本篇文章主要描述一下结巴库的基本使用方式有哪些:
目录
Python里面可以使用的第三方中文分词库有哪些?
- HanLP
- LIP
- jieba
jieba库目的?
中文文本之间每个汉字都是连续书写的,我们需要通过特定的手段来获得其中的每个词组,这种手段叫做分词,jieba号称要做最好的 Python 中文分词组件。
jieba分词的原理
①分词依靠中文词库
② 利用一个中文词库,确定汉字之间的关联概率
③ 汉字间概率大的组成词组,形成分词结果
④ 除了分词,用户还可以添加自定义的词组
可以通过jieba库来完成这个过程
jieba库使用说明
(1)jieba分词的三种模式
精确模式、全模式、搜索引擎模式
1)精确模式:就是把一段文本精确地切分成若干个中文单词,若干个中文单词之间经过组合,就精确地还原为之前的文本。其中不存在冗余单词。
2)全模式:将一段文本中所有可能的词语都扫描出来,可能有一段文本它可以切分成不同的模式,或者有不同的角度来切分变成不同的词语,在全模式下,Jieba库会将各种不同的组合都挖掘出来。分词后的信息再组合起来会有冗余,不再是原来的文本。
3)搜索引擎模式:在精确模式基础上,对发现的那些长的词语,我们会对它再次切分,进而适合搜索引擎对短词语的索引和搜索。也有冗余。
Jieba库常用函数:重点记输入什么类型(字符串?列表?)、输出什么类型(字符串(jieba.cut)列表(jieba.lcut);
① jieba.cut(s) 精确模式:把文本精确的切分开,不存在冗余单词:
参数解释:
「strs」: 需要分词的字符串;
「cut_all」:用来控制是否采用全模式;
「HMM」:用来控制是否使用 HMM 模型;
「use_paddle」:用来控制是否使用paddle模式下的分词模式,paddle模式采用延迟加载方式,通过enable_paddle接口安装paddlepaddle-tiny,并且import相关代码;
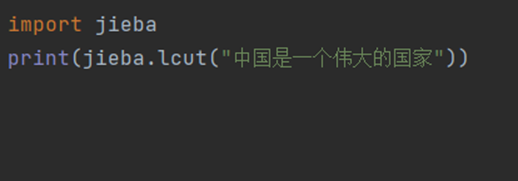

② jieba.lcut(s,cut_all=True) 全模式:把文本中所有可能的词语都扫描出来,有冗余:


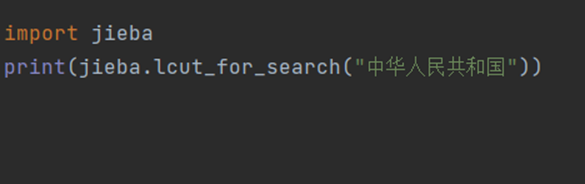
③jieba.lcut_for_search(s) 搜索引擎模式:在精确模式基础上,对长词再次切分:
参数解释:
「strs」:需要分词的字符串;
「HMM」:是否使用 HMM 模型,默认值为 True。该方法适合用于搜索引擎构建倒排索引的分词,粒度比较细。

jieba.Tokenizer(dictionary=DEFAULT_DICT)
新建自定义分词器,可用于同时使用不同词典。jieba.dt 为默认分词器,所有全局分词相关函数都是该分词器的映射。
添加词典用法:
一个词占一行;每一行分三部分:词语、词频(可省略)、词性(可省略),用空格隔开,顺序不可颠倒。
jieba.load_userdict(dict_path) # dict_path为文件类对象或自定义词典的路径。
关键词提取
1,基于TF-IDF算法的关键词提取
import jieba.analyse
2)关键词提取所使用逆向文件频率(IDF)文本语料库可以切换成自定义语料库的路径
用法:
jieba.analyse.set_idf_path(file_name) # file_name为自定义语料库的路径
3)关键词提取所使用停止词(Stop Words)文本语料库可以切换成自定义语料库的路径
- 用法: jieba.analyse.set_stop_words(file_name) # file_name为自定义语料库的路径
- 自定义语料库示例:
4)关键词一并返回关键词权重值示例
词性标注
jieba.posseg.POSTokenizer(tokenizer=None) 新建自定义分词器
路径:
了解更多自行找想要的知识点,个人知识点总结,
https://blog.csdn.net/TFATS/article/details/108810284
Python:jieba库的介绍与使用_python_Algorithm-007-DevPress官方社区 (csdn.net)