JavaScript与其他的语言根本性的差异:
函数是一等公民(一级对象)——在JavaScript中,函数与其他对象共存,并且能够像任何其他对象一样地使用。函数可以通过字面量创建,可以赋值给变量,可以作为函数参数进行传递,甚至可以作为返回值从函数中返回。
函数闭包——它从根本上例证了函数之于JavaScript的重要性。我们浅层理解它,闭包是当函数主动维护了在函数内使用的外部的变量,则该函数为一个闭包。
作用域——直到最近,JavaScript都还没有(类似C语言中的)块级作用域下的变量,取而代之则只能依赖函数级别的变量和全局变量。
基于原型的面向对象——不同于其他主流的面向对象语言使用基于类的面向对象,JavaScript使用基于原型的面向对象。
对象、原型、函数和闭包的紧密结合组成了JavaScript。
web应用的生命周期:
客户端Web应用的周期从用户指定某个网站地址(或单击某个链接)开始,由两个步骤组成:页面构建和事件处理
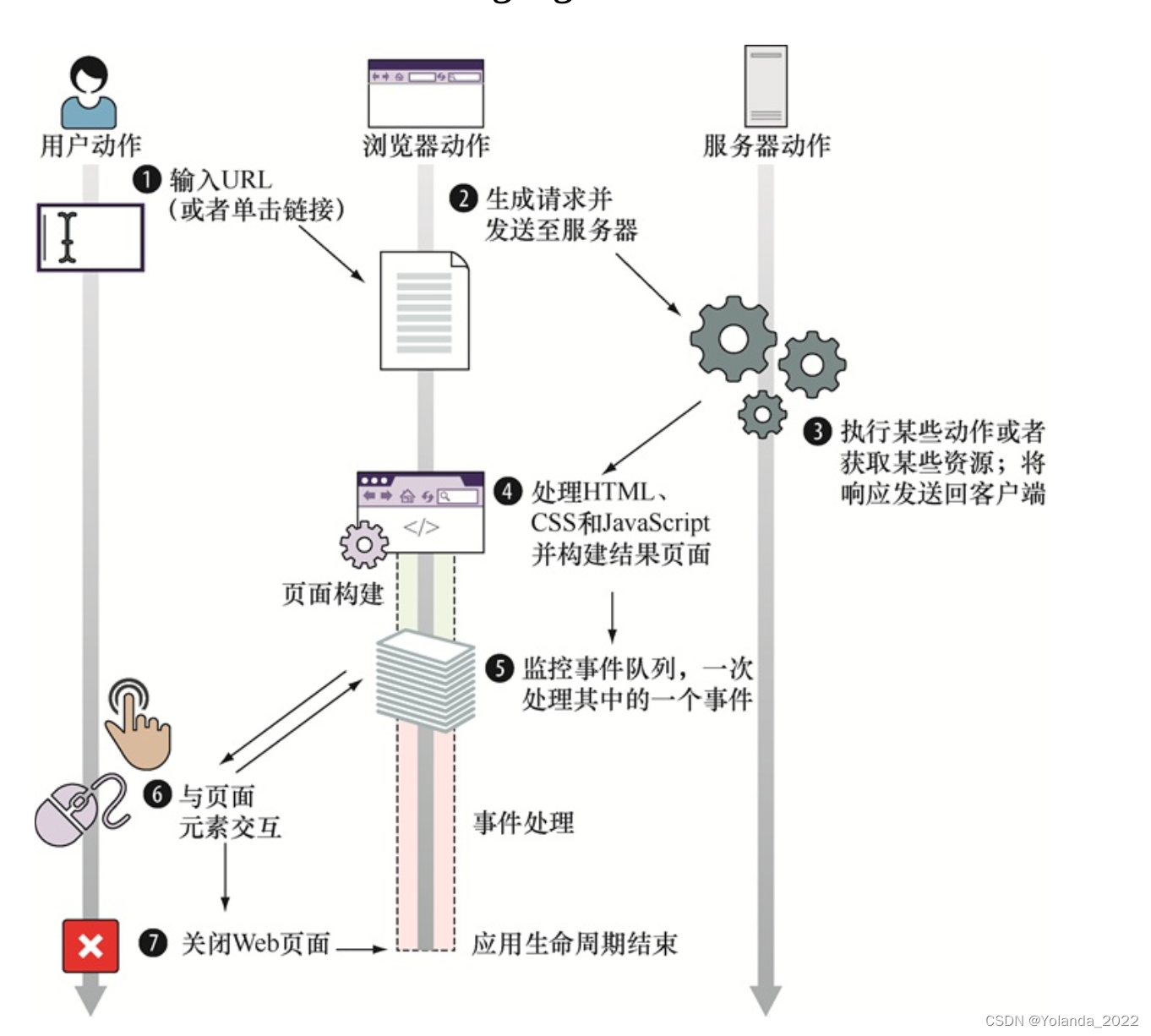
从用户的角度来说,浏览器构建了发送至服务器(序号2)的请求,该服务器处理了请求(序号3)并形成了一个通常由HTML、CSS和JavaScript代码所组成的响应。当浏览器接收了响应(序号4)时,我们的客户端应用开始了它的生命周期。 由于客户端Web应用是图形用户界面(GUI)应用,其生命周期与其他的GUI应用相似(例如标准的桌面应用或移动应用),其执行步骤如下所示:
1.页面构建——创建用户界面;
2.事件处理——进入循环(序号5)从而等待事件(序号6)的发生,发生后调用事件处理器。
应用的生命周期随着用户关掉或离开页面(序号7)而结束。
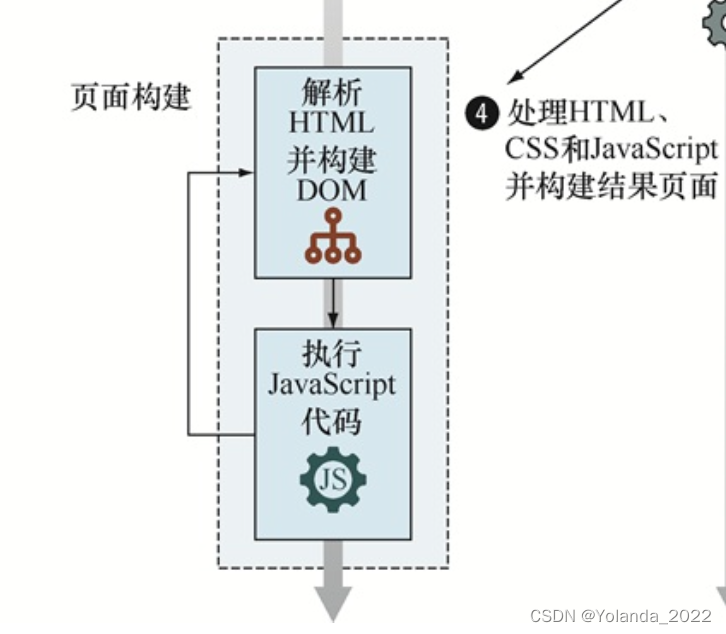
页面构建阶段从浏览器接收页面代码开始。其执行分为两个步骤:HTML解析和DOM构建,以及JavaScript代码的执行。
HTML解析和DOM构建:
页面构建阶段始于浏览器接收HTML代码时,该阶段为浏览器构建页面UI的基础。通过解析收到的HTML代码,构建一个个HTML元素,构建DOM。
尽管DOM是根据HTML来创建的,两者紧密联系,但需要强调的是,它们两者并不相同。你可以把HTML代码看作浏览器页面UI构建初始DOM的蓝图。为了正确构建每个DOM,浏览器还会修复它在蓝图中发现的问题。
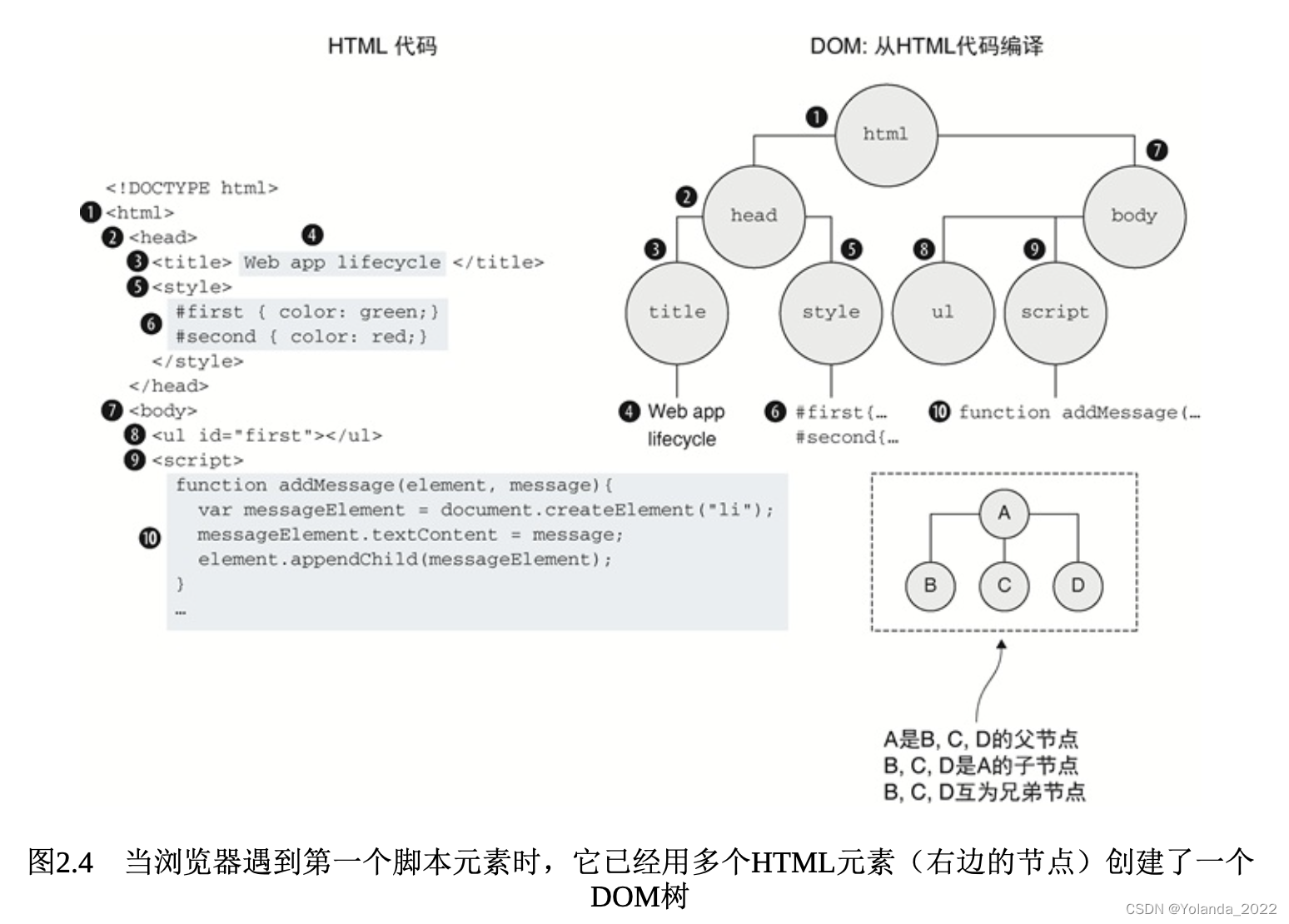
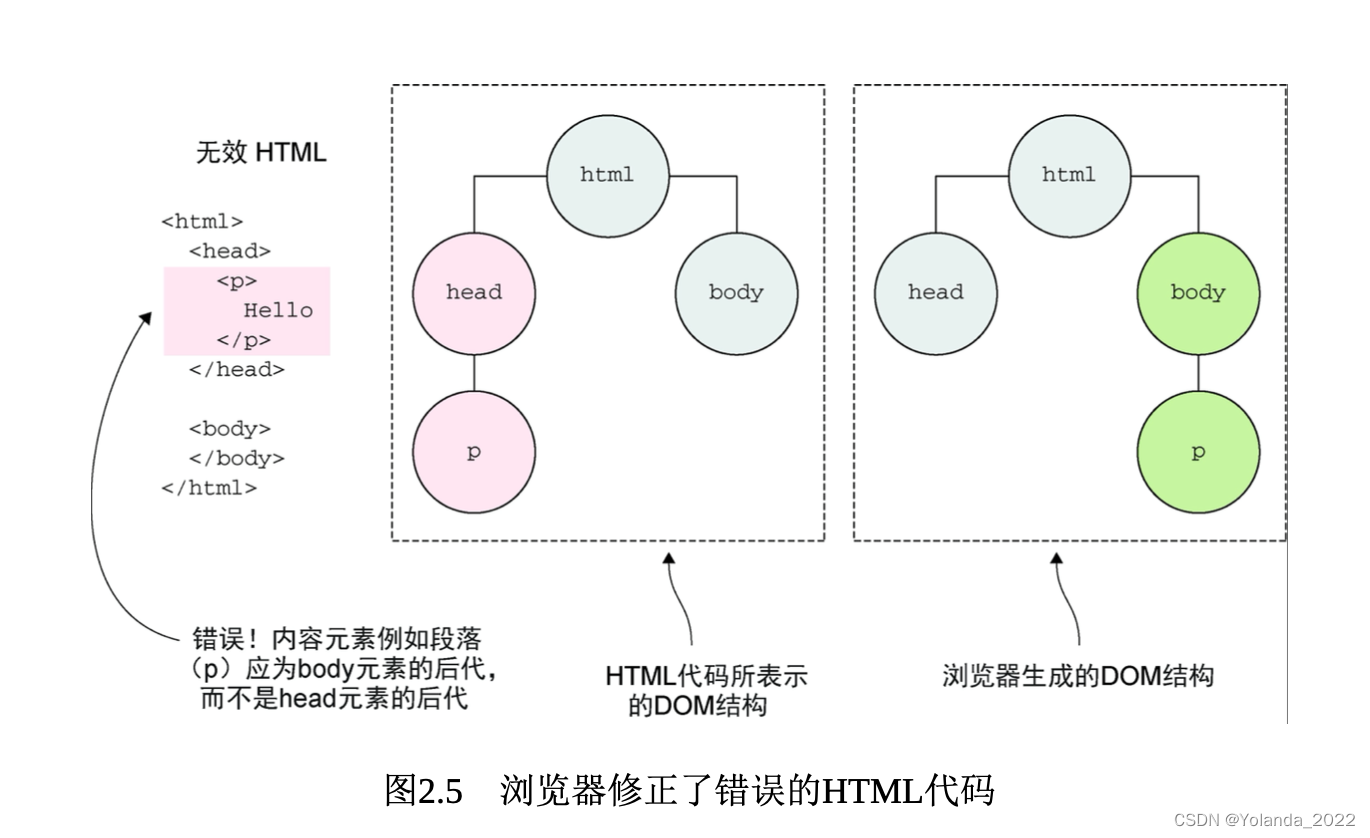
在页面构建阶段,浏览器会遇到特殊类型的HTML元素——脚本元素,该元素用于包括JavaScript代码。每当解析到脚本元素时,浏览器就会停止从HTML构建DOM,并开始执行JavaScript代码。
执行JavaScript代码:
所有包含在脚本元素中的JavaScript代码由浏览器的JavaScript引擎执行。
一般来说,JavaScript 代码能够在任何程度上修改DOM结构:它能创建新的节点或移除现有DOM节点。但它依然不能做某些事情,例如选择和修改还没被创建的节点。这就是为什么要把script元素放在页面底部的原因。如此一来,我们就不必担心是否某个HTML元素已经加载为DOM。
当浏览器在页面构建阶段遇到了脚本节点,它会停止HTML到DOM的构建,转而开始执行JavaScript代码,也就是执行包含在脚本元素的全局JavaScript 代码。
一旦JavaScript引擎执行到了脚本元素中JavaScript代码的最后一行,浏览器就退出了JavaScript执行模式,并继续余下的HTML构建为DOM节点。在这期间,如果浏览器再次遇到脚本元素,那么从HTML到DOM的构建再次暂停,JavaScript运行环境开始执行余下的JavaScript代码。只要还有没处理完的HTML元素和没执行完的JavaScript代码,下面两个步骤都会一直交替执行。
1.将HTML构建为DOM。
2.执行JavaScript代码。
最后,当浏览器处理完所有HTML元素后,页面构建阶段就结束了。随后浏览器就会进入应用生命周期的第二部分:事件处理。
事件处理:
在页面构建阶段执行的JavaScript代码,除了会影响全局应用状态和修改DOM外,还会注册事件监听器(或处理器)。这类监听器会在事件发生时,由浏览器调用执行。
浏览器执行环境的核心思想基于:同一时刻只能执行一个代码片段,即所谓的单线程执行模型。
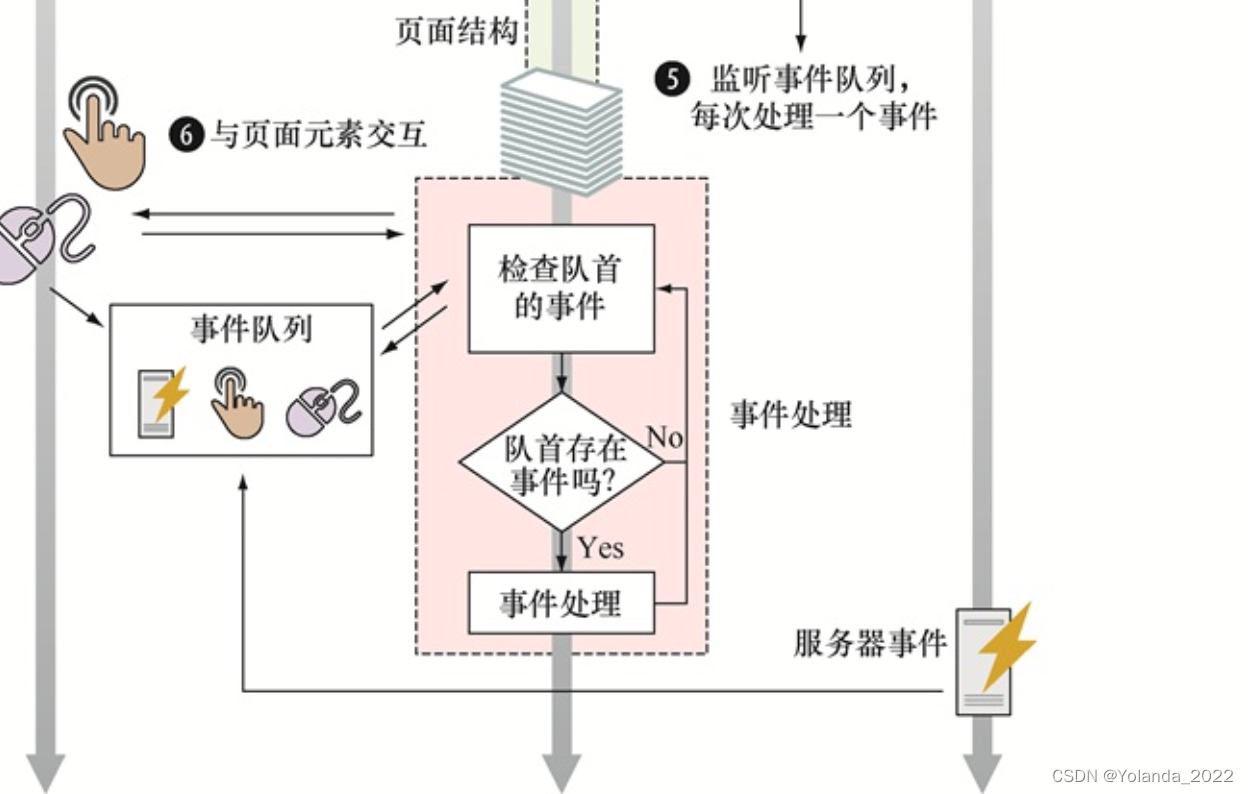
事件处理——在同一时刻,只能处理多个不同事件中的一个,处理顺序是事件生成的顺序。事件处理阶段大量依赖事件队列,所有的事件都以其出现的顺序存储在事件队列中。事件循环会检查事件队列的队头,如果检测到了一个事件,那么相应的事件处理器就会被调用.
