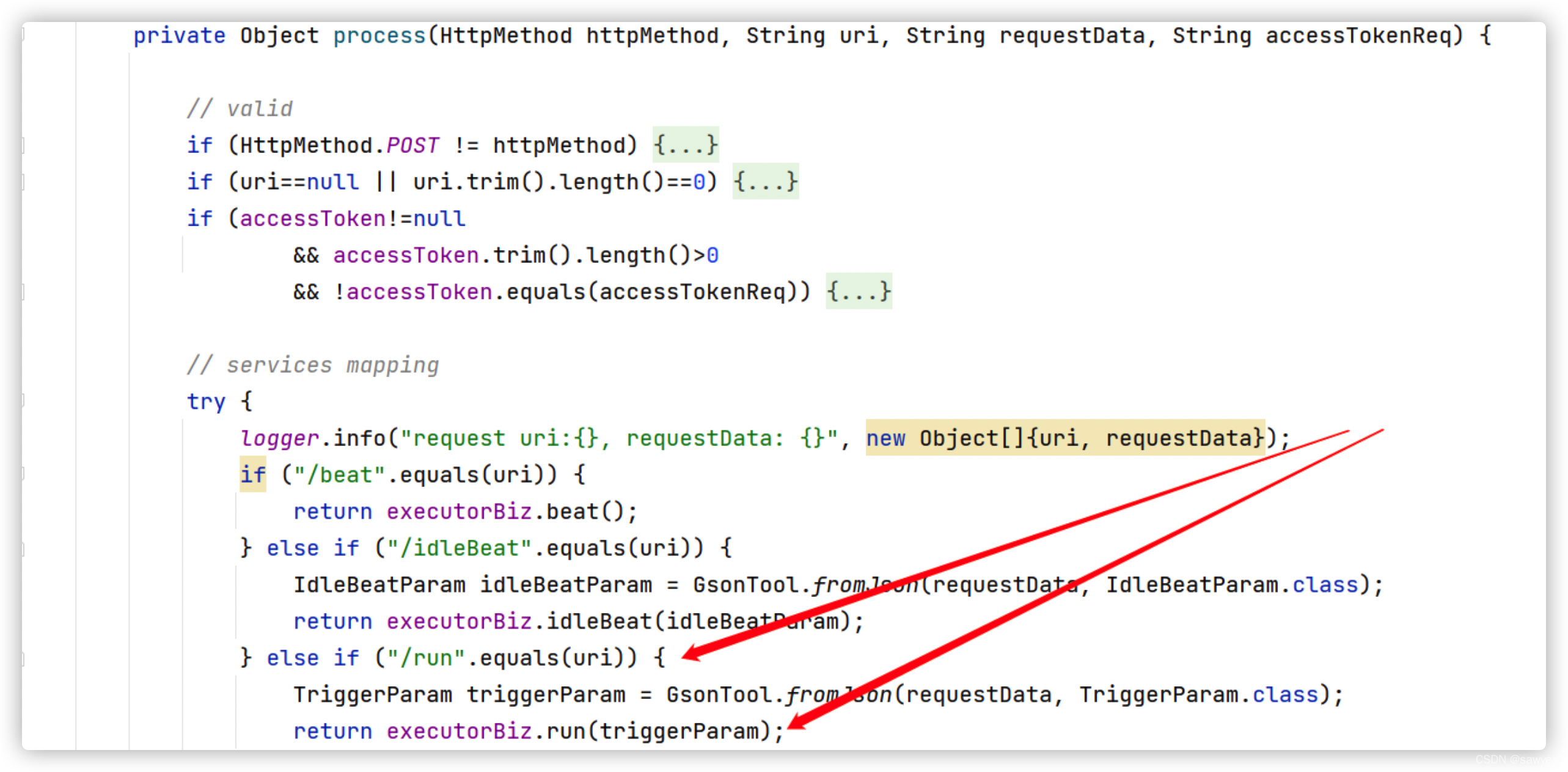
ExecutorBizImpl是ExecutorBiz实现类,负责执行器核心处理逻辑
这里我们能看见一个很关键的类jobThread

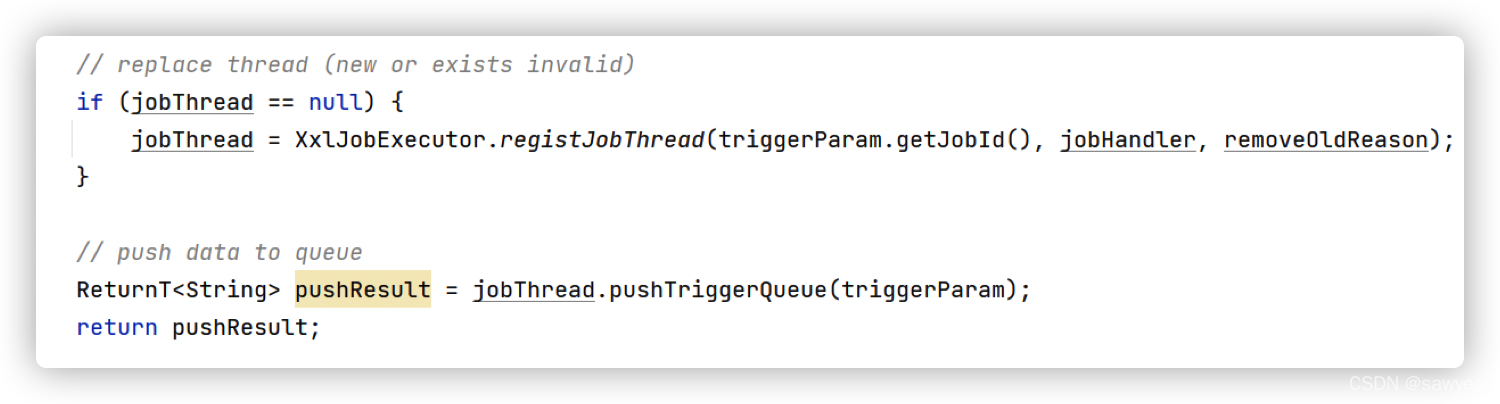
上图,你需要留意两个代码
第一个,XxlJobExecutor.registJobThread这里说的是 jobThread 线程 