分类模型数据加载
1 重点函数介绍
1.1 ImageFolde()介绍
用来针对以下情况的数据读取,返回的是一个二维矩阵,0为数据地址,1为label值,也就是子文件夹的字典映射值(从0开始)
形如以下情况的:

ImageFolder(root, transform=None, target_transform=None, loader=default_loader)
root: 就是需要读取的文件夹名称,这里为medical-mnist
transform: 对loader读取图片返回值进行的数据增强,一般都是对PIL Image进行数据操作
target_transform: 对label的数据增强操作
loader: 对给定路径下的图片的读取操作,默认读取为RGB格式的PIL Image对象
返回值:
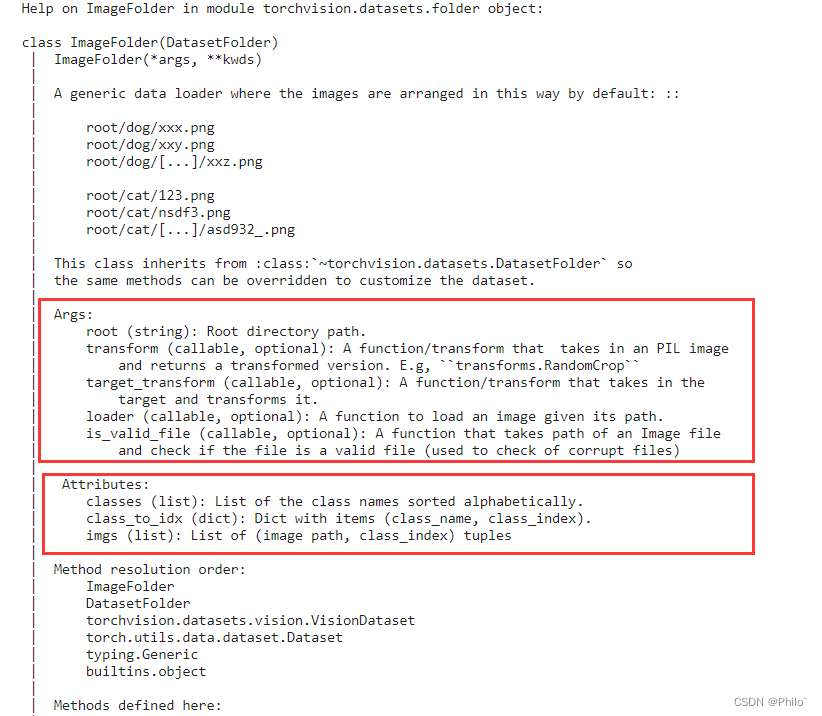
我们可以把它理解为一个二维数组,第一维是图片地址,第二维是图片所在的文件夹的映射值
示例代码:
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import DataLoader
from torchvision import datasets, transforms, models
from torchvision.utils import make_grid
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
import os
import random
import cv2
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings("ignore")
train_transforms = transforms.Compose([
transforms.RandomRotation(10), # Rotation (-10,109)
transforms.RandomHorizontalFlip(), # HorizontalFlip by 0.5 ratio
transforms.Resize(227),
transforms.CenterCrop(227),
transforms.ToTensor(),
transforms.Normalize([0.485,0.456,0.406], # Three channesl by data-mean/std (mean, std)
[0.229,0.224,0.225])
])
dataset = datasets.ImageFolder(root="../input/medical-mnist", transform=train_transforms)
# self.classes:用一个 list 保存类别名称 self.class_to_idx:类别对应的索引,与不做任何转换返回的 target 对应
# self.imgs:保存(img-path, class) tuple的 list
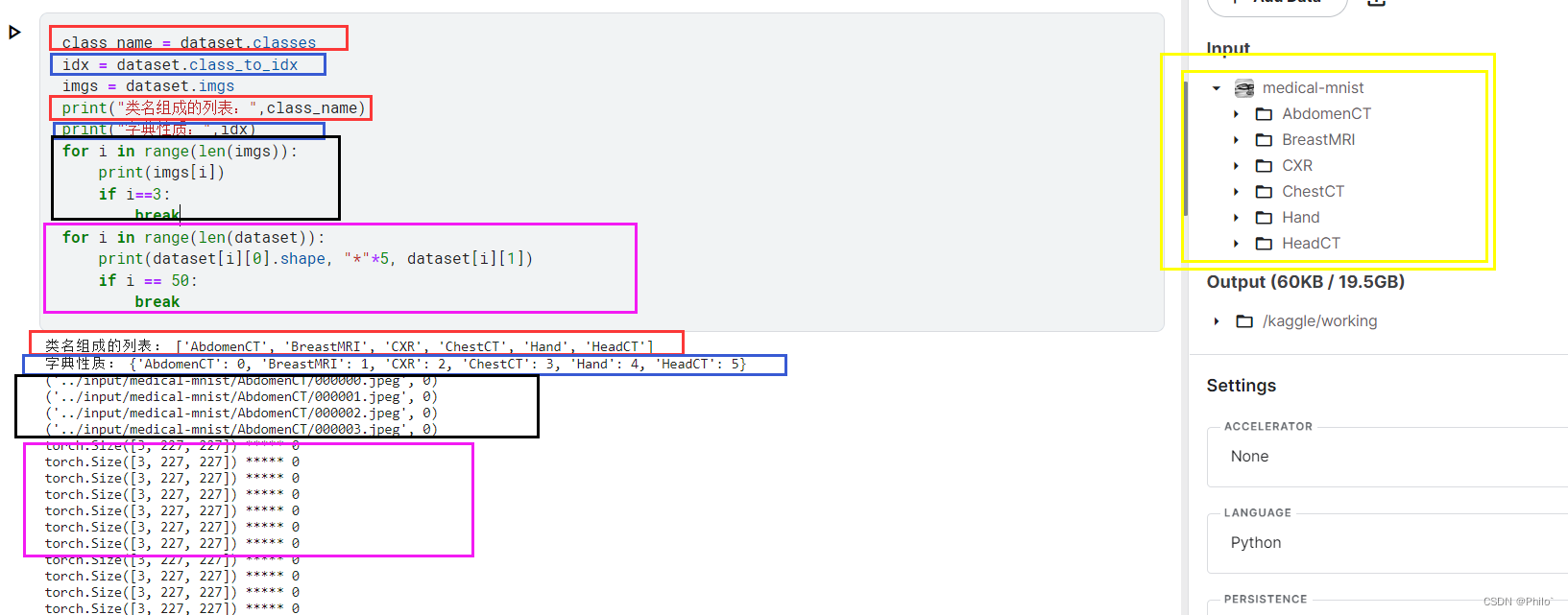
class_name = dataset.classes
idx = dataset.class_to_idx
imgs = dataset.imgs
print("类名组成的列表:",class_name)
print("字典性质:",idx)
for i in range(len(imgs)):
print(imgs[i])
if i==3:
break
for i in range(len(dataset)):
