CenterFusion++:基于centerfusion改进的下一代毫米波雷达与视觉融合方案
A frustum proposal-based 3D object detection network for multi-stage fusion in autonomous driving
- 源码:https://github.com/brandesjj/centerfusionpp
- 文章:file:///D:/googleDownload/K%C3%BCbel_Brandes_2022.pdf
为了能够保证在未知环境中安全导航,必须在不同的天气和明亮条件下准确、可靠地检测自车周围三维环境中的物体,包括它们的速度。 这项工作涉及在自动驾驶中使用深度机器学习将两种互补的传感器模式雷达和摄像头进行传感器融合。 目标是结合两种传感器模式的优点并弥补它们的缺点。 常见的传感器融合算法通常使用经过充分研究的算法,例如卡尔曼滤波器。 然而,随着机器学习算法的日益普及,人们对基于深度学习的不同传感器模式融合的兴趣加深。 经过广泛的文献研究,这项工作激发、实现和评估了对相机雷达传感器融合中最先进的深度学习网络的两项主要修改。提出的改进包括一个子网络,它从点云的选定部分学习,并将早期融合引入网络。所有提出的架构的训练运行都是在流行的 nuScenes 数据集上进行的。
改进方向
上述提到的两点修改(基于centerfusion):
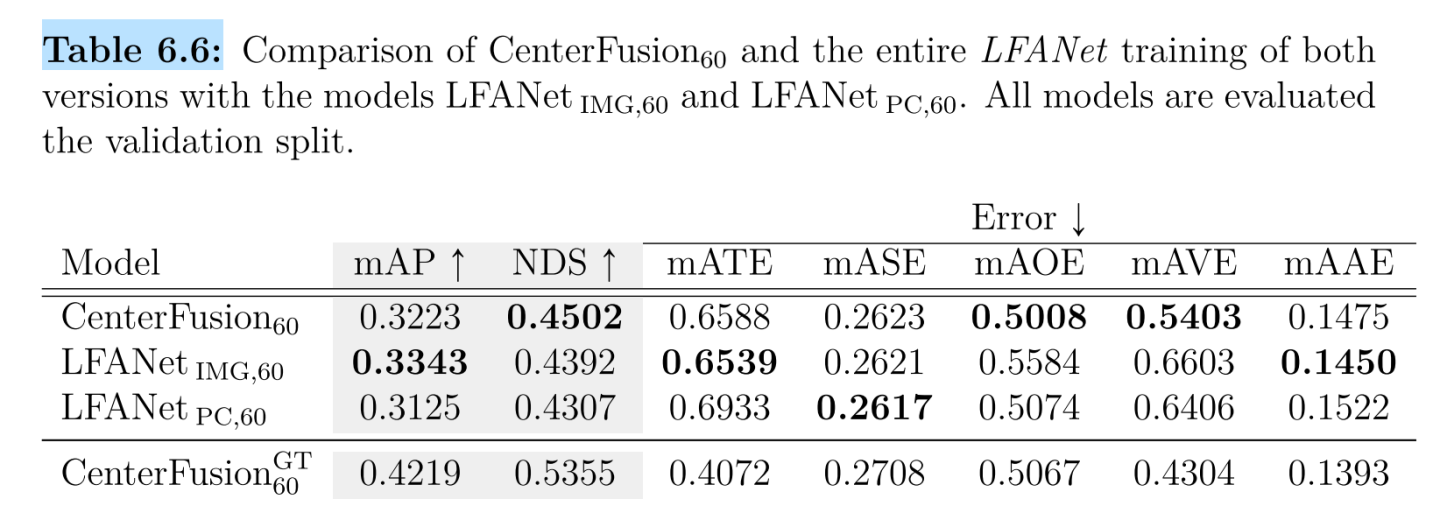
- **早期融合(EF):如上图的3D TO 2D的绿色框,**作为雷达点云在图像平面上的投影。投射的雷达点图像特征(默认为:深度、x和z的速度分量以及RCS值)然后被concate到RGB图像通道,作为网络结构中基于图像的骨干的新输入。EF引入了对相机传感器故障和挑战性环境条件(如雨/夜/雾)的鲁棒性。
