作者:Zhuo Wu, Ethan Yang, Adrian Boguszewski, Anisha Udayakumar, Yiwei Lee, Stephanie Maluso, Raymond Lo, Ryan Loney, Ansley Dunn, Wanglei Shen
As OpenVINO™’s 5-year anniversary approaches, we want to take a moment to express our deepest appreciation for your loyalty and continued use of OpenVINO over the past five years. It has been an incredible journey thus far, and we are proud to have you as a part of our community. Our continuous support from the community has allowed us to reach more than 1 million downloads.
随着OpenVINO™5周年纪念日的临近,我们想花点时间对您在过去五年中对OpenVINO的持续使用表示最深切的感谢。到目前为止,这是一段不可思议的旅程,我们很自豪您能成为我们社区中的一员。社区的持续支持使我们的下载量超过了100万次。
As we mark this important milestone, we are thrilled to announce our latest release, OpenVINO™ 2023.0, with a range of new features and capabilities that will empower developers to achieve even more in making it easier to deploy and accelerate AI.
在我们纪念这一重要里程碑之际,我们激动地发布我们的最新版本OpenVINO™2023.0,它具有一系列新的特性和功能,将使开发人员能够更轻松地部署和加速人工智能。
The 2023.0 version is focused on improving the developer journey through minimizing offline conversions, broadening model support and advancing hardware optimizations. The full release notes are available here. Highlights include:
2023.0版本的重点是通过最大限度地减少离线转换、扩大模型支持和推进硬件优化来改善开发者之旅。完整的发布说明可在此获得。亮点包括:
- Minimize code changes for AI developers to adopt, maintain your codes and align better with deep learning frameworks 尽量减少AI开发者在采用和维护代码时的代码修改并更好的与各深度学习框架保持一致
- New TensorFlow integration: Simplify the workflow from training to deployment of TensorFlow models. 全新的TensorFlow体验:简化从训练到部署TensorFlow模型的工作流程
- Now on Conda Forge! Easier access of OpenVINO Runtime for C++ developers who prefer Conda. 现在可用Conda Forge!对于习惯使用Conda的C++开发人员来说,更容易安装OpenVINO 运行时库
- Broader processor support: ARM processor support now includes OpenVINO CPU inferencing, including dynamic shapes, full processor performance and broad sample code/notebook tutorial coverage. 更广泛的处理器支持:当前ARM处理器支持包括OpenVINO CPU推理计算,动态输入,完整的处理器性能和广泛的示例代码/Notebook教程覆盖
- Extended Python support: Added support for Python 3.11 for more potential performance improvements. 扩展Python支持:增加了对Python 3.11的支持,以获得更多潜在的性能改进。
- Optimize and deploy with ease across more models including NLP, and access more AI acceleration with new hardware feature capabilities 在包括NLP在内的更多模型上轻松实现优化和部署,并通过新的硬件特性能力获得更多的AI加速
- Broader model support: Support for generative AI models, text processing models, transformer models, etc. 更广泛的模型支持:支持生成式AI模型、文本处理模型、Transformer模型等。
- Dynamic shapes support on GPU: No need to reshape models to static shapes when leveraging GPU, providing more flexibility in coding, especially for NLP models. GPU上支持动态输入:当使用GPU时,不需要将模型输入改为静态输入,这在编写代码时提供了更多的灵活性,特别是对于NLP模型。
- NNCF is the quantization tool of choice: Combine post-training quantization (POT) into Neural Network Compression Framework (NNCF), with which it is easier to add tremendous performance improvements through model compression. NNCF是首选的量化工具:将训练后量化(POT)集成到神经网络压缩框架(NNCF)中,有了它,通过模型压缩,更容易获得巨大的性能提升
- See a performance boost straight away with automatic device discovery, load balancing and dynamic inference parallelism across CPU, GPU and more 通过自动设备发现,负载平衡和跨CPU, GPU等的动态推理并行,可以直接看到性能的提升
- Thread scheduling in CPU plugin: Optimize for performance or power saving by running inference on E-cores, P-cores, or both for Intel® 12th Gen CORE CPU and up. CPU插件中的线程调度:通过在英特尔®第12代酷睿及以上版本的CPU的能效核、性能核或能效核+性能核上运行推理来优化性能或能效。
- Default inference precision: Default to different formats to provide optimal performance on CPU and GPU. 默认推理精度:默认为不同的格式,以在CPU和GPU上提供最佳性能。