函数
对象能做的任何一件事,函数也都能做。函数也是对象,唯一的特殊之处在于它是可调用的,即函数会被调用以便执行某项动作。
回调函数
即在执行过程中,我们建立的函数会被其他函数在稍后的某个合适时间点“再回来调用”
给函数添加属性
函数作为对象的乐趣----我们可以给函数添加属性。
var ninja = {
}
ninja.name = "hitsuke"; ⇽--- 创建新对象并为其分配一个新属性
var wieldSword = function(){
};
wieldSword.swordType = "katana"; ⇽--- 创建新函数并为其分配一个新属性
存储唯一函数集合
var store = {
nextId: 1, ⇽--- 跟踪下一个要被复制的函数
cache: {
}, ⇽--- 使用一个对象作为缓存,我们可以在其中存储函数 add: function(fn) {
if (!fn.id) {
fn.id = this.nextId++;
this.cache[fn.id] = fn;
return true;
}
} ⇽--- 仅当函数唯一时,将该函数加入缓存 };
function ninja(){
} assert(store.add(ninja), "Function was safely added.");
assert(!store.add(ninja),"But it was only added once.");
⇽--- 测试上面的代码按预期工作
给函数附加一个属性后,我们就能够引用该属性。本例通过这种方式可以确保该ninja函数仅被添加到函数中一次。
自记忆函数
如下,缓存answers是isPrime函数自身的属性,只要函数还在,缓存也就存在。
function isPrime(value) {
if (!isPrime.answers) {
isPrime.answers = {
}; ⇽--- 创建缓存
}
if (isPrime.answers[value] !== undefined) {
return isPrime.answers[value];
} ⇽--- 检查缓存的值
var prime = value !== 0 && value !== 1; // 1 is not a prime
for (var i = 2; i < value; i++) {
if (value % i === 0) {
prime = false;
break;
}
}
return isPrime.answers[value] = prime; ⇽--- 存储计算的值
}
assert(isPrime(5), "5 is prime!");
assert(isPrime.answers[5], "The answer was cached!");
⇽--- 测试该函数 是否正常工作
函数表达式
总是其他表达式的一部分的函数(作为赋值表达式的右值,或者作为其他函数的参数)叫作函数表达式
立即执行函数
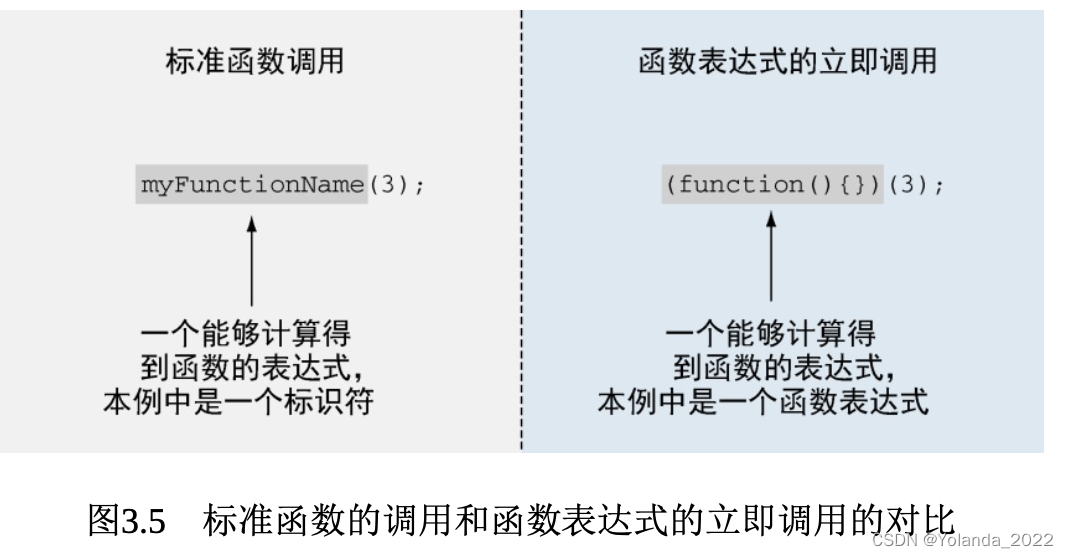
立即调用函数表达式主题的4个不同版本:

箭头函数
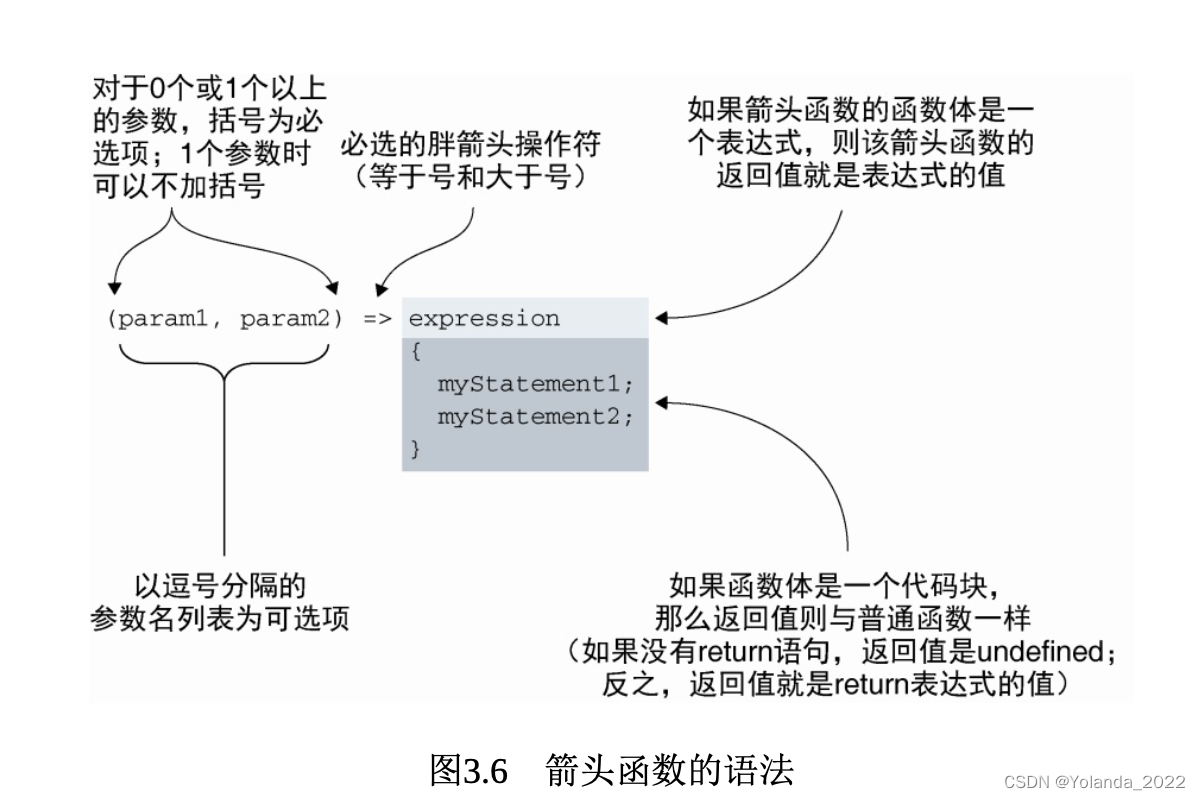
函数的形参和实参
1.形参是我们定义函数时所列举的变量。
函数形参是在函数定义时指定的。
2.实参是我们调用函数时所传递给函数的值。
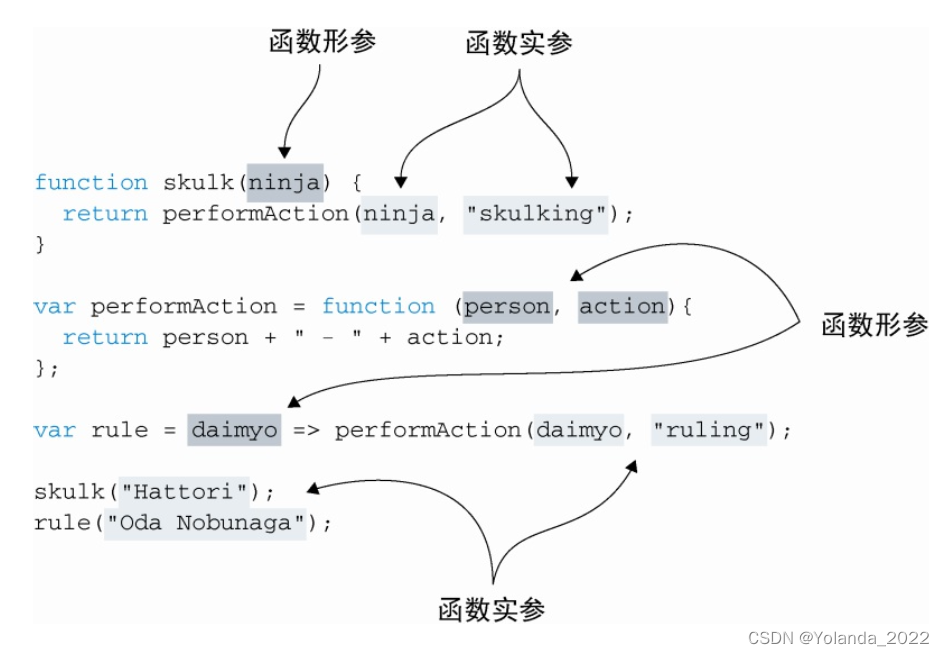
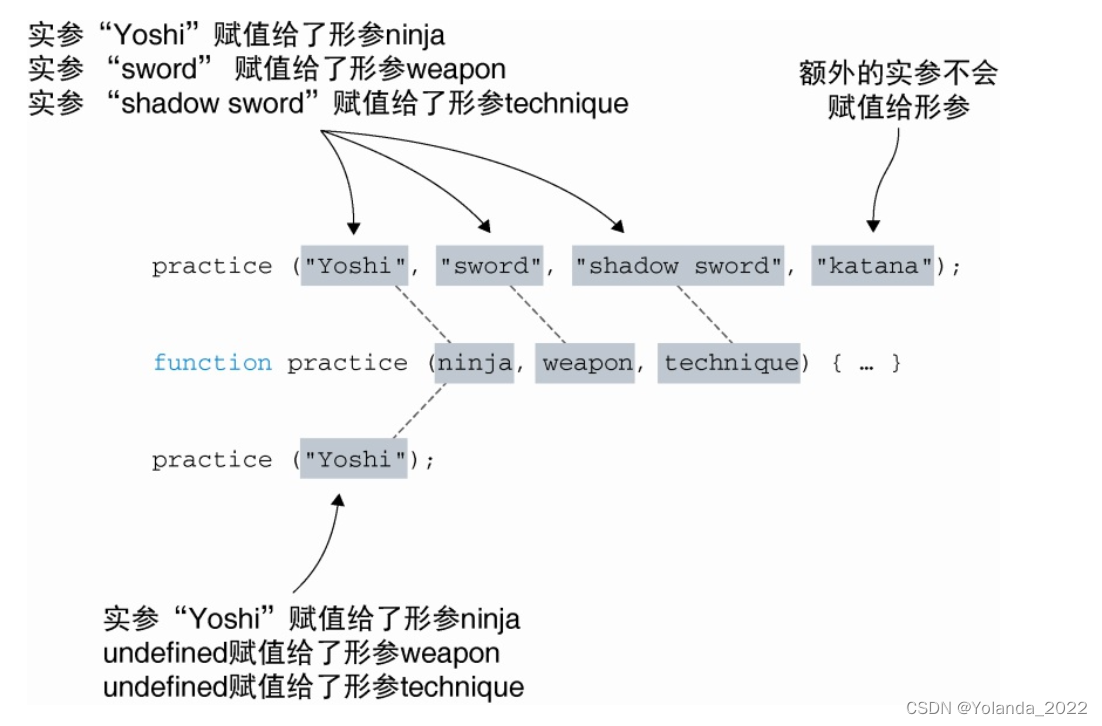
函数调用
隐式参数arguments和this。
这些隐式参数在函数声明中没有明确定义,但是会默认传递给函数,并且可以在函数内正常访问。
arguments参数
arguments对象的主要作用是允许我们访问传递给函数的所有参数,即便部分参数没有和函数的形参关联也无妨。
arguments对象有一个名为length的属性,表示实参的确切个数。
arguments对象仅是一个类数组的结构,但它并非JavaScript数组,如果你尝试在arguments对象上使用数组的方法,会发现最终会报错。
大多数情况下可以使用剩余参数来代替arguments参数。剩余参数是真正的Array实例,也就是说你可以在它上面直接使用所有的数组方法。
this参数:函数上下文
this参数是面向对象JavaScript编程的一个重要组成部分,代表函数调用相关联的对象。因此,通常称之为函数上下文。
通过4种方式调用一个函数
作为一个函数(function)——skulk(),直接被调用。
作为一个方法(method)——ninja.skulk(),关联在一个对象上,实现面向对象编程。
作为一个构造函数(constructor)——new Ninja(),实例化一个新的对象。
通过函数的apply或者call方法——skulk.apply(ninja)或者skulk.call(ninja)。
1.作为函数直接被调用
function ninja() {
};
ninja(); ⇽--- 函数定义作为函数被调用
var samurai = function(){
};
samurai(); ⇽--- 函数表达式作为函数被调用
(function(){
})() ⇽--- 会被立即调用的函数表达式,作为函数被调用
当以这种方式调用时,函数上下文(this关键字的值)有两种可能性:在非严格模式下,它将是全局上下文(window对象),而在严格模式下,它将是undefined。
2.作为方法被调用
var ninja = {
};
ninja.skulk = function(){
};
ninja.skulk();
当一个函数被赋值给一个对象的属性,并且通过对象属性引用的方式调用函数时,函数会作为对象的方法被调用。
当函数作为某个对象的方法被调用时,该对象会成为函数的上下文,并且在函数内部可以通过参数访问到。
function whatsMyContext() {
return this;
}
var ninja1 = {
getMyThis: whatsMyContext
};
ninja1.getMyThis() === ninja1 // true
var ninja2 = {
getMyThis: whatsMyContext
};
ninja2.getMyThis() === ninja2 // true
3.作为构造函数调用
function Ninja() {
this.skulk = function() {
return this;
};
} ⇽--- 构造函数创建一个对象,并在该对象也就是函数上下文上添加一个属性skulk。
这个skulk方法再次返回函数上下文,从而能让我们在函数外部检测函数上下文
var ninja1 = new Ninja();
var ninja2 = new Ninja(); ⇽--- 通过关键字new调用构造函数创建两个新对象,
变量ninja1和变量ninja2分别引用了这两个新对象
ninja1.skulk() === ninja1 // true
ninja2.skulk() === ninja2 // true
⇽--- 检测已创建对象中的skulk方法。每个方 法都应该返回自身已创建的对象
关键字new调用函数会触发以下几个动作:
1.创建一个新的空对象。
2.该对象作为this参数传递给构造函数,从而成为构造函数的函数
上下文。
3.新构造的对象作为new运算符的返回值。
构造函数的目的是创建一个新对象,并进行初始化设置,然后将其作为构造函数的返回值
构造函数有返回值且返回值为简单数据类型的情况:
function Ninja() {
⇽--- 定义一个叫做Ninja的构造函数
this.skulk = function () {
return true;
};
return 1; ⇽--- 构造函数返回一个确定的原始类型值,即数字1
}
Ninja() === 1, ⇽--- 该函数 以函数的形式被调用,正如预期,其返回值为数字1
var ninja = new Ninja(); ⇽--- 该函数通过new关键字以构造函数的形式被调用
typeof ninja === "object"
typeof ninja.skulk === "function"
⇽--- 测试表明,返回值1被忽略了,一个新的被初始化的对象被通过关键字new所返回
构造函数有返回值且返回值为对象的情况:
var puppet = {
rules: false
}; ⇽--- 创建一个全局对象,该对象的rules属性设置为false
function Emperor() {
this.rules = true;
return puppet;
} ⇽--- 尽管初始化了传入的this对象,返回该全局对象
var emperor = new Emperor(); ⇽--- 作为构造函数调用该函数
emperor === puppet
emperor.rules === false
⇽--- 测试表明,变量emperor 的值为由构造函数返回的对象,而不是new表达式所返回的对象
puppet对象最终作为构造函数调用的返回值,而且在构造函数中对函数上下文的操作都是无效的
总结:
如果构造函数返回一个对象,则该对象将作为整个表达式的值返回,而传入构造函数的this将被丢弃。但是,如果构造函数返回的是非对象类型,则忽略返回值,返回新创建的对象
当构造函数被作为简单函数来调用
function Ninja() {
this.skulk = function() {
return this;
};
}
var whatever = Ninja();
如果在非严格模式下调用的话,skulk属性将创建在window对象上,
因为在严格模式下this并未定义。
4.使用apply和call方法调用
不同类型函数调用之间的主要区别在于:
最终作为函数上下文(可以通过this参数隐式引用到)传递给执行函数的对象不同。
对于方法而言,即为方法所在的对象;
对于顶级函数而言是window或者undefined(取决于是否处于严格模式下);
对于构造函数而言是一个新创建的对象实例。
function juggle() {
var result = 0;
for (var n = 0; n < arguments.length; n++) {
result += arguments[n];
}
this.result = result;
} ⇽--- 函数“处理”了参数,并将结果result变量放在任意一个作为该函数上下文的对 象上
var ninja1 = {
};
var ninja2 = {
}; ⇽--- 这些对象的初始值为空,它们会作为测试对象
juggle.apply(ninja1,[1,2,3,4]); ⇽--- 使用apply方法向ninja1传递一个参数 数组
juggle.call(ninja2, 5,6,7,8); ⇽--- 使用call方法向ninja2传递一个参数列表
ninja1.result === 10
ninja2.result === 26 ⇽--- 测试展现了传入ju ggle方法中的对象拥有了结果值
apply与call的功能类似,但问题是在二者中如何选择?
