AI大模型落地加速还会远吗?首个完全量化Vision Transformer的方法FQ-ViT
本文重新审视了完全量化的Vision Transformer,并将精度下降归因于LayerNorm输入的严重通道间变化,提出了Power-of-Two Factor(PTF),一种简单而有效的后训练方法,可以在只有一个分层量化尺度的情况下对LayerNorm输入实现精确量化。
模型量化显著降低了模型推理的复杂性,并已被广泛用于现实应用的部署。然而,大多数现有的量化方法主要是在卷积神经网络(CNNs)上开发的,当应用于全量化的Vision Transformer时,会出现严重的退化。
在这项工作中证明了这些困难中的许多是由于LayerNorm输入中的严重通道间变化而出现的,并且提出了Power-of-Two Factor(PTF),这是一种减少全量化Vision Transformer性能退化和推理复杂性的系统方法。此外,观察到注意力图中的极端非均匀分布,提出了Log Int Softmax(LIS)来维持这一点,并通过使用4位量化和BitShift算子来简化推理。
在各种基于Transformer的架构和基准测试上进行的综合实验表明,全量化Vision Transformer(FQ-ViT)在注意力图上使用更低的位宽的同时,也优于以前的工作。例如,在ImageNet上使用ViT-L达到84.89%的Top-1准确率,在COCO上使用Cascade Mask R-CNN(SwinS)达到50.8 mAP。据所知是第1个在全量化的Vision Transformer上实现无损精度下降(~1%)的算法。
Github地址:https://github.com/megvii-research/FQ-ViT
基于Transformer的架构在各种计算机视觉(CV)任务中取得了具有竞争力的性能,包括图像分类、目标检测、语义分割等。与CNN的同类架构相比,Transformer通常具有更多的参数和更高的计算成本。例如,ViT-L具有307M参数和190.7G FLOP,在经过大规模预训练的ImageNet中达到87.76%的准确率。然而,当部署到资源受限的硬件设备时,基于Transformer的架构的大量参数和计算开销带来了挑战。
为了便于部署,已经提出了几种技术,包括架构设计的量化、剪枝、蒸馏和自适应。在本文中重点关注量化技术,并注意到剪枝、蒸馏和架构自适应与本文的工作正交,并且可以组合。
大多数现有的量化方法都是在神经网络上设计和测试的,并且缺乏对转化子特异性构建的适当处理。先前的工作发现,在量化Vision Transformer的LayerNorm和Softmax时,精度显著下降。在这种情况下,模型没有完全量化,导致需要在硬件中保留浮点单元,这将带来巨大的消耗,并显著降低推理速度。
因此,重新审视了Vision Transformer的这2个专属模块,并发现了退化的原因:
-
首先,作者发现LayerNorm输入的通道间变化严重,有些通道范围甚至超过中值的40倍。传统方法无法处理如此大的激活波动,这将导致很大的量化误差。
