论文链接:https://arxiv.org/abs/2002.03662
import torch
import torch.nn.functional as F
class DDL(torch.nn.Module):
""" Implented of
"""
def __init__(self, pos_kl_weight=0.1, neg_kl_weight=0.02,
order_loss_weight=0.5, positive_threshold=0.0):
""" Args:
pos_kl_weight: weight for positive kl loss
neg_kl_weight: weight for negative kl loss
order_loss_weight: weight for order loss
positive_threshold: threshold fo positive pair
"""
super(DDL, self).__init__()
self.pos_kl_weight = pos_kl_weight
self.neg_kl_weight = neg_kl_weight
self.order_loss_weight = order_loss_weight
self.positive_threshold = positive_threshold
# register_buffer:在内存中定一个常量,同时,模型保存和加载的时候可以写入和读出。
# 该方法的作用是定义一组参数,该组参数的特别之处在于:模型训练时不会更新(即调用 optimizer.step() 后该组参数不会变化,只可人为地改变它们的值)
# 保存模型时,该组参数又作为模型参数不可或缺的一部分被保存。
self.register_buffer('t', torch.arange(0, 1.0, 0.001).view(-1, 1).t()) # 分配直方图间隔
def forward(self, neg_features, pos_pair_features_first, pos_pair_features_second):
# 教师(简单样本)和学生(难分样本)均有b个正样本对(2b个样本)、b个不同身份的样本
# sample b positive pairs (i.e., 2b samples) and b samples with different identities
assert len(pos_pair_features_first) == len(pos_pair_features_second)
assert len(neg_features) == len(pos_pair_features_first)
# 通过深度网络F将数据嵌入高维特征空间后,可以得到负对s-和正对s+的相似度
neg_distributions, neg_distances = self._neg_distribution(neg_features)
pos_distirbutions, pos_distances = self._pos_distribution(pos_pair_features_first, pos_pair_features_second)
pos_kl_losses = []
neg_kl_losses = []
order_losses = []
# 对难分样本的相似度分布(即学生分布)进行约束,使其近似于易样本的相似度分布(即教师分布)
# 教师分布和学生分布均包含正负两对相似度分布
for i in range(1, len(pos_distirbutions)): # first branch as the anchor
pos_kl = self._kl(pos_distirbutions[0], pos_distirbutions[i])
pos_kl_losses.append(pos_kl)
for i in range(1, len(neg_distributions)): # first branch as the anchor
neg_kl = self._kl(neg_distributions[0], neg_distributions[i])
neg_kl_losses.append(neg_kl)
for neg in neg_distances:
for pos in pos_distances:
order_loss = torch.mean(neg) - torch.mean(pos)
order_losses.append(order_loss)
ddl_loss = sum(pos_kl_losses) * self.pos_kl_weight + sum(neg_kl_losses) * \
self.neg_kl_weight + sum(order_losses) * self.order_loss_weight
return ddl_loss, neg_distances, pos_distances
def _kl(self, anchor_distribution, distribution):
# distribution拟合anchor_distribution
loss = F.kl_div(torch.log(distribution + 1e-9), anchor_distribution + 1e-9, reduction="batchmean")
return loss
# 直方图中每个节点的概率
def _histogram(self, dists):
dists = dists.view(-1, 1)
simi_p = torch.mm(dists, torch.ones_like(self.t)) - torch.mm(torch.ones_like(dists), self.t)
simi_p = torch.sum(torch.exp(-0.5 * torch.pow((simi_p / 0.1), 2)), 0, keepdim=True)