答案是选择与现有参数相匹配的方法。
如果有一组无关的值,则直接使用call方法。若已有参数是数组类型,apply方法是更佳选择。
5.箭头函数
箭头函数没有单独的this值。箭头函数的this与声明所在的上下文的相同。
调用箭头函数时,不会隐式传入this参数,而是从定义时的函数继承上下文。
在全局代码中定义对象字面量,在字面量中定义箭头函数,那么箭头函数内的this指向全局window对象
<button id="test">Click Me! </button>
<script>
assert(this === window, "this === window"); ⇽--- 全局代码中的this指向 全局window对象
var button = {
⇽--- 使用对象字面量定义button
clicked: false,
click: () => {
⇽--- 箭头函数是对象字面量的属性
this.clicked = true;
assert(button.clicked,"The button has been clicked"); ⇽--- 验证 是否单击按钮
assert(this === window, "In arrow function this === window"); ⇽- -- 箭头函数中的this指向全局window对象
assert(window.clicked, "clicked is stored in window"); ⇽--- clicked属性存储在window对象上
}
}
var elem = document.getElementById("test");
elem.addEventListener("click", button.click);
</script>
6.bind方法
所有函数均可访问bind方法,可以创建并返回一个新函数,并绑定在传入的对象上
小结

闭包和作用域
如果没有闭包,事件处理和动画等包含回调函数的任务,它们的实现将变得复杂得多。除此之外,如果没有闭包,将完全不可能实现私有变量。
闭包允许函数访问并操作函数外部的变量。
只要变量或函数存在于声明函数时的作用域内,闭包即可使函数能够访问这些变量或函数。
一个简单的闭包
var outerValue = "ninja"; ⇽--- 在全局作用域中定义一个变量
function outerFunction() {
assert(outerValue === "ninja", "I can see the ninja.");
⇽--- 在全局作用域中声明函数
}
outerFunction(); ⇽--- 执行该函数
我们在同一作用域中声明了变量outerValue及外部函数outerFunction——本例中,是全局作用域。
因为外部变量outerValue和外部函数outerFunction都是在全局作用域中声明的,该作用域(实际上就是一个闭包)从未消失(只要应用处于运行状态)。这也不足为奇,该函数可以访问到外部变量,因为它(这个外部变量)仍然在作用域内并且是可见的。
var outerValue = "samurai";
var later;
function outerFunction() {
var innerValue = "ninja";
function innerFunction() {
assert(outerValue === "samurai", "I can see the samurai.");
assert(innerValue === "ninja", "I can see the ninja.")
}
later = innerFunction;
}
outerFunction();
later();
关键:尽管试图隐藏在函数体内,但是仍然能够检测到ninja变量。
当在外部函数中声明内部函数时,不仅定义了函数的声明,而且还创建了一个闭包。该闭包不仅包含了函数的声明,还包含了在函数声明时该作用域中的所有变量。当最终执行内部函数时,尽管声明时的作用域已经消失了,但是通过闭包,仍然能够访问到原始作用域。
正如保护气泡一样,只要内部函数一直存在,内部函数的闭包就一直保存着该函数的作用域中的变量。
这就是闭包。闭包创建了被定义时的作用域内的变量和函数的安全气泡,因此函数获得了执行时所需的内容。该气泡与函数本身一起包含了函数和变量。
谨记每一个通过闭包访问变量的函数都具有一个作用域链,作用域链包含闭包的全部信息,这一点非常重要。因此,虽然闭包是非常有用的,但不能过度使用。使用闭包时,所有的信息都会存储在内存中,直到JavaScript引擎确保这些信息不再使用(可以安全地进行垃圾回收)或页面卸载时,才会清理这些信息
闭包的使用
1.封装私有变量
在构造器中隐藏变量,使其在外部作用域中不可访问,但是可在闭包内部进行访问。
function Ninja() {
⇽--- 定义Ninja构造函数
var feints = 0;
⇽--- 在构造函数内部声明一个变量,因为所声明的变量的作用域局限于构造函数的内部,
所以它是一个“私有”变量。我们使用该变量统计Ninja佯攻的次数
this.getFeints = function() {
return feints;
⇽--- 创建用于访问计数变量feints的方法。由于在构造函数
外部的代码是无法访问feints变量的,这是通过只读形式访问该变量的常用方法
};
this.feint = function() {
feints++;
};
⇽--- 为feints变量声明一个累加方法。由于feints为私有变量,在外部是无法累加的,
累加过程则被限制在我们提供的方法中
}
var ninja1 = new Ninja();
⇽--- 现在开始测试,首先创建一个Ninja的实例
ninja1.feint();
⇽--- 调用feint方法,通过该方法增加Ninja的佯攻次数
assert(ninja1.feints === undefined,
⇽--- 验证我们无法直接获取该变量值);
⇽--- 虽然我 们无法直接对feints变量赋值,但是我们仍然能够通过getFeints方法操作该变量的值
var ninja2 = new Ninja();
assert(ninja2.getFeints() === 0,
"The second ninja object gets its own feints variable.");
⇽--- 当我们通过ninja构造函数创建一个新的ninja2实例时,ninja2对象则具有
自己私有的feints变量
2.回调函数
处理回调函数是另一种常见的使用闭包的情景。回调函数指的是需要在将来不确定的某一时刻异步调用的函数。通常,在这种回调函数中,我们经常需要频繁地访问外部数据。
<div id="box1">First Box</div>
⇽--- 创建用于展示动画的DOM元素
<script>
function animateIt(elementId) {
var elem = document.getElementById(elementId);
⇽--- 在动画函数ani mateLt内部,获取DOM元素的引用
var tick = 0; ⇽--- 创建一个计时器用于记录动画执行的次数
var timer = setInterval(function() {
⇽--- 创建并启动一个JavaScript 内置的计时器,传入一个回调函数
if (tick < 100) {
elem.style.left = elem.style.top = tick + "px";
tick++;
} ⇽--- 每隔10毫秒调用一次计时器的回调函数,调整元素的位置100次
else {
clearInterval(timer);
assert(tick === 100,
⇽--- 执行了100次之后,停止计时器,并验证我 们还可以看到与执行动画有关的变量
"Tick accessed via a closure.");
assert(elem,
"Element also accessed via a closure.");
assert(timer,
"Timer reference also obtained via a closure.");
}
}, 10);
⇽--- setInterval函数的持续时间为10毫秒,也就是说回调函数每隔10毫秒调用一次
}
animateIt("box1"); ⇽--- 全部设置完成之后,我们可以执行动画函数并查看动画效果
</script>
通过在函数内部定义变量,并基于闭包,使得在计时器的回调函数中可以访问这些变量,每个动画都能够获得属于自己的“气泡”中的私有变量。
如果我们把变量放在全局作用域中,那么需要为每个动画分别设置3个变量,否则同时用3个变量来跟踪多个不同动画的状态,动画的状态就会发生冲突。
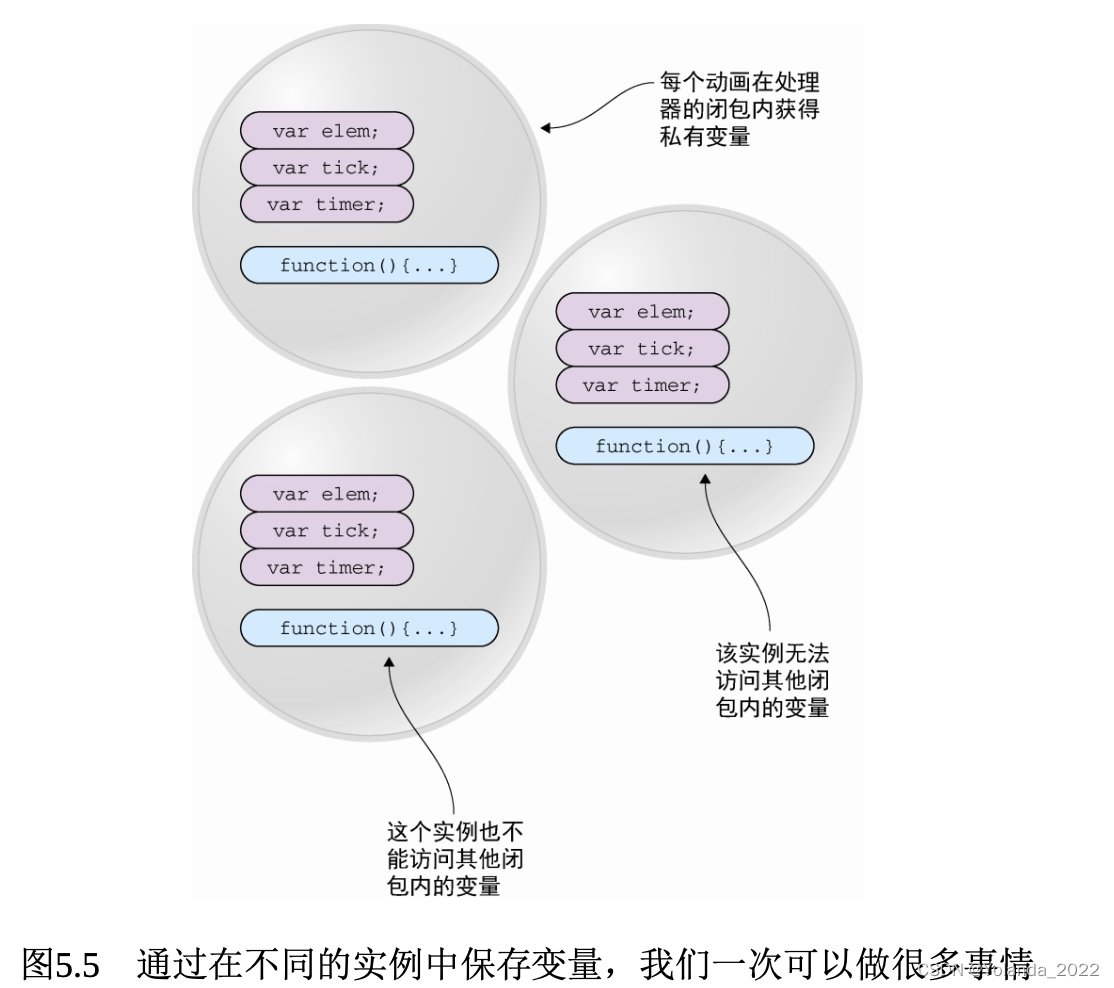
通过执行上下文来跟踪代码
当调用函数时可通过关键字访问函数上下文。函数执行上下文,虽然也称为上下文,但完全是不一样的概念。
执行上下文是内部的JavaScript概念,JavaScript引擎使用执行上下文来跟踪函数的执行。
有两种执行上下文: 全局执行上下文和函数执行上下文。
二者最重要的差别是:全局执行上下文只有一个,当JavaScript程序开始执行时就已经创建了全局上下文;而函数执行上下文是在每次调用函数时,就会创建一个新的。