- Extension of Model caching: Reduce the first inference latency for both GPU and CPU. 模型缓存扩展:减少GPU和CPU的首次推理延迟
Now, let’s dive into some of the new features introduced above. 现在,让我们深入研究一下上面介绍的一些新功能。
Exploring New Features in OpenVINO™ 2023.0 探索OpenVINO™2023.0中的新功能
New TensorFlow integration 全新的TensorFlow体验
Right now TensorFlow developers can move from training to deployment more easily. There is no need to convert TensorFlow or TensorFlow Lite format model files to OpenVINO IR format offline- It happens automatically at runtime. Now, you can you can start experimenting with Model Optimizer to enjoy improved conversion time for limited scope of models or load a standard TensorFlow or TensorFlow model directly in OpenVINO Runtime or OpenVINO Model Server
现在,TensorFlow开发人员可以更容易地从模型训练转移到模型部署。无需离线将TensorFlow或TensorFlow Lite格式的模型文件转换为OpenVINO IR格式-这会在运行时自动发生。现在,您可以开始试验Model Optimizer,以改善有限范围模型的转换时间,或者直接在OpenVINO Runtime或OpenVINO Model Server中加载标准TensorFlow或TensorFlow Lite模型
The following diagram shows a simple example: 下图显示了一个简单的示例:

Figure 1. General workflow for deploying TensorFlow/TensorFlow Lite model
图1. 部署 TensorFlow/TensorFlow Lite 模型的通用工作流程
Broader model support 更广泛的模型支持
AI developers can find extended model support for generative AI models, such as CLIP, BLIP, Stable Diffusion 2.0, Stable diffusion with ControlNet, text processing models, transformer models, such as S-BERT, GPT-J, etc., Detectron2, Paddle Slim, Segment Anything Model (SAM), YOLOv8, RNN-T, and more.
AI开发者可以找到更多的对生成式AI模型支持,例如,CLIP, BLIP, Stable Diffusion 2.0,带ControlNet的Stable Diffusion等;对文本处理模型的支持,对Transformer模型的支持,例如,S-BERT, GPT-J等,对Detectron2, Paddle Slim, Segment Anything Model(SAM), YOLOv8, RNN-T等模型的支持。

Figure 2. Infinite zoom video effect generated by stable-diffusion-2-inpainting model.
图2. 由stable-diffusion-2-inpainting模型生成的无限变焦视频效果

Figure 3. ControlNet workflow using OpenPose to extract key points from the input image, then introduced into Stable Diffusion as additional conditioning along with the text prompt. Images are generated based on these two conditions.
图3. 基于两个条件生成的图像,用OpenPose从输入图像提取关键点的ControlNet工作流程,然后作为额外条件与文本提示词一起输入到Stable Diffusion模型
SAM (1)
Figure 4. Segment anything in the given picture with Segment Anything Model (SAM).
图4. 用Segment Anything Model (SAM)模型分割给定图片的一切
Default inference precision 默认推理精度
The latest update includes a significant improvement in the performance of the inference on various devices, which now operate in high-performance mode by default. This means that for GPU devices, FP16 inference is used, while CPU devices use BF16 inference (if available). Previously, users had to convert IR to FP16 themselves to enable GPU execution in FP16 mode. Now, all devices can select default inference precision automatically, and this selection is disconnected from IR precision. In the rare event that high-performance mode impacts accuracy, users can adjust the inference precision hint.
最新的更新包括在各种设备上的推理性能的显著提高,这些设备现在默认以高性能模式运行。这意味着对于GPU设备,使用FP16推理,而CPU设备使用BF16推理(如果可用)。以前,用户必须自己将IR转换为FP16,才能使GPU在FP16模式下执行。现在,所有设备都可以自动选择默认推理精度,并且此选择与IR精度没有关系。在极少数情况下,使用默认模式可能会影响推理准确性,此时用户也可以通过接口手动调整推理精度。
Additionally, developers can control the IR precision separately. By default, we recommend setting it to FP16 to reduce the model size by 2x for floating-point models. It is important to note that IR precision does not affect how devices execute the model but serves to compress the model by reducing the weight precision.