p_sum = torch.sum(simi_p, 1)
simi_p_normed = simi_p / p_sum
return simi_p_normed
def _pos_distribution(self, first_features, second_features, positive_threshold=0.):
pos_distirbutions = []
pos_distances = []
for first_feature, second_feature in zip(first_features, second_features):
first_feature = F.normalize(first_feature)
second_feature = F.normalize(second_feature)
pos_distance = torch.mul(first_feature, second_feature).sum(dim=1)
# 相似度小于0的正对通常是离群值,主要目标不是专门处理噪声,因此将其作为实际设置删除
pos_distance = torch.masked_select(pos_distance, pos_distance > positive_threshold)
pos_p = self._histogram(pos_distance)
pos_distirbutions.append(pos_p)
pos_distances.append(pos_distance)
return pos_distirbutions, pos_distances
# 通过深度网络F将数据嵌入高维特征空间后,得到负s-相似度
def _neg_distribution(self, neg_features):
neg_distributions = []
neg_distances = []
for neg_feature in neg_features:
neg_feature = F.normalize(neg_feature)
neg_distance = torch.mm(neg_feature, neg_feature.transpose(0, 1))
# ??没懂这个意义
neg_distance = torch.triu(neg_distance, diagonal=1) # diagonal控制上三角的对角线开始位置
neg_distance, _ = torch.max(neg_distance, dim=1) # 每行最大值 选出相似度最大的
neg_p = self._histogram(neg_distance)
neg_distributions.append(neg_p)
neg_distances.append(neg_distance)
return neg_distributions, neg_distances
针对:在无约束图像上进行大规模人脸识别的一个主要挑战是如何处理姿态、分辨率、种族和光照的变化。
DDL:缩小简单样本和困难样本的性能差距,适用于各种面部变化。
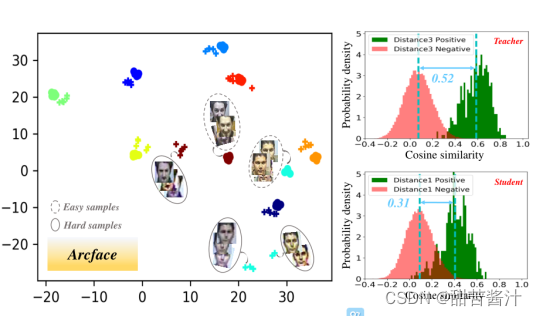
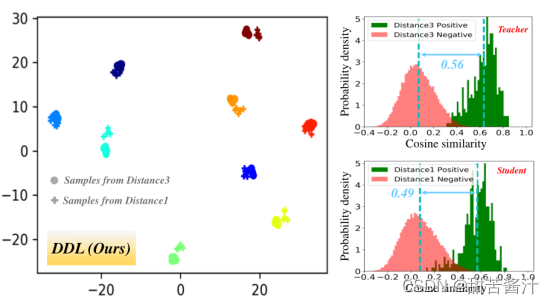
如上图所示,Arcface通过在特征空间中紧密分组,很好地解决了小变化的图像,这些就是简单样本。相比之下,具有较大变化的图像通常远离特征空间中的简单图像,处理起来也困难得多。这些为难分样品。
流程:
Train dataset分E/H,二者均构建正负对,嵌入高维特征空间,构建正负对相似性,估计相似度分布,最后利用DDL训练分类器。
正负对的形成:
正对:预先离线构建,每对由同一个人的两个样本组成
负对:通过硬负挖掘的方法从不同人的两个样本中在线构建,选择相似性最大的负对
因此:
LDDL=LKL+Lorder
LKL:KL散度来约束学生分布和教师分布之间的相似性,缩小难分样本与简单样本的性能差距。
Lorder:但是教师分布可能会选择接近学生分布,导致正负对分布之间有更多的混淆区域以至于降低性能,为了解决这个问题,增加了阶损失,它最小化了负和正对之间的相似分布期望距离,控制重叠。
L= LDDL+Larcface
其中Larcface可以被任何一种流行的人脸识别损失替代。(作用:保持简单样本的性能)
其中:
量化各种soTA方法之间的差异,论文引入了两种统计数据来评估,即期望边际和直方图相交,这两个分布来自正和负对。通常情况下,更小的直方图相交和更大的期望裕度表明更好的验证/识别性能,因为它意味着更多的鉴别嵌入学习。DDL实现了最接近教师分布的统计,从而获得了最好的性能。
知识蒸馏:可以将一个网络的知识转移到另一个网络,两个网络可以是同构或者异构。做法是先训练一个teacher网络,然后使用这个teacher网络的输出和数据的真实标签去训练student网络。知识蒸馏,可以用来将网络从大网络转化成一个小网络,并保留接近于大网络的性能;也可以将多个网络的学到的知识转移到一个网络中,使得单个网络的性能接近emsemble的结果。
区分easy和hard样本:
基本上可以根据图像中是否含有较大的面部变化,例如低分辨率和较大的姿态变化,可能会阻碍身份信息的变化。
(1)采用Arcface等最先进的分类器,将训练集分为,简单样本和难分样本,然后分别构建两个相似度分布:来自简单样本的教师分布和来自难分样本的学生分布;
(2)提出了一种新的分布蒸馏损失来约束学生分布,使其接近教师分布,从而减少学生分布中正对和负对之间的重叠。在通用的大规模面部基准和不同种族、分辨率和姿势的基准上进行了广泛的实验。论文定量结果表明,方法优于强基线,如Arcface和Cosface。
缺点:
1、容易样本和难样本需要手动确认,需要大量手工标注的工作;
2、难样本是根据类型而言的,如低分辨率、难识别的姿态,对于不同的难样本类型,需要构造不同的难样本分布。如果有多种难样本,就要构造多种分布,这也是非常复杂的过程。