-
其次,作者发现注意力图的值具有极端的不均匀分布,大多数值聚集在0~0.01之间,少数高注意力值接近1。
基于以上分析,作者提出了Power-of-Two Factor(PTF)来量化LayerNorm的输入。通过这种方式,量化误差大大降低,并且由于Bit-Shift算子,整体计算效率与分层量化的计算效率相同。
此外,还提出了Log Int Softmax(LIS),它为小值提供了更高的量化分辨率,并为Softmax提供了更有效的整数推理。结合这些方法,本文首次实现了全量化Vision Transformer的训练后量化。

如图1所示,本文的方法显著提高了全量化Vision Transformer的性能,并获得了与全精度对应算法相当的精度。
本文的贡献有4方面:
-
重新审视了完全量化的Vision Transformer,并将精度下降归因于LayerNorm输入的严重通道间变化。同时,观察到注意力图的极端不均匀分布,导致量化误差。
-
提出了Power-of-Two Factor(PTF),这是一种简单而有效的后训练方法,可以在只有一个分层量化尺度的情况下对LayerNorm输入实现精确量化。
-
提出了Log Int Softmax(LIS),这是一种可以对注意力图执行4-bit量化的新方法。使用LIS,可以将注意力映射存储在一个激进的低位上,并用Bit-Shift运算符代替乘法。在Softmax模块上实现了仅整数推理,显著降低了推理消耗。
-
使用各种基于Transformer的架构对图像分类和目标检测进行了广泛的实验。结果表明,全量化Vision Transformer具有8位权重/激活和4位注意力映射,可以实现与浮点版本相当的性能。
相关工作
Vision Transformer
最近,基于Transformer的体系结构在CV任务中显示出巨大的威力。基于ViT的新兴工作证明了分类、检测和分割等所有视觉任务的有效性。新提出的Swin Transformer在几乎传统的CV任务上甚至超过了最先进的神经网络,呈现出强大的Transformer表达和泛化能力。
然而,这些高性能的Vision Transformer归因于大量的参数和高计算开销,限制了它们的采用。因此,设计更小、更快的Vision Transformer成为一种新趋势。LeViT通过下采样、Patch描述符和注意力MLP块的重新设计,在更快的推理方面取得了进展。DynamicViT提出了一个动态Token稀疏化框架,以逐步动态地修剪冗余Token,实现竞争复杂性和准确性的权衡。Evo-ViT提出了一种快速更新机制,该机制可以保证信息流和空间结构,从而降低训练和推理的复杂性。虽然上述工作侧重于高效的模型设计,但本文在量化的思路上提高了压缩和加速。
模型量化
目前的量化方法可以分为两类:量化感知训练(QAT)和训练后量化(PTQ)。
QAT依赖于训练来实现低比特(例如2比特)量化和有希望的性能,而它通常需要高水平的专家知识和巨大的GPU资源来进行训练或微调。为了降低上述量化成本,无训练的PTQ受到了越来越广泛的关注,并出现了许多优秀的作品。OMSE建议通过最小化量化误差来确定激活的值范围。AdaRound提出了一种新的舍入机制来适应数据和任务损失。