此外,开发者可以单独控制IR精度。默认情况下,我们建议将其设置为FP16,以便为浮点模型减少2倍的模型大小。值得注意的是,IR精度并不影响设备执行模型的方式,而是通过降低权重精度来压缩模型。

Figure 5. Auto conversion of IR model to default inference precision
图5. 自动转换IR模型为默认推理精度
NNCF as the quantization tool of choice NNCF作为首选的量化工具
NNCF provides a suite of advanced algorithms for Neural Networks inference optimization in OpenVINO™ with minimal accuracy drop. It is designed to work with models from PyTorch, TensorFlow, ONNX and OpenVINO™.
NNCF为OpenVINO™中的神经网络推理优化提供了一套先进的算法,并具有最小的精度损失。它支持对PyTorch、TensorFlow、ONNX和OpenVINO™模型对象进行量化 。
Previously, OpenVINO had separate tools for post training optimization (POT) and quantization aware training. We’ve combined both methods into NNCF, of which the compression algorithms provided are listed below, in Figure 5. This helps to reduce the model size, memory footprint and latency, as well as improve the computational efficiency.
在这之前,OpenVINO有单独的工具用于训练后优化(POT)和量化感知训练。我们将这两种方法合并到NNCF中,其中提供的压缩算法如下所示,见图5。这有助于减少模型大小、内存占用和延迟,并提高计算效率。
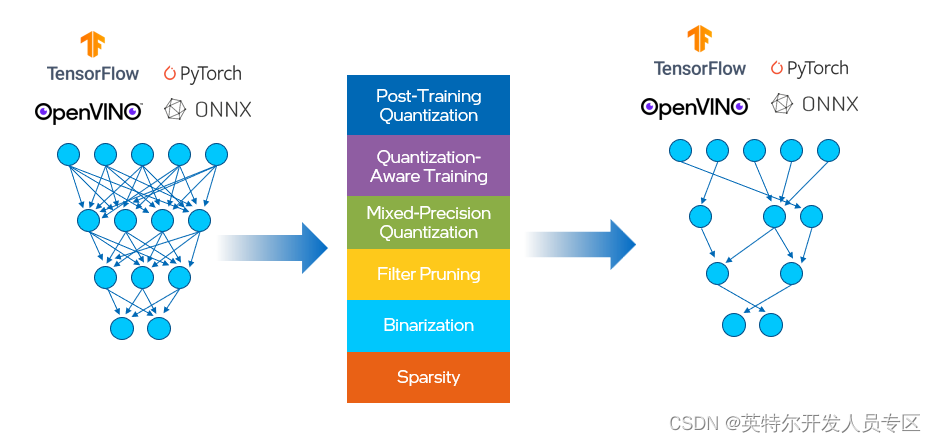
Figure 6. Compression algorithms provided in NNCF.
图6. NNCF提供的压缩算算法
The post-training quantization algorithm takes samples from the representative dataset, inputs them into the network, and calibrates the network based on the resulting weights and activation values. Once calibration is complete, values in the network are converted to 8-bit integer format. The basic POT quantization flow in NNCF is the simplest way to apply 8-bit quantization to the model:
训练后量化算法从代表性数据集中获取样本,并将其输入到网络中,然后根据所得的权重和激活值对网络进行校准。一旦校准完成,网络中的值就被转换为8位整型格式。NNCF的基本训练后量化流程是将8位量化应用于模型的最简单方法:
- Set up an environment and install dependencies. 设置环境并安装依赖项
pip install nncf- Prepare a calibration dataset 准备校准数据集
import nncf
calibration_loader = torch.utils.data.DataLoader(...)
def transform_fn(data_item):
images, _ = data_item
return images
calibration_dataset = nncf.Dataset(calibration_loader, transform_fn)
Run to get a quantized model 运行以获取量化模型
model = ... #OpenVINO/ONNX/PyTorch/TF object
quantized_model = nncf.quantize(model, calibration_dataset)Tutorials on how to use NNCF for model quantization and compression can be found here, of which we have validated applying post-training quantization to YOLOv5 model with little accuracy drop (Figure 8).