- **可学习的目标-雷达点云关联网络 (LFANet):这也是不同于centerfusion,*架构的第二个主要变化是关于相机和雷达点云之间的基于frustum-proposal关联方法。我们提出了一个称为LFANet的网络,该网络将frustum的点云经过处理作为固定大小的radar特征图作为输入,输出一个代表frustum中所有雷达点的人工雷达点r,而不是选择从primary head预测出来的目标关联(用r*表示frustum内部的所有点云)。LFANet经过训练,可以输出与雷达点相关的边界盒中心的深度,以及相应的径向速度。然后,LFANet的输出被用作Nabati等人所介绍的热图中的新通道。
一些细节
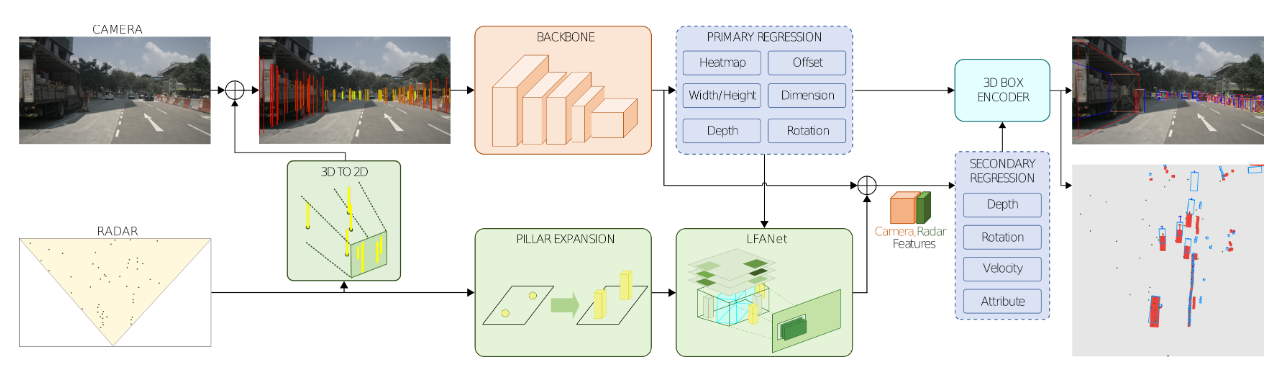
- 雷达点云叠帧后的偏移
当n_sweeps=13时,点云由于它车运动,偏移较大,centerfusion选取sweeps=3,此时点云偏移在自车GT范围内,误差可接受
