各函数包与函数模块之间的所属关系如图:
注意,所有函数包以及Notbook文件都是所属父文件夹的同级别文件,只有这样才能顺利调用所需函数
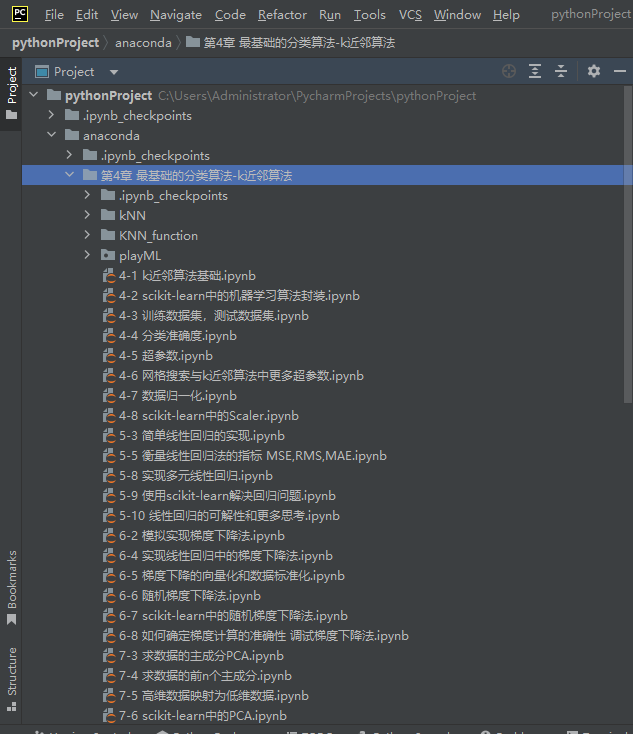
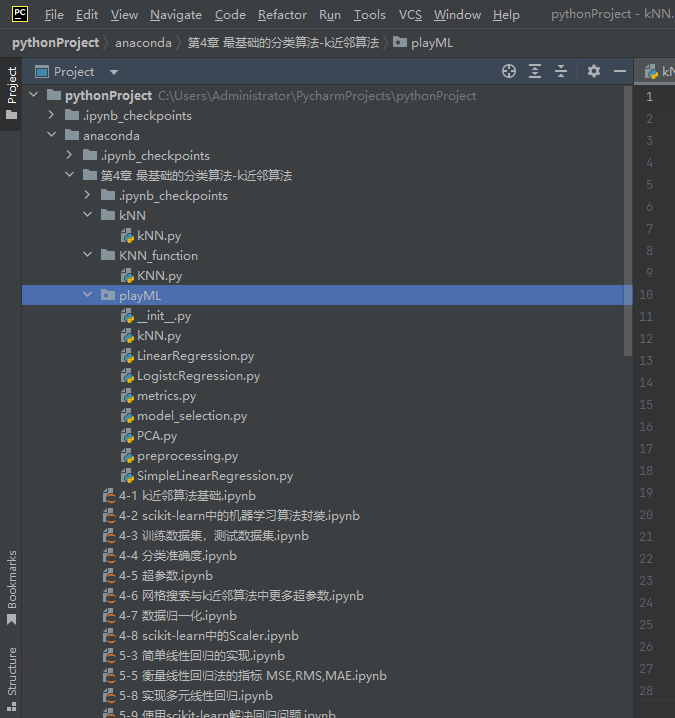
各函数包如下:
kNN
import numpy as np
from math import sqrt
from collections import Counter
class KNNClassifier:
def __init__(self, k):
"""初始化kNN分类器"""
assert k >= 1, "k must be valid"
self.k = k
self._X_train = None
self._y_train = None
def fit(self, X_train, y_train):
"""根据训练数据集X_train和y_train训练kNN分类器"""
assert X_train.shape[0] == y_train.shape[0],\
"the size of X_train must be equal to the size of y_train"
assert self.k <= X_train.shape[0],\
"the size of X_train must be at least k ."
self._X_train = X_train
self._y_train = y_train
return self
def predict(self, X_predict): # predict(self, X_predict)
"""给定待预测数据集X_predict,返回X_predict的结果向量"""
assert self._X_train is not None and self._y_train is not None,\
" must fit before predict!"