print(dataset[i][0].shape, "*"*5, dataset[i][1])
if i == 50:
break
结果为:
1.2 引入train_test_split()用法
用来对输入的列表参数进行分割,按照一定比例返回训练集和测试集的索引,用于下一步的测试集合成
sklearn.model_selection.train_test_split(*arrays, test_size=None, train_size=None, random_state=None, shuffle=True, stratify=None)
参数介绍:

示例结果:
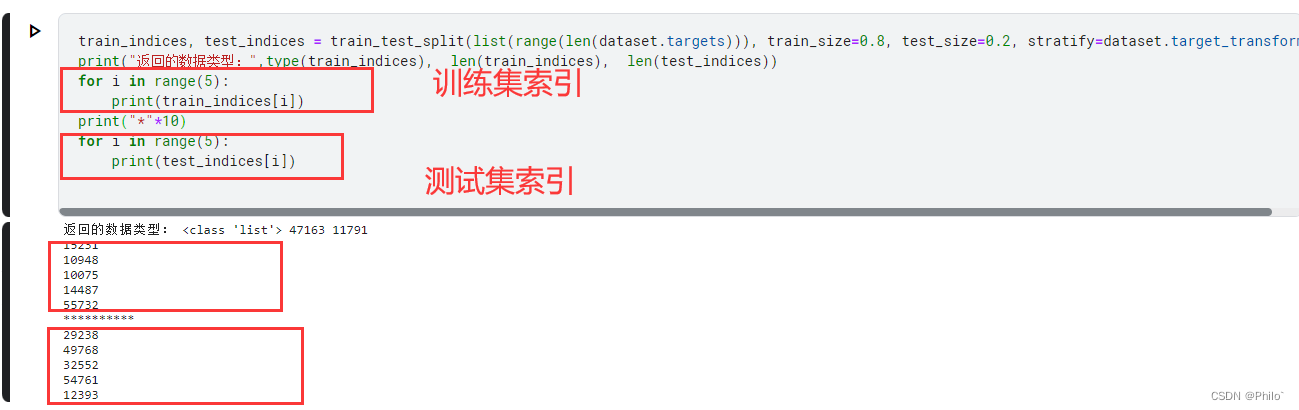
这里需要注意test_size和train_size的和必须小于等于1
第一个参数必须是一个列表,所以先取长度,再转范围,最后形成列表
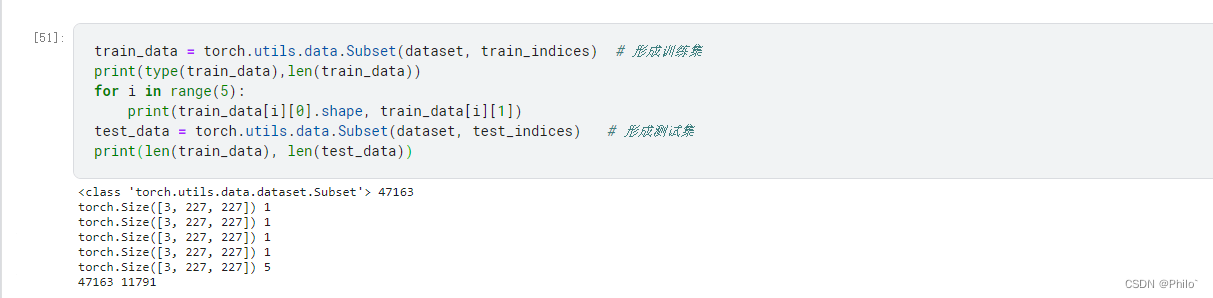
1.3 引入torch.utils.data.Subset()用法
传入全部数据集和需要形成测试集或者是训练集的索引,返回切好的数据集
data = torch.utils.data.Subset(dataset , indices)
示例:
1.4 引入DataLoader()
将上面得到的数据集,放入加载器中,设置batchsize大小,shuffle等属性,之后就可以传入网络模型中训练了

这个咱就不介绍了,都会用,重点是1.4以前的部分
2 训练集和测试集在一起的情况
形如:

使用套路:
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import DataLoader
from torchvision import datasets, transforms, models
from torchvision.utils import make_grid
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
# 前期准备工作 以下仅供参考
train_transforms = transforms.Compose([
transforms.RandomRotation(10), # Rotation (-10,109)
transforms.RandomHorizontalFlip(), # HorizontalFlip by 0.5 ratio
transforms.Resize(227),
transforms.CenterCrop(227),
transforms.ToTensor(),
transforms.Normalize([0.485,0.456,0.406], # Three channesl by data-mean/std (mean, std)
[0.229,0.224,0.225])
])
# 第一步,传入类别文件夹的父文件夹,以及需要做的数据变换
dataset = datasets.ImageFolder(root="../input/medical-mnist", transform=train_transforms)
# 第二步 设置训练集和测试集的占比
train_indices, test_indices = train_test_split(list(range(len(dataset.targets))), train_size=0.8, test_size=0.2, stratify=dataset.target_transform)
