一、Sentinel-2 MSI多光谱遥感数据下载
(一)登录Copernicus Open Access Hub网页[2];
(二)选择研究区域并设定云覆盖百分比和卫星平台等参数(依据自己的研究目的而定);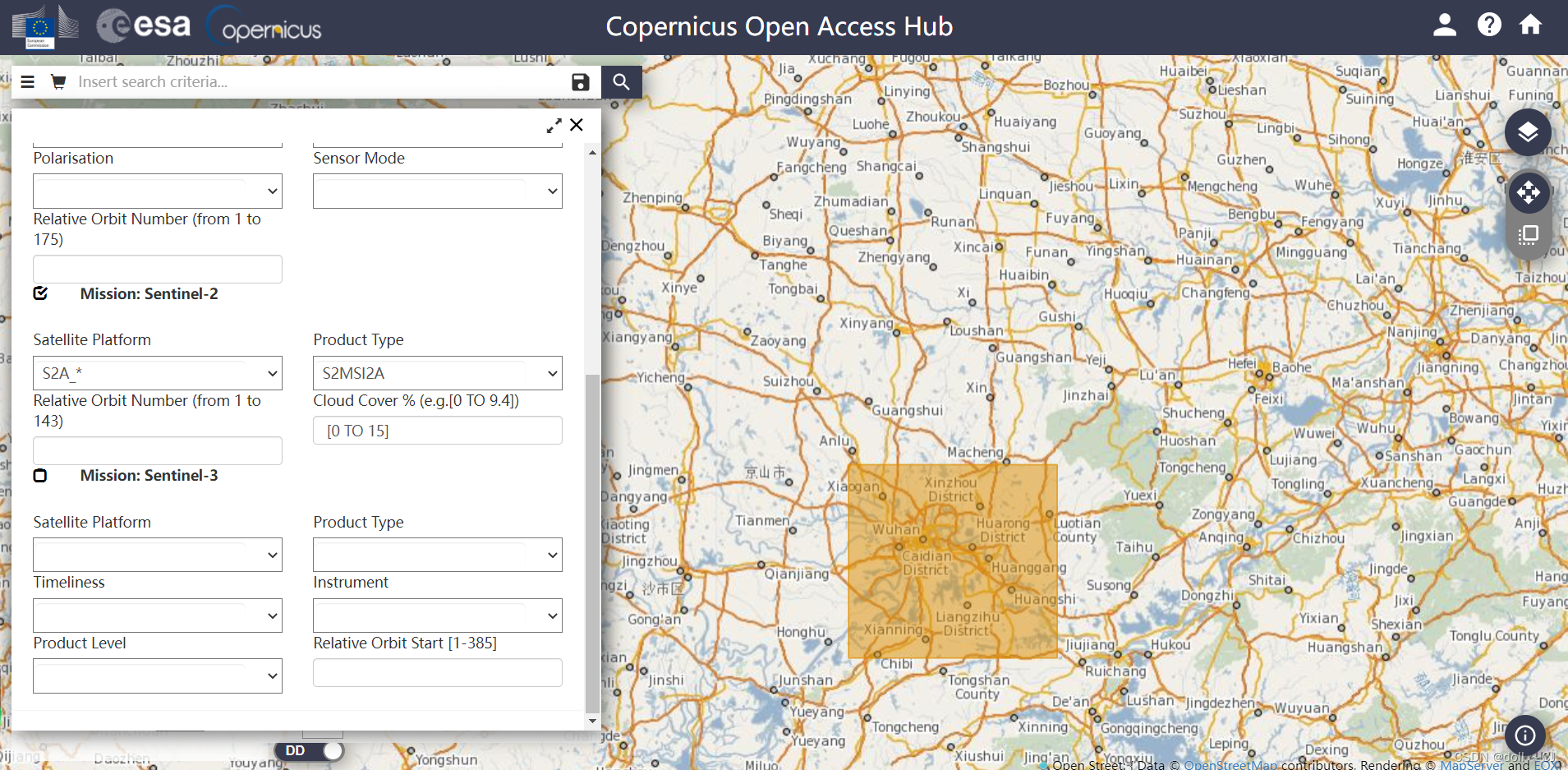

(三) 利用GDAL与Opencv库将遥感数据转换为普通RGB三通道影像
我们知道Sentinel-2 MSI数据是多光谱数据,其包含10米、20米和60米空间分辨率且16bit辐射分辨率数据[3]。对于深度学习而言,个人实验受限于计算机的算力和内存并且大多数深度学习数据集为8bit辐射分辨率,因此,我需要将10米分辨率的红绿蓝三波段转换为8bit数据(即DN∈[0,255])输出。
其中,若需要使得DNnew显得更为合理,可引入四舍五入法归纳正整数。
在实验中,仅按上述公式转换并不能保证色彩尽可能地与原图一致(色彩为暗色调)。为了使得图像对比度明显且尽可能与原图具有较为一致的色彩,所以采用1%线性拉伸对转换后的数据进行图像增强。
此处的1%线性拉伸,即将图像小于1%分位的像素值全部赋值为0,将图像大于99%分位的像素值全部赋值为255,其余的像素值线性拉伸(百分位概念及计算方法详见[5]):