assert X_predict.shape[1] == self._X_train.shape[1],\
" the feature number of X_predict must be equal to X_train"
y_predict = [self._predict(x) for x in X_predict]
return np.array(y_predict)
def _predict(self, x):
"""给定单个待测数据x,返回x的预测结果值"""
assert x.shape[0] == self._X_train.shape[1],\
"the feature number of x must be equal to x_train"
distances = [sqrt(np.sum((x_train - x) ** 2))
for x_train in self._X_train]
nearest = np.argsort(distances)
topK_y = [self._y_train[i] for i in nearest[:self.k]]
votes = Counter(topK_y)
return votes.most_common(1)[0][0]
def __repr__(self):
return "KNN(k=%d)" % self.k
KNN_function
# KNN_classify()
import numpy as np
from math import sqrt
from collections import Counter
def KNN_classify (k, X_trian, y_trian, x):
assert 1 <= k <= X_trian.shape[0], ' k must be valid'
assert X_trian.shape[0] == y_trian.shape[0],\
'the size of X_trian must equal to the size of y_trian '
assert X_trian.shape[1] == x.shape[0],\
"the feature number of must be equal to X_trian "
distances = [sqrt(np.sum(x_trian - x) ** 2) for x_trian in X_trian]
nearest = np.argsort(distances)
topk_y = [y_trian[i] for i in nearest[:k]]
votes = Counter(topk_y)
return votes.most_common(1)[0][0]
print(" KNN_classify 已加载.")
playML:
kNN.py
import numpy as np
from math import sqrt
from collections import Counter
from .metrics import accuracy_score # from .metrics 报错
class KNNClassifier:
def __init__(self, k):
"""初始化kNN分类器"""
assert k >= 1, "k must be valid"
self.k = k
self._X_train = None
self._y_train = None
def fit(self, X_train, y_train):
"""根据训练数据集X_train和y_train训练kNN分类器"""
assert X_train.shape[0] == y_train.shape[0],\
"the size of X_train must be equal to the size of y_train"
assert self.k <= X_train.shape[0],\
"the size of X_train must be at least k ."
self._X_train = X_train
self._y_train = y_train
return self
def predict(self, X_predict): # predict(self, X_predict)
"""给定待预测数据集X_predict,返回X_predict的结果向量"""
assert self._X_train is not None and self._y_train is not None,\
" must fit before predict!"
assert X_predict.shape[1] == self._X_train.shape[1],\
" the feature number of X_predict must be equal to X_train"
y_predict = [self._predict(x) for x in X_predict]
return np.array(y_predict)
def _predict(self, x):
"""给定单个待测数据x,返回x的预测结果值"""
assert x.shape[0] == self._X_train.shape[1],\
"the feature number of x must be equal to x_train"
distances = [sqrt(np.sum((x_train - x) ** 2))
for x_train in self._X_train]
nearest = np.argsort(distances)
topK_y = [self._y_train[i] for i in nearest[:self.k]]
votes = Counter(topK_y)
return votes.most_common(1)[0][0]
def score(self, X_test, y_test):
"""根据测试数据集 X_test 和 y_test 确定当前模型的准确度"""
y_predict = self.predict(X_test) # self._predict(X_test),大意了直接采纳第一个提示
return accuracy_score(y_test, y_predict)
def __repr__(self):
return "KNN(k=%d)" % self.k
LinearRegression.py
import numpy as np
from .metrics import r2_score