关于如何使用NNCF进行模型量化和压缩的教程可以在这里找到,其中我们验证了将训练后量化应用于YOLOv5模型,精度几乎没有下降(图8)
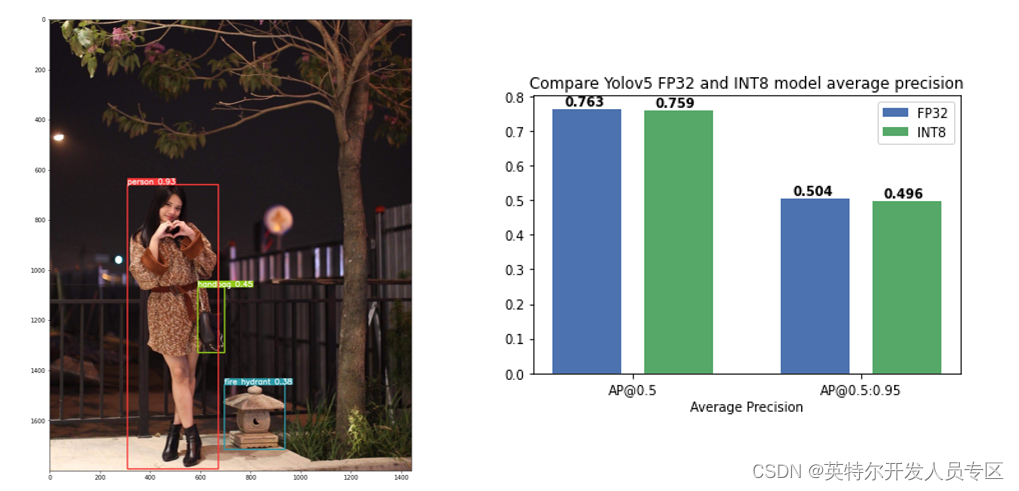
Figure 8. Apply post-training quantization in NNCF to YOLOv5 model with small accuracy impacts.
图8. 将训练后量化应用于YOLOv5模型,精度几乎没有下降
Thread scheduling in CPU plug-in CPU插件中的线程调度
Improve multi-thread scheduling for Intel® platform. 提升Intel®平台的多线程调度。
With the new ov::hint::scheduling_core_type property, performance or power saving could be configured by choosing to run inference on {ov::hint::SchedulingCoreType::ANY_CORE, ov::hint::SchedulingCoreType::PCORE_ONLY, ov::hint::SchedulingCoreType::ECORE_ONLY}, for Intel® 12th Gen CORE CPU and up, HYBRID platform.
有了新的ov::hint::scheduling_core_type属性,可以通过选择在{ov::hint::SchedulingCoreType::ANY_CORE, ov::hint::SchedulingCoreType::PCORE_ONLY, ov::hint::SchedulingCoreType::ECORE_ONLY}上运行推理来配置性能优先或能效优先,用于英特尔®12代及以上酷睿CPU,HYBRID平台。
By setting the ov::hint::enable_hyper_threading property to “True”, both physical and logical cores could be enabled on P-cores for Intel® platform.