JavaScript基于单线程的执行模型:在某个特定的时刻只能执行特定的代码。一旦发生函数调用,当前的执行上下文必须停止执行,并创建新的函数执行上下文来执行函数。当函数执行完成后,将函数执行上下文销毁,并重新回到发生调用时的执行上下文中。所以需要跟踪执行上下文——正在执行的上下文以及正在等待的上下文。最简单的跟踪方法是使用执行上下文栈(或称为调用栈)。
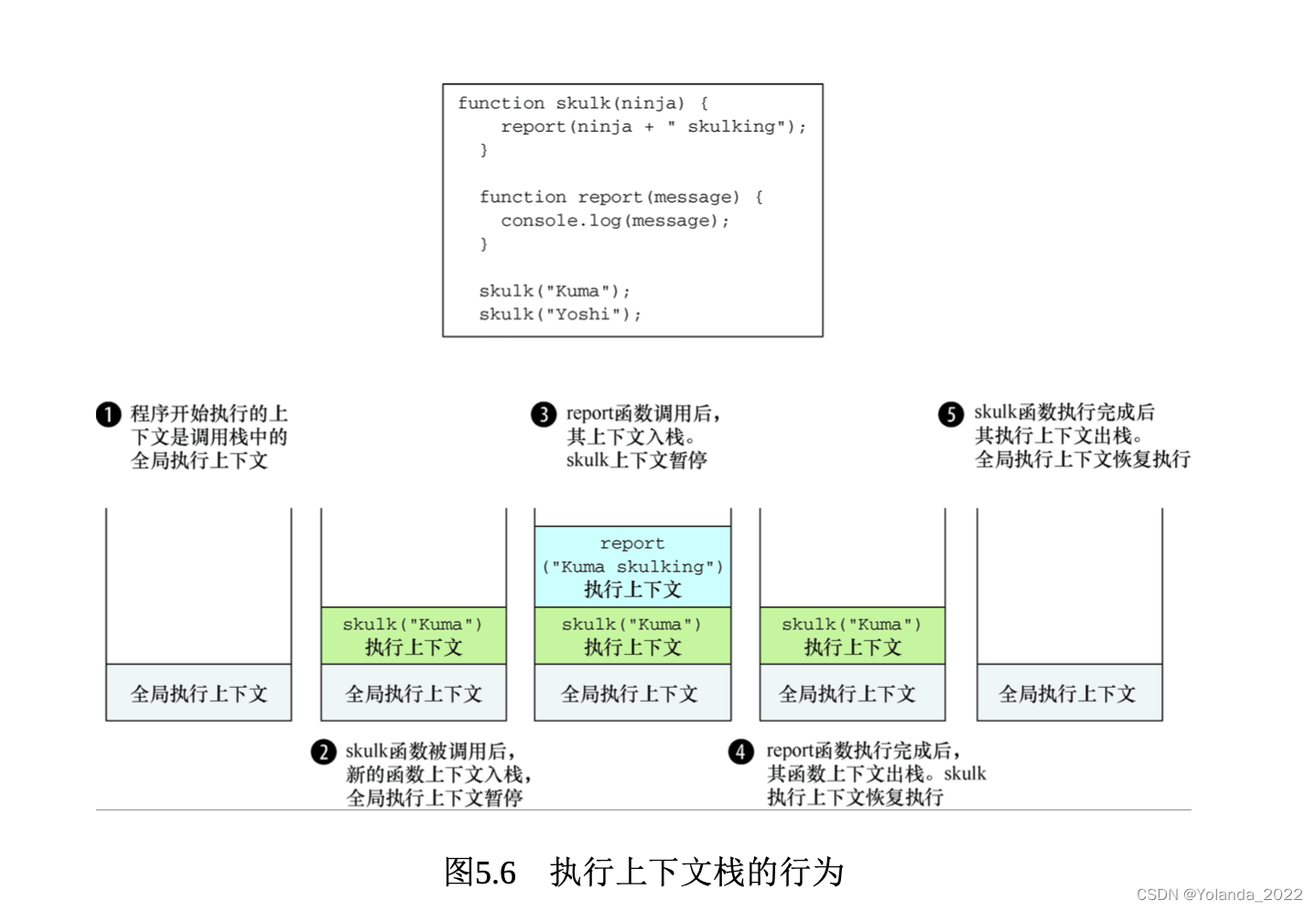
每个JavaScript程序只创建一个全局执行上下文,并从全局执行上下文开始执行(在单页应用中每个页面只有一个全局执行上下文)在上面的过程中我们不断创建新的函数执行上下文,并置入执行上下文栈的顶部。
在同一个特定时刻只能执行特定代码。
使用词法环境跟踪变量的作用域
内部代码结构可以访问外部代码结构中定义的变量。
js中的变量类型
const
我们不能将一个全新的值赋值给const变量。但是,我们可以修改const变量已有的对象。例如,我们可以给已有对象添加属性
var
var globalNinja = "Yoshi";
function reportActivity() {
var functionActivity = "jumping";
for (var i = 1; i < 3; i++) {
var forMessage = globalNinja + " " + functionActivity;
assert(forMessage === "Yoshi jumping",
"Yoshi is jumping within the for block");
assert(i, "Current loop counter:" + i);
}
assert(i === 3 && forMessage === "Yoshi jumping",
"Loop variables accessible outside of the loop");
⇽--- 但是 在for循环外部,仍然能访问for循环中定义的变量
}
reportActivity();
assert(typeof functionActivity === "undefined"
&& typeof i === "undefined" && typeof forMessage === "undefined",
"We cannot see function variables outside of a function");
让人困惑的是,即使在块级作用域内定义的变量,在块级作用域外仍然能够被访问。
这源于通过var声明的变量实际上总是在距离最近的函数内或全局词法环境中注册的,不关注块级作用域。
因为var是函数作用域。
通过var声明变量,在距离最近的函数内或全局词法环境中定义(忽略块级作用域)。在如上的示例中,变量forMessage与i虽然是被包含在for循环中,但实际是在reportActivity环境中注册的(距离最近的函数环境)
使用let与const定义具有块级作用域的变量
let和const直接在最近的词法环境中定义变量(可以是在块级作用域内、循环内、函数内或全局环境内)。
我们可以使用let和const定义块级别、函数级别、全局级别的变量。
在词法环境中注册标识符
如果在check函数声明前去调用这个函数,是不会有问题的,但是代码如何逐行执行,JavaScript引擎是如何知道check函数存在呢?这说明JavaScript引擎耍了小把戏,JavaScript代码的执行事实上是分两个阶段进行的。
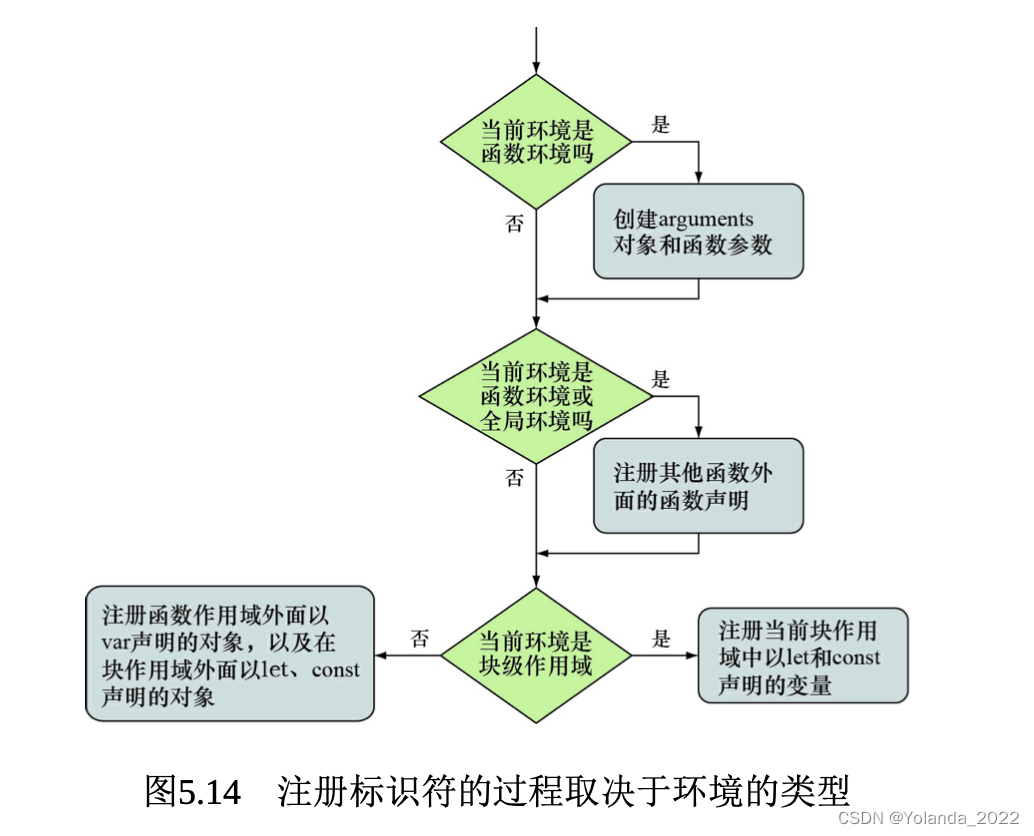
一旦创建了新的词法环境,就会执行第一阶段。在第一阶段,没有执行代码,但是JavaScript引擎会访问并注册在当前词法环境中所声明的变量和函数。JavaScript在第一阶段完成之后开始执行第二阶段,具体如何执行取决于变量的类型(let、var、const和函数声明)以及环境类型(全局环境、函数环境或块级作用域)。
具体的处理过程如下:
1.如果是创建一个函数环境,那么创建形参及函数参数的默认值。如果是非函数环境,将跳过此步骤。
2.如果是创建全局或函数环境,就扫描当前代码进行函数声明(不会扫描其他函数的函数体),但是不会扫描函数表达式或箭头函数。对于所找到的函数声明,将创建函数,并绑定到当前环境与函数名相同的标识符上。若该标识符已经存在,那么该标识符的值将被重写。如果是块级作用域,将跳过此步骤。
3.扫描当前代码进行变量声明。在函数或全局环境中,找到所有当前函数以及其他函数之外通过var声明的变量,并找到所有在其他函数或代码块之外通过let或const定义的变量。在块级环境中,仅查找当前块中通过let或const定义的变量。对于所查找到的变量,若该标识符不存在,进行注册并将其初始化为undefined。若该标识符已经存在,将保留其值。
整个处理过程如下图所示:
为什么可以在函数声明之前调用函数
我们可以这么做的原因是fun是通过函数声明进行定义的,第二阶段表明函数已通过函数声明进行定义,在当前词法环境创建时已在其他代码执行之前注册了函数标识符。
JavaScript引擎通过这种方式为开发者提供便利,允许我们直接使用函数的引用,而不需要强制指定函数的定义顺序。
需要注意的是,这种情况仅针对函数声明有效。函数表达式与箭头函数都不在此过程中,而是在程序执行过程中执行定义的。这就是不能提前访问函数表达式与箭头函数的原因。
函数重载
assert(typeof fun === "function", "We access the function");
var fun = 3;
assert(typeof fun === "number", "Now we access the number");
function fun(){
}
assert(typeof fun === "number", "Still a number"); ⇽--- fun 仍然指向数字
在如上的示例中,声明的变量与函数均使用相同的名字fun。如果你执行这段代码会发现,两个断言assert都通过了。
在第一个断言中,标识符fun指向一个函数;在第二个断言中,标识符fun指向一个数字。
JavaScript的这种行为是由标识符注册的结果直接导致的。
在处理过程的第2步中,通过函数声明进行定义的函数在代码执行之前对函数进行创建,并赋值给对应的标识符;
在第3步,处理变量的声明,那些在当前环境中未声明的变量,将被赋值为undefined。
在如上的示例中,在第2步——注册函数声明时,由于标识符fun已经存在,并未被赋值为undefined。这就是第1个测试fun是否是函数的断言执行通过的原因。
之后,执行赋值语句var fun = 3,将数字3赋值给标识符fun。执行完这个赋值语句之后,fun就不再指向函数了,而是指向数字3。
在程序的实际执行过程中,跳过了函数声明部分,所以函数的声明不会影响标识符fun的值。
生成器函数
function* WeaponGenerator() {
⇽--- 通过在关键字function后面添加星号*定义 生成器函数
yield "Katana";
yield "Wakizashi";
yield "Kusarigama";
⇽--- 使用新的关键字yield生成独立的值
}
for (let weapon of WeaponGenerator()) {
console.log(weapon !== undefined, weapon);
} ⇽--- 使用新的循环类型for-of取出生成的值序列
// 打印结果如下
true Katana
true Wakizashi
true Kusarigama
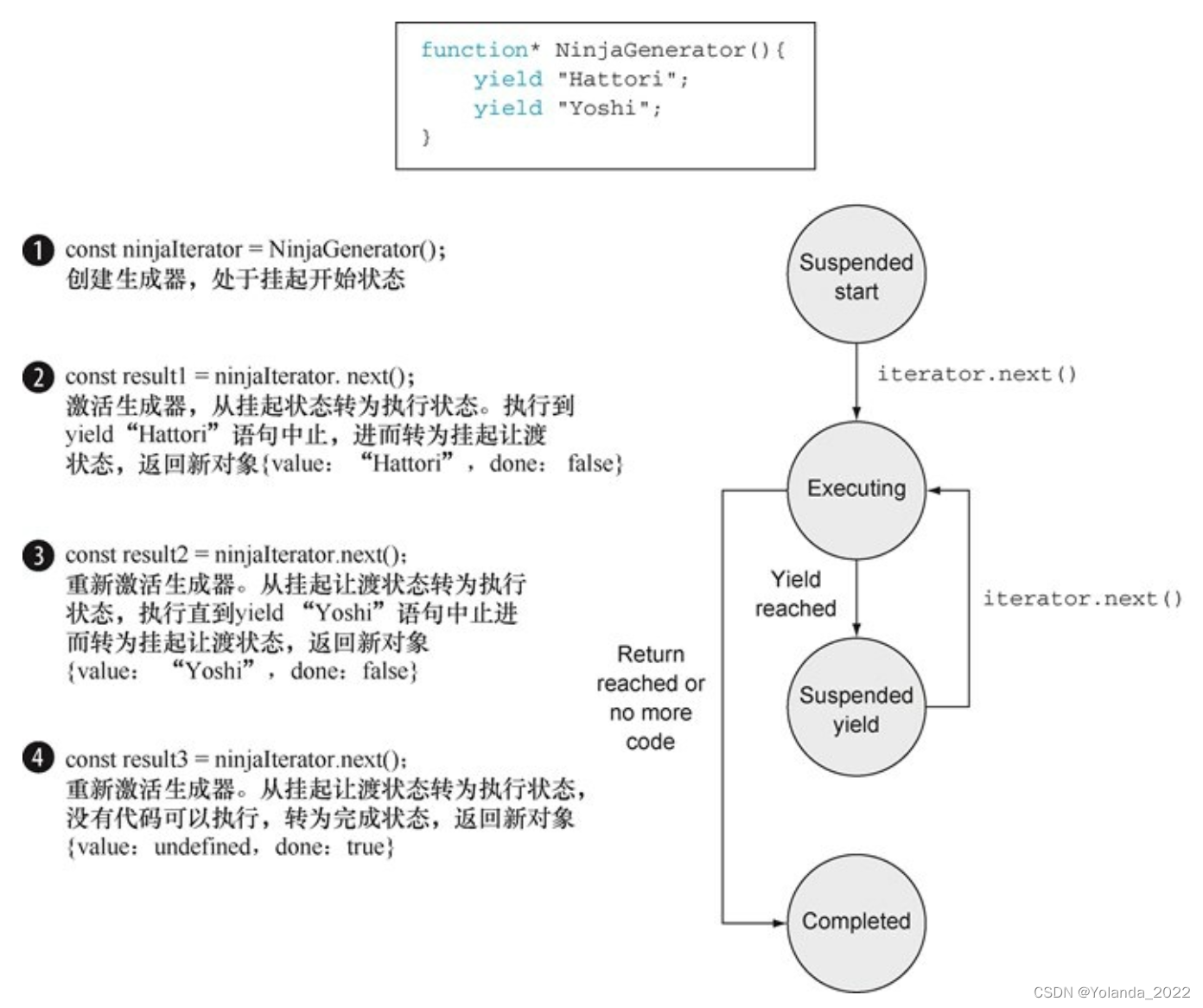
生成器函数和标准函数非常不同。对初学者来说,调用生成器并不会执行生成器函数,相反,它会创建一个叫作迭代器(iterator)的对象。
function* WeaponGenerator() {
yield "Katana";
yield "Wakizashi";
}
// ⇽--- 定义一个生成器,它能生成一个包含两个武器数据的序列
const weaponsIterator = WeaponGenerator();
// ⇽--- 调用生成器得到一个迭代器 ,从而我们能够控制生成器的执行
const result1 = weaponsIterator.next();
// ⇽--- 调用迭代器的next方法向生成器请求一个新值
assert(typeof result1 === "object"
&& result1.value === "Katana"
&& !result1.done,
"Katana received!");
// ⇽--- 结果为一个对象,其中包含着一个返回值,及一个指示器告诉我们生成器是否还会生成值
const result2 = weaponsIterator.next();
assert(typeof result2 === "object"
&& result2.value === "Wakizashi" && !result2.done,
"Wakizashi received!"
);
// ⇽--- 再次调用next方法从生成器中获取新值
const result3 = weaponsIterator.next();
assert(typeof result3 === "object"
&& result3.value === undefined && result3.done,
"There are no more results!"