# 源名需加kNN
class LinearRegression:
def __int__(self):
"""初始化 Linear Regression 模型"""
self.coef_ = None
self.interception_ = None
self._theta = None
def fit_normal(self, X_train, y_train):
"""根据训练数据集 X_train, y_train 训练 Linear Regression 模型"""
assert X_train.shape[0] == y_train.shape[0], \
"the size of X_train must be equal to the size of y_train"
X_b = np.hstack([np.ones((len(X_train), 1)), X_train])
self._theta = np.linalg.inv(X_b.T.dot(X_b)).dot(X_b.T).dot(y_train)
self.interception_ = self._theta[0]
self.coef_ = self._theta[1:]
return self
def fit_gd(self, X_train, y_train, eta=0.001, n_iters=1e4):
"""根据训练数据集 X_trian, y_train,使用梯度下降法训练 Linear Regression模型"""
assert X_train.shape[0] == y_train.shape[0], \
"the size of X_train must equal to the size of y_train"
def J(theta, X_b, y):
try:
return np.sum((y - X_b.dot(theta)) ** 2) / len(X_b)
except:
return float('inf')
def dJ(theta, X_b, y):
# res = np.empty(len(theta))
# res[0] = np.sum(X_b.dot(theta) - y)
# for i in range(1, len(theta)):
# res[i] = (X_b.dot(theta) - y).dot(X_b[:, i])
# return res * 2 / len(theta)
return X_b.T.dot(X_b.dot(theta) - y) * 2 / len(y)
def gradient_descent(X_b, y, initial_theta, eta, n_iters=1e5, epsilon=1e-8):
theta = initial_theta
# theta_history.append(initial_theta)
i_iters = 0
while i_iters < n_iters:
gradient = dJ(theta, X_b, y)
last_theta = theta
theta = theta - eta * gradient
# theta_history.append(theta)
if (abs(J(theta, X_b, y) - J(last_theta, X_b, y)) < epsilon):
break
i_iters += 1
return theta
X_b = np.hstack([np.ones((len(X_trian), 1)), X_trian])
initial_theta = np.zeros(X_b.shape[1])
self._theta = gradient_descent(X_b, y_train, initial_theta, eta)
self.interception_ = self._theta[0]
self.coef_ = self._theta[1:]
return self
def fit_sgd(self, X_train, y_train, n_iters=5, t0=5, t1=50):
"""根据训练数据集 X_trian, y_train,使用梯度下降法训练 Linear Regression模型"""
assert X_train.shape[0] == y_train.shape[0], \
"the size of X_train must equal to the size of y_train"
assert n_iters >= 1,\
"the size of n_iters must >= 1"
def dJ_sgd(theta, X_b_i, y_i):
return X_b_i.T.dot(X_b_i.dot(theta) - y_i) * 2
def sgd(X_b, y, initial_theta, n_iters, t0=5, t1=50):
def learning_rate(t):
return t0 / (t + t1)
theta = initial_theta
m = len(X_b)
for cur_iter in range(n_iters):
indexes = np.random.permutation(m)
X_b_new = X_b[indexes]
y_new = y[indexes]
for i in range(m):
gradient = dJ_sgd(theta, X_b_new[i], y_new[i])
theta = theta - learning_rate(cur_iter * m + i) * gradient
return theta
X_b = np.hstack([np.ones((len(X_train), 1)), X_train])
initial_theta = np.zeros(X_b.shape[1])
self._theta = sgd(X_b, y_train, initial_theta, n_iters, t0, t1)
self.interception_ = self._theta[0]
self.coef_ = self._theta[1:]
return self
def predict(self, X_predict):
"""给定待测数据集 X_predict,返回表示 X_predict 的结果向量 """
assert self.interception_ is not None and self.coef_ is not None, \
"must fit before predict!"