\2. Primarry Head的雷达特征图


其中M1=d_max,M2,M3为1,只对深度channel标准化
\3. 与CenterFusion的不同

\4. Learn Frustum Association Net(LFANet)
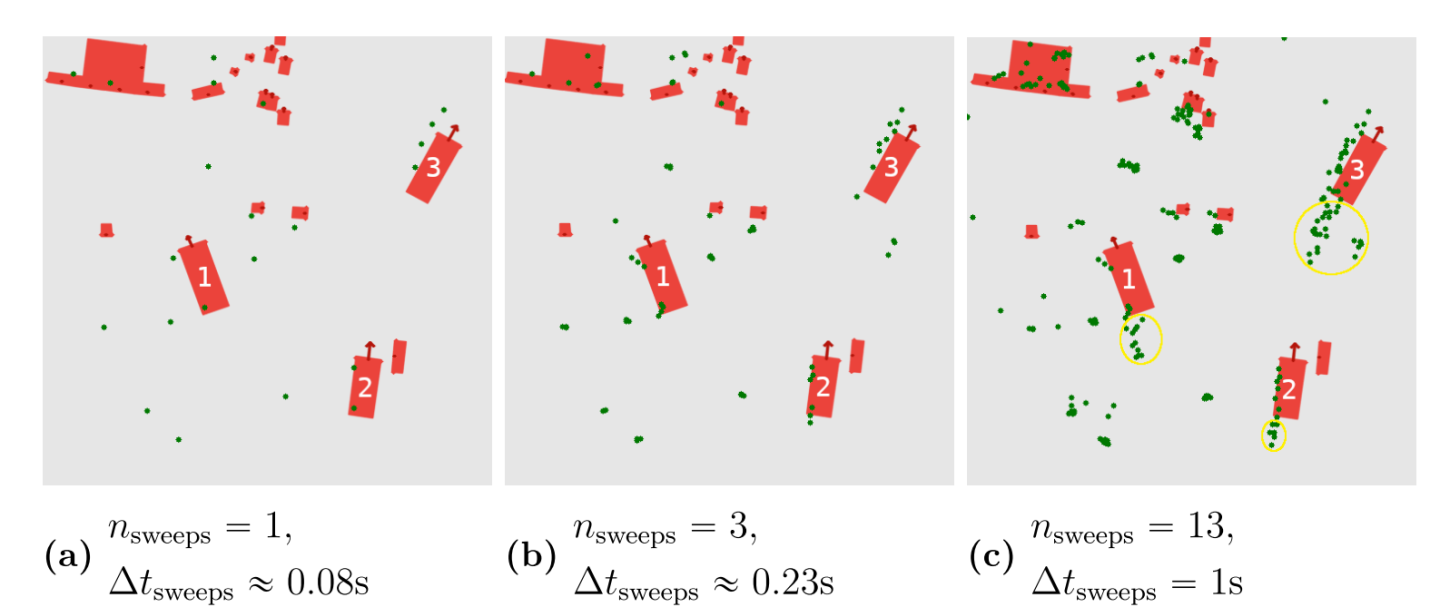
作者统计CenterFusion的深度特征图关联方式(只选择frustum的depth_min的雷达点云作为2d-bbox的深度)下计算的object depth与GT object depth的相对、标准化误差值。其中:横坐标是error的单位,纵坐标是error对应的frustum数量,统计的frustum是指至少包含至少一个radar点云的object。
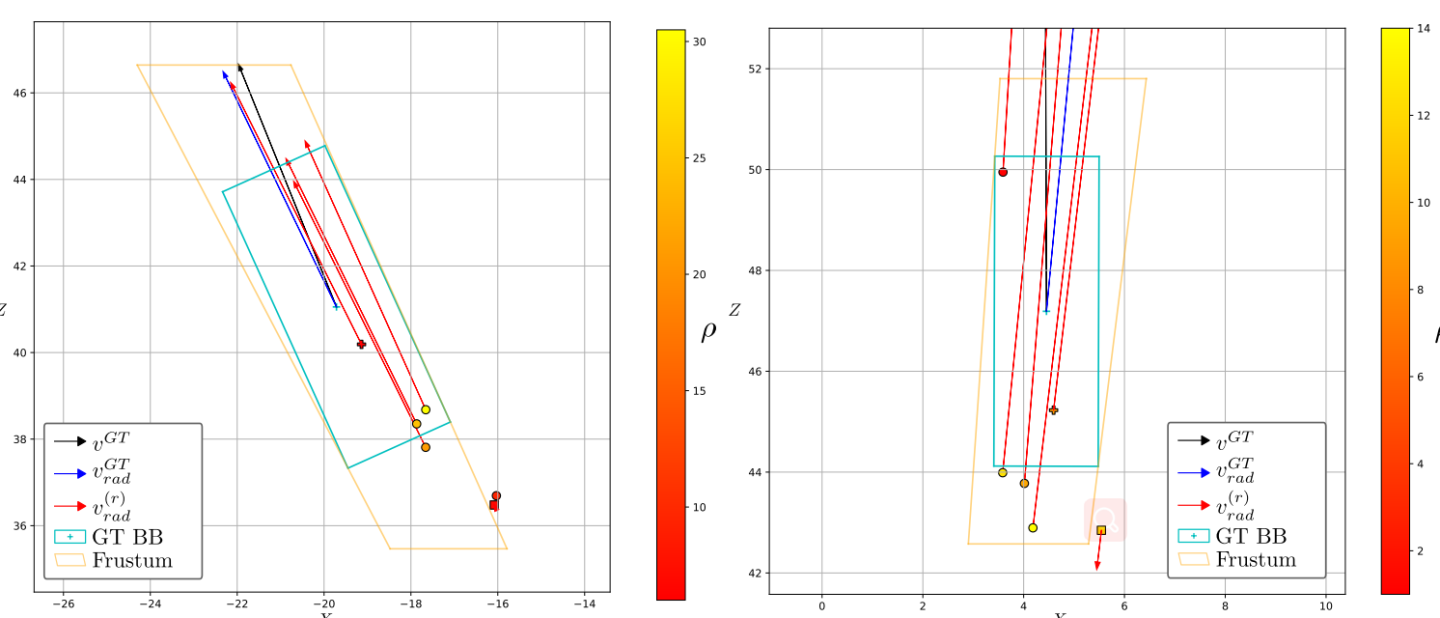