);
// ⇽--- 当没有可执行的代码,生成器就会返回“undefined”值,表示它的状态为已经完成
从迭代器遍历看for-of的实现原理:
function* WeaponGenerator(){
yield "Katana";
yield "Wakizashi";
}
const weaponsIterator = WeaponGenerator();
⇽--- 新建一个迭代器
let item;
⇽--- 创建一个变量,用这个变量来保存生成器产生的值
while(!(item = weaponsIterator.next()).done) {
assert(item !== null, item.value);
}
⇽--- 每次循环都会从生成器中取出一个值,然后输出该值。当生成器不会再生成值 的时候,停止迭代
while(!(item = weaponsIterator.next()).done) {
assert(item !== null, item.value)
}
for-of循环不过是对迭代器进行迭代的语法糖。
把执行权交给下一个生成器
function* WarriorGenerator(){
yield "Sun Tzu";
yield* NinjaGenerator();
⇽--- yield*将执行权交给了另一个生成器
yield "Genghis Khan";
}
function* NinjaGenerator(){
yield "Hattori";
yield "Yoshi";
}
for(let warrior of WarriorGenerator()){
assert(warrior !== null, warrior);
}
执行这段代码后会输出 Sun Tzu、Hattori、Yoshi、Genghis Khan。
在迭代器上使用yield*操作符,程序会跳转到另外一个生成器上执行。本例中,程序从WarriorGenerator跳转到一个新的NinjaGenerator生成器上,每次调用WarriorGenerator返回迭代器的next方法,都会使执行重新寻址到了NinjaGenerator上。该生成器会一直持有执行权直到无工作可做。所以我们本例中生成Sun Tzu之后紧接的是Hattori和Yoshi。仅当NinjaGenerator的工作完成后,调用原来的迭代器才会继续输出值Genghis Khan。
注意,对于调用最初的迭代器代码来说,这一切都是透明的。
for-of循环不会关心WarriorGenerator委托到另一个生成器上,它只关心在done状态到来之前都一直调用next方法。
使用生成器
1.用生成器生成ID序列
function* IdGenerator() {
⇽--- 定义生成器函数IdGenerator
let id = 0; ⇽--- 一个始终记录ID的变量,这个变量无法在生成器外部改变 while (true) {
yield ++id;
} ⇽--- 循环生成无限长度的ID序列
}
const idIterator = IdGenerator(); ⇽--- 这个迭代器我们能够向生成器请求新的 ID值
const ninja1 = {
id: idIterator.next().value };
const ninja2 = {
id: idIterator.next().value };
const ninja3 = {
id: idIterator.next().value }; ⇽--- 请求3个新ID值
assert(ninja1.id === 1, "First ninja has id 1");
assert(ninja2.id === 2, "Second ninja has id 2");
assert(ninja3.id === 3, "Third ninja has id 3"); ⇽--- 测试运行结果
标准函数中一般不应该书写无限循环的代码。但在生成器中没问题!当生成器遇到了一个yield语句,它就会一直挂起执行直到下次调用next方法,所以只有每次调用一次next方法,while循环才会迭代一次并返回下一个ID值。
2.使用迭代器遍历DOM树
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<div id="subTree">
<form>
<input type="text"/>
</form>
<p>Paragraph</p>
<span>Span</span>
</div>
<script>
function* DomTraversal(element){
yield element;
element = element.firstElementChild;
while (element) {
yield* DomTraversal(element);
// ⇽--- 用yield将迭代控制转移到另一个Dom Traversal生成器实例上
element = element.nextElementSibling;
}
}
const subTree = document.getElementById("subTree");
// 打印出来当前element的标签名称
for(let element of DomTraversal(subTree)) {
console.log(element !== null, element.nodeName);
}
</script>
</body>
</html>
作为生成器函数参数发送值
function* NinjaGenerator(action) {
// ⇽--- 生成器可以像其他函数一样接收标准参数
const imposter = yield ("Hattori " + action);
// ⇽--- 奇迹出现了。产生一个值的同时,生成器会返回一个中间计算结果。
// 通过带有参数的调用迭代器的next方法,我们可以将数据传递回生成器
console.log(imposter === "Hanzo",
"The generator has been infiltrated");
yield ("Yoshi (" + imposter + ") " + action);
// ⇽--- 传递回的值将成为yield表达式的返回值,因此impostrer的值是Hanzo
}
const ninjaIterator = NinjaGenerator("skulk");
const result1 = ninjaIterator.next();