assert X_predict.shape[1] == len(self.coef_), \
"the feature number of X_predict must be equal to X_train"
X_b = np.hstack([np.ones((len(X_predict), 1)), X_predict])
return X_b.dot(self._theta)
def score(self, X_test, y_test):
"""根据测试数据集 X_test 和 y_test 确定当前模型的准确度"""
y_predict = self.predict(X_test)
return r2_score(y_test, y_predict)
def __repr__(self):
return "LinearRegression()"
LogistcRegression.py
import numpy as np
from .metrics import accuracy_score
# 源名需加kNN
class LogisticRegression:
def __int__(self):
"""初始化 LogisticRegression 模型"""
self.coef_ = None
self.interception_ = None
self._theta = None
def _sigmoid(self, t):
return 1 / (1 + np.exp(-t))
def fit(self, X_train, y_train, eta=0.001, n_iters=1e4):
"""根据训练数据集 X_trian, y_train,使用梯度下降法训练 LogisticRegression模型"""
assert X_train.shape[0] == y_train.shape[0], \
"the size of X_train must equal to the size of y_train"
def J(theta, X_b, y):
y_hat = self._sigmoid(X_b.dot(theta))
try:
return - np.sum(y*np.log(y_hat) + (1-y)*np.log(1-y_hat)) / len(y)
except:
return float('inf')
def dJ(theta, X_b, y):
return X_b.T.dot(self._sigmoid(X_b.dot(theta)) - y) * 2 / len(y)
def gradient_descent(X_b, y, initial_theta, eta, n_iters=1e5, epsilon=1e-8):
theta = initial_theta
# theta_history.append(initial_theta)
i_iters = 0
while i_iters < n_iters:
gradient = dJ(theta, X_b, y)
last_theta = theta
theta = theta - eta * gradient
# theta_history.append(theta)
if (abs(J(theta, X_b, y) - J(last_theta, X_b, y)) < epsilon):
break
i_iters += 1
return theta
X_b = np.hstack([np.ones((len(X_train), 1)), X_train])
initial_theta = np.zeros(X_b.shape[1])
self._theta = gradient_descent(X_b, y_train, initial_theta, eta)
self.interception_ = self._theta[0]
self.coef_ = self._theta[1:]
return self
def predict_proba(self, X_predict):
"""给定待测数据集 X_predict,返回表示 X_predict 的结果概率向量 """
assert self.interception_ is not None and self.coef_ is not None, \
"must fit before predict!"
assert X_predict.shape[1] == len(self.coef_), \
"the feature number of X_predict must be equal to X_train"
X_b = np.hstack([np.ones((len(X_predict), 1)), X_predict])
return self._sigmoid(X_b.dot(self._theta))
def predict(self, X_predict):
"""给定待测数据集 X_predict,返回表示 X_predict 的结果向量 """
assert self.interception_ is not None and self.coef_ is not None, \
"must fit before predict!"
assert X_predict.shape[1] == len(self.coef_), \
"the feature number of X_predict must be equal to X_train"
proba = self.predict_proba(X_predict)
return np.array(proba >= 0.5, dtype='int')
def score(self, X_test, y_test):
"""根据测试数据集 X_test 和 y_test 确定当前模型的准确度"""
y_predict = self.predict(X_test)
return accuracy_score(y_test, y_predict)
def __repr__(self):
return "LogisticRegression()"
metrics.py
import numpy as np
from math import sqrt
def accuracy_score(y_ture, y_predict):
"""计算 y_ture与 y_predict之间的准确度"""
assert y_ture.shape[0] == y_predict.shape[0]
"the size of y_ture must be equal to the size of y_predict"
return sum(y_ture == y_predict)/len(y_ture)
def mean_squared_error(y_ture, y_predict):
"""计算 y_ture,与 y_predict 之间的MSE """
assert len(y_ture) == len(y_predict), \
"the size of y_ture must be equal to the size of y_predict "
return np.sum((y_ture - y_predict) ** 2) / len(y_ture)
def root_mean_squared_error(y_ture, y_predict):
"""计算 y_ture与 y_predict之间的RMSE"""
assert len(y_ture) == len(y_predict), \
"the size of y_ture must be equal to the size of y_predict "
return sqrt(mean_squared_error(y_ture, y_predict))
def mean_absolute_error(y_ture, y_predict):
"""计算 y_ture,与 y_predict 之间的MAE """
assert len(y_ture) == len(y_predict), \
"the size of y_ture must be equal to the size of y_predict "
return np.sum(np.absolute(y_ture - y_predict)) / len(y_predict)
def r2_score(y_ture, y_predict):
"""计算 y_ture,与 y_predict 之间的 R Square """
return 1 - mean_squared_error(y_ture, y_predict) / np.var(y_ture)
def TN(y_ture, y_predict):
assert len(y_ture) == len(y_predict)
