几种IO模型
企业开发
2023-06-05 12:52:05
阅读次数: 0
IO
真正的IO操作涉及到和IO设备的交互,而操作系统限制了应用程序直接和设备交互。我们通常说的IO操作实际上是应用程序和操作系统进行交互,一般会使用操作系统的System Call,即系统调用,读是read(),写是write(),不同的操作系统中实现可能有差异,但是功能是相同的。通过调用read,把数据从操作系统内核缓冲区复制到应用程序缓冲区;调用write,是把数据从应用程序缓冲区复制到操作系统内核缓冲区。真正与IO设备交互,是由操作系统在合适的时机发起系统中断,找到中断向量与对应的设备交互。
所以,IO分为两个阶段,一个是内核和设备交互阶段,另一个是内核和应用程序交互阶段。
同步IO与异步IO
同步IO是指用户线程是主动发起IO请求的一方,操作系统内核是被动接受IO请求的一方。
异步IO和同步IO相反,是指操作系统内核是主动发起IO请求的一方,用户线程是被动接受的一方。用户线程向内核注册了各种IO事件的回调函数,由内核去主动调用。
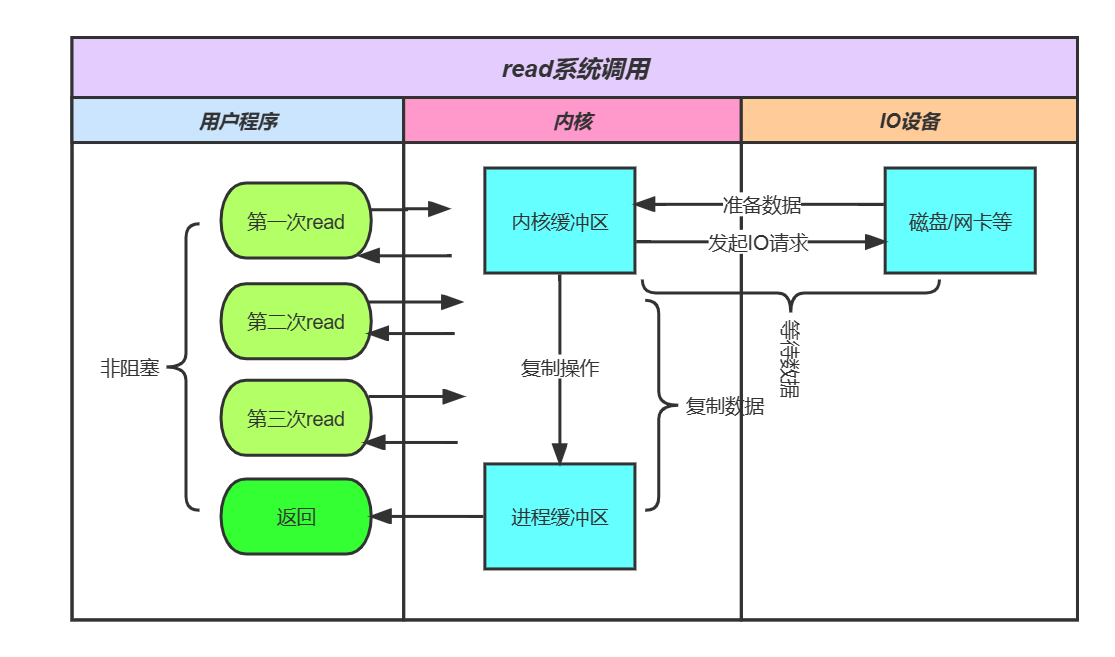
阻塞IO与非阻塞IO
阻塞IO指的是需要内核IO操作彻底完成后,才返回到用户线程继续执行。阻塞指的是用户程序的执行状态。
非阻塞IO指的是用户程序不需要等待内核IO操作彻底完成,在调用IO后内核会立即返回给用户线程一个状态值,用户线程可以继续往下执行,线程处于非阻塞的状态。
BIO
BIO即是blocking IO,同步阻塞性IO,应用程序从IO系统调用开始,直到系统调用返回,在这段时间内,用户线程是阻塞的。返回成功后,线程开始处理应用程序缓冲区数据。
假设现在用BIO模型读取磁盘上的一个文件:
(1)从read系统调用开始,用户线程就进入阻塞状态。
(2)当系统内核收到read系统调用,就开始准备数据。一开始,数据可能还没有到达内核缓冲区(可能没读完一个块),这时内核需要等待。
(3)内核一直等到完整的数据到达,将数据从内核缓冲区复制到应用程序缓冲区,之后read返回结果(返回复制到用户缓冲区中的字节数)。
(4)read返回后,用户线程会从阻塞中恢复,继续运行。
所以BIO模型在内核进行IO操作的两个阶段,用户线程都处于阻塞状态。
举个例子,小王去饭店吃饭,点了一份麻辣烫,然后他就一直盯着取餐口,直到老板向取餐口放置一份麻辣烫。之后,他去取来麻辣烫吃掉。
其中,小王就是应用程序,老板就是操作系统内核,点餐这个动作就是发起IO请求,取饭这个动作就是从内核缓冲区拷贝到进程缓冲区。
