#1-2 基本概念
1.Hadoop 在某种程度上将多台计算机组织成了一台计算机(做同一件事),那么 HDFS 就相当于这台计算机的硬盘,而 MapReduce 就是这台计算机的 CPU 控制器。
2. Hadoop 支持在单个设备上运行,主要有两种模式:单机模式和伪集群模式.
3.Hadoop 主要包含 HDFS 和 MapReduce 两大组件,HDFS 负责分布储存数据,MapReduce 负责对数据进行映射、规约处理(即将统计结果合并到一个更庞大的数据结果中去),并汇总处理结果。
4.数据存储的稳定性往往通过"多存几份"的方式实现。
5.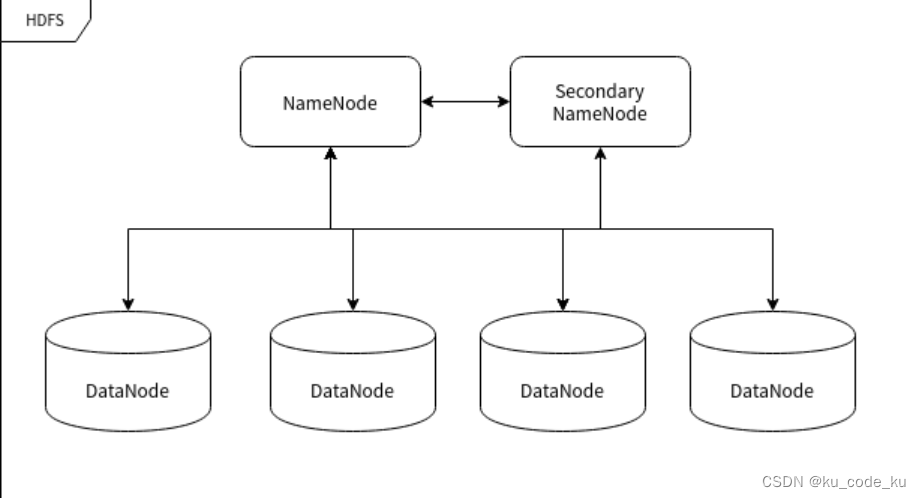
6. 大量数据的处理是一个典型的"道理简单,实施复杂"的事情。也就是说用它做的事情的逻辑不会很复杂,但是就是太多。
7.你可以把 MapReduce 想象成人口普查,人口普查局会把若干个调查员派到每个城市。每个城市的每个人口普查人员都将统计该市的部分人口数量,然后将结果汇总返回首都。在首都,每个城市的统计结果将被规约到单个计数(各个城市的人口),然后就可以确定国家的总人口。
8.Hadoop 三种模式:单机模式、伪集群模式和集群模式。
#1-3 HDFS基本使用
# 显示根目录 / 下的文件和子目录,绝对路径 hdfs dfs fs -ls / # 新建文件夹,绝对路径 hdfs dfs -mkdir /hello # 上传文件 hdfs dfs -put hello.txt /hello/ # 下载文件 hdfs dfs -get /hello/hello.txt # 输出文件内容 hdfs dfs -cat /hello/hello.txt
#1.4 hadoop集群
1.配置策略:
HDFS 命名节点对数据节点的远程控制是通过 SSH 来实现的,因此关键的配置项应该在命名节点被配置,非关键的节点配置要在各个数据节点配置。
2.配置文件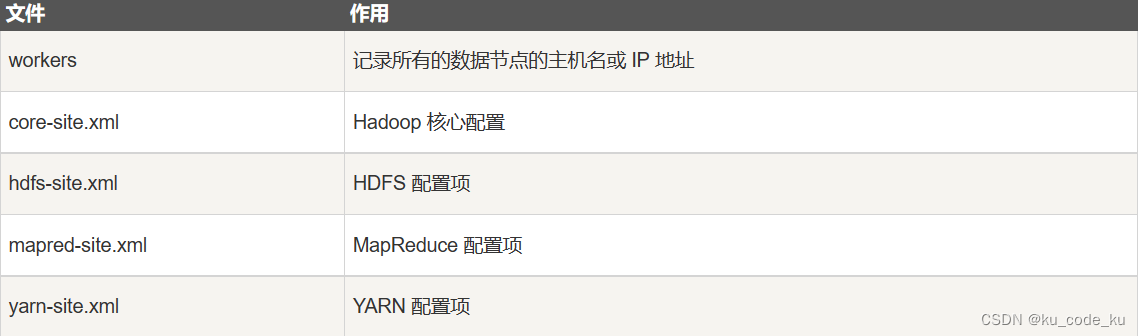
3.
