maskrcnn代码:链接:https://pan.baidu.com/s/1d20yy6PRKojqKLDW_gB3-A
提取码:1vob
各个TensorFlow对应的python Keras 版本
cuda版本对应的python
其实如果你用CPU版本的就不需要考虑cuda和cudnn
但是如果你用GPU版本的话就好安装配置cuda和cudnn了
网上教程也很多可以自行学习本文主要是CPU的maskrcnn的环境
好 那么开始
第一就是各个版本对应的python版本,可以参照下面的图
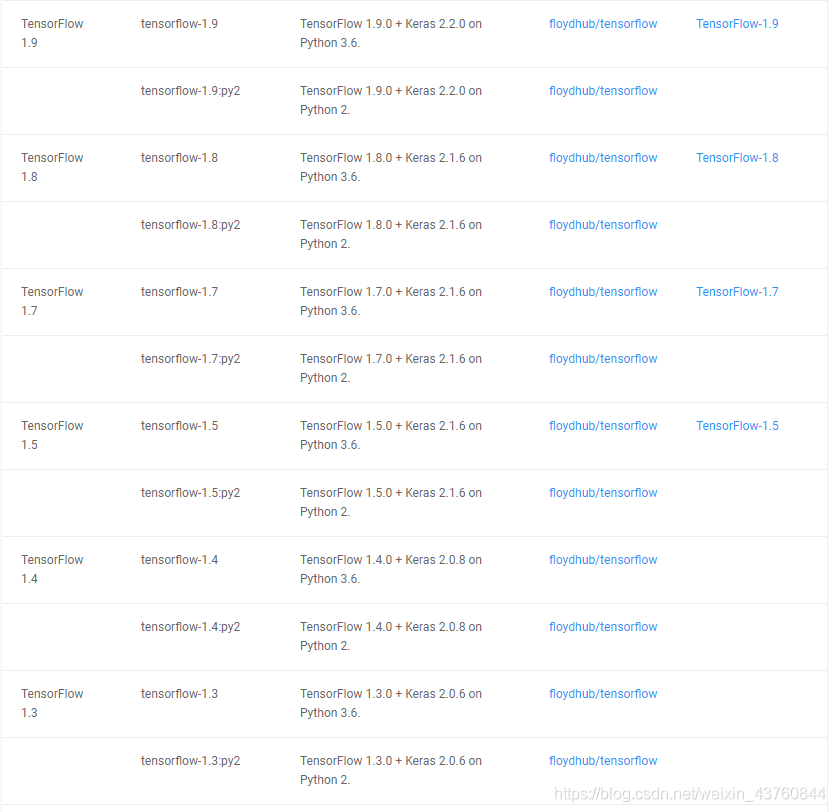
建议,python是3.5,TensorFlow1.5.0,Keras 2.1.6,否则代码可能报错
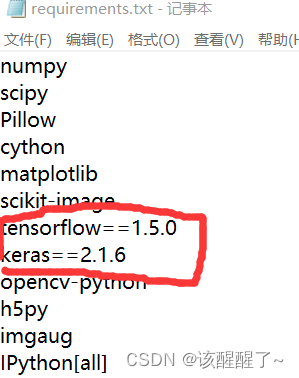
一些依赖包在代码requirements.txt文件中有可以直接pip安装 其他库都可以用pip安装,如果慢的话可以加一个国内的清华镜像 但是注意requirements.txt这个文件中也带有TensorFlow和Keras
如果你手动安装了这两个库,那就要先去文件中把这两个删掉,否则如有冲突,然后报错
pip install TensorFlow==1.5.0 -i https://pypi.tuna.tsinghua.edu.cn/simple现在开始训练数据集
训练自己数据的步骤:
- :安装Labelme
- pip install labelme
- Pip install pyqt5
- Pip install pillow==4.0.0
- :标注数据
- 使用labelme得到json标注文件
- 使用命令labelme_json_to_dataset 1.json得到json文件夹
- 也可以用批处理脚本得到所有json文件夹
- 得到4个文件夹标注信息
- :代码中需要改动的地方:
- NUM_CLASSES:表示类别的个数
- self.add_class("shapes", 1, "category1") 添加标签中定义的类别
- 指定好路径(数据集的路径)
- 在train_test.py 里修改自己的数据集路径
dataset_root_path="mydata/"
img_floder = dataset_root_path + "pic"
mask_floder = dataset_root_path + "cv2_mask"
imglist = os.listdir(img_floder)
count = len(imglist)
- DETECTION_MIN_CONFIDENCE 指定的稍微小一点可以得到更多结果
- :训练之后测试结果
- 先得到.h5的模型文件
- 然后在test_model.py里修改自己的权重文件然后进行预测
- 此代码是预测路径中随机选取一张图片进行预测然后用终端进行展示,如果想预测所有的图片就需要改代码,如下:
# Load a random image from the images folder # file_names = next(os.walk(IMAGE_DIR))[2] # image = skimage.io.imread(os.path.join(IMAGE_DIR, random.choice(file_names))) count = os.listdir(IMAGE_DIR) for i in range(0,len(count)): path = os.path.join(IMAGE_DIR, count[i]) if os.path.isfile(path): file_names = next(os.walk(IMAGE_DIR))[2] image = skimage.io.imread(os.path.join(IMAGE_DIR, count[i])) # Run detection results = model.detect([image], verbose=1) r = results[0] visualize.display_instances(i,count[i],image, r['rois'], r['masks'], r['class_ids'], class_names, r['scores']) print("len",len(count)) # a=datetime.now() # # Run detection # results = model.detect([image], verbose=1) # b=datetime.now() # # Visualize results # print("time:",(b-a).seconds) # r = results[0] # print (r) # visualize.display_instances(image, r['rois'], r['masks'], r['class_ids'], # class_names, r['scores'])在预测代码中的最后一行有一些需要注释掉
-
还有打开visualLiza.py文件修改
-
if auto_show: # plt.savefig(r"D:\PYTTC\pythonProject\mask rcnn_test\save\mask100") # plt.show() # if auto_show: ###############保存预测结果图像 fig = plt.gcf() fig.set_size_inches(width / 100.0, height / 100.0) # 输出原始图像width*height的像素 plt.gca().xaxis.set_major_locator(plt.NullLocator()) plt.gca().yaxis.set_major_locator(plt.NullLocator()) plt.subplots_adjust(top=1, bottom=0, left=0, right=1, hspace=0, wspace=0) plt.margins(0, 0) path1 = 'D:/PYTTC/pythonProject/mask rcnn_test/save/mask100/' path = os.listdir(path1) i = len(path) plt.savefig("D:/PYTTC/pythonProject/mask rcnn_test/save/mask100/MGWD"+'_'+str(i)+".jpg")此函数下的内容,原有内容应该只有 plt.show()需要注释掉,改为相应的内容
-
path1=“ 这里是你要保存预测结果的路径”’
-
详情请看这里 6-测试与展示模块_哔哩哔哩_bilibili
-
OK 大概就是这些了,出bug是一件令人头疼的事情,有时候一个接一个都找不过来,所以如有问题,欢迎评论区讨论!!