# 第三步 传入全部数据集 以及索引,得到数据处理后的最终结果
train_data = torch.utils.data.Subset(dataset, train_indices) # 形成训练集
test_data = torch.utils.data.Subset(dataset, test_indices) # 形成测试集
# 第四步 使用数据加载器进行数据加载,得到可以传入模型的数据集
train_loader = DataLoader(train_data, batch_size=12, shuffle=True)
test_loader = DataLoader(test_data, batch_size=12)
之后就是愉快的模型训练和测试了
介绍一下例子中出现的完整代码模型,是使用AlexNet对医学图像进行分类的模型,链接如下:AlexNet模型介绍及源码使用
3 训练集和测试集不在一起的情况
形如:
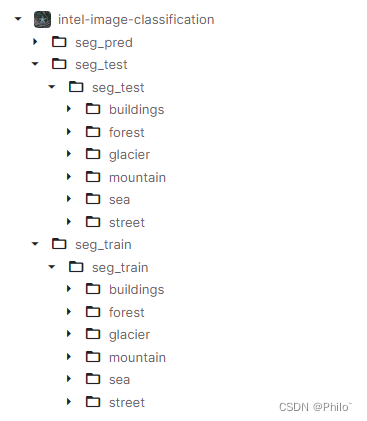
忽略其中的多级重复文件夹名称哈,这是Kaggle的数据集,修改不了,我们自己在构造文件夹时可以避免这样的问题。
使用套路:
import os
from torch.utils.data import DataLoader
from torchvision import datasets, transforms, models
from torchvision.utils import make_grid
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
# 前期准备工作 一下仅供参考
train_transforms = transforms.Compose([
transforms.RandomRotation(10),
transforms.RandomHorizontalFlip(),
transforms.Resize(227),
transforms.CenterCrop(227),
transforms.ToTensor(),
transforms.Normalize([0.485,0.456,0.406],
[0.229,0.224,0.225])
])
test_transforms = transforms.Compose([
transforms.Resize([227,227]),
transforms.ToTensor(),
transforms.Normalize([0.485,0.456,0.406],
[0.229,0.224,0.225])
])
# 第一步 分别传入训练集和测试集
train_dataset = datasets.ImageFolder(root="../input/intel-image-classification/seg_train/seg_train", transform=train_transforms)
test_dataset = datasets.ImageFolder(root="../input/intel-image-classification/seg_test/seg_test" , transform = test_transforms)
# 第二步 不需要索引了, 直接使用数据加载器进行加载
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=64, shuffle=True)
print(len(train_loader), len(test_loader))
之后就是愉快的模型训练和测试了
介绍一下这个例子的出处,GoogleNet重点介绍及源码分享