除了上述针对神经网络的工作外,Liu等人还提出了一种具有相似性感知和秩感知策略的Vision Transformer训练后量化方法。然而,这项工作没有量化Softmax和LayerNorm模块,导致量化不完整。在本文的FQ-ViT中,目标是在PTQ范式下实现精确、完全量化的Vision Transformer。
本文方法
在本节中将详细介绍所提出的方法。首先,在第3.1节中,提出了网络量化的初步结果。然后在第3.2和3.3节中,分析了全量化Vision Transformer退化的原因,并提出了两种新的量化方法,Power-of-Two Factor(PTF)和Log-Int-Softmax(LIS)。
准备工作

1、Uniform Quantization
 2、Log2 Quantization
2、Log2 Quantization
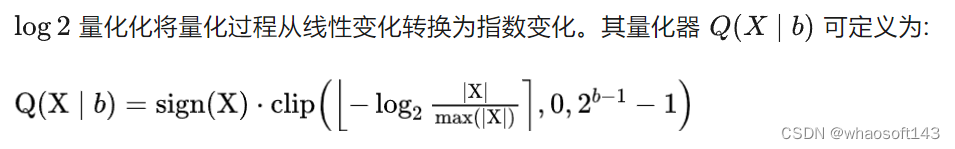 在本文中,为了实现一个全量化的Vision Transformer,本文量化了所有模块的量化,包括Conv、Linear、MatMul、LayerNorm、Softmax等。特别是对Conv、Linear和MatMul模块采用均匀的MinMax量化,对LayerNorm和Softmax采用以下方法。
在本文中,为了实现一个全量化的Vision Transformer,本文量化了所有模块的量化,包括Conv、Linear、MatMul、LayerNorm、Softmax等。特别是对Conv、Linear和MatMul模块采用均匀的MinMax量化,对LayerNorm和Softmax采用以下方法。
LayerNorm量化的Power-of-Two Factor
 图2显示了最后一个LayerNorm层中的通道激活范围。此外,还展示了ResNets的案例进行比较。考虑到ResNets中没有LayerNorm,选择相同位置的激活(第4阶段的输出)来展示。
图2显示了最后一个LayerNorm层中的通道激活范围。此外,还展示了ResNets的案例进行比较。考虑到ResNets中没有LayerNorm,选择相同位置的激活(第4阶段的输出)来展示。
可以观察到,与ResNets相比,Vision Transformer中的通道范围波动更大。例如,ResNet152的最大范围/中值范围仅为21.6/4.2,而在Swin-B中则上升到622.5/15.5。基于这种极端的通道间变化,将相同的量化参数应用于所有通道的逐层量化将导致不可容忍的量化误差。一种可能的解决方案是使用分组量化或通道量化,其将不同的量化参数分配给不同的组或通道。然而,这些仍然会导致浮点域中的均值和方差的计算,从而导致较高的硬件开销。





2、LayerNorm的量化实现
class QIntLayerNorm(nn.LayerNorm):
