@[TOC]
概述
UNet是一种用于图像分割任务的深度学习模型,最初由Olaf Ronneberger等人在2015年提出。它的名字来源于其U形状的网络结构。
UNet的主要特点是它使用了编码器和解码器结构,其中编码器部分由一系列卷积层和池化层组成,可以对输入图像进行特征提取和压缩。解码器部分则通过上采样和反卷积层将编码器输出的低分辨率特征映射扩展回原始分辨率,从而获得分割结果。
UNet的另一个重要特点是它采用了跳跃连接(skip connections),这些连接将编码器中的某些层与解码器中相应的层连接起来,从而使解码器可以利用更多的低级别特征来进行分割。这种跳跃连接结构可以有效地解决分割过程中信息丢失和分割不准确的问题。
UNet已被广泛应用于医学图像分割、自然图像分割等任务中,并取得了很好的效果。
网络结构
。UNet架构由对称的编码器和解码器组成
输入层:接受输入图像。
编码器:由卷积层和池化层组成,用于逐步缩小图像的尺寸并提取特征。
解码器:由卷积层和上采样层组成,用于逐步恢复图像的尺寸并将编码器中提取的特征与解码器的对应层相结合。
跳跃连接:将编码器中的特征与解码器的对应层相结合,以便恢复图像的分辨率。
输出层:输出与输入图像具有相同尺寸的分割图像,其中每个像素被标记为分割类别之一。
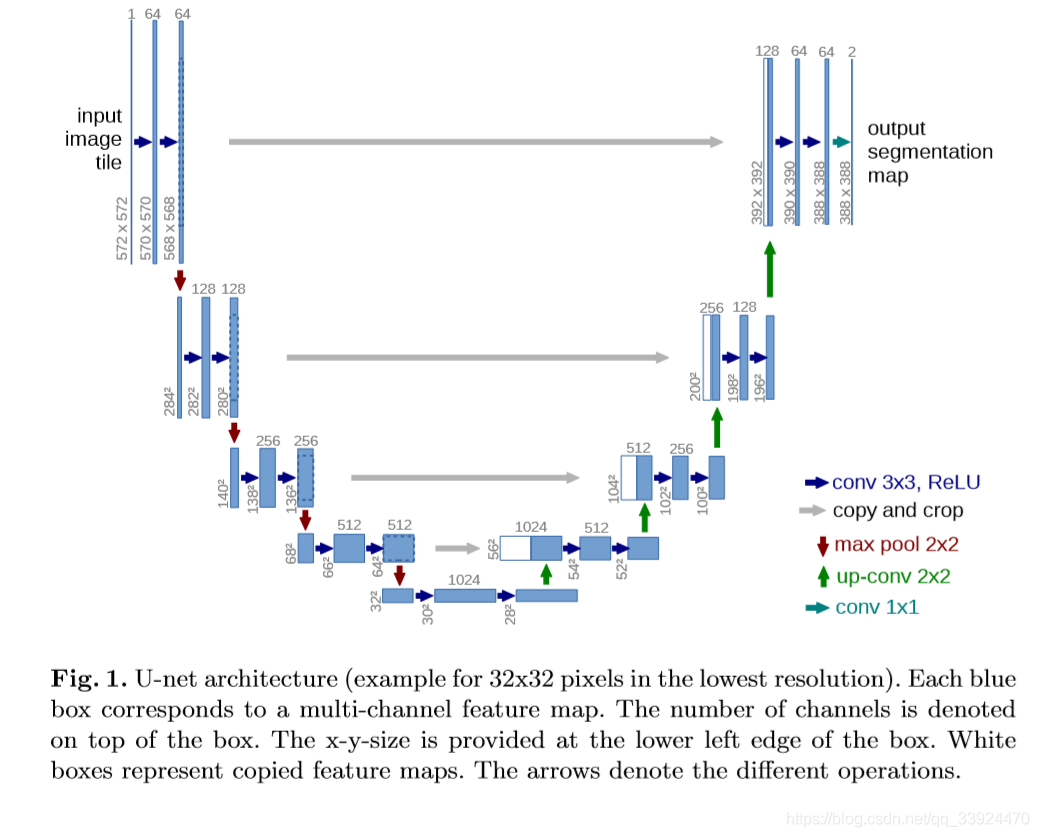
__________________________________________________________________________________________________
深蓝色箭头:利用3×3的卷积核对图片进行卷积后,通过ReLU激活函数输出特征通道;
灰色箭头:对左边下采样过程中的图片进行裁剪复制;
红色箭头:通过最大池化对图片进行下采样,池化核大小为2×2;
绿色箭头:反卷积,对图像进行上采样,卷积核大小为2×2;
青色箭头:使用1×1的卷积核对图片进行卷积。
具体流程如下:
第一层处理
输入一张 572×572×1 的图片
使用 64 个 3×3 的卷积核进行卷积,并通过 ReLU 函数得到 64 个 570×570×1 的特征通道
再使用 64 个 3×3 的卷积核进行卷积,并通过 ReLU 函数得到 64 个 568×568×1 的特征通道,即第一层的处理结果
下采样过程
对第一层的处理结果进行 2×2 的池化核操作,将图片下采样为原来大小的一半:284×284×64
使用 128 个卷积核进一步提取特征,得到一个新的特征图片
重复以上步骤,对新的特征图片进行下采样,每一层都会经过两次卷积来提取图像特征
每下采样一层,都会把图片减小一半,卷积核数目增加一倍
最终下采样部分的结果是 28×28×1024,即一共有 1024 个特征层,每一层的特征大小为 28×28
上采样过程
从最右下角开始,把28×28×1024的特征矩阵经过512个2×2的卷积核进行反卷积,把矩阵扩大为56×56×512。
为了减少数据丢失,采用把左边降采样时的图片裁剪成相同大小后直接拼接的方法增加特征层(这里是左半边白色部分的512个特征通道),再进行卷积来提取特征。
每一层都会进行两次卷积来提取特征,每上采样一层,都会把图片扩大一倍,卷积核数目减少一半。
右边部分从下往上则是4次上采样过程。
在最后一步中,选择了2个1×1的卷积核把64个特征通道变成2个,也就是最后的388×388×2,这里是一个二分类的操作,把图片分成背景和目标两个类别。
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_1 (InputLayer) [(None, 572, 572, 1) 0
__________________________________________________________________________________________________
conv2d (Conv2D) (None, 570, 570, 64) 640 input_1[0][0]
__________________________________________________________________________________________________
batch_normalization (BatchNorma (None, 570, 570, 64) 256 conv2d[0][0]
__________________________________________________________________________________________________
activation (Activation) (None, 570, 570, 64) 0 batch_normalization[0][0]