return np.sum((y_ture == 0) & (y_predict == 0))
def FP(y_ture, y_predict):
assert len(y_ture) == len(y_predict)
return np.sum((y_ture == 0) & (y_predict == 1))
def FN(y_ture, y_predict):
assert len(y_ture) == len(y_predict)
return np.sum((y_ture == 1) & (y_predict == 0))
def TP(y_ture, y_predict):
assert len(y_ture) == len(y_predict)
return np.sum((y_ture == 1) & (y_predict == 1))
def confusion_matrix(y_true, y_predict):
return np.array([
[TN(y_true,y_predict), FP(y_true,y_predict)],
[FN(y_true,y_predict), TP(y_true,y_predict)]
])
def precision_score(y_true, y_predict):
tp = TP(y_true, y_predict)
fp = FP(y_true, y_predict)
try:
return tp / (tp + fp)
except:
return 0.0
def recall_score(y_true, y_predict):
tp = TP(y_true, y_predict)
fn = FN(y_true, y_predict)
try:
return tp / (tp + fn)
except:
return 0.0
def f1_score(precision, recall):
try:
return 2 * precision * recall / ( precision + recall)
except:
return 0.0
def TPR(y_true, y_predict):
tp = TP(y_true, y_predict)
fn = FN(y_true, y_predict)
try:
return tp / (tp + fn)
except:
return 0.0
def FPR(y_true, y_predict):
tp = TP(y_true, y_predict)
tn = TN(y_true, y_predict)
try:
return tp / (tp + tn)
except:
return 0.0
model_selection.py
import numpy as np
def train_test_split(X, y, test_radio=0.2, seed=None):
"""将数据X和y按照test_radio分割成X_train、y_train、X_test、y_test"""
assert X.shape[0] == y.shape[0],\
"the size of X must be equal to the size of y"
assert 0.0 <= test_radio <= 1.0,\
"test_ration must be valid"
if seed:
np.random.seed(seed)
shuffled_indexes = np.random.permutation(len(X))
test_size = int(test_radio * len(X))
test_indexes = shuffled_indexes[:test_size]
train_indexes = shuffled_indexes[test_size:]
X_train = X[train_indexes]
y_train = y[train_indexes]
X_test = X[test_indexes]
y_test = y[test_indexes]
return X_train, X_test, y_train, y_test
PCA.py
import numpy as np
class PCA:
def __init__(self, n_components):
""" 初始化"""
assert n_components >= 1, "n_components must be valid"
self.n_components = n_components
self.components = None
def fit(self, X, eta=0.01, n_iters=1e4):
"""获得数据集 X 的前 n 个主成分"""
assert self.n_components <= X.shape[1], \
"n_components must not be greater than feature number of X"
def demean(X):
return X - np.mean(X, axis=0)
def f(w, X):
return np.sum((X.dot(w) ** 2)) / len(X)
def df(w, X):
return X.T.dot(X.dot(w)) * 2.0 / len(X)
def direction(w):
return w / np.linalg.norm(w)
def first_componet(X, initial_w, eta, n_iters=1e4, epsilon=1e-8):
w = direction(initial_w)
i_iters = 0
while i_iters < n_iters:
gradient = df(w, X)
last_w = w
w = w + eta * gradient
w = direction(w) # 注意1:每次求一个单位方向
if (abs(f(w, X) - f(last_w, X)) < epsilon):
break
i_iters += 1
return w
X_pca = demean(X)
self.components_ = np.empty(shape=(self.n_components, X.shape[1]))
res = []
for i in range(self.n_components):
initial_w = np.random.random(X_pca.shape[1])
w = first_componet(X_pca, initial_w, eta, n_iters)
self.components_[i, :] = w
X_pca = X_pca - X_pca.dot(w).reshape(-1, 1) * w
return self
def transform(self, X):
"""将X给定的,映射到各个主成分分量中"""
assert X.shape[1] == self.components_.shape[1]
return X.dot(self.components_.T)
def inverse_transform(self, X):
"""将给定的X,反向映射回原来的特征空间"""
assert X.shape[1] == self.components_.shape[0]
return X.dot(self.components_)
def __repr__(self):
return "PCA(n_components=%d)" % self.n_components
preprocessing.py
import numpy as np
class StandardScaler:
def __int__(self):
self.mean_ = None
self.scale_ = None
def fit(self, X):
"""根据训练数据集X获得数据的均值和方差"""
assert X.ndim == 2, "The dimension of X must be 2"
self.mean_ = np.array(np.mean(X[:, i]) for i in range(X.shape[1]))
self.scale_ = np.array(np.std(X[:, i]) for i in range(X.shape[1]))
return self
def transform(self, X):
""" 将 X 根据这个StandardScaler进行均值方差归一化处理"""
assert X.ndim == 2, "The dimension of X must be 2"
assert self.mean_ is not None and self.scale_ is not None,\
"must fit before transform!"