console.log(result1.value === "Hattori skulk","Hattori is skulking");
const result2 = ninjaIterator.next("Hanzo");
console.log(result2.value === "Yoshi (Hanzo) skulk",
"We have an imposter!");
抛出异常
function* NinjaGenerator() {
try{
yield "Hattori";
fail("The expected exception didn't occur");
// ⇽--- 此处的错误将不会发生
}
catch(e){
assert(e === "Catch this!", "Aha! We caught an exception");
// ⇽--- 捕获异常并检测接收到的异常是否符合预期
}
}
const ninjaIterator = NinjaGenerator();
const result1 = ninjaIterator.next();
assert(result1.value === "Hattori", "We got Hattori");
// ⇽--- 从生成器拉取一个值
ninjaIterator.throw("Catch this!");
// ⇽--- 向生成器抛出一个异常
探索生成器内部构成(187页码)
当程序从生成器中执行完毕后,发生了一个有趣的现象。一般情况下,当程序从一个标准函数返回后,对应的执行环境上下文会从栈中弹出,并被完整地销毁。但在生成器中不是这样。
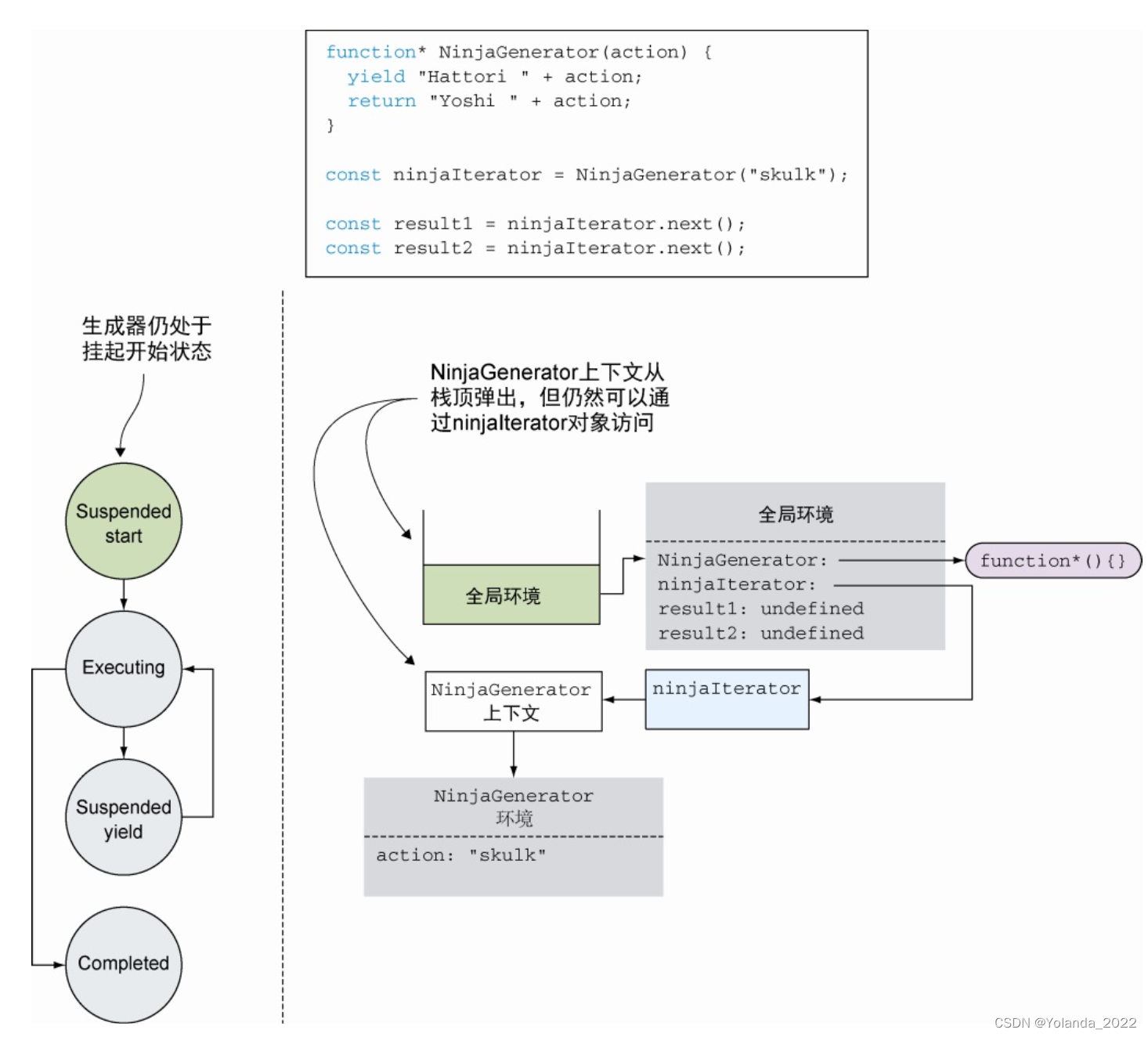
相对应的NinjaGenerator会从栈中弹出,但由于ninjaIterator还保存着对它的引用,所以它不会被销毁。
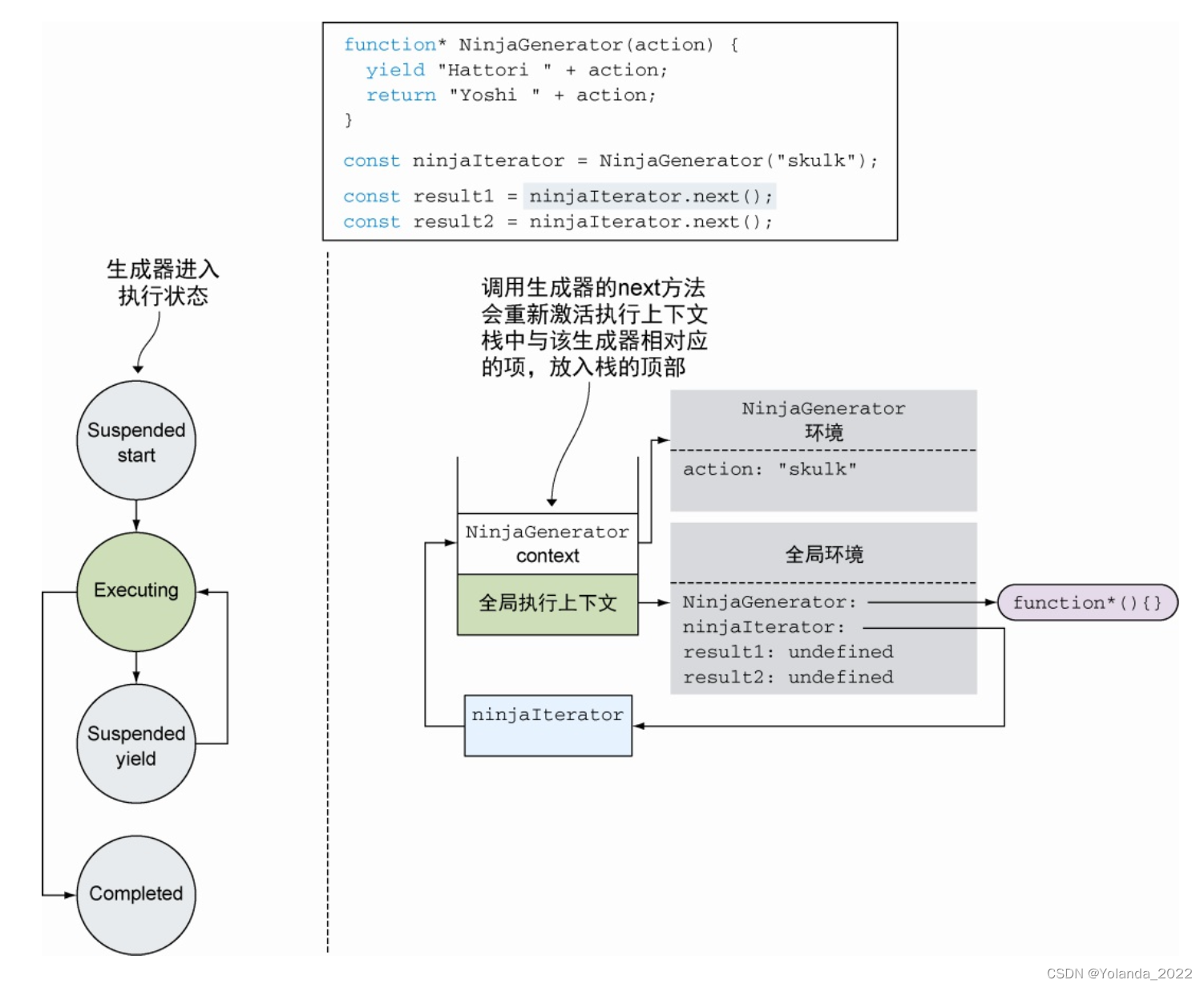
如上图,如果这只是一个普通的函数调用,这个语句会创建一个新的next()的执行环境上下文项,并放入栈中。但你可能注意到了,生成器绝不标准,对next方法调用的表现也很不同。它会重新激活对应的执行上下文。在这个例子中,是NinjaGenerator上下文,并把该上下文放入栈的顶部,从它上次离开的地方继续执行。
调用生成器的next方法会重新激活执行上下文栈中与该生成器相对应的项,首先将该项入栈,然后从它上次退出的位置继续执行。
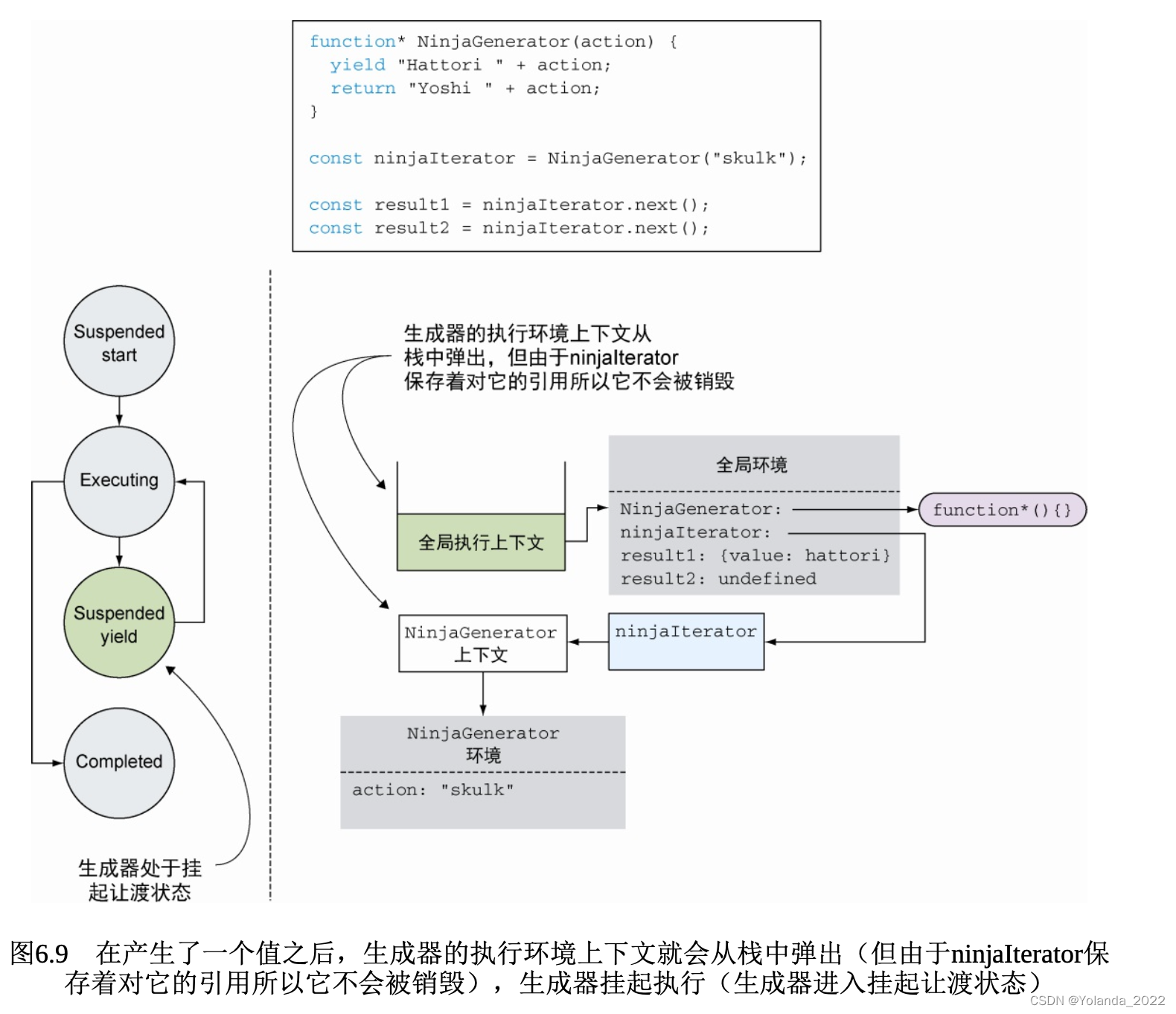

在这个位置,我们又把整个流程走了一遍:首先通过ninjaIterator激活NinjaGenerator的上下文引用,将其入栈,在上次离开的位置继续执行。本例中,生成器计算表达式"Yoshi " + action。但这一次没再遇到yield表达式,而是遇到了一个return语句。这个语句会返回值Yoshi skulk并结束生成器的执行,随之生成器进入结束状态。
generator的特性
当我们从生成器中取得控制权后,生成器的执行环境上下文一直是保存的,不是像标准函数一样退出后销毁。
使用promise
promise对象用于作为异步任务结果的占位符。它代表了一个我们暂时还没获得但在未来有希望获得的值。


生成器和promise的结合
async(function*(){
try {
const ninjas = yield getJSON("data/ninjas.json");
const missions = yield getJSON(ninjas[0].missionsUrl);
const missionDescription = yield getJSON(missions[0].detailsUrl);
}
catch(e) {
//Oh no, we weren't able to get the mission details
}
});
function async(generator) {
var iterator = generator();
function handle(iteratorResult) {
if(iteratorResult.done) {
return;
}
const iteratorValue = iteratorResult.value;
if(iteratorValue instanceof Promise) {
iteratorValue
.then(res => handle(iterator.next(res)))
.catch(err => iterator.throw(err));
}
}
try {
handle(iterator.next());
}
catch (e) {
iterator.throw(e);
}
}
面向对象与原型
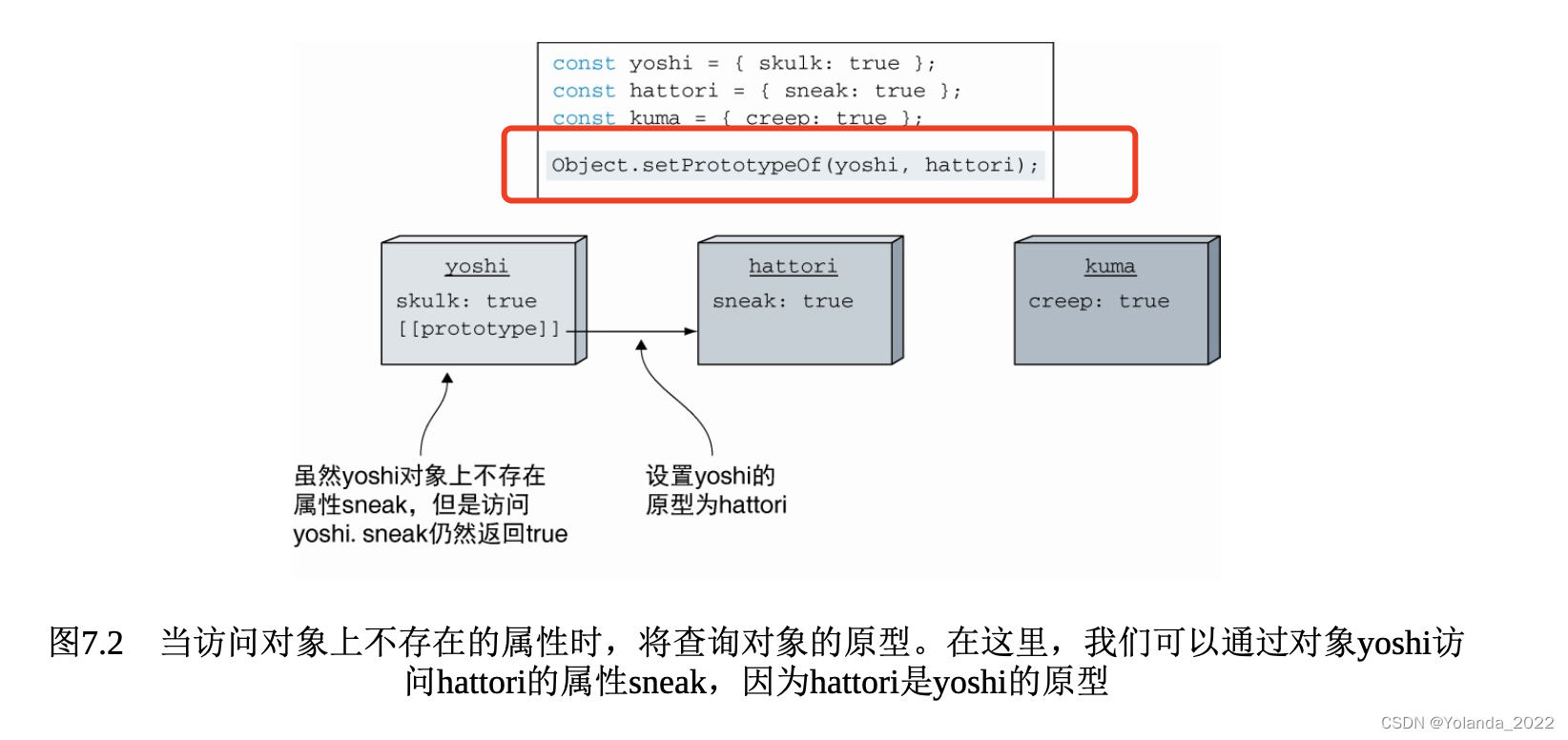
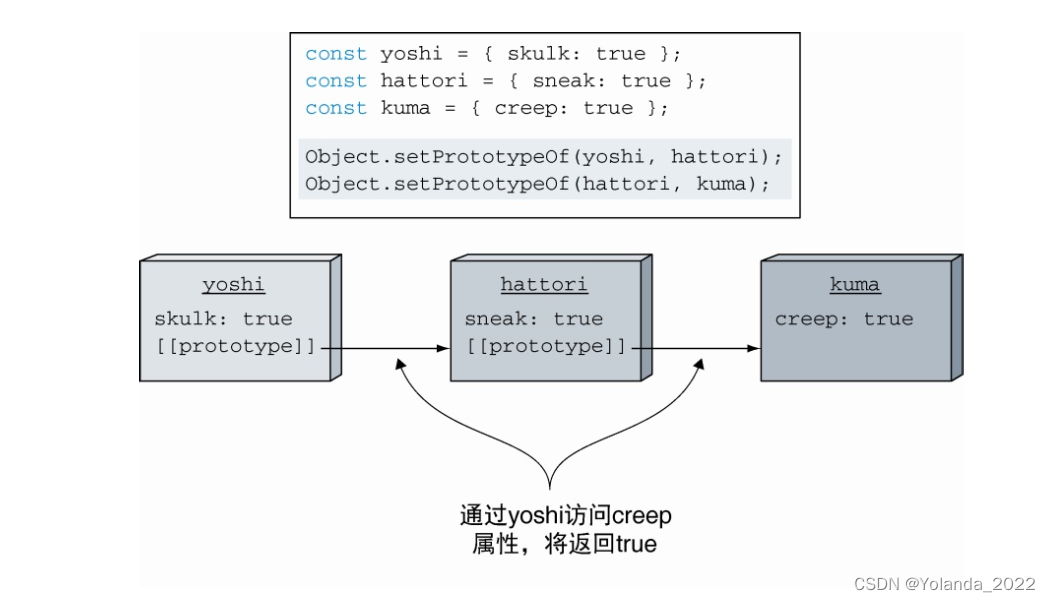
每个对象都可以有一个原型,每个对象的原型也可以拥有一个原型,以此类推,形成一个原型链。查找特定属性将会被委托在整个原型链上,只有当没有更多的原型可以进行查找时,才会停止查找。
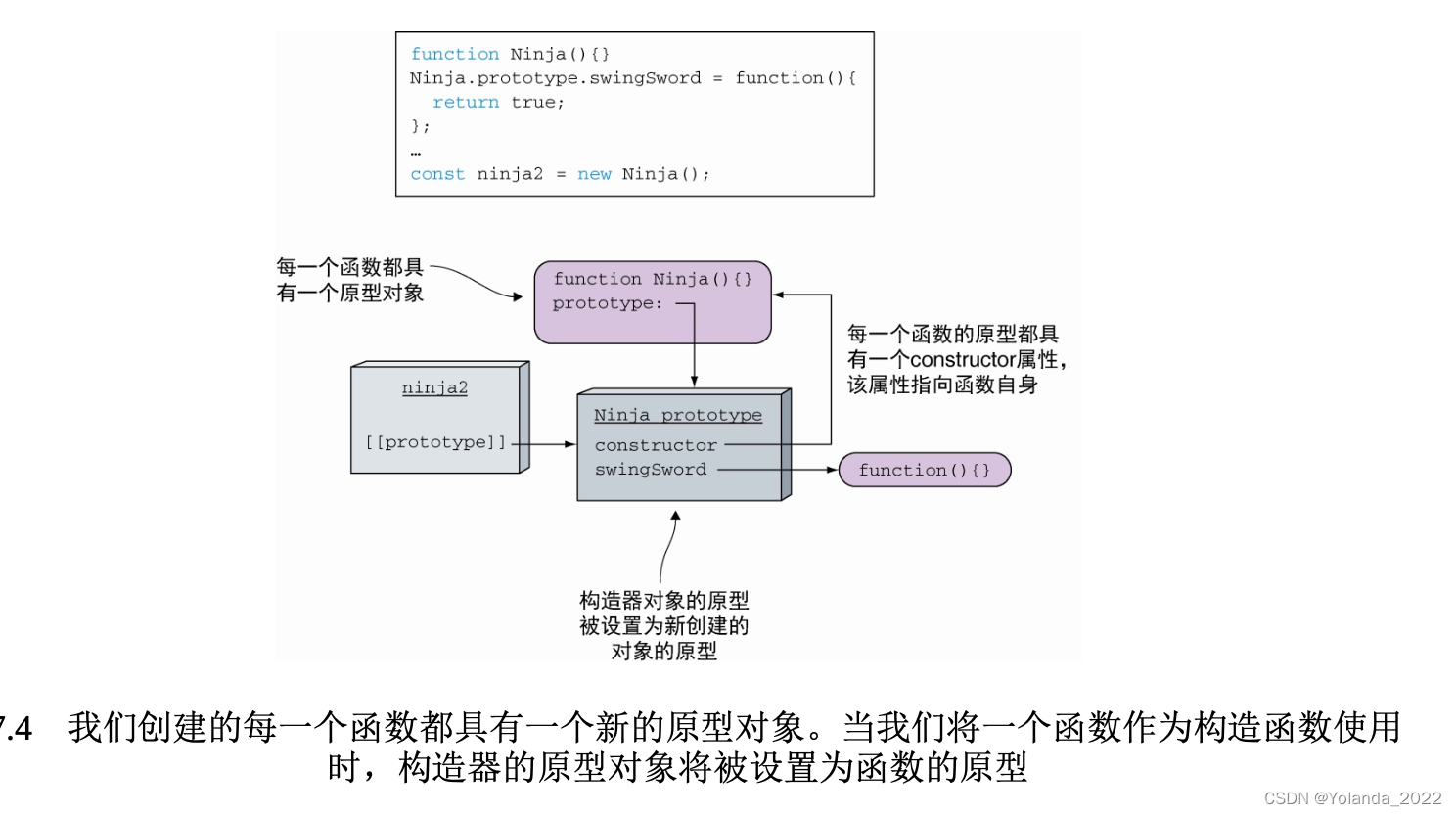
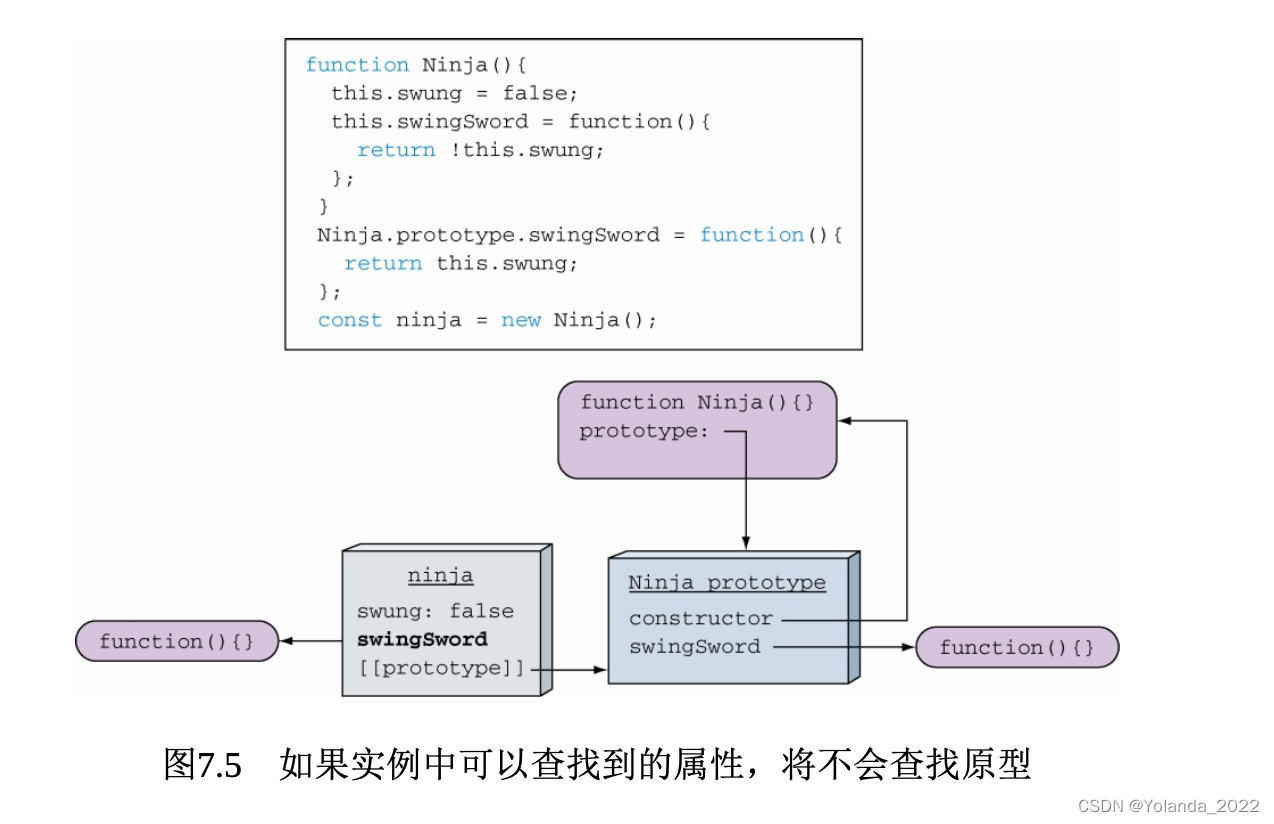
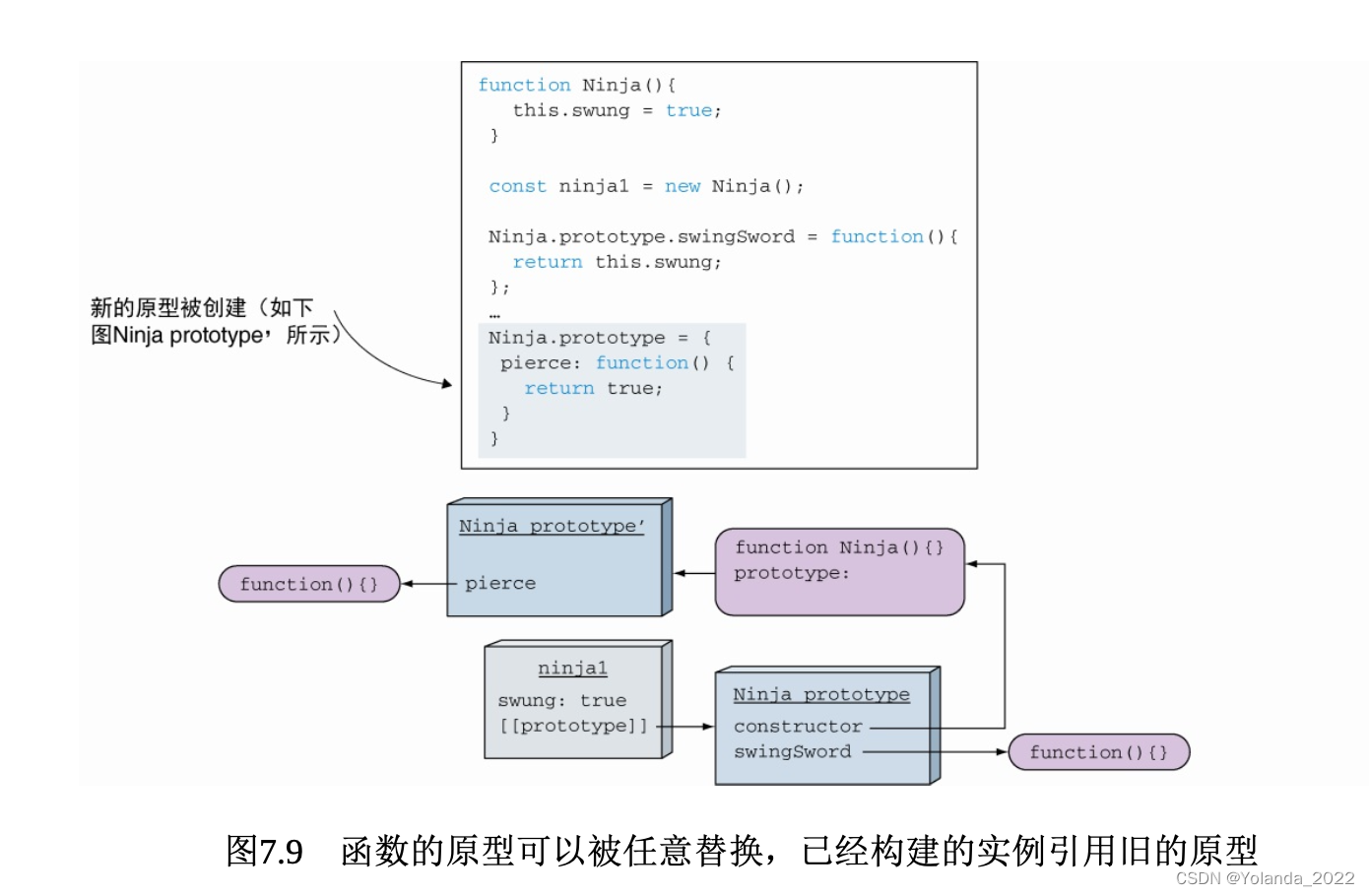
即使Ninja函数不再指向旧的Ninja原型,但是旧的原型仍然存在于ninja1的实例中,通过原型链仍然能够访问swingSword方法。但是,如果我们在Ninja发生这些变化之后再创建新的实例对象,此时应用程序的状态如图7.10所示。
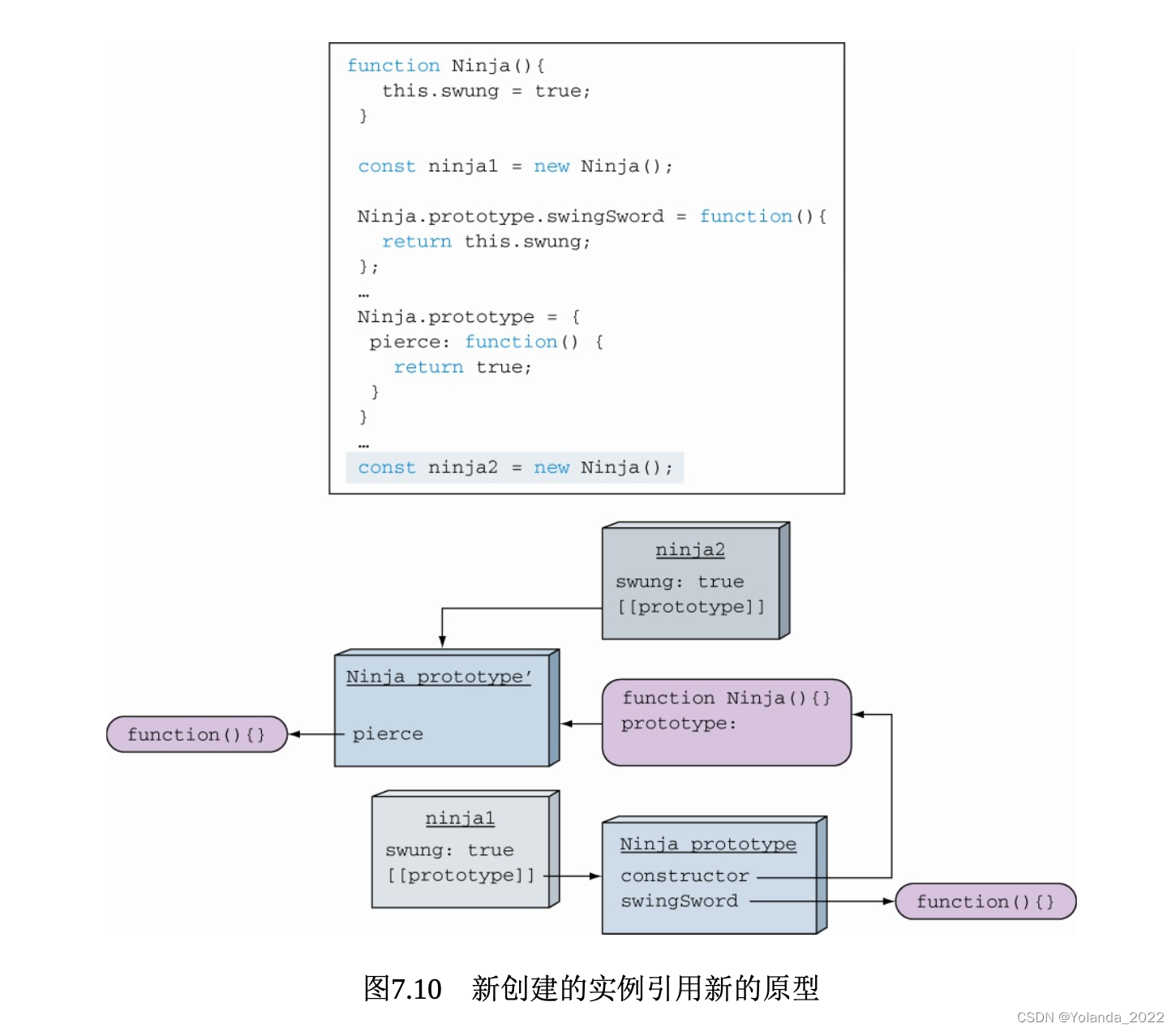
对象与函数原型之间的引用关系是在对象创建时建立的。新创建的对象将引用新的原型,它只能访问pierce方法,原来旧的对象保持着原有的原型,仍然能够访问swingSword方法。
通过构造函数实现对象类型
检查实例的类型与它的constructor
function Ninja(){
}
const ninja = new Ninja();
assert(typeof ninja === "object",
// ⇽--- 通过typeof检测ninja的类型,但从结 果仅仅能够得知ninja是一个对象而已