__________________________________________________________________________________________________
conv2d_1 (Conv2D) (None, 568, 568, 64) 36928 activation[0][0]
__________________________________________________________________________________________________
batch_normalization_1 (BatchNor (None, 568, 568, 64) 256 conv2d_1[0][0]
__________________________________________________________________________________________________
activation_1 (Activation) (None, 568, 568, 64) 0 batch_normalization_1[0][0]
__________________________________________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 284, 284, 64) 0 activation_1[0][0]
__________________________________________________________________________________________________
conv2d_2 (Conv2D) (None, 282, 282, 128 73856 max_pooling2d[0][0]
__________________________________________________________________________________________________
batch_normalization_2 (BatchNor (None, 282, 282, 128 512 conv2d_2[0][0]
__________________________________________________________________________________________________
activation_2 (Activation) (None, 282, 282
卷积核大小、卷积核数量、数值确定和训练深度确定
U-net卷积核大小的选择原则为越小越好,且一般为奇数×奇数的正方形。因此通常选用3×3的卷积核。但1×1的卷积核不具有提升感受野的作用,而卷积核为偶数×偶数时不能保证图片在进行same卷积操作后,还能够还原到原本的大小。
每一层的卷积核数量在U-net中是根据随着深度增加需要提取的更多、更抽象的特征而增加的。在U-net浅层中,提取的是颜色、轮廓等比较浅显的图像特征,因此卷积核数量不需要特别多。而随着U-net训练层数越深,需要更多的卷积核才能够把抽象特征提取出来。而U-net每一层都会把卷积核数量翻一倍,是因为经过下采样后图片大小会变成原来的一半,认为卷积核应该增多一倍才能够更全面地提取图片特征。
卷积核中的数值实际上就相当于是一般全连接神经网络中的权值。在U-net中,卷积核数值的确定是类似全连接神经网络中权值的确定过程,一开始用随机数进行初始化,后面根据损失函数逐步对数值进行调整。当训练精度符合要求后停止,即能确定每个卷积核中的数值。而调整卷积核数值的过程,实际上就是U-net的训练过程。
U-net训练深度的选择目前没有一个专门的标准,一般根据经验选取,或设置多种不同的深度,通过训练效果来选择最优的层数。在U-net原文中也没有明确解释为什么选择4层,可能是在该训练项目中,4层的分割效果最好。
升级版本
U-Net++是一种基于U-Net的改进型神经网络结构,通过增加连接方式和多尺度特征融合来提高图像分割精度。与传统的U-Net相比,U-Net++在保持U-Net结构简洁的同时,能够更好地捕捉图像的细节信息,提高分割精度。
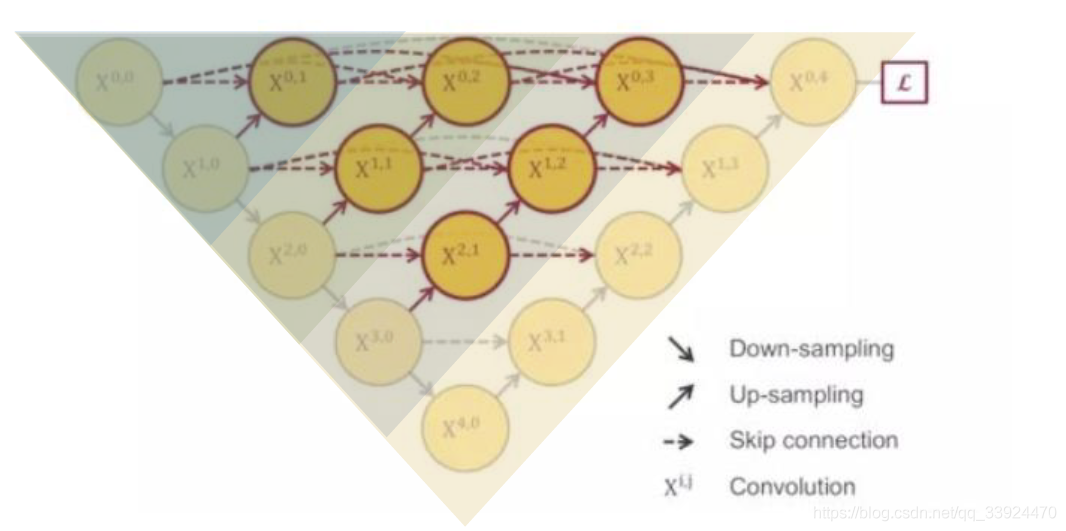
基于深度为4层的U-net
将1~3层的U-net全部组合到一起
每个深度的训练效果相互融合相互补充
对图像进行更为精确的分割