def __init__(self, normalized_shape, eps=1e-5, elementwise_affine=True):
super(QIntLayerNorm, self).__init__(normalized_shape, eps,
elementwise_affine)
assert isinstance(normalized_shape, int)
self.mode = 'ln'
def get_MN(self, x):
bit = 8
N = torch.clamp(bit - 1 - torch.floor(torch.log2(x)), 0, 31)
M = torch.clamp(torch.floor(x * torch.pow(2, N)), 0, 2 ** bit - 1)
return M, N
def forward(self,
x,
in_quantizer=None,
out_quantizer=None,
in_scale_expand=1):
if self.mode == 'ln':
x = F.layer_norm(x, self.normalized_shape, self.weight, self.bias,
self.eps)
elif self.mode == 'int':
in_scale = in_quantizer.scale
if in_scale_expand != 1:
in_scale = in_scale.unsqueeze(-1).expand(
-1, in_scale_expand).T.reshape(-1)
out_scale = out_quantizer.scale
assert in_scale is not None and out_scale is not None
channel_nums = x.shape[-1]
in_scale = in_scale.reshape(1, 1, -1)
out_scale = out_scale.reshape(1, 1, -1)
x_q = (x / in_scale).round()
in_scale1 = in_scale.min()
in_scale_mask = (in_scale / in_scale1).round()
x_q = x_q * in_scale_mask
mean_x_q = x_q.mean(dim=-1) * in_scale1
std_x_q = (in_scale1 / channel_nums) * torch.sqrt(
channel_nums * (x_q**2).sum(dim=-1) - x_q.sum(dim=-1)**2)
A = (in_scale1 / std_x_q).unsqueeze(-1) * \
self.weight.reshape(1, 1, -1) / out_scale
A_sign = A.sign()
M, N = self.get_MN(A.abs())
B = ((self.bias.reshape(1, 1, -1) -