开始注册到jobThreadRepository且启动了jobThread线程,同一个jobid在同一个执行器内有且只有一个对应的jobThread线程(jobThreadRepository负责保持jobid和线程的映射关系),线程启动后run方法会一直消费内部队列triggerQueue,什么时候结束消费?答案是连续从队列triggerQueue获取消费数据,连续30次,每次超时时间3秒,也就是90s后线程会自销毁线程结束且移除jobThreadRepository中的映射关系
第二个,jobThread.pushTriggerQueue(triggerParam) 把数据扔进队列即可,为 jobThread线程 triggerQueue 添加任务,任务保存在,也就是所谓的单机串行
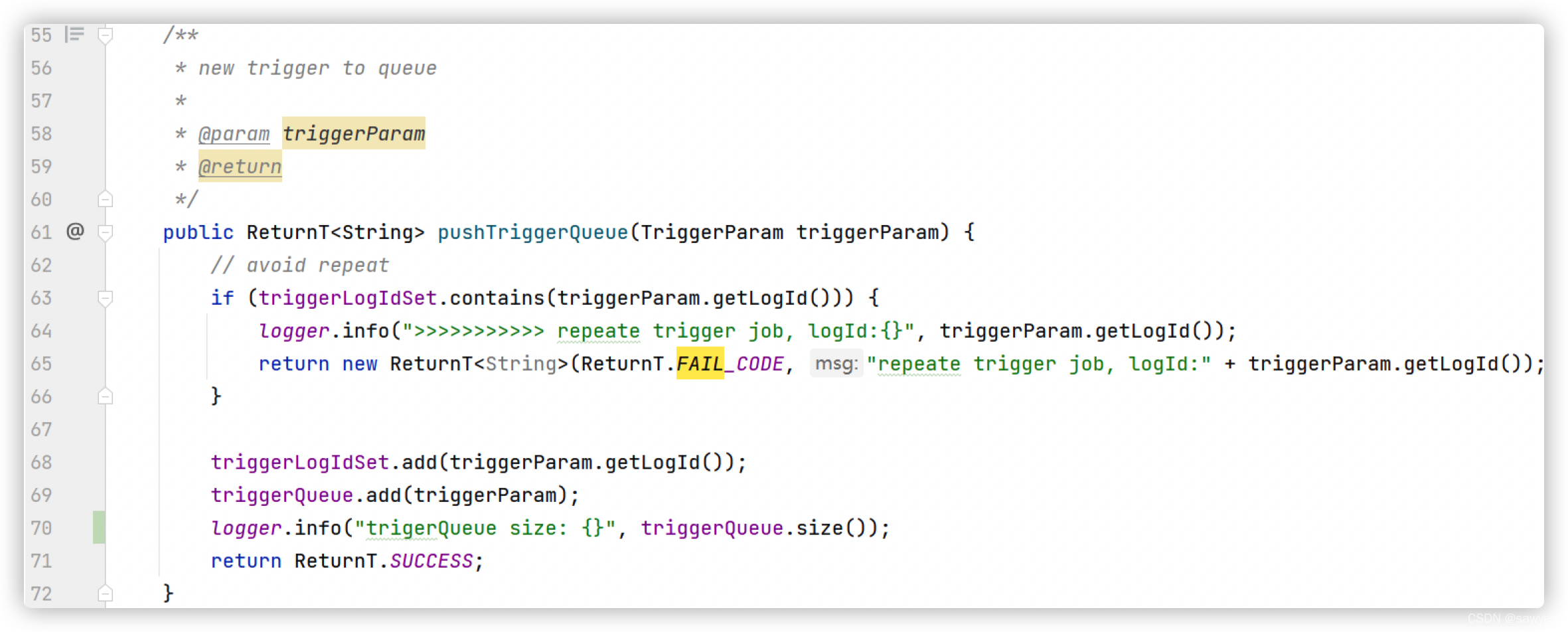
这里就需要介绍执行器的核心之一JobThread.triggerQueue