通过将ov::hint::enable_hyper_threading属性设置为 "True",物理核和逻辑核都可以在英特尔®平台的性能核上启用,因此通过这种配置带来性能提升。
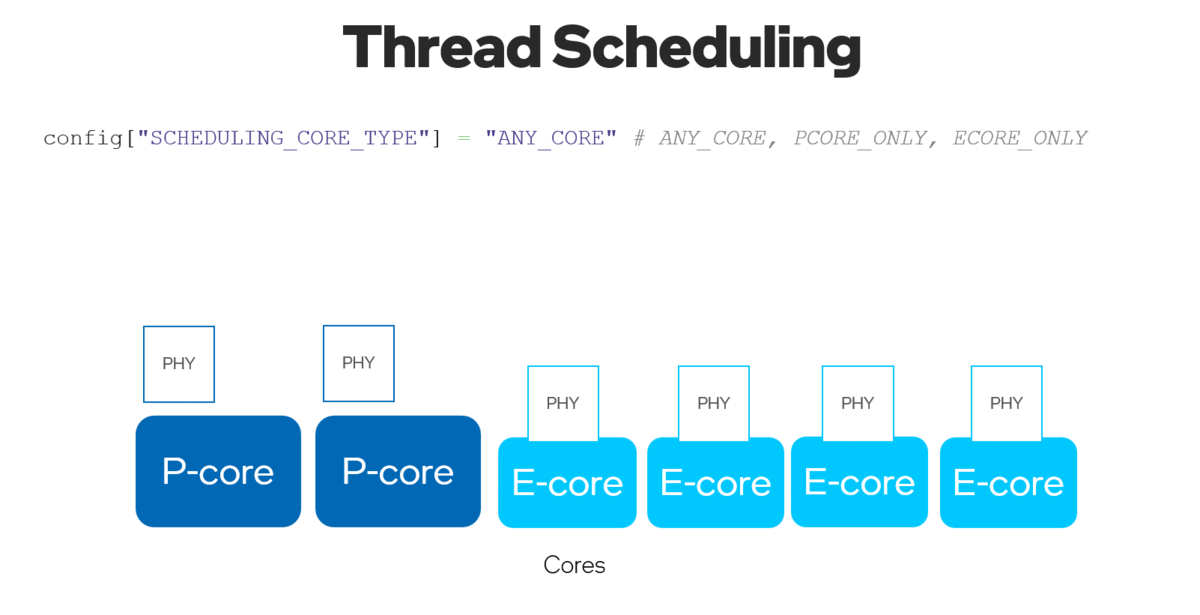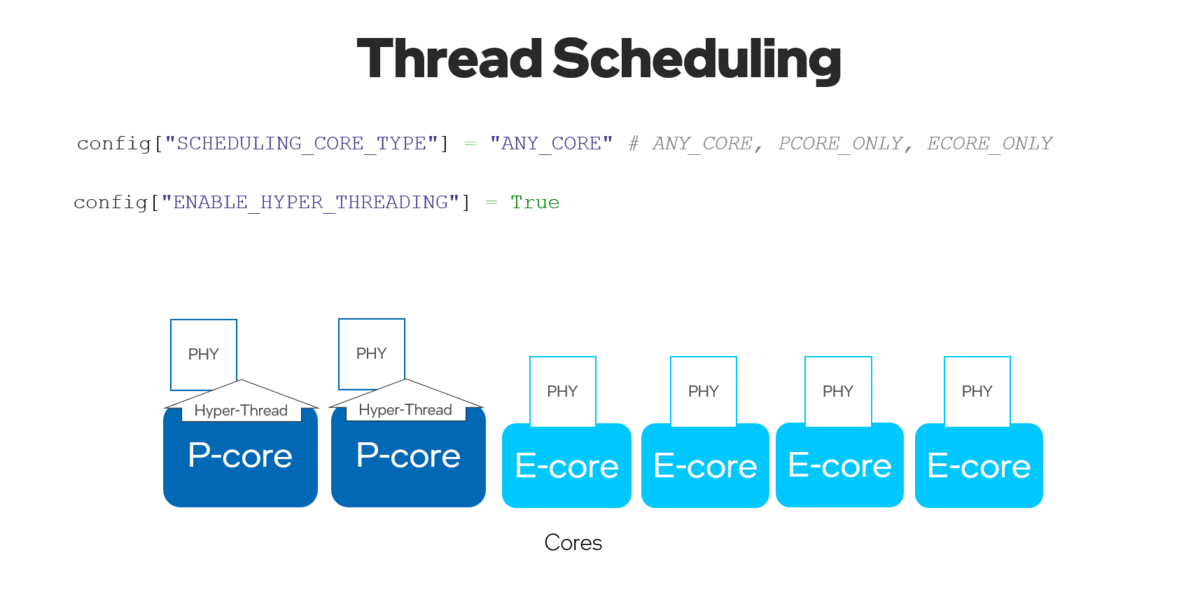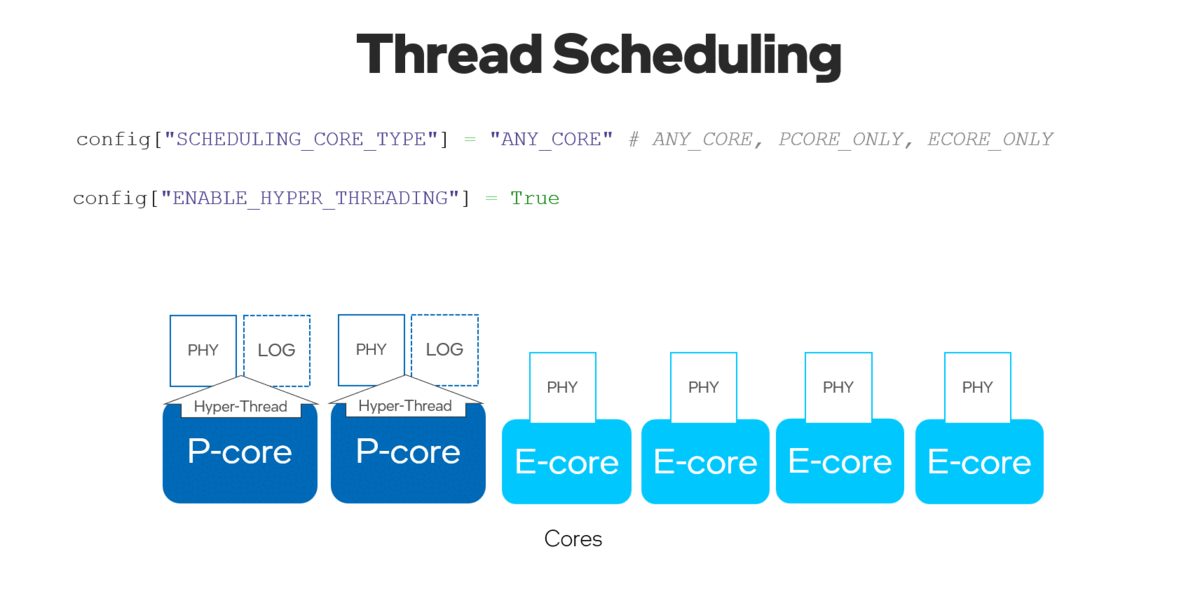
Figure 9. Enable “SCHEDULING_CORE_TYPE” and “ENABLE_HYPER_THREADING” with improved multi-threading in CPU plug-in.
图9.启用 "SCHEDULING_CORE_TYPE "和 "ENABLE_HYPER_THREADING",在CPU插件中提升了多线程。
Another new property is ov::hint::enable_cpu_pinning. In default, ov::hint::enable_cpu_pinning is set to “True”, which means multiple threads for running inference requests of multiple deep learning models will be scheduled by OpenVINO Runtime((TBB). In this mode, inference of one deep learning model with multiple threads will be treated as an overall graph, of which each thread will be bound to a CPU processor without cache missing and additional overhead. However, in the case of simultaneously running inference for two neural networks, multiple threads of different inference requests could be scheduled on the same CPU processors, leading to computation competition on the same processor resources (as shown in Figure 10).