(mean_x_q / std_x_q).unsqueeze(-1) *
self.weight.reshape(1, 1, -1)) / out_scale *
torch.pow(2, N)).round()
x_q = ((A_sign * M * x_q + B) / torch.pow(2, N)).round()
x = x_q * out_scale
else:
raise NotImplementedError
return x
用于Softmax量化的Log Int Softmax
多头自注意力(MSA)是基于Transformer的架构中最重要的组件之一,但由于Token数量的二次复杂性,即图像分辨率除以Patch size,它被认为是资源最密集的组件。随着模型性能被证明受益于更高的分辨率和更小的Patch size,当分辨率增加和Patch size减小时,注意力图的存储和计算成为瓶颈,直接影响推理的吞吐量和延迟。因此,更小的注意力映射和更高效的推理成为迫切需要。
1、Attention Map的Log2量化
为了将注意力映射压缩到较小的大小并加快推理速度,将注意力映射量化到较低的位宽。当实验用均匀量化将注意力图从8位量化到4位时,所有的Vision Transformer都表现出严重的性能下降。
例如,在具有4位均匀量化注意力图的ImageNet上,DeiT-T仅导致8.69%的top-1准确率,比8位情况降低了63.05%。
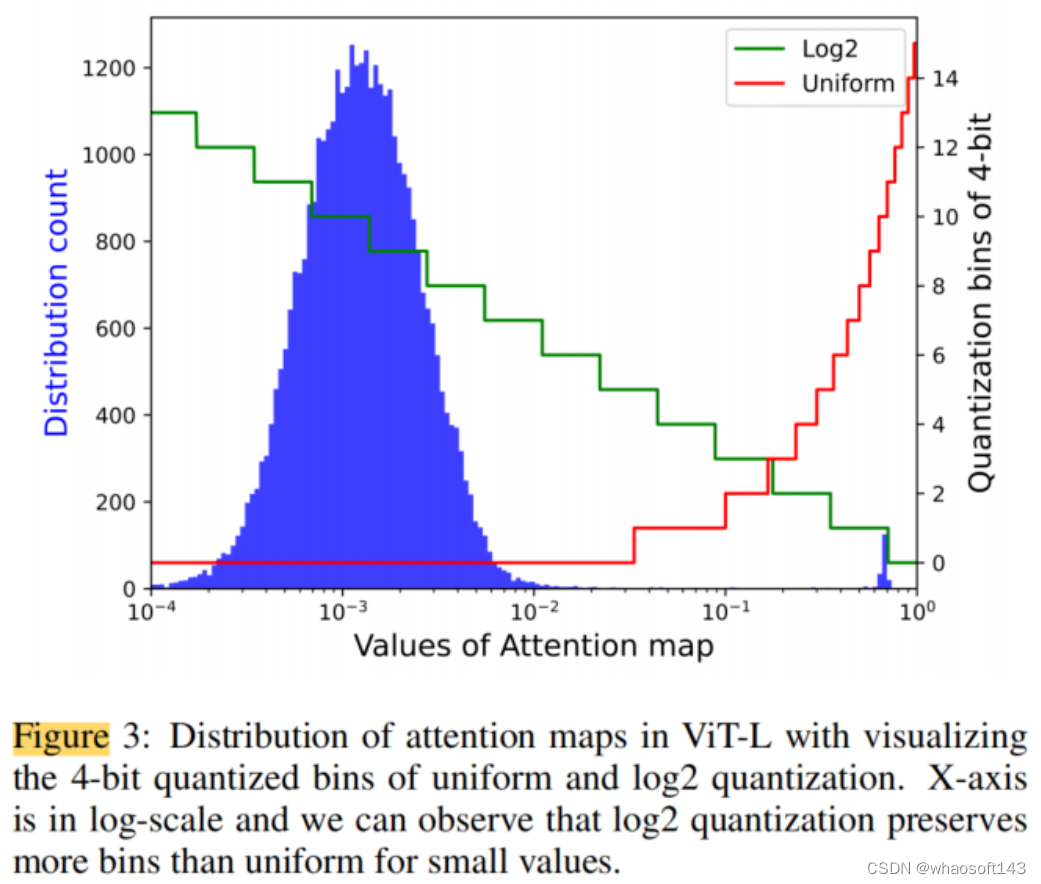 受DynamicViT中稀疏注意力思想的启发,作者探讨了注意力图的分布,如图3所示。观察到以一个相当小的值为中心的分布,而只有少数异常值具有接近1的较大值。对ViT-L中的所有注意力图进行平均,约98.8%的值小于1/16。与只为这么多值分配1个bin的4位均匀量化相比,log2方法可以为它们分配12个bin。
受DynamicViT中稀疏注意力思想的启发,作者探讨了注意力图的分布,如图3所示。观察到以一个相当小的值为中心的分布,而只有少数异常值具有接近1的较大值。对ViT-L中的所有注意力图进行平均,约98.8%的值小于1/16。与只为这么多值分配1个bin的4位均匀量化相比,log2方法可以为它们分配12个bin。





3、Integer-only推理
先前的工作选择不量化Softmax,因为Softmax中计算量的可忽略性和量化可能导致精度显著下降。然而,数据在CPU和GPU/NPU之间移动,进行去量化和再量化,会给硬件设计带来很大困难,这是一个不可忽视的消耗。
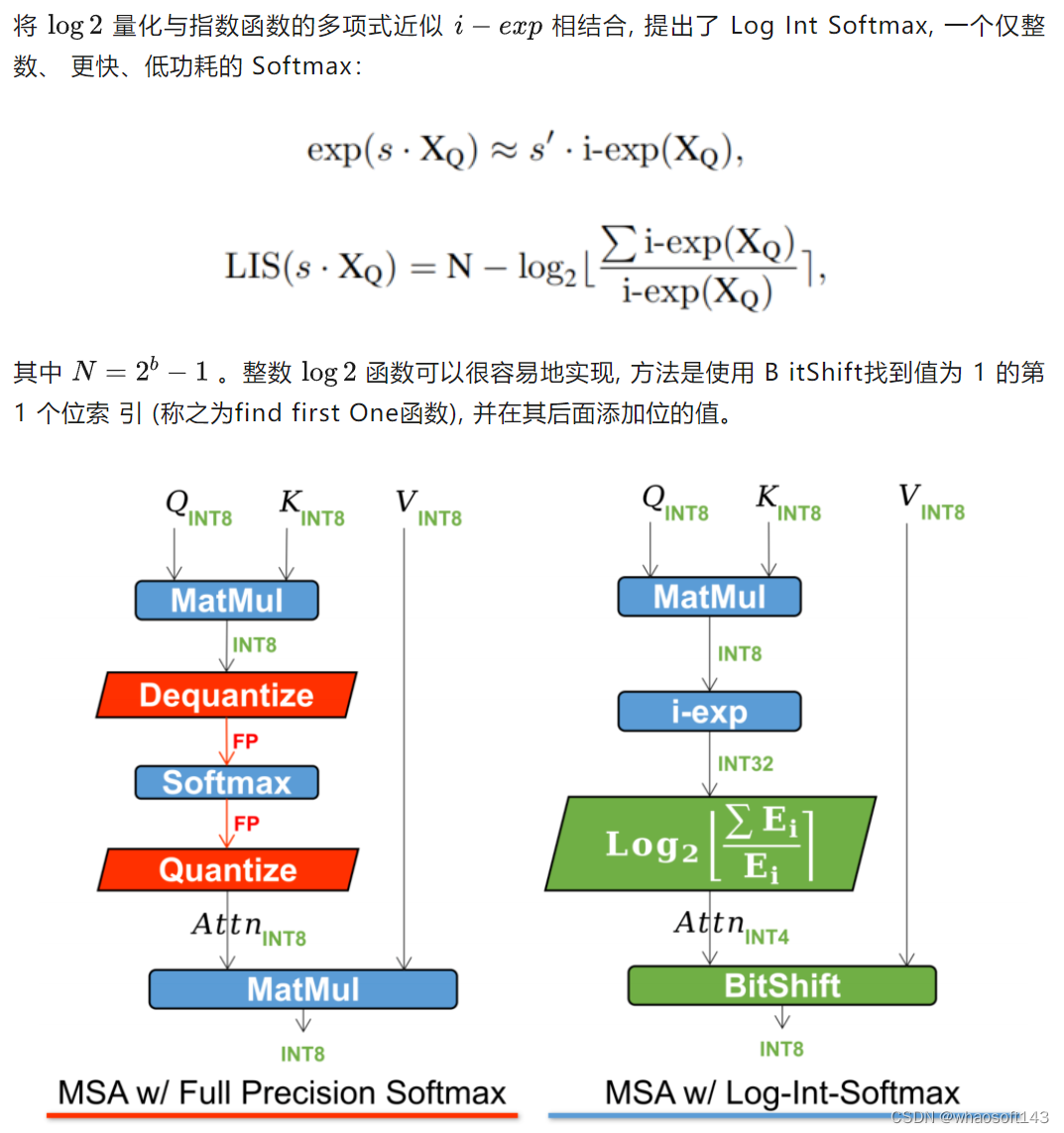

当采用Log IntSoftmax时,如右侧所示,整个数据类型可以是纯整数,并单独计算和并行计算量化尺度。值得注意的是,LIS在注意力图上使用4位表示,这显著减少了内存占用。
4、Softmax的量化的实现
class QIntSoftmax(nn.Module):
def __init__(self,
log_i_softmax=False,