"The type of the instance is object."
);
assert(ninja instanceof Ninja,
// ⇽--- 通过instanceof检测ninja的类型,其结 果提供更多信息——ninja是由Ninja构造而来的
"instanceof identifies the constructor."
);
assert(ninja.constructor === Ninja,
// ⇽--- 通过constructor引用检测ninja 的类型,得到的结果为其构造函数的引用
"The ninja object was created by the Ninja function."
);
instanceof,它提供了一种用于检测一个实例是否由特定构造函数创建的方法。
我们可以使用constructor属性,所有的实例对象都可以访问constructor属性,constructor属性是创建实例对象的函数的引用。
constructor属性的存在仅仅是为了说明该对象是从哪儿创建出来的。
实现继承
我们真正想要实现的是一个完整的原型链,在原型链上,Ninja继承自Person,Person继承自Mammal,Mammal继承自Animal,以此类推,一直到Object。创建这样的原型链最佳技术方案是一个对象的原型直接是另一个对象的实例:
SubClass.prototype = new SuperClass();
Ninja.prototype = new Person();
因为SubClass实例的原型是SuperClass的实例,SuperClass实例具有SuperClass的全部属性,SuperClass实例也同时具有一个指向超类的原型。
使用原型实现继承
function Person(){
}
Person.prototype.dance = function(){
};
function Ninja(){
}
Ninja.prototype = new Person();
// ⇽--- 通过将Ninja的原型赋值为Person的实例 ,实现Ninja继承Person
const ninja = new Ninja();
assert(ninja instanceof Ninja,
"ninja receives functionality from the Ninja prototype");
assert(ninja instanceof Person, "... and the Person prototype");
assert(ninja instanceof Object, "... and the Object prototype");
assert(typeof ninja.dance === "function", "... and can dance!")
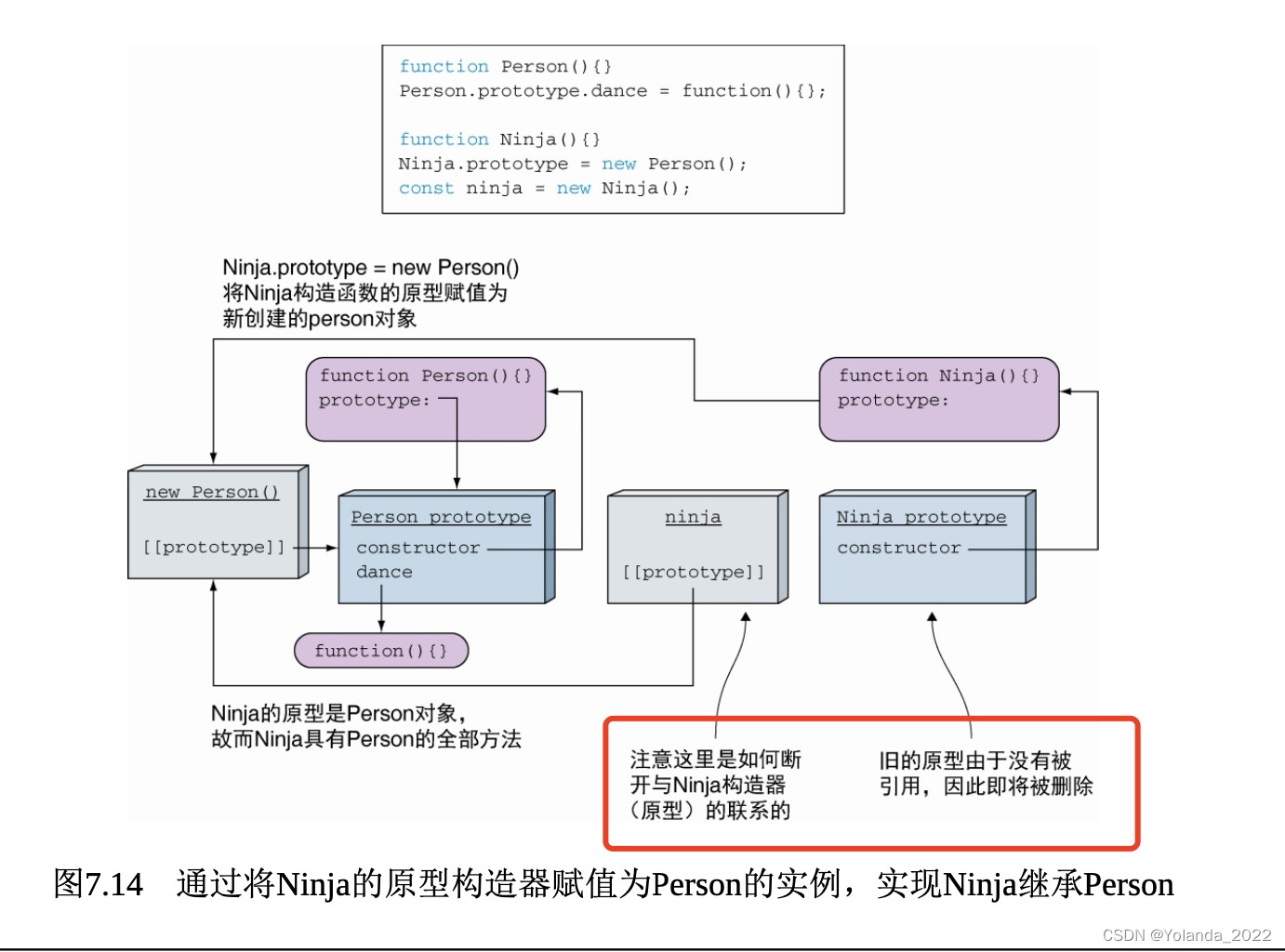
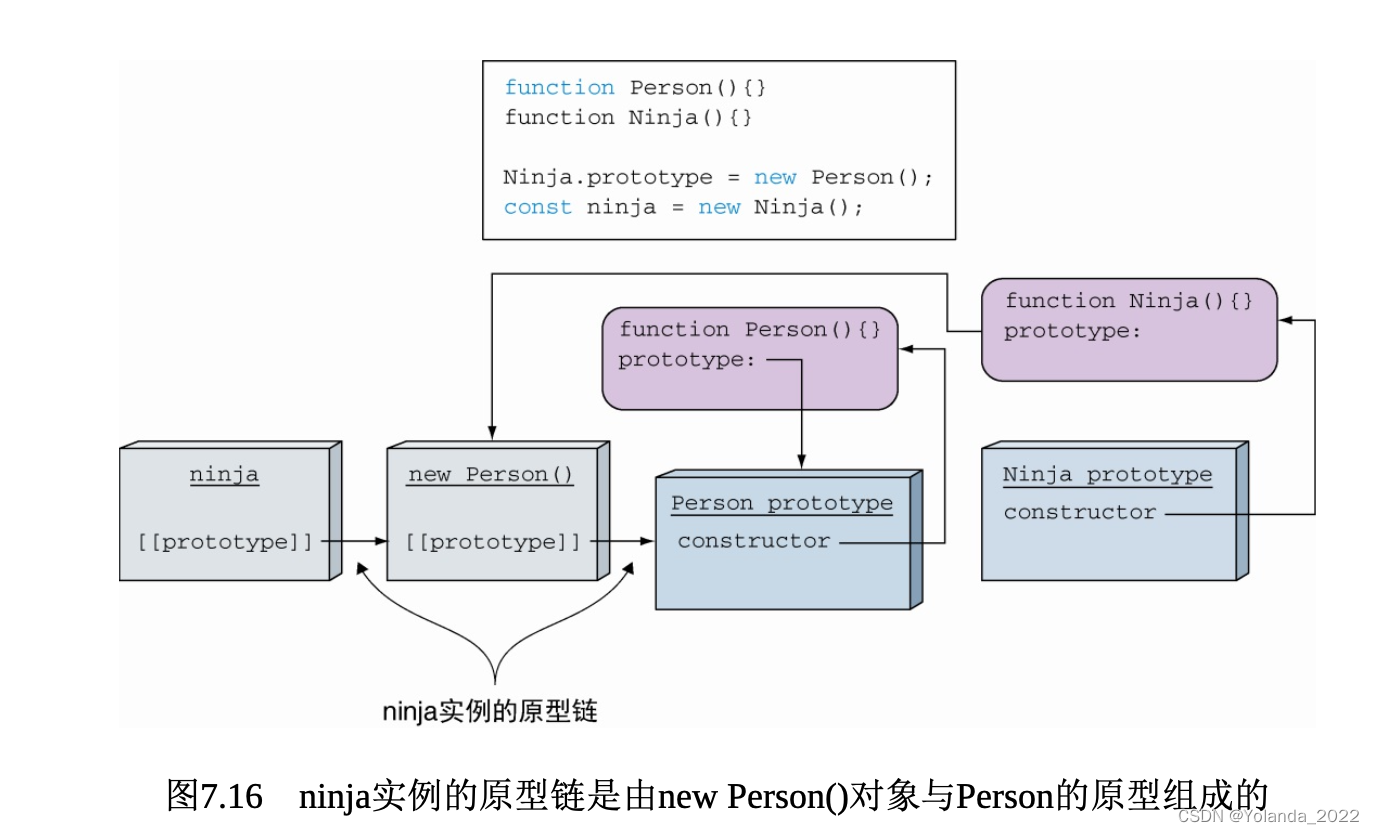
执行 ninja instanceof Ninja 表达式时,JavaScript引擎检查 Ninja 函数的原型——new Person()对象,是否存在于ninja实例的原型链上。new Person()对象是ninja实例的原型,因此,表达式执行结果为true。
在检查ninja instanceof Person时,JavaScript引擎查找Person函数的原型,检查它是否存在于在ninja实例的原型链上。由于Person的原型的确存在于ninja实例的原型链上,Person是new Person()对象的原型,所以Person也是ninja实例的原型。

instanceof操作符检查右边的函数原型是否存在于操作符左边的对象的原型链上。小心函数的原型可以随时发生改变。
实例不可访问静态方法,而类可以访问静态方法。
在ES6之前的版本中实现继承是一件痛苦的事。
function Person(){
}
Person.prototype.dance = function(){
};
function Ninja(){
}
Ninja.prototype = new Person();
Object.defineProperty(Ninja.prototype, "constructor", {
enumerable: false,
value: Ninja,
writable: true
});
对所有实例均可访问的方法必须直接添加在构造函数原型上,如Person构造函数上的dance方法。为了实现继承,我们必须将实例对象衍生的原型设置成“基类”。
在本例中,我们将一个新的Person实例对象赋值给Ninja.prototype。糟糕的是,这会弄乱constructor属性,所以需要通过Object.defineProperty方法进行手动设置。
控制对象的访问
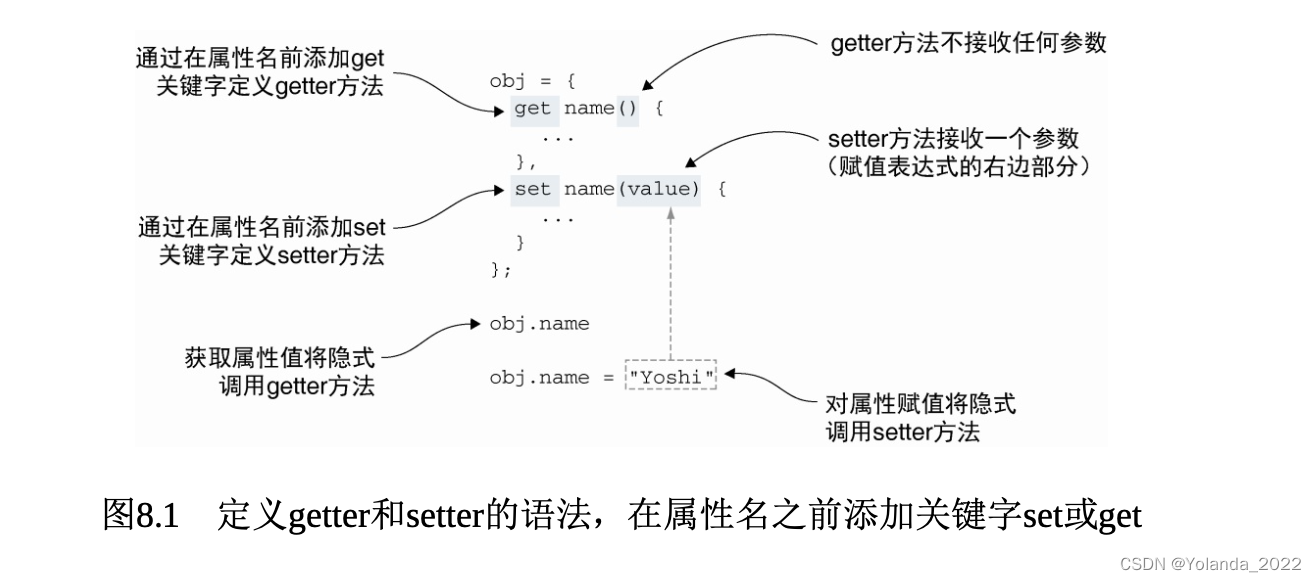
使用代理检测性能(new proxy代理函数)
function isPrime(number){
if(number < 2) {
return false; }
for(let i = 2; i < number; i++) {
if(number % i === 0) {
return false; }
}
// ⇽--- 定义isPrime函数的简单实现
return true;
}
isPrime = new Proxy(isPrime, {
// ⇽--- 使用代理包装isPrime方法
apply: (target, thisArg, args) => {
// ⇽--- 定义apply方法,当代理对象作为 函数被调用时将会触发该apply方法的执行
console.time("isPrime");
// ⇽--- 启动一个计时器,记录isPrime函数执行的起 始时间
const result = target.apply(thisArg, args);
// ⇽--- 调用目标函数
console.timeEnd("isPrime");
// ⇽--- 停止计时器的执行并输出结果
return result; }
});
isPrime(1299827);
// ⇽--- 同调用原始方法一样,调用isPrime方法
使用isPrime函数作为代理的目标对象。同时,添加apply方法,当调用isPrime函数时就会调用apply方法。
使用代理自动填充属性
function Folder() {