另一个新属性是ov::hint::enable_cpu_pinning。默认情况下,ov::hint::enable_cpu_pinning被设置为 “True”, 这意味着用于运行多个深度学习模型的推理请求的多个线程将由 OpenVINO 运行时(TBB)调度。在这种模式下,具有多个线程的一个深度学习模型的推理将被视为一个整体图,其中每个线程将绑定到 CPU 处理器,而不会引起缓存丢失和额外的开销。但是,在同时运行两个神经网络的推理的情况下,可能在相同的 CPU 处理器上调度不同深度学习模型推理请求的多个线程,从而导致对相同处理器资源上的竞争(如图 10 所示)。
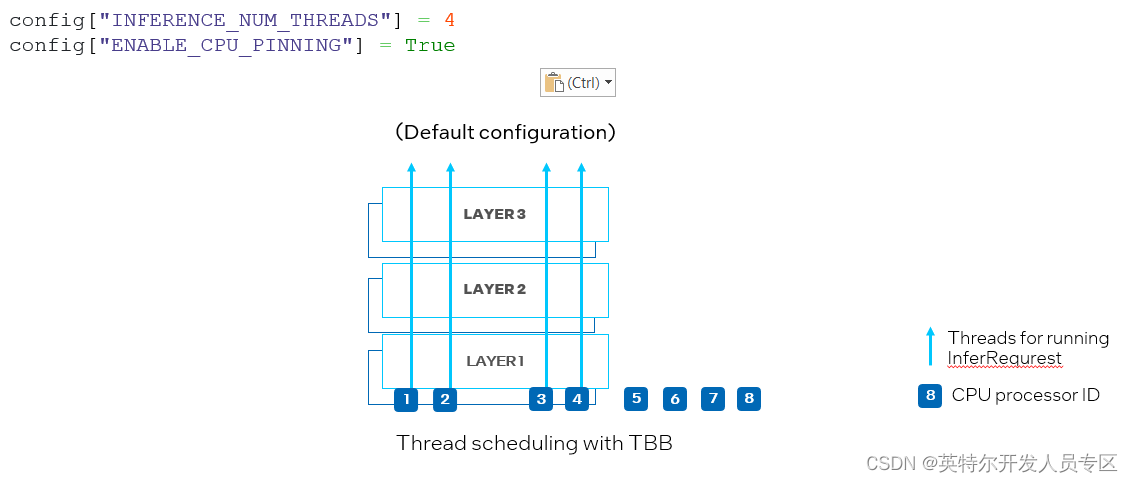
Figure 10. Set “ENABLE_CPU_PINNING” to “True” in CPU plug-in, with TBB scheduling for multiple threads.
图 10. 在CPU插件中设置 "ENABLE_CPU_PINNING "为 "True",为多线程启用TBB调度
To avoid CPU processor resource competition, we can disable the processor binding properties by setting ov::hint::enable_cpu_pinning to “False” and let the operation system schedule the processor resource for each thread of the network. In this mode, the inference on different layers of the same deep learning model could be switched across different processors, resulting in cache missing and additional overhead (as shown in Figure 11).
为了避免 CPU 处理器资源竞争,我们可以通过将 ov::hint::enable_cpu_pinning 设置为 “False”来禁用处理器绑定属性,并让操作系统为神经网络的每个线程调度处理器资源。在这种模式下,同一深度学习模型不同层上的推理可能会在不同的处理器之间切换,从而导致缓存丢失和额外的开销(如图 11 所示),此时开发者可以根据实际的测试结果,选择最合适的方案进行部署。
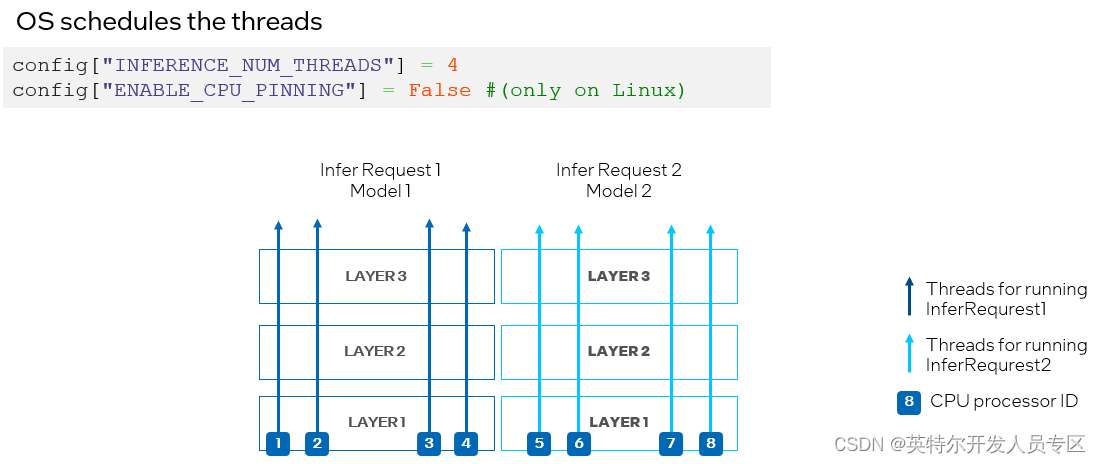 &
& 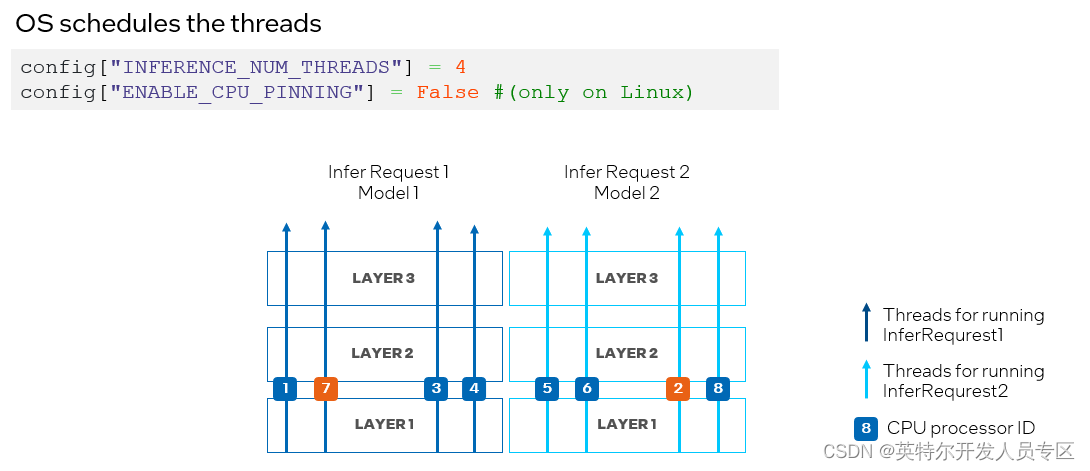
Figure 11. Set “ENABLE_CPU_PINNING” to “False” in CPU plug-in, with OS scheduling for multiple threads.
图11. 在CPU插件中设置 "ENABLE_CPU_PINNING "为 "False",由操作系统调度多线程
Upgrade to OpenVINO™ 2023.0 升级到OpenVINO™ 2023.0