图一 无拉伸原图 图二 1%线性拉伸结果 图三 训练数据对比(步骤四修正)
import os
import cv2
from osgeo import gdal
import numpy as np
# 利用GDAL库读入Sentinel-2 MSI 实验数据
# 解压后10米分辨率影像文件夹地址(批量处理的话,可以设置文件夹操作即可)
path = r"G:\产学研数据备份\S2A\S2A_MSIL2A_20230107T031121_N0509_R075_T49RGQ_20230107T064700.SAFE\GRANULE\L2A_T49RGQ_A039397_20230107T031415\IMG_DATA\R10m"
Rpath = os.path.join(path,"T49RGQ_20230107T031121_B04_10m.jp2")
Gpath = os.path.join(path,"T49RGQ_20230107T031121_B03_10m.jp2")
Bpath = os.path.join(path,"T49RGQ_20230107T031121_B02_10m.jp2")
PathList = [Bpath,Gpath,Rpath]
# 读取文件数据并深度复制保存
gdal.AllRegister()
B = gdal.Open(Bpath)
# 获取影像高宽
height = B.RasterYSize
width = B.RasterXSize
del B
# 正式处理RGB数据
BGR = []
for p in PathList:
data = gdal.Open(p)
# GetRasterBand()函数是从1开始计数
DNdata = data.GetRasterBand(1).ReadAsArray(0,0,width,height)
# 深度复制数据
copy = DNdata.copy()
# 此处直接采用了Numpy的broadcast特性
copy = 255*((copy-np.min(copy))/(np.max(copy)-np.min(copy)))
# 对数据进行1%拉伸增强
minborder = np.percentile(copy,1)
maxborder = np.percentile(copy,99)
copy = 255 * ((copy-minborder)/(maxborder-minborder))
copy[copy < 0] = 0
copy[copy > 255] = 255
# 转换COPY格式为uint8
copy = np.uint8(copy)
BGR.append(copy)
del data
BGRoutput = cv2.merge(BGR)
# 将文件写为png格式输出(该函数要求BGR输出)--图片位于同级文件
cv2.imwrite("data1.png",BGRoutput)
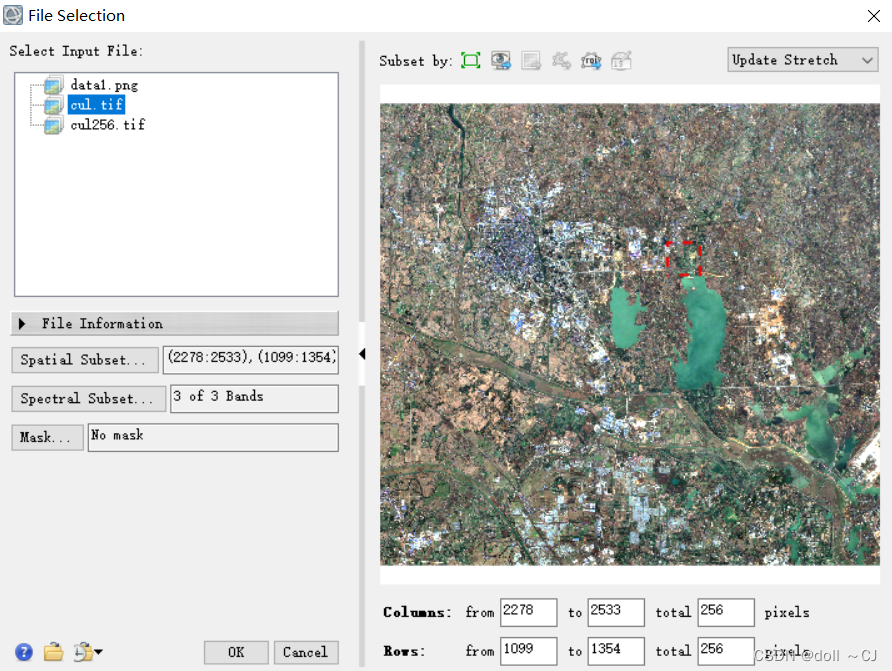
(四)针对研究区对数据进行裁剪
根据研究区与训练目标选择图像裁剪,裁剪图像大小始终保证256×256pixels。此时,对训练目标的多方式几何裁剪,我认为也是一种图像正则化方式。
基于ENVI软件利用subset by roi操作保存文件(save as)为TIFF格式并保证训练样本大小为256×256pixels。