#1-5 MAPREDUCE编程(python)
Hadoop的MapReduce和HDFS均采用Java进行实现,默认提供Java编程接口,如果要用其他语言来实现MR编程就需要Hadoop提供的一个框架Streaming,Streaming的原理是用Java实现一个包装用户程序的MapReduce程序,该程序负责调用hadoop提供的Java编程接口。
1.操作HDFS的包hdfs
Python API 操作Hadoop hdfs详解 - 知乎 (zhihu.com)![]() https://zhuanlan.zhihu.com/p/159737801
https://zhuanlan.zhihu.com/p/159737801
2.开发者可以通过实现 Map 和 Reduce 相关的方法来进行数据处理。
使用python语言进行MapReduce程序开发主要分为两个步骤,一是编写程序,二是用Hadoop Streaming命令提交任务
利用Linux所提供的管道符“|”将两个命令隔开,管道符左边命令的输出就会作为管道符右边命令的输入。
python实现hadoop经典程序wordcount
基础版:运行前可以本地测试的。
"""
created on:time-4
@function : use hadoop mr to realise word count
@author:ZHU SIR
"""
#!/usr/bin/env python3
import sys
#print(value, ...,
# sep=' ',
# end='\n',
# file=sys.stdout,
# flush=False)
for line in sys.stdin:
ss=line.strip().split(" ")
for s in ss:
if s.strip()!="":
print('{}\t{}'.format(word, 1))
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import sys
# word_list=["foo 1",
# "foo 1",
# "nima 1",
# "nima 1",
# "wocao 1",
# "gouba 1"]
current_word = None
current_count = 0
word = None
for line in sys.stdin:
# 移除line收尾的空白字符
line = line.strip()
# 解析我们从mapper.py得到的输入
word, count = line.split('\t', 1)
# 将字符串count转换为int
try:
count = int(count)
except ValueError:
# 不是数字,不做处理,跳过
continue
# hadoop在将kv对传递给reduce之前会进行按照key进行排序,在这里也就是word
if current_word == word:
current_count += count
else:
if current_word is not None:
# 将结果写入STDOUT
print('{}\t{}'.format(current_word, current_count))
current_count = count
current_word = word
# 最后一个单词不要忘记输出
if current_word == word:
print('{}\t{}'.format(current_word, current_count))注(本地测试时注意手动对map的结果进行排序)
高级版:智能在hadoop环境中使用。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import sys
def read_input(std_input):
for line in std_input:
# 将line分割成单词
yield line.split()
def main(separator='\t'):
# 从标准输入STDIN输入
data = read_input(sys.stdin)
for words in data:
# 将结果写到标准输出,此处的输出会作为reduce的输入
for word in words:
print('{}{}{}'.format(word, separator, 1))
if __name__ == "__main__":
main()#!/usr/bin/env python
# -*- coding: utf-8 -*-
from itertools import groupby
from operator import itemgetter
import sys
def read_mapper_output(std_input, separator='\t'):
for line in std_input:
yield line.rstrip().split(separator, 1)
def main(separator='\t'):
# 从STDIN输入
data = read_mapper_output(sys.stdin, separator=separator)
# groupby通过word对多个word-count对进行分组,并创建一个返回连续键和它们的组的迭代器:
# - current_word - 包含单词的字符串(键)
# - group - 是一个迭代器,能产生所有的["current_word", "count"]项
# itemgetter: 用于获取对象的哪些维的数据,itemgetter(0)表示获取第0维
for current_word, group in groupby(data, itemgetter(0)):
try:
total_count = sum(int(count) for current_word, count in group)
print('{}{}{}'.format(current_word, separator, total_count))
except ValueError:
pass
if __name__ == '__main__':
main()#本地python来直接实现开发,调试和运行
用Python玩转Hadoop - 简书 (jianshu.com)![]() https://www.jianshu.com/p/70bd81b2956f
https://www.jianshu.com/p/70bd81b2956f
在使用python进行MR编程的时候会有这个东西:yield有点高级,可以看下面的东西:
python中yield的用法详解python yield![]() https://blog.csdn.net/mieleizhi0522/article/details/82142856这里有两本不错的参考电子书分别是歪果仁hadoop with python(english)和清华的python+spark+hdoop机器学习与大数据实战。
https://blog.csdn.net/mieleizhi0522/article/details/82142856这里有两本不错的参考电子书分别是歪果仁hadoop with python(english)和清华的python+spark+hdoop机器学习与大数据实战。


#1-6Hadoop与Docker
在docker上部署hadoop集群是一个不错的想法,docker这玩意确实好。大概知道docker是干什么的就看下面这篇文章:
Docker是干什么用的? - 简书 (jianshu.com)![]() https://www.jianshu.com/p/dac95c4d9917
https://www.jianshu.com/p/dac95c4d9917