OpenVINO™ gets the most out of your AI application from start to finish. With your continued support, we can produce valuable upgrades for developers everywhere. With its smart and comprehensive capabilities, OpenVINO is like having your own performance engineer by your side.
OpenVINO™从头到尾都能让您的AI应用发挥最大的作用。有了您的持续支持,我们可以为各地的开发人员提供有价值的升级。凭借其智能和全面的功能,OpenVINO™就像在您身边有自己的性能工程师。
You can upgrade to OpenVINO™ 2023.0 using the following command:
您可以使用以下命令升级到OpenVINO™2023.0:
- pip install --upgrade openvino-dev
But make sure to check all your dependencies because the upgrade may update other packages beyond OpenVINO. If you wish to install the C/C++ API, pull a pre-built Docker image or download from another repository, visit the download page to find a package that suits your needs. If you are looking for model serving instructions, check out the new documentation.
但是请确保检查所有的依赖项,因为升级可能会更新OpenVINO之外的其他包。如果您希望安装C/ C++ API,拉取预构建的Docker镜像或从其他存储库下载,请访问下载页面以找到适合您的需求的包。如果您正在寻找模型服务指令,请查看新的文档。
Additional Resources: 额外的资源:
OpenVINO™ Release Notes OpenVINO™发行说明
Provide Feedback & Report Issues
Notices & Disclaimers
Intel technologies may require enabled hardware, software or service activation.
No product or component can be absolutely secure.
Your costs and results may vary.
© Intel Corporation. Intel, the Intel logo, and other Intel marks are trademarks of Intel Corporation or its subsidiaries. Other names and brands may be claimed as the property of others.
Thanks to people participated in this blog: 感谢参与本博客的作者:
Zhuo Wu, Ethan Yang, Adrian Boguszewski, Anisha Udayakumar, Yiwei Lee, Stephanie Maluso, Raymond Lo, Ryan Loney, Ansley Dunn, Wanglei Shen