quant=False,
calibrate=False,
last_calibrate=False,
bit_type=BIT_TYPE_DICT['int8'],
calibration_mode='layer_wise',
observer_str='minmax',
quantizer_str='uniform'):
super(QIntSoftmax, self).__init__()
self.log_i_softmax = log_i_softmax
self.quant = quant
self.calibrate = calibrate
self.last_calibrate = last_calibrate
self.bit_type = bit_type
self.calibration_mode = calibration_mode
self.observer_str = observer_str
self.quantizer_str = quantizer_str
self.module_type = 'activation'
self.observer = build_observer(self.observer_str, self.module_type,
self.bit_type, self.calibration_mode)
self.quantizer = build_quantizer(self.quantizer_str, self.bit_type,
self.observer, self.module_type)
@staticmethod
def log_round(x):
x_log_floor = x.log2().floor()
big = x_log_floor
extra_mask = (x - 2**big) >= 2**(big - 1)
big[extra_mask] = big[extra_mask] + 1
return big
@staticmethod
def int_softmax(x, scaling_factor):
def int_polynomial(x_int, scaling_factor):
coef = [0.35815147, 0.96963238, 1.] # ax**2 + bx + c
coef[1] /= coef[0]
coef[2] /= coef[0]
b_int = torch.floor(coef[1] / scaling_factor)
c_int = torch.floor(coef[2] / scaling_factor**2)
z = x_int + b_int
z = x_int * z
z = z + c_int
scaling_factor = coef[0] * scaling_factor**2
return z, scaling_factor
def int_exp(x_int, scaling_factor):
x0 = -0.6931 # -ln2
