有的说InnoDB支持哈希索引,有的说不支持,到底哪个是正确的呢?关于这个问题要说支持也对,不支持也对。
对于InnoDB的哈希索引,分两种情况:
(1)InnoDB用户无法手动创建哈希索引,这层来说InnoDB是不支持哈希索引的;
(2)InnoDB会自调优(self-tuning),如果判定建立自适应哈希索引(Adaptive Hash Index, AHI),能够提升查询效率,InnoDB自己会建立相关哈希索引(自适应哈希索引),这一层上说,InnoDB又是支持哈希索引的;
那什么是自适应哈希索引(Adaptive Hash Index, AHI)呢?举个例子:
假设一张表:
t(id pk ,name key ,age ,phone) id:是主键,name是辅助索引(普通索引)
表中有数据
101 zhangxx 18 13600130000
102 zhaoxx 20 136001300850
103 chengxx 28 13211300000
104 huanggxx 21 1378013000
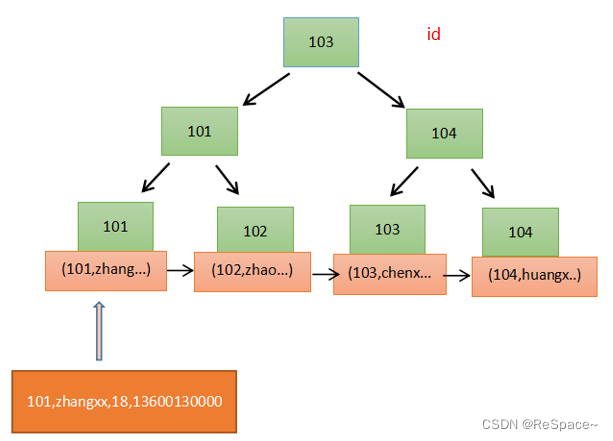
如上图:发起主键id查询时,能够通过聚集索引,直接定位到行记录
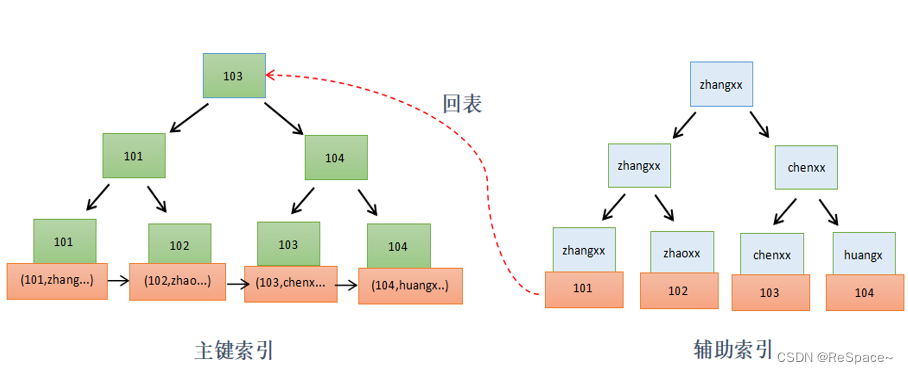
如上图发起普通索引查询时:
(1)会先从普通索引查询出主键(上图右边);
(2)再由主键,从聚集索引上二次遍历定位到记录(上图左边)。(回表)
在这个查询过程中,不管是主键索引还是普通索引,记录定位的寻路路径(Search Path)都很长。
在MySQL运行的过程中,如果InnoDB发现,有很多SQL存在这类很长的寻路,并且有很多SQL会命中相同的页面(page),(或者是频繁被访问的索引)InnoDB会在自己的内存缓冲区(Buffer)里,开辟一块区域,建立自适应哈希索引AHI,以加速查询。(简单理解为一些热点数据被维护成一个哈希表,当要查询这些数据时可以快速返回,不需要再经过b+树的查找过程)
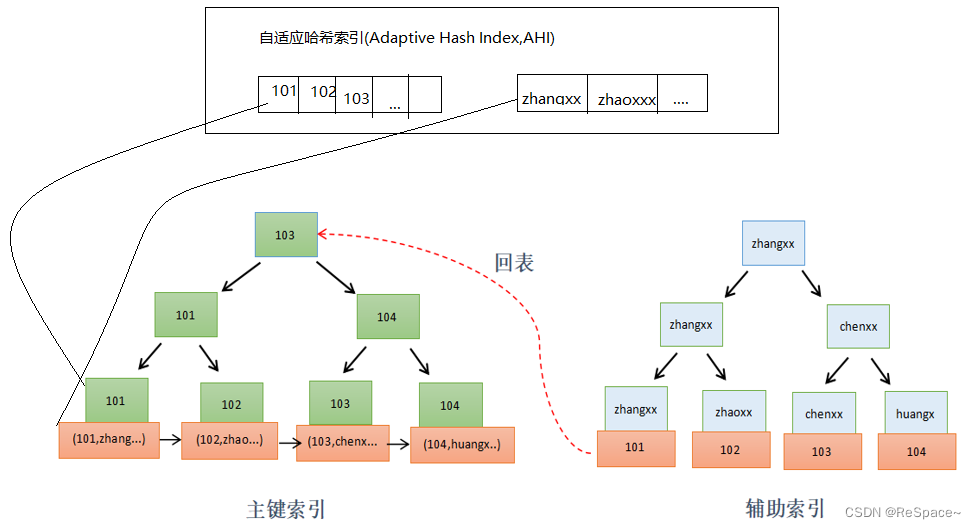
InnoDB的自适应哈希索引,更像“索引的索引”,因为其目的是为了加速索引寻路。
由于是系统自己判断“应该可以加速查询”而创建的,不需用户参与,故称“自适应”哈希索引。
哈希索引中的key和value是什么呢?
key是索引键值(或者键值前缀)。
value是索引记录页面位置
哈希索引的特征:
- 等值查询性能优秀
- 存在hash冲突
- 不支持范围查询
如何观察AHI的使用情况
通过命令SHOW ENGINE INNODB STATUS可以看到AHI的使用情况
默认开启,可以通过 set global innodb_adaptive_hash_index=off/on 关闭和打开该功能
一般情况下,自适应哈希索引都能提升查询效率。