assert X.shape[1] == len(self.mean_), \
"The feature number of X must be equal to mean_ and std_"
resX = np.empty(shape=X.shape, dtype=float)
for col in range(X.shape[1]):
resX[:, col] = (X[:, col] - self.mean_[col]) / self.scale_[col]
return resX
SimpleLinearRegression.py
import numpy as np
from .metrics import r2_score # 加点下标运行报错,不加点下标jupyter 能运行
class SimpleLinearRegression1:
def __int__(self):
"""初始化 Simple Linear Regression 模型"""
self.a_ = None
self.b_ = None
def fit(self, x_train, y_train):
"""根据训练数据集x_train,y_train 训练 Simple Linear Regression 模型"""
assert x_train.ndim == 1, \
" Simple Linear Regression can only solve single feature training data"
assert len(x_train) == len(y_train), \
"the size of x_train must be equal to the size of y_train"
x_mean = np.mean(x_train)
y_mean = np.mean(y_train)
num = 0.0
d = 0.0
for x, y in zip(x_train, y_train):
num += (x - x_mean) * (y - y_mean)
d += (x - x_mean) ** 2
self.a_ = num / d
self.b_ = y_mean - self.a_ * x_mean
return self
def predict(self, x_predict):
"""给定待测数据集x_predict,返回表示x_predict的结果向量"""
# print(x_predict.ndim)
assert x_predict.ndim == 1, \
"Simple Linear Regression can only solve single feature training data"
assert self.a_ is not None and self.b_ is not None, \
"must fit before predict!"
return np.array([self._predict(x) for x in x_predict]) # predict(x)无下划线问题严重
def _predict(self, x_single):
"""给定单个待测数据 x_single,返回x_single的预测结果值"""
return self.a_ * x_single + self.b_
def __repr__(self):
return "Simple Linear Regression1()"
class SimpleLinearRegression2:
def __int__(self):
"""初始化 Simple Linear Regression 模型"""
self.a_ = None
self.b_ = None
def fit(self, x_train, y_train):
"""根据训练数据集x_train,y_train 训练 Simple Linear Regression 模型"""
assert x_train.ndim == 1, \
" Simple Linear Regression can only solve single feature training data"
assert len(x_train) == len(y_train), \
"the size of x_train must be equal to the size of y_train"
x_mean = np.mean(x_train)
y_mean = np.mean(y_train)
num = 0.0
d = 0.0
num = (x_train - x_mean).dot(y_train - y_mean)
d = (x_train - x_mean).dot(x_train - x_mean)
self.a_ = num / d
self.b_ = y_mean - self.a_ * x_mean
return self
def predict(self, x_predict):
"""给定待测数据集x_predict,返回表示x_predict的结果向量"""
# print(x_predict.ndim)
assert x_predict.ndim == 1, \
"Simple Linear Regression can only solve single feature training data"
assert self.a_ is not None and self.b_ is not None, \
"must fit before predict!"
return np.array([self._predict(x) for x in x_predict]) # predict(x)无下划线问题严重
def _predict(self, x_single):
"""给定单个待测数据 x_single,返回x_single的预测结果值"""
return self.a_ * x_single + self.b_
def score(self, x_test, y_test):
"""根据测试数据集 x_test 和 y_test 确定当前模型的准确度"""
y_predict = self.predict(x_test)
return r2_score(y_test, y_predict)
def __repr__(self):
return "Simple Linear Regression2()"