问题描述:
已知句子按行存放在.txt记事本中,现在想要实现对句子进行解析(获取词性,依存关系分析,头节点),按照下图格式存放在json文件中。
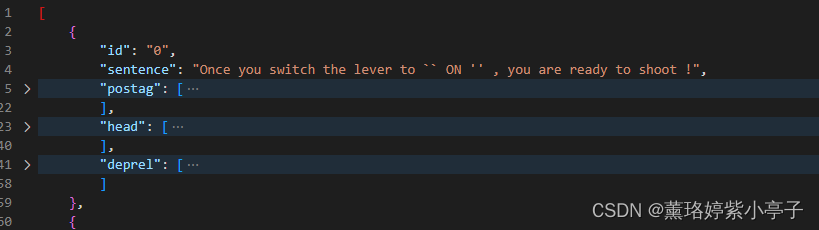
其中,postag中存放的是对sentence进行词性标注之后的结果,head存放的是依存关系解析,当前token对应的头, deprel存放的是依存关系解析标签。
问题解决:
import json
import stanza
file_txt = "/data/qtxu/EMCGCN-ASTE-main/data_COQE/Camera-COQE/test_only_sentence.txt"
file_json = "/data/qtxu/EMCGCN-ASTE-main/data_COQE/Camera-COQE/test_vocab.json"
def get_tags2(tags1):
'''
将通过staza进行词性标注的结果,进行重新排序标注
'''
count_dict = {}
tags2 = []
for tag in tags1:
if tag not in count_dict:
count_dict[tag] = 0
tags2.append(f"{count_dict[tag]}-{tag}")
count_dict[tag] += 1 if tag not in {'PART', 'PUNCT','ADV','DET', 'SYM', 'SPACE'} else 0 # 扣除一些不常见的词语,不参与计数
return tags2
stanza.download('en')
nlp_en = stanza.Pipeline('en')
def get_params(sentence, nlp):
en_doc = nlp(sentence)
postag = []
head = []
deprel = []
for i, sent in enumerate(en_doc.sentences):
# print("[Sentence {}]".format(i+1))
for word in sent.words:
postag.append(word.pos)
head.append(word.head)
deprel.append(word.deprel)
return postag, head, deprel
with open(file_txt, "r") as fr:
sentences = [line.strip() for line in fr.readlines()] # 存放在list中
# Function one : format[{……},{……}]
data = []
for num in range(len(sentences)):
dict_ = {}
dict_['id'] = str(num)
dict_['sentence'] = sentences[num]
# pos, dep = get_pos_and_dep(sentences[num], nlp_en)
pos, head, deprel = get_params(sentences[num], nlp_en)
dict_['postag'] = get_tags2(pos)
dict_['head'] = head
dict_['deprel'] = deprel
data.append(dict_)
with open(file_json, 'w+') as fw:
json.dump(data, fw, separators=(',', ':'))
# Fucntion two: format:{
{},{},{}}
# dict_ = {}
# for num in range(len(sentences)):
# dict_params = {}
# pos, head, deprel = get_params(sentences[num], nlp_en)
# dict_params['postag'] = get_tags2(pos)
# dict_params['head'] = head
# dict_params['deprel'] = deprel
# dict_[str(sentences[num])] = dict_params
# with open(file_json, 'w+') as fw:
# json.dump(dict_, fw, separators=(',', ':'))
print("task ending!!!")