n = 30 # sufficiently large integer
x0_int = torch.floor(x0 / scaling_factor)
x_int = torch.max(x_int, n * x0_int)
q = torch.floor(x_int / x0_int)
r = x_int - x0_int * q
exp_int, exp_scaling_factor = int_polynomial(r, scaling_factor)
exp_int = torch.clamp(torch.floor(exp_int * 2**(n - q)), min=0)
scaling_factor = exp_scaling_factor / 2**n
return exp_int, scaling_factor
x_int = x / scaling_factor
x_int_max, _ = x_int.max(dim=-1, keepdim=True)
x_int = x_int - x_int_max
exp_int, exp_scaling_factor = int_exp(x_int, scaling_factor)
exp_int_sum = exp_int.sum(dim=-1, keepdim=True)
return exp_int, exp_int_sum
def forward(self, x, scale):
if self.log_i_softmax and scale is not None:
exp_int, exp_int_sum = self.int_softmax(x, scale)
softmax_out = torch.round(exp_int_sum / exp_int)
rounds = self.log_round(softmax_out)
mask = rounds >= 2**self.bit_type.bits
qlog = torch.clamp(rounds, 0, 2**self.bit_type.bits - 1)
deq_softmax = 2**(-qlog)
deq_softmax[mask] = 0
return deq_softmax
else:
x = x.softmax(dim=-1)
if self.calibrate:
self.quantizer.observer.update(x)
if self.last_calibrate:
self.quantizer.update_quantization_params(x)
if not self.quant:
return x
x = self.quantizer(x)
return x
实验
Image Classification on ImageNet
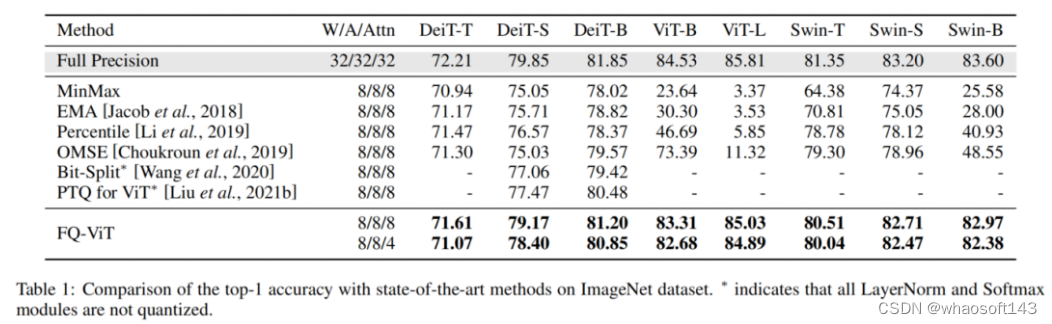 为了证明所提出的方法的有效性,作者在ImageNet中使用各种Vision Transformer进行了广泛的实验,即ViT、DeiT、Swin Transformer。