这是一个无界队列,而且是每个JobThread线程对象独立一份,同一个jobid在同一个执行器内有且只有一个对应的jobThread线程,从而保证各自任务的单机串行,不同的任务是多线程的JobThread,各自维护 triggerQueue
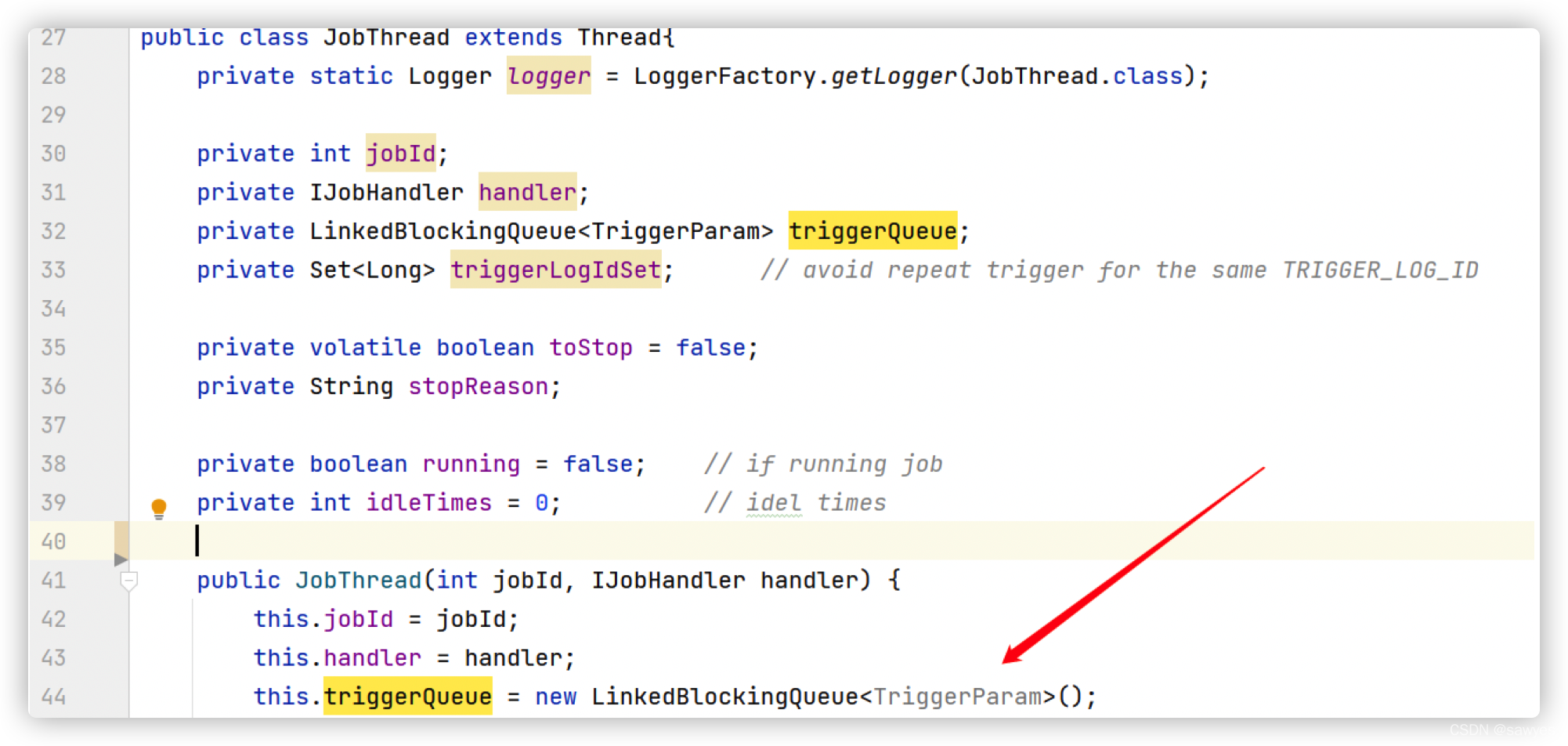
结论1
通过上面代码分析,我们在回头看看,同一个任务ID,经过路由策略第一个,总是把任务分配到同一个执行器,然后存储到triggerQueue队列

结论2
