本篇文章属于所有发表的文章的导读吧,以后会常更新。
目录
1.数据挖掘、机器学习、深度学习、云计算、人工智能
- 数据挖掘:从海量数据中”挖掘“隐藏信息
- 机器学习:给计算机程序输入数据,让计算机学会新知识
- 深度学习:从大数据中自动学习特征
- 云计算:大规模分布式IT基础设施
- 人工智能:基于学习、认知构成的对人的替代取得高度共识
它们之间的关系:
数据是人工智能的来源,大数据并行计算流计算等技术是人工智能能实用化的保障,人工智能是大数据,尤其复杂数据分析的主要方法
机器学习基础:机器学习(一)——基础概念_三三木木七的博客-CSDN博客。
2.深度学习、强化学习、对抗学习、迁移学习
(待补充)
3.基础知识--线性代数
3.1 标量、向量、矩阵、张量
3.2 矩阵和向量乘法
3.3 单位矩阵和逆矩阵
3.4 线性相关与生成子空间
3.5 范数
3.6 正交向量与子空间
3.7 特殊矩阵和向量
3.8 特征分解
3.9 奇异值分解
3.10 MP伪逆
4.基础知识--概率与数理统计
4.1 概率、概率空间、随机变量
4.2 概率分布
4.3 条件概率
4.4 链式法则、贝叶斯定理
4.5 数学期望
4.6 方差
4.7 相关系数
4.8 最大似然估计
5.常用工具库
5.1 Numpy
Numpy,提供科学计算的基础库,主要提供N维数组实现及计算能力和基础的数学算法。(基础科学计算库)
详情:(1条消息) 机器学习(二)--NumPy_三三木木七的博客-CSDN博客
5.1.1 张量 ✅
逐元素计算
矩阵相加
标量与矩阵相乘
relu运算
5.1.2 广播
5.1.3 张量点积
(1)向量点积
向量元素个数相同
(2) 卷积
5.1.4 矩阵相乘
5.1.5 张量变形
改变张量的行和列,得到想要的形状
变形后张量的元素总数和初始张量相同
特殊的张量变形--转置:行和列交换
5.1.6 下采样
5.2 Scipy
Scipy,基于Numpy开发的一系列数学运算方法。数据操作,并行计算等。(强大的科学计算工具集)
5.3 Pandas
Pandas,功能强大的时间序列数据集处理工具。依赖于Numpy。(数据分析的利器)
5.4 Matplotlib
Matplotlib,数据可视化工具包
5.5 Scikit-learn
Scikit-learn,机器学习
6.机器学习
6.1 什么是训练什么是推理?
机器学习:人们输入数据和从这些数据中预期得到的答案,系统输出规则(训练)。
预测/推理:这些规则随后应用于新的数据,并使计算机自主生成答案。
6.2 机器学习一般流程
从实践的意义上来说,机器学习是一种通过利用数据,训练出模型,然后使用模型预测的一种方法。
一般流程:数据->模型->损失函数->优化->调优->结果分析->算法扩展->部署和运营->基础设施
数据:经验存储
模型:基于问题和数据选取基础模型
损失函数:模型准确度的衡量标准
优化:eg梯度下降法最小化损失函数
调优:调整模型超参数
结果分析:比较模型准确度与运行时间
算法扩展:验证集测试
部署和运营:实时、稳定、拓展
基础设施:推理规模、接口规范、计算能力
6.3 机器学习问题类型
分类
回归
聚类
异常检测
强化学习
7.深度学习
深度学习是机器学习的一类模型,通过组合低层特征形成更加抽象的高层表示属性类别或特征,以发现数据的特征表示。
7.1 前馈神经网络
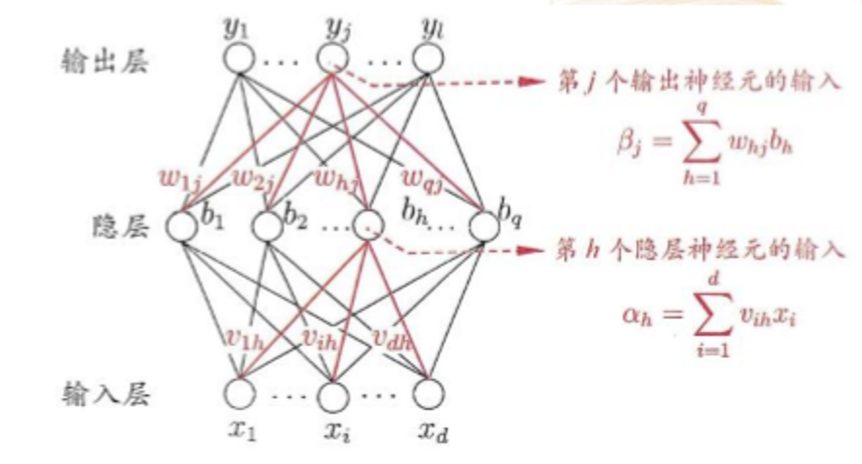
输入层、隐藏层、输出层。
神经元从输入层开始,接受前一级输入,并输出到下一级,直至输出层。
整个网络中无反馈,可用有向无环图表示。
7.2 卷积神经网络
多层神经网络,将局部连接、权值共享、亚采样,这三种结构思想结合,提取图像/文本特征。
7.3 循环神经网络
一种对序列数据建模的神经网络,一个序列当前的输出与前面的输出也有关。
7.4 迁移学习
迁移学习是把易训练好的模型参数迁移到新的模型来帮助新模型训练,可以将已经学到的模型参数通过某种方式来分享给新模型,从而加快并优化模型的学习效率。
7.5 对抗学习
生成式对抗网络核心是对抗式,两个网络互相竞争,一个负责生成样本,另一个负责判别样本
7.6 强化学习
强化学习研究的是智能体Agent与环境之间交互的任务,学习如何将环境映射到动作,以获取最大的,数值的,奖励信号。