1.BipedalWalker环境
BipedalWalker-v3是一个简单的4关节行走机器人环境,用于强化学习任务。这个环境有两个版本:普通版(Normal)和高难度版(Hardcore)。

普通版的地形略为不平,而高难度版包含梯子、树桩和陷阱。在普通版中,要解决问题,需要在1600个时间步内获得300分。在高难度版中,需要在2000个时间步内获得300分。
1.1 环境定义
- 行动空间:动作是每个关节(两个髋关节和两个膝关节)的电机速度值,范围在[-1,1]之间。
- 观察空间:状态包括船体(Hull, 蓝色五边形)角速度、角速度、水平速度、垂直速度、关节位置、关节角速度、腿与地面接触情况以及10个激光雷达测距仪的测量结果。
- 奖励:向前移动会获得奖励,总共可以获得300多分。如果机器人摔倒,会扣除100分。施加电机扭矩会消耗少量分数。更优化的代理程序将获得更高的分数。
- 起始状态:行走者从地形的左端站立起来,船体水平,双腿处于相同位置,膝盖微弯。
- 终止条件:如果船体与地面接触,或者行走者超过地形长度的右端,本回合将终止。
1.2 Baseline
rl-baselines3-zoo中给定了一些算法训练BipedalWalker的基准结果。包括基础模型BipedalWalker-v3以及BipedalWalkerHardcore-v3模型。可以看出,主流算法ddpg、td3等均可以达到300左右的最终reward。
| algo | mean_reward BipedalWalker-v3 / Hardcore |
n_timesteps |
| a2c | 299.754 / 96.171 | 5M / 200M |
| ddpg | 197.486 / - | 1M / - |
| ppo | 287.939 / 122.374 | 5M / 100M |
| sac | 297.668 / 4.423 | 500 k / 10M |
| td3 | 305.990 / -98.116 | 1M / 10M |
| tqc | 329.808 / 235.226 | 500k / 2M |
1.3 自定义Gymnasium模型
为什么?
为什么Gym库已经配置好了的环境,还需要自定义环境呢?因为Gym库存在由Ray触发的观测空间的Bug,需要修改Gym原环境。
根据2023年3月提交的一份Bug Report,Gymnasium环境库似乎存在Observation is outside the given space的问题,此Bug我在RayRL的训练中会遇到,参考:
-
Bug Report
- Bug fix
上述问题出现于gymnasium/envs/box2d/lunar_lander.py文件,似乎在BipedalWalker-v3也会稳定复现,近期笔者准备也在GitHub上也提一个Bug Report。
如何自定义Gymnasium环境
1) 在Anaconda环境中,于~/anaconda3/envs/RayRLlib/lib/python3.8/site-packages/gymnasium/envs新建一个文件夹my_envs,专门用于存放自定义环境
2) 在my_envs中,新建__init__.py文件,内容为
from gymnasium.envs.my_envs.my_bipedal_walker import my_BipedalWalker, my_BipedalWalkerHardcore其中,my_envs为文件夹名,my_bipedal_walker是自定义环境的python文件名,my_BipedalWalker与my_BipedalWalkerHardcore是自定义环境的class名。
3) 在my_envs中,复制新建my_bipedal_walker.py文件,并修改。
相对于原其余bipedal_walker.py文件,将bipedal_walker.py文件中的BipedalWalker均改为my_BipedalWalker。并修改观测空间:
...
class my_BipedalWalker(gym.Env, EzPickle):
...
# we use 5.0 to represent the joints moving at maximum
# 5 x the rated speed due to impulses from ground contact etc.
low = np.array(
[
-math.pi * SCALE * 2 ,
-5.0 * SCALE * 2,
-5.0 * SCALE * 2,
-5.0 * SCALE * 2,
-math.pi * SCALE * 2,
-5.0 * SCALE * 2,
-math.pi * SCALE * 2,
-5.0 * SCALE * 2,
-0.0 * SCALE * 2,
-math.pi * SCALE * 2,
-5.0 * SCALE * 2,
-math.pi * SCALE * 2,
-5.0 * SCALE * 2,
-0.0 * SCALE * 2,
]
+ [-1.0 * int(SCALE) * 2] * 10
).astype(np.float32)
high = np.array(
[
math.pi * SCALE * 2,
5.0 * SCALE * 2,
5.0 * SCALE * 2,
5.0 * SCALE * 2,
math.pi * SCALE * 2,
5.0 * SCALE * 2,
math.pi * SCALE * 2,
5.0 * SCALE * 2,
5.0 * SCALE * 2,
math.pi * SCALE * 2,
5.0 * SCALE * 2,
math.pi * SCALE * 2,
5.0 * SCALE * 2,
5.0 * SCALE * 2,
]
+ [1.0 * int(SCALE) * 2] * 10
).astype(np.float32)
...
