目录
SQL 执行流程图

1、查询缓存
前提说明:查询缓存在 MySQL8.0 就已经被废除了,因为其缓存的效率不高
原因:
查询缓存是提前把查询结果缓存起来,这样下次不需要执行就可以直接拿到结果。需要说明的是,在 MySQL 中的查询缓存,不是缓存查询计划,而是查询对应的结果。这就意味着查询匹配的 鲁棒性大大降低 ,只有相同的查询操作才会命中查询缓存 。两个查询请求在任何字符上的不同(例如:空格、注释、大小写),都会导致缓存不会命中。因此 MySQL的查询缓存命中率不高 。
Robust(鲁棒性):指控制系统在一定参数摄动下,维持其它某些性能的特性
此外,既然是缓存,那就有它 “缓存失效” 的时候 。MySQL的缓存系统会监测涉及到的每张表,只要该表的 结构或者数据被修改,如对该表使用了 INSERT 、 UPDATE 、 DELETE 、 TRUNCATE TABLE 、 ALTER TABLE 、 DROP TABLE 或 DROP DATABASE 语句,那之前的缓存都将无效没有意义,因为之后又对表进行了更改操作,导致前后不一致!对于 更新压力大的数据库 来说,查询缓存的命中率会非常低。所以,只能适用于修改操作比较低的表中,局限性很大。
2、解析器
如图所示:

分析器先做“ 词法分析 ”。你输入的是由多个字符串和空格组成的一条 SQL 语句,MySQL 需要识别出里面的字符串分别是什么,代表什么。
接着,要做“ 语法分析 ”。根据词法分析的结果,语法分析器(比如:Bison)会根据语法规则,判断你输入的这个 SQL 语句是否满足 MySQL 语法 。
若 SQL 语句中语法正确,则会生成像这样的语法树:

3、优化器
定义:在优化器中会确定 SQL 语句的执行路径,比如是根据全表检索 ,还是根据索引检索等。
举例:如下语句是执行两个表的 join 语句
select * from test1 join test2 using(ID)
where test1.name='zhangwei' and test2.name='mysql高级课程';方案1:可以先从表 test1 里面取出 name='zhangwei'的记录的 ID 值,再根据 ID 值关联到表 test2,再判 断 test2 里面 name的值是否等于 'mysql高级课程'。
方案2:可以先从表 test2 里面取出 name='mysql高级课程' 的记录的 ID 值,再根据 ID 值关联到 test1, 再判断 test1 里面 name的值是否等于 zhangwei。
这两种执行方法的逻辑结果是一样的,但是执行的效率会有不同,而优化器的作用就是决定选择使用哪一个方案,以达到最优解。优化器阶段完成后,这个语句的执行方案就确定下来了,然后进入执行器阶段
4、执行器
如图所示(通过上面的优化器,现在已经步入到了执行器):
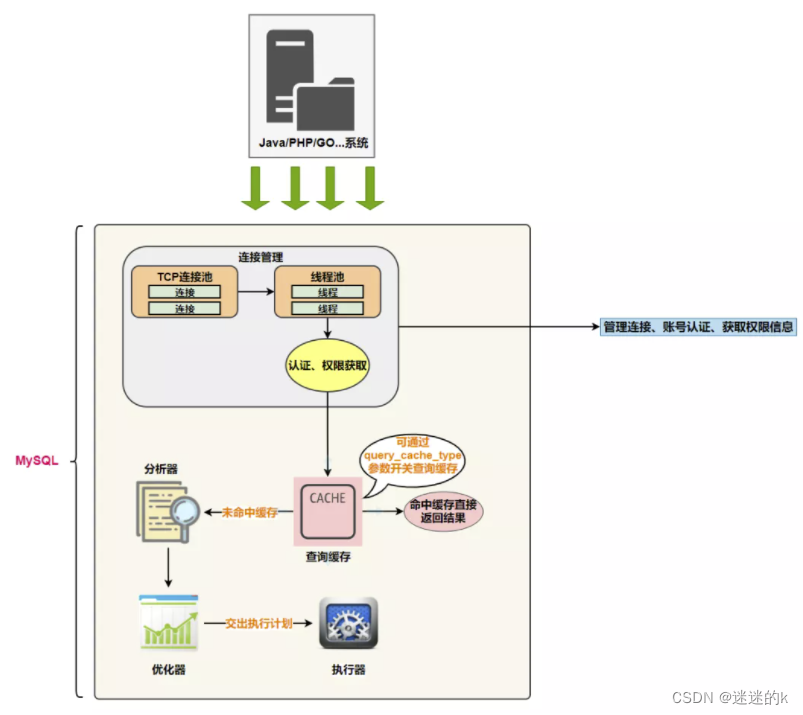
在执行之前需要判断该用户是否具备权限 。如果没有,就会返回权限错误。如果具备权限,就执行 SQL 查询并返回结果。在 MySQL8.0 以下的版本,如果设置了查询缓存,这时会将查询结果进行缓存。
至此,总结:
SQL 语句在 MySQL 中的流程是: SQL语句→查询缓存→解析器→优化器→执行器 。