补充:Sentinel-2批量转换生成RGB格式图片的便捷方式详见参考资料[4]。
二、labelme软件的下载安装
labelme是基于python、Qt编写的具有图形交互界面的图形图像注释工具,其需要由命令行启动。在labelme软件的下载中,我们可能会遇到由网络引起的下载失败问题,此类问题通常可以通过添加镜像或者直接反复下载解决。
具体下载方法如下:
# 第一步:打开下载好的Anaconda Navigator(anaconda3)软件
# 第二步:打开CMD.exe Prompt
# 第三步:创建Python虚拟环境
conda create --name=labelme python=3.6
# 第四步:激活labelme虚拟环境
conda activate labelme
# 第五步:下载labelme软件(任选一种适合自己并能成功下载的方式)
(可选)pip install labelme
(可选)pip install labelme --trusted-host http://mirrors.aliyun.com/pypi/simple
(可选)pip install labelme --trusted-host https://pypi.mirrors.ustc.edu.cn/simple
(可选)pip install labelme --trusted-host http://pypi.tuna.tsinghua.edu.cn/simple
# 下载成功
三、labelme语义分割数据标注方法
(一)打开labelme软件
# 第一步:打开anaconda3
# 第二步:打开CMD.exe Prompt
第三步:activate labelme
第四步:labelme

(二)载入样本图片
File -> Open -> 选择样本图片->open;
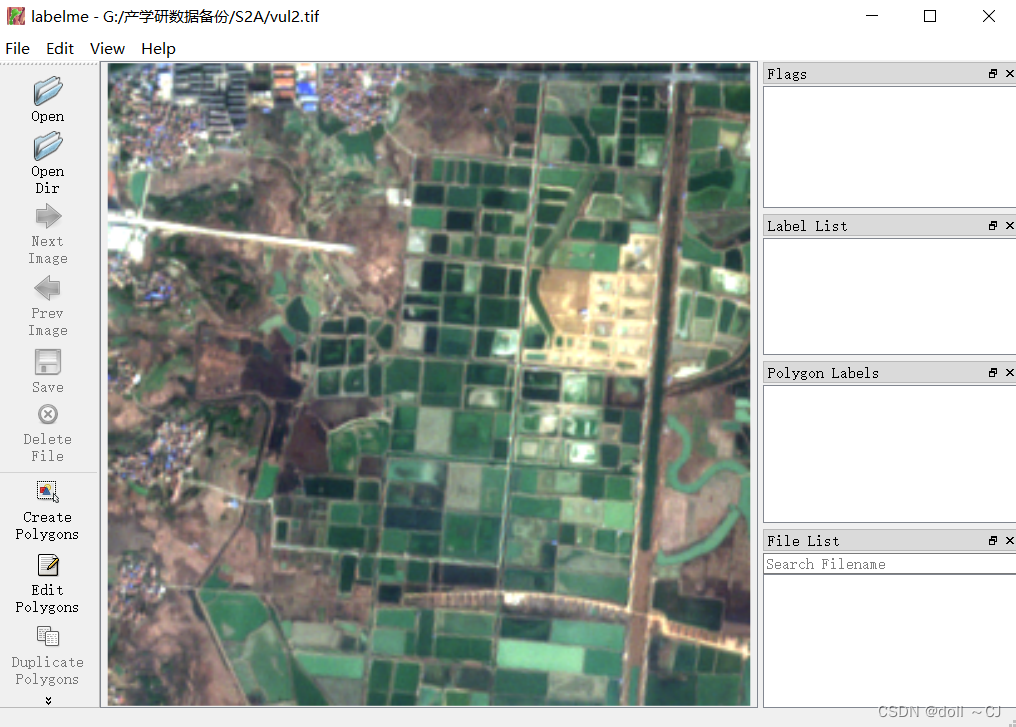
(三) 勾选训练目标并保存标注文件
Create Polygons -> 定义目标标签与类别号->Save(保存类别文件);

(四)关闭GUI后,在命令行运用labelme_draw_json 查看分割文件


(五)利用labelme_json_to_dataset命令形成样本文件(忽略命令行后的提示)


(六)(统一数据集格式)使得语义分割标注数据的目标为白色,背景为黑色
命令行转换后的数据为R波段为0/128标识,B\G波段为0的RGB图像,而为了匹配基础数据集,此处需要将128全部替换为255并且输出单幅灰度图像。
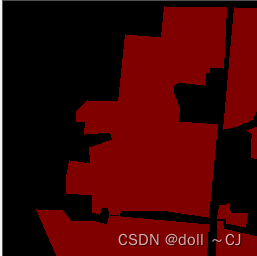

图四 转换前 图五 转换后
# 此处可直接构建文件夹进行批量化转换
# opencv识别路径不带中文
path = r"G:\ChanXueYanRemark\label.png"
# 以灰度图像读取
img = cv2.imread(path)
B,G,R = cv2.split(img)
R[R == 128] = 255
cv2.imwrite("label4.png",R)(七)标签制作数据展示
os.listdir()所读取到的文件名是乱序的,可选择处理文件名调用list.sort()函数可以对文件按顺序排序或利用字符串解析方法提取相对应文件。

参考资料:
[1]深度学习图像标签标注软件labelme超详细教程 - 知乎
[2]https://scihub.copernicus.eu/dhus/#/home
[3]https://jcb-excellent.blog.csdn.net/article/details/125992493
[4]Sentinel 2 批量zip生成RGB图:s22rgb - 知乎
[5]百分位(percentile)是什么概念?怎么理解第95个百分位(95th percentile)_你的瓦刀的博客-CSDN博客_百分位
[6]labelme/examples/tutorial at main · wkentaro/labelme · GitHub