其中,观测空间均乘以了SCALE * 2。
4) 在~/anaconda3/envs/RayRLlib/lib/python3.8/site-packages/gymnasium/envs文件夹下,修改与box2d、my_envs、classic_control并列的__init__.py文件,添加my_BipedalWalker-v0的注册内容。
"""Registers the internal gym envs then loads the env plugins for module using the entry point."""
from typing import Any
from gymnasium.envs.registration import (
...
)
# My self-defined envs reg
# ----------------------------------------
register(
id="my_BipedalWalker-v0",
entry_point="gymnasium.envs.my_envs.my_bipedal_walker:my_BipedalWalker",
max_episode_steps=1600,
reward_threshold=300,
)
# Classic
# ----------------------------------------
......此时,可通过make my_BipedalWalker-v0来导入修改过观测空间的环境。
2. 基于RayRLlib的训练
采用algo.train()方法训练,强化学习算法采用Apex-DDPG,主要超参数为
| actor_hiddens |
[200, 200] |
| actor_hidden_activation |
relu |
| actor_lr |
0.0001 |
| critic_hiddens |
[200, 200] |
| critic_hidden_activation |
relu |
| critic_lr |
0.0001 |
| replay_buffer_config["capacity"] |
5_000_000 |
| observation_filter |
MeanStdFilter |
| rollout_fragment_length |
10 |
| smooth_target_policy |
True |
| tau |
0.005 |
| target_network_update_freq |
500 |
| target_noise |
0.3 |
| target_noise_clip |
0.5 |
| train_batch_size |
128 |
import gymnasium as gym
from ray.rllib.algorithms.apex_ddpg.apex_ddpg import ApexDDPGConfig
from ray.rllib.algorithms.ppo import PPOConfig
from ray.tune.logger import pretty_print
import numpy as np
import math
import time
import os
import random
SCALE = 30.0
ob_low = np.array([-3.14, -5., -5., -5., -3.14, -5., -3.14, -5., 0., -3.14, -5., -3.14, -5., 0., -1., -1., -1., -1., -1., -1., -1., -1., -1., -1. ]) * SCALE * 2
ob_high = np.array([3.14, 5., 5., 5., 3.14, 5., 3.14, 5., 5., 3.14, \
5., 3.14, 5., 5., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1. ]) * SCALE * 2
at_low=np.array([-1.0, -1.0, -1.0, -1.0])