为了证明所提出的方法的有效性,作者在ImageNet中使用各种Vision Transformer进行了广泛的实验,即ViT、DeiT、Swin Transformer。
表1中报告了Top-1的准确度结果。很明显,目前所有的方法都无法捕捉到完全量化的Vision Transformer,而FQ-ViT做到了这一点,即使在注意力图上的比特非常低,也能实现几乎无损的量化。同时,FQ-ViT显著超过了ViT的PTQ,其LayerNorm和Softmax没有量化。
例如,在所有模块量化为8位的情况下,FQ-ViT在DeiT-B上实现了81.20%的准确率,并且当注意力图压缩为4位时,它仍然可以实现80.85%的准确率。
Object Detection on COCO

作者还对目标检测基准COCO进行了实验。选择Swin系列检测器进行实验,结果见表2。可以观察到,所有当前的方法在完全量化的检测器上都具有较差的性能。FQ-ViT显著提高了量化精度,并在Mask R-CNN(Swin-S)上实现了47.2mAP,在Cascade Mask R-CNN上实现了50.8mAP,在权重/激活上实现了8位,在注意力图上实现了4位。
消融实验
 为了研究本文中PTF和LIS的效果,作者在各种策略下对ViTB进行了充分量化,并在表3中报告了结果。作者设计了两个基线。”Baseline#8”索引模型由MinMax完全量化,具有8位权重、激活和注意力图,而“Baseline#4”在注意力图上具有较低的位宽(4位)。
为了研究本文中PTF和LIS的效果,作者在各种策略下对ViTB进行了充分量化,并在表3中报告了结果。作者设计了两个基线。”Baseline#8”索引模型由MinMax完全量化,具有8位权重、激活和注意力图,而“Baseline#4”在注意力图上具有较低的位宽(4位)。
从结果来看有几个观察结果。首先,具有PTF和LIS的模型优于基线,并实现了几乎无损的精度。其次,得益于BitShift运算符,PTF只引入了少量的BitOP,而LIS则减少了这一数量。
可视化结果
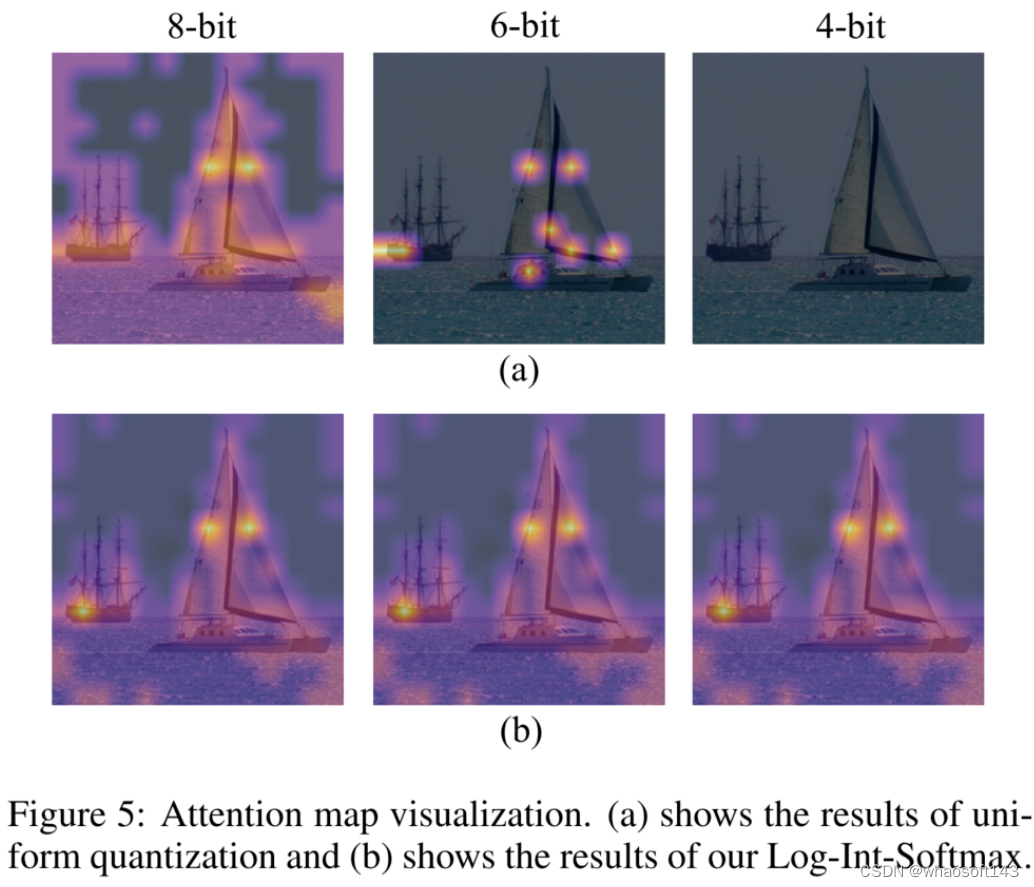 作者将注意力图可视化,以查看均匀量化和LIS之间的差异,如图5所示。当两者都使用8位时,均匀量化集中在高激活区域,而LIS在低激活区域保留更多纹理,这保留了注意力图的更多相对秩。在8位的情况下,这种差异不会产生太大的差异。然而,当量化到较低的位宽时,如6位和4位的情况所示,均匀量化会急剧退化,甚至使所有关注区域失效。相反,LIS仍然表现出类似于8位的可接受性能。
作者将注意力图可视化,以查看均匀量化和LIS之间的差异,如图5所示。当两者都使用8位时,均匀量化集中在高激活区域,而LIS在低激活区域保留更多纹理,这保留了注意力图的更多相对秩。在8位的情况下,这种差异不会产生太大的差异。然而,当量化到较低的位宽时,如6位和4位的情况所示,均匀量化会急剧退化,甚至使所有关注区域失效。相反,LIS仍然表现出类似于8位的可接受性能。