之前有一段时间整理了Python的基础,是时候来一些实践了。我们都知道,Python提供了很多方便好用、功能强大的库,本篇主要总结使用pandas进行数据处理和分析。
目录
一、前言
中午准备跟同事去吃饭,发现他在那很苦恼。问他 ,说是想用pandas实现一个功能:把某数据平台的CSV文件做简单处理,然后保存为excel文件,因为经常做类似的工作,每次手动去搞比较烦。他的问题是pip3 install pandas总是报错,帮他看了一下,是电脑代理的问题。
回来后,我在想,我也有类似的数据分析工作,但我该场景可能一年有那么两三次,不频繁,也都是手动在搞,心想我也可以使用pandas去写一下。我的需求是:在app某业务场景中,需要统计app每个页面的百分比,并且需要计算累计百分比,我的原始数据是一份统计页面和打开次数的csv文件。

二、代码
代码比较简单,加了点注释,直接上代码:
import pandas as pd
def pandas_head():
# 输入path和输出path
input_path = "origin.csv"
output_path = "result.xlsx"
# 读取csv文件并根据"count"列按照数值大小递减排序
data = pd.read_csv(input_path).sort_values(by="count", ignore_index=True, ascending=False)
# 新增"percent"列,计算百分比
data['percent'] = data['count'] / data['count'].sum(axis=0)
data['percent'] = data['percent'].apply(lambda x: format(x, '.2%'))
# 新增"cum_percent"列,计算累计百分比
data['cum_percent'] = data['count'].cumsum() / data['count'].sum(axis=0)
data['cum_percent'] = data['cum_percent'].apply(lambda x: format(x, '.2%'))
# 保存到excel
data.to_excel(output_path, index=False)
pandas_head()
运行后,输出result.xlsx:
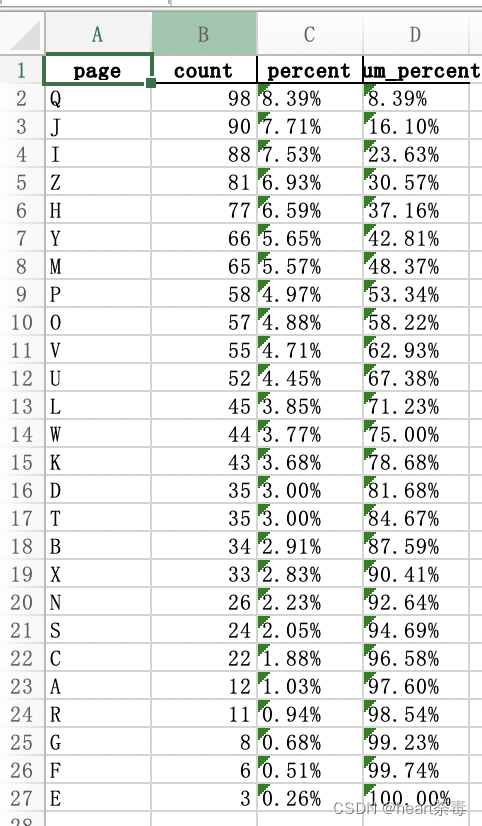
使用excel打开后的效果:
可能会遇到如下报错:

解决方式:导入一下openpyxl包即可。
使用pandas我们可以做很多的日常数据分析工作,相比于自己去导入到excel然后再利用excel的能力/公式等去做数据分析工作,极大的简化了操作步骤,且出错的概率也低很多。