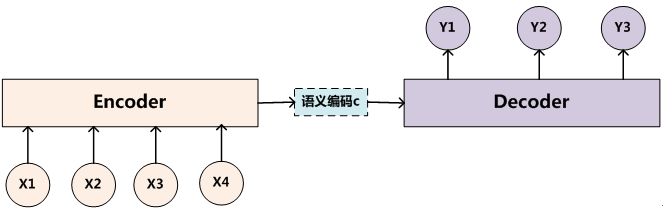
编码器
常见的深度学习模型有 CNN、RNN、LSTM、AE 等,其实都可以归为一种通用框架 - Encoder-Decoder.
Attention
定义:
简单来说:表示重要性的权值向量。
注意力向量Q、与其他元素K、计算相似度,相似度再与元素集合V加权求和,得到权值向量
Q、K、V ----- softmax(Q,K)*V

Self-Attention
实际上,Attention 机制听起来高大上,其关键就是学出一个权重分布,然后作用在特征上。
- 这个权重可以保留所有的分量,叫加权(Soft Attention),也可以按某种采样策略选取部分分量(Hard Attention)。
- 这个权重可以作用在原图上,如目标物体检测;也可以作用在特征图上,如 Image-Caption
- 这个权重可以作用在空间尺度上,也可以作用于 Channel 尺度上,给不同通道的特征加权
- 这个权重可以作用在不同时刻上,如机器翻译