return new Proxy({
}, {
get: (target, property) => {
report("Reading " + property);
// ⇽--- 记录所有读取对象属性的日志
if(!(property in target)) {
target[property] = new Folder();
} ⇽--- 如果对象不具有该属性,则创建该属性
return target[property];
}
});
}
const rootFolder = new Folder();
try {
rootFolder.ninjasDir.firstNinjaDir.ninjaFile = "yoshi.txt";
// ⇽--- 每 当访问属性时,都会执行代理方法,若该属性不存在,则创建该属性
pass("An exception wasn’t raised");
// ⇽--- 不会抛出异常
}
catch(e){
fail("An exception has occurred");
}
使用代理实现负数组索引
function createNegativeArrayProxy(array) {
if (!Array.isArray(array)) {
throw new TypeError('Expected an array');
// ⇽--- 如果传入的参数不是数组,则抛出异常
}
return new Proxy(array, {
// ⇽--- 返回新的代理。该代理使用传入的数组作为 代理目标
get: (target, index) => {
// ⇽--- 当读取数组元素时调用get方法
index = +index;
// ⇽--- 使用一元+操作符将属性名变成的数值
return target[index < 0 ? target.length + index : index];
// ⇽--- 如果访问的是负向索引,则逆向访问数组。如果访问的是正向索引,则正常访问数组
},
set: (target, index, val) => {
// ⇽--- 当写入数组元素时,调用set方法
index = +index;
return target[index < 0 ? target.length + index : index] = val;
}
}
);
}
const ninjas = ["Yoshi", "Kuma", "Hattori"];
// ⇽--- 创建标准数组
const proxiedNinjas = createNegativeArrayProxy(ninjas);
// ⇽--- 将数组传 入create-Nigati-veArrayProx-y,创建代理数组
assert(ninjas[0] === "Yoshi" && ninjas[1] === "Kuma"
&& ninjas[2] === "Hattori"
,"Array items accessed through positive indexes");
assert(typeof ninjas[-1] === "undefined"
// ⇽--- 验证无法通过标准数组直接使 用负向索引访问数组元素。
&& typeof ninjas[-2] === "undefined"
&& typeof ninjas[-3] === "undefined",
"Items cannot be accessed through negative indexes on an array");
assert(proxiedNinjas[-1] === "Hattori"
// ⇽--- 但是可以通过代理使用负向索引 访问数组元素,因为代理get方法进行了必要的处理
&& proxiedNinjas[-2] === "Kuma"
&& proxiedNinjas[-3] === "Yoshi",
"But they can be accessed through negative indexes");
代理效率不高,所以谨慎使用。
处理集合
pop和push方法只影响数组最后一个元素:pop移除最后一个元素,push在数组末尾增加元素。shift和unshift方法修改第一个元素,之后的每一个元素的索引都需要调整。因此,pop和push方法比shift和unshift要快很多,非特殊情况不建议使用shift和unshift方法。
reduce
const numbers = [1, 2, 3, 4];
const sum = numbers.reduce((aggregated, number) =>
aggregated + number, 0);
// ⇽--- 使用reduce函数从数组中取得累计值
assert(sum === 10, "The sum of first four numbers is 10");
reduce方法接收初始值,对数组每个元素执行回调函数,回调函数接收上一次回调结果以及当前的数组元素作为参数。最后一次回调函数的结果作为reduce的结果。
事件循环
所有微任务会在下一次渲染之前执行完成,因为它们的目标是在渲染前更新应用程序状态。
我们想象以下内容,主线程JavaScript代码执行时间需要15ms。第一个单击事件处理器需要运行8ms。第二个单击事件处理器需要运行5ms。让我们继续发挥想象,假设有一个手快的用户在代码执行后5ms时单击第一个按钮,随后在12ms时单击第二个按钮。
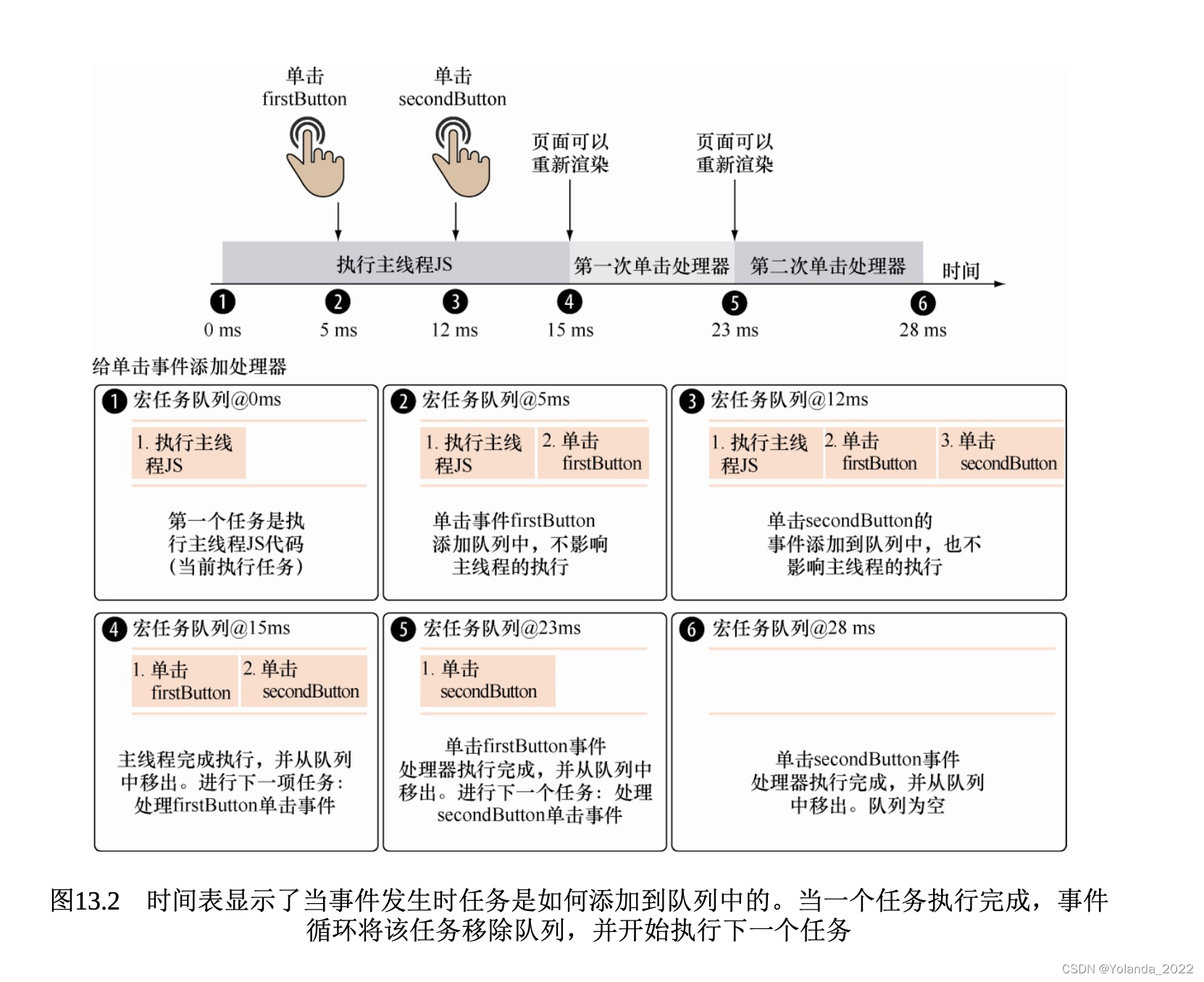
由于JavaScript基于单线程执行模型,单击firstButton并不会立即执行对应的处理器。(记住,一个任务一旦开始执行,就不会被另一个任务中断)firstButton的事件处理器则进入任务队列,等待执行。当单击secondButton时发生类似的情况:对应的事件处理器进入队列,等待执行。注意,事件监测和添加任务是独立于事件循环的,尽管主线程仍在执行,仍然可以向队列添加任务。
同时含有微任务和宏任务的实例
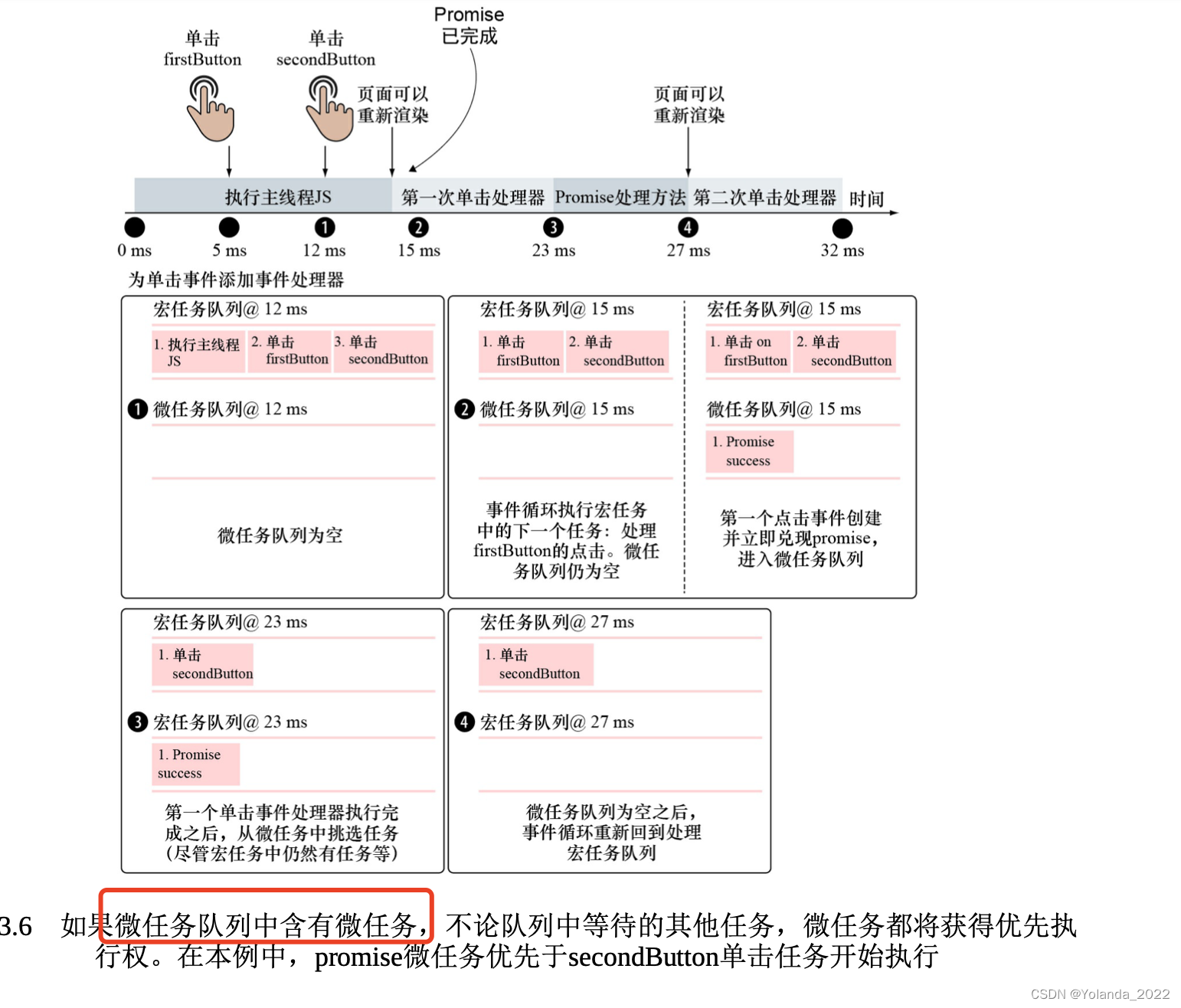
事件循环任务代表浏览器执行的行为。任务分为以下两类。
宏任务是分散的、独立的浏览器操作,如创建主文档对象、处理各种事件、更改URL等。
微任务是应该尽快执行的任务。包括promise回调和 DOM 突变。
由于单线程的执行模型,一次只能处理一个任务,一个任务开始执行后不能被另一个任务中断。事件循环通常至少有两个事件队列: 宏任务队列和微任务队列。