报错了的任务,根据配置重试,由调度器重新触发分发给执行器(不是执行器自己重试的),通过在执行器的/run接口断点调试可以证明
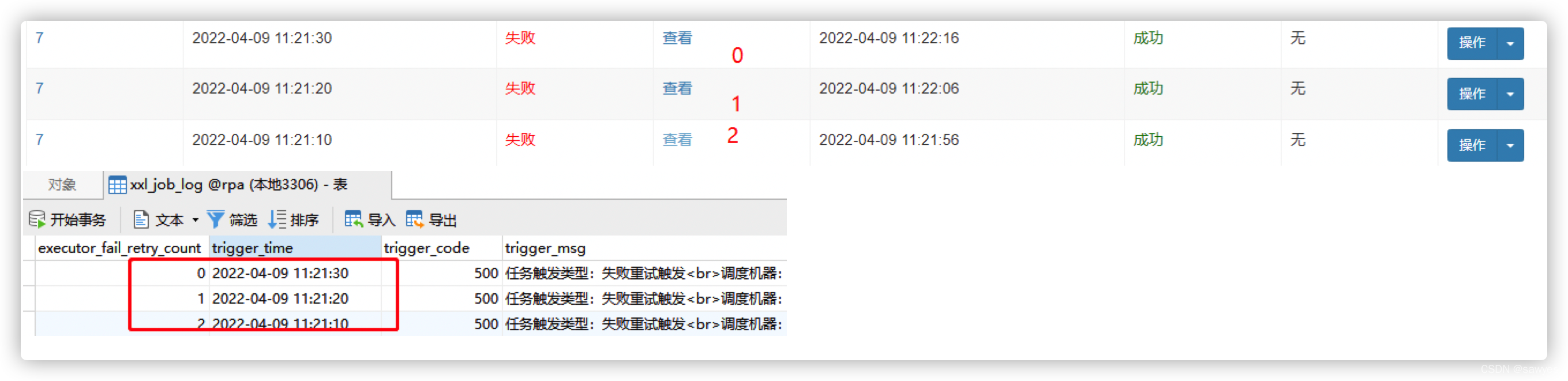
结论3
同一个执行器内的同一个job是不可能并发的,因为数据一定会乱
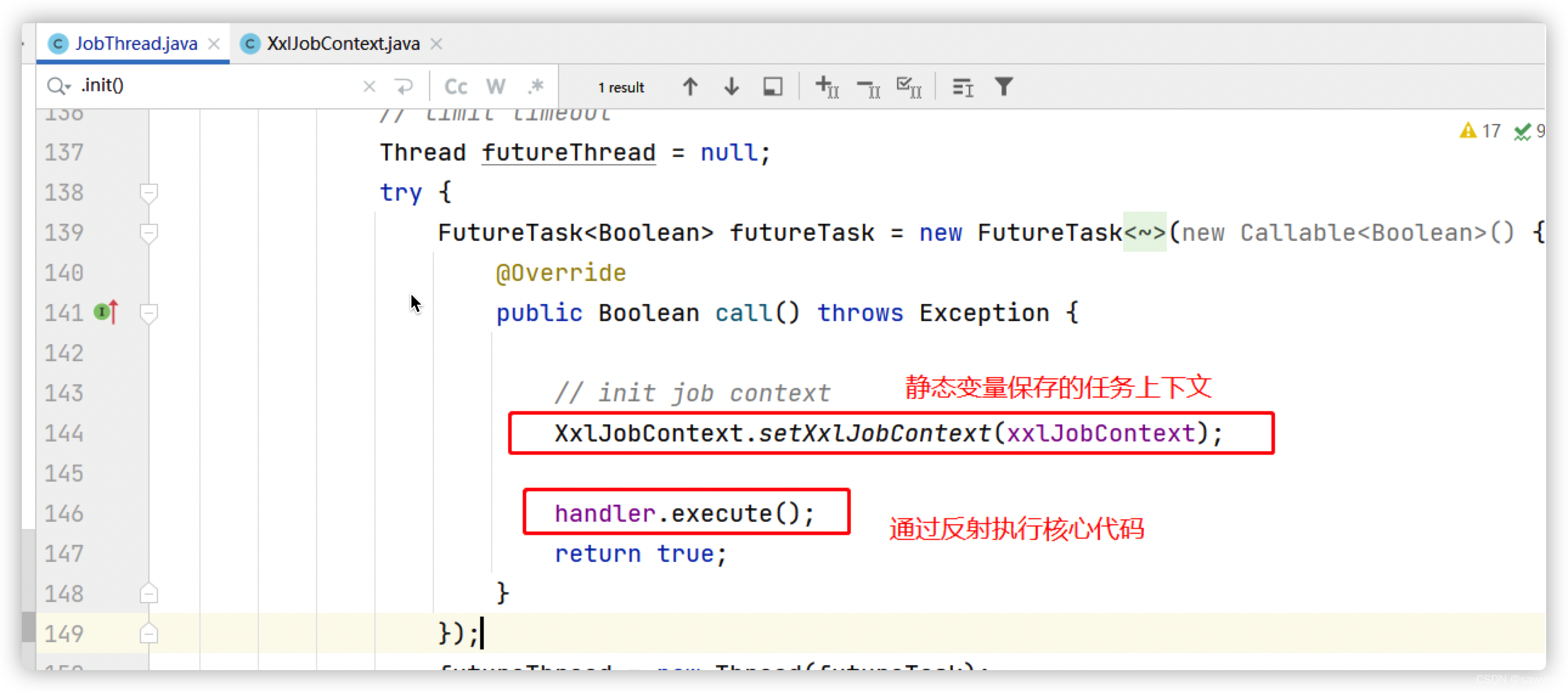
从静态变量可以判断出同一个执行器同一个Job不可能会并发,因为线程肯定是不安全的