由于是小王发起点餐,所以这是同步的;但是小王一直盯着取餐口没有做其他事,说明他处于阻塞状态,所以这是同步阻塞IO模型。
NIO
Non-Blocking IO,非阻塞IO。在NIO模型中,应用程序的线程一旦开始IO系统调用,会出现以下两种情况:
(1)在内核缓冲区中没有数据的情况下,系统调用会立即返回,返回一个调用失败的信息。
(2)在内核缓冲区中有数据的情况下,则处于阻塞状态,直到数据从内核缓冲区复制到用户进程缓冲区完成后,系统调用返回成功,线程恢复运行。
假设现在用NIO模型读取磁盘上的一个文件:
(1)在内核数据没有准备好的阶段,用户线程发起IO请求时,立即返回。一般为了读取到最终的数据,用户线程需要不断地发起IO系统调用(while循环)。
(2)内核数据到达后,用户线程发起系统调用时,用户线程进入阻塞状态。内核开始复制数据,将数据从内核缓冲区复制到进程缓冲区,然后内核返回结果。
(3)用户线程读到数据后,解除阻塞状态,继续运行。也就是说,用户进程需要经过多次的尝试,才能保证最终真正读到数据,然后继续执行。
所以,NIO模型在操作系统与设备交互阶段,用户线程处于非阻塞状态,在操作系统与应用程序交互期间,用户线程需要阻塞以复制缓冲区。
还是小王去饭店吃饭,点了一份麻辣烫,在吃饭之前,他询问老板,饭好了吗,老板回复没有,然后他就每隔3分钟询问一次,直到饭做好了为止。之后,他去取来麻辣烫吃掉。
由于还是小王发起点餐,所以这是同步的;询问老板老板立即回复,说明是非阻塞的,所以这是同步非阻塞IO模型。
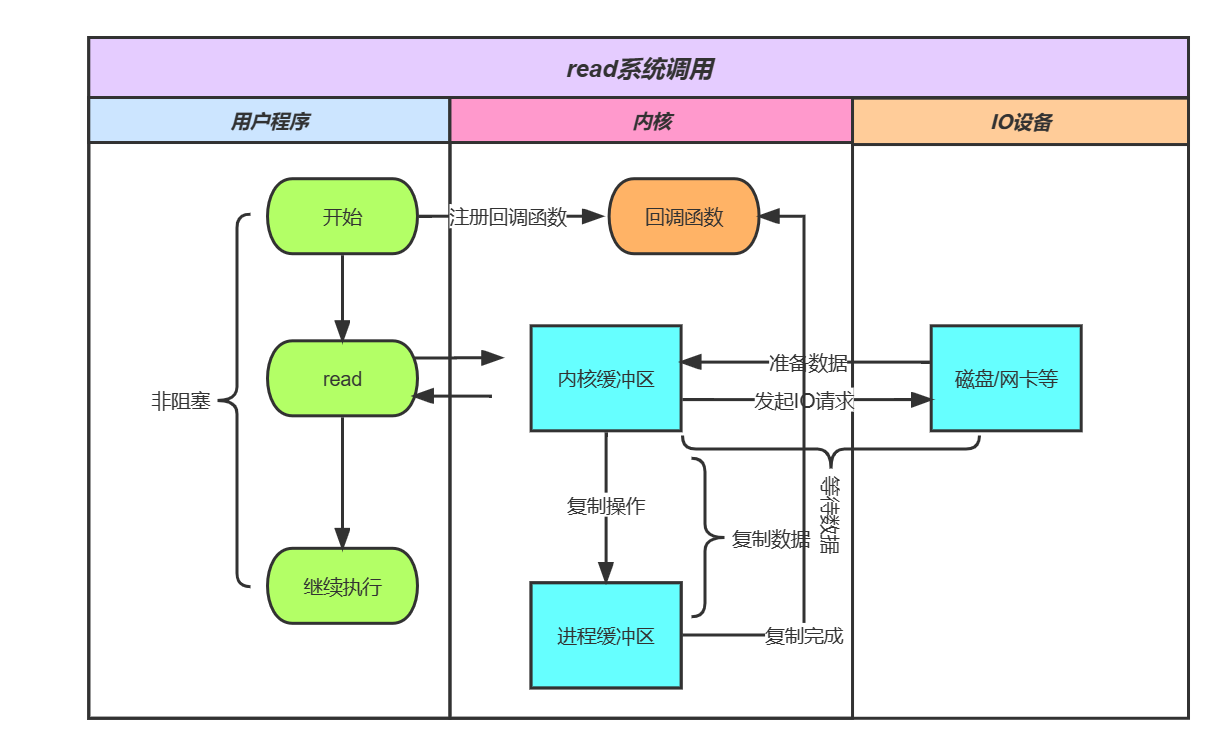
AIO
异步IO模型(Asynchronous IO,简称为AIO)。基本流程是:用户线程通过系统调用,向内核注册某个函数。内核在整个IO操作(包括数据准备、缓冲区数据复制)完成后,通知用户线程,执行后续的业务操作。在整个内核的数据处理过程中,包括内核将数据从网卡或磁盘读取到内核缓冲区、将内核缓冲区的数据复制到用户缓冲区两个阶段中,用户线程都不需要阻塞。
假设现在通过AIO模型来读取磁盘上的一个文件:
(1)当用户线程发起了read系统调用,可以继续往下执行,用户线程不阻塞,也不需要轮询来查询是否内核准备好了数据。
(2)内核开始IO的第一个阶段:与设备交互准备数据。等到数据准备好了,执行第二阶段,将数据从内核缓冲区复制到进程缓冲区。
(3)内核会给用户进程发送一个信号(Signal),或者回调用户线程注册的函数,通知用户线程read操作结束。
(4)用户线程读取进程缓冲区的数据,完成后续的业务操作。