at_high=np.array([1.0, 1.0, 1.0, 1.0])
config = ApexDDPGConfig()
config = (
ApexDDPGConfig()
.framework("torch")
.environment(
env = "my_BipedalWalker-v0" ,
observation_space=gym.spaces.Box(low=ob_low , high=ob_high, shape=(24,)),
action_space=gym.spaces.Box(low=at_low, high=at_high, shape=(4,)),
)
.training(use_huber=False,n_step=1)
.rollouts(num_envs_per_worker=10)
.resources(num_gpus=1)
.resources(num_trainer_workers=18)
.rollouts(num_rollout_workers=20)
)
config["actor_hiddens"] = [200, 200]
config["actor_hidden_activation"] = 'relu'
config["actor_lr"] = 0.0001
config["critic_hiddens"] = [200, 200]
config["critic_hidden_activation"] = 'relu'
config["critic_lr"] = 0.0001
config.replay_buffer_config["capacity"] = 5_000_000 # 500_000_000 occupies 9.75GBx4 memory
config["clip_rewards"] = False
config["lr"] = 0.0001
config["rollout_fragment_length"] = 10
config["smooth_target_policy"] = True
config["tau"] = 0.005
config["target_network_update_freq"] = 500
config["target_noise"] = 0.3
config["target_noise_clip"] = 0.5
config["train_batch_size"] = 128
config["observation_filter"] = "MeanStdFilter"
print(config.to_dict())
algo = config.build()
for iters in range(1,501):
result = algo.train()
#print(pretty_print(result))
print("\n当前迭代次数: {}".format(iters))
print("平均reward: {}".format(result['episode_reward_mean']))
print("最大reward: {}".format(result['episode_reward_max']))
print("最小reward: {}".format(result['episode_reward_min']))
# tensorboard --logdir /home/.../ray_results/ --port 6699采用3900X+2070训练,Apex算法需要GPU,否则需要在config中改为fake GPU。训练调用了18核心与GPU,训练时长约3h。Reward保持了原生,没有修改(部分博主会将机器人摔倒的负值奖励改为-1以提高训练速度),因此训练初期会由于机器人Hull的倾覆扣大分(如下代码)而Reward增长不稳定。
if self.game_over or pos[0] < 0:
reward = -100
terminated = True3. 训练结果
平均Reward
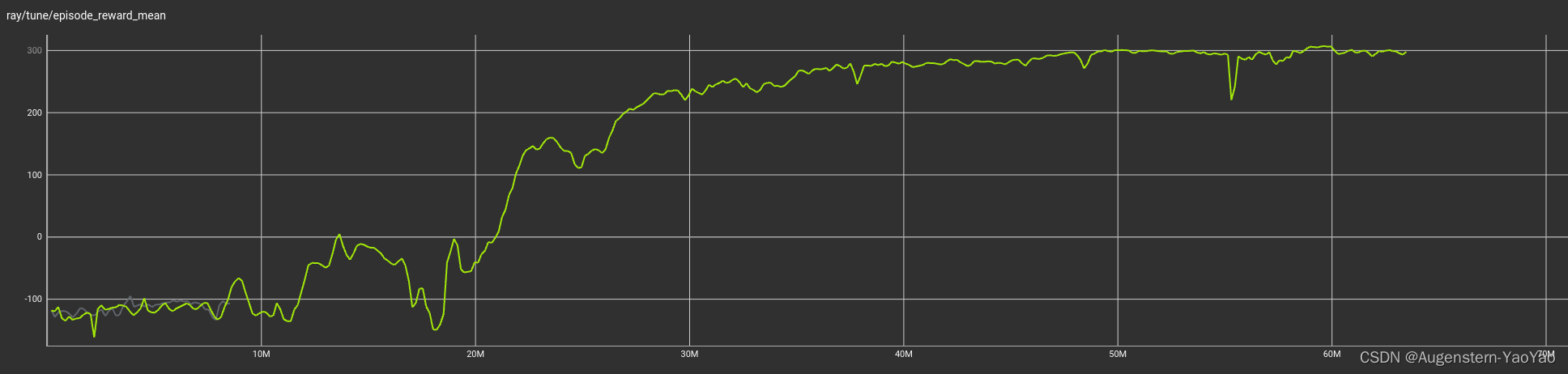
最大Reward
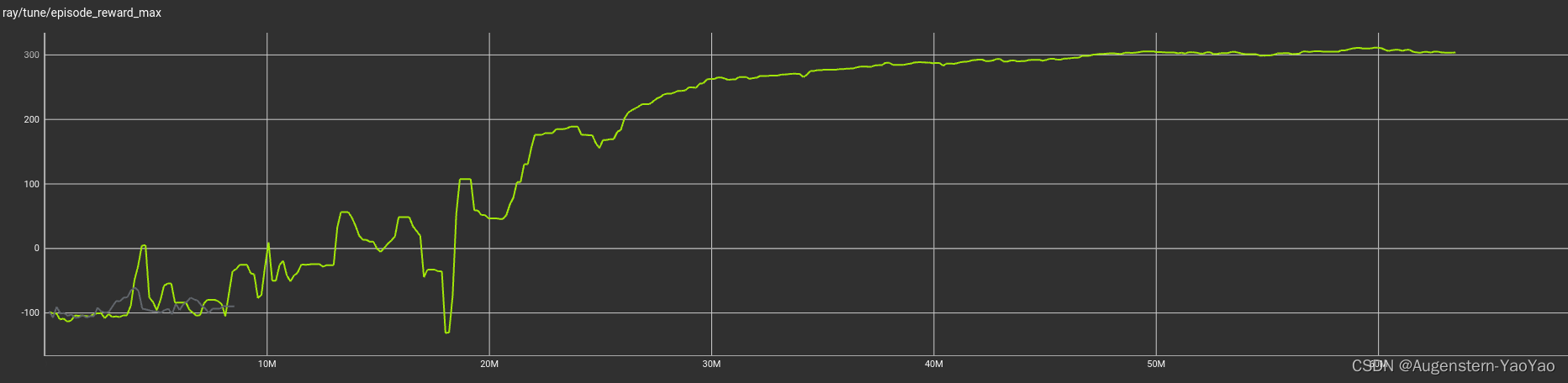
奖励分布