上图中:最下方的方块为按照最近关联点原则匹配给object的深度,可以看到此时造成了错误匹配,其关联方式的鲁棒性是较差的,作者基于此,提出一种LFANet关联所有点云的方式。
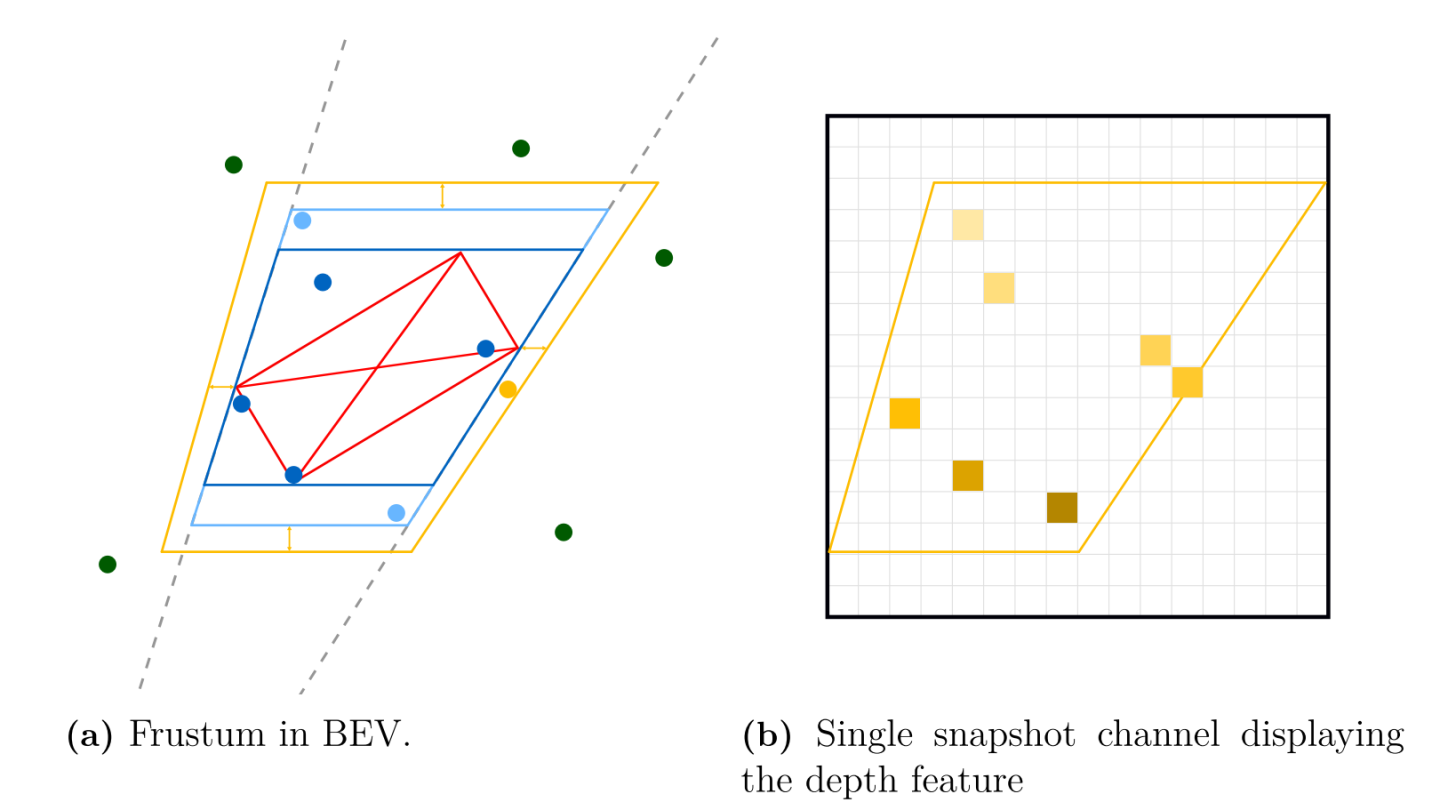
右侧(b)展示经过作者量化后的kxk大小的frustum feature map,包含了所有需要考虑的雷达点云,大小为kxkxc,其中c=5,且radar point须从距离空间,转换到BEV像素空间。
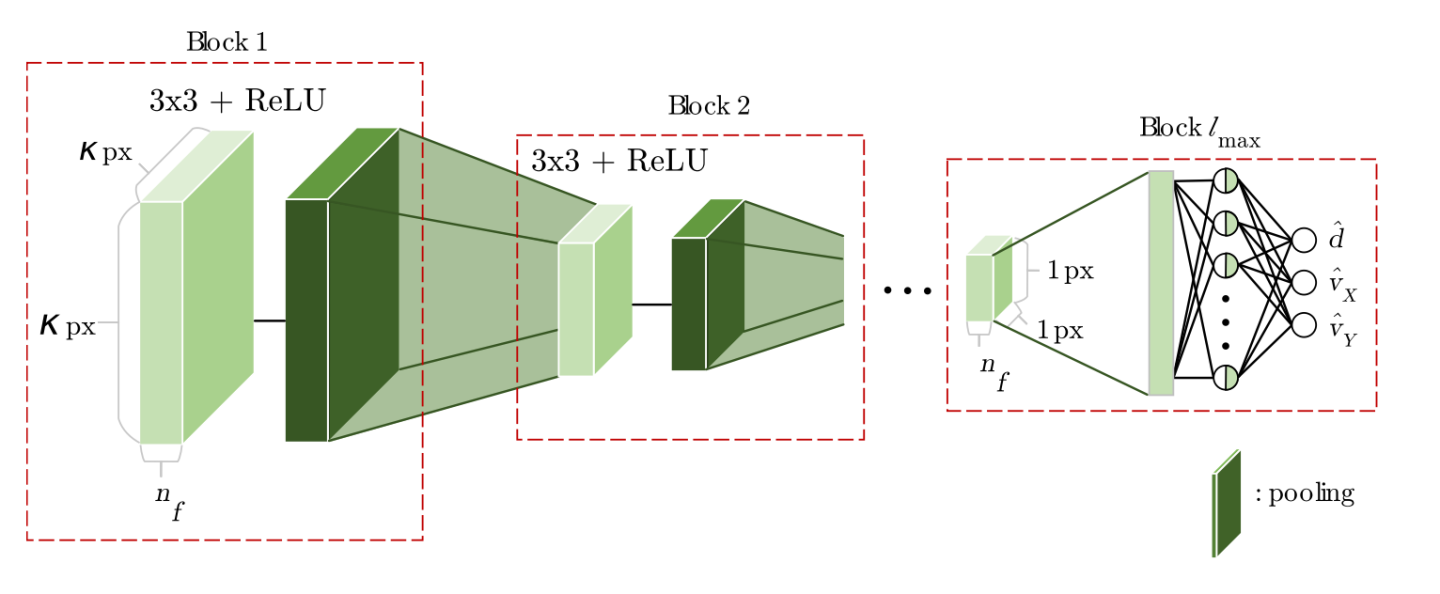
LFANet结构
如上,输入为处理后的frustum feature map,得到最后的[d, vx, vy]作为r*,也就是artificial point作为可信度更高的深度值,改进了centerfusion的鲁棒性较差的劣势。
结果
- 在Early Fusion的改进

\2. 在LFANet的改进