所以,在AIO模型中内核等待数据和复制数据的两个IO阶段,用户线程都不阻塞。
假设现在饭店开始开放外卖服务,小王用外卖App点了份炒面并填写了住址,看到下单成功就干别的去了,然后外卖小哥把饭送到小王家门口,小王开心的吃了一顿美餐。
填写住址这个操作就相当于向内核中注册函数,从饭做好到外卖小哥送到家这两个过程小王也没有干等着,所以这是非阻塞的,所以整体上为异步IO模型。
IO多路复用
在IO多路复用模型中,引入了一种新的系统调用,称为选择器,功能是查询IO的就绪状态。在Linux系统中,对应的系统调用为select/epoll系统调用,epoll是select的增强版。通过该系统调用,一个进程可以监视多个文件描述符,一旦某个描述符就绪(一般是内核缓冲区可读/可写),内核能够将就绪的状态返回给应用程序。之后,应用程序根据就绪的状态,进行相应的IO系统调用。
假设现在用IO多路复用模型编写一个socket监听服务器:
(1)注册IO操作。每收到一个客户端socket连接时将其注册到select/epoll选择器中。
(2)开始就绪状态的轮询。通过选择器的查询方法,查询注册过的所有socket连接的就绪状态。通过查询的系统调用,内核会返回一个就绪的socket列表。当任何一个注册过的socket中的数据准备好了,内核缓冲区有数据(就绪)了,内核就将该socket加入到就绪的列表中。
在轮询时,负责轮询的用户线程将会一直阻塞。
(3)用户线程获得了就绪状态的列表后,根据其中的socket连接,发起read系统调用,用户线程阻塞,内核开始将数据从内核缓冲区复制到进程缓冲区。
(4)复制完成后,内核返回结果,用户线程才会从阻塞中恢复继续执行。
假设小王,小张,小李去饭店吃饭,小王点了拉面,小张点了盖浇米饭,小李点了胡辣汤,这时他们雇了一个人帮他们查看饭的状态,如果谁的饭好了就通知某人去取饭。
这个过程中,三个人雇用的这个人就充当一个选择器,他需要不停的查看饭的状态,如果小王的饭好了就通知小王,然后小王去取饭,其他两人的饭也是如此,这就是IO多路复用。
总结
BIO、NIO在高并发场景下不可用,BIO需要一个线程维护一个IO连接,NIO需要不断轮询,占用CPU资源,NIO很少单独使用。
吞吐量最好的是AIO,其次是IO多路复用。
AIO目前只有windows的IOCP,linux下支持还不完善,所以跑在linux上的高并发网络应用程序大多采用IO多路复用模型。
转载自blog.csdn.net/qq_32076957/article/details/128825147