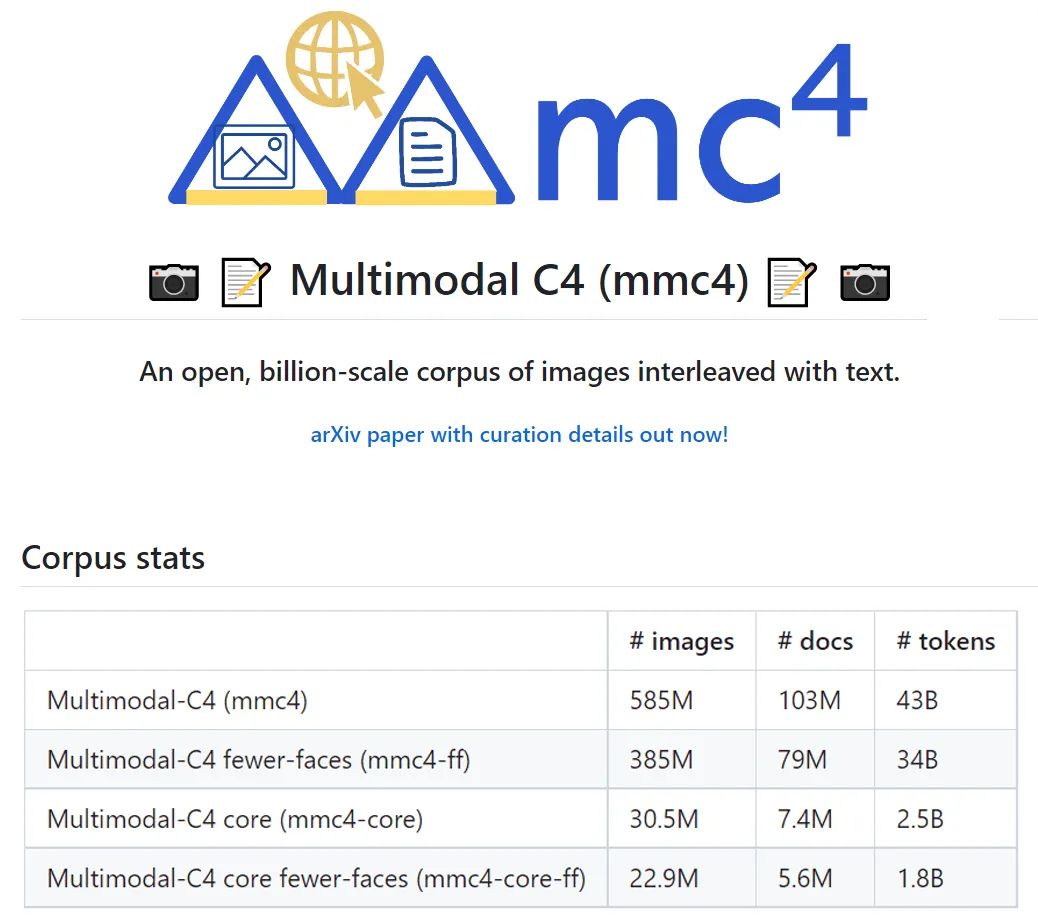
想要训练GPT-4的小伙伴们看过来!由AI2、华大、哥大等单位联合推出了由5.8亿图片、1亿文档、430亿token组成的超大文本图片交织数据集。旨在支持上下文视觉和语言模型的研究。这是训练开源大模型OpenFlamingo的训练数据集。
Multimodal C4数据集通过线性分配算法,使用CLIP特征将图片嵌入文本当中,并在常见主题如烹饪、旅游、科技等领域中提供有关的图像和文本内容。论文披露了该数据集的构建方法和数据质量检查,并说明了该数据集的使用和价值。
论文链接:https://arxiv.org/pdf/2304.06939.pdf
下载地址:https://github.com/allenai/mmc4