目录
re模块
compile(pattern, flags=0)
flag匹配模式
match(pattern, string, flags=0)
search(pattern, string, flags=0)
findall(pattern, string, flags=0)
split(pattern, string, maxsplit=0, flags=0)
sub(pattern, repl, string, count=0, flags=0)
---------------------------------------------------------------------------------------------
re模块
1下载re模块

2导入模块
import re
3 语法
re模块相当于是一个语言模块,拥有自己的语言规则,是爬虫的数据爬取进行数据的提取的三大模块(re xpath bs4 ) 之一,下面介绍re的语法的一些标识符:
(1)匹配单个字符

(2)匹配多个字符

补充一点:使用多字符就会使正则表达式变成贪婪,多字符标记加上个?就会使正则表达式变成非贪婪,下面会有介绍
(3)匹配开头结尾

(4)匹配分组

re.match()
match(pattern, string, flags=0)===>match("正则表达式", 拿来匹配的字符串, 匹配方式)
(1)简单介绍
match(pattern, string, flags=0)===>match("正则表达式", 拿来匹配的字符串, 匹配方式)
这样解释可能一点不友好,下面开始使用match()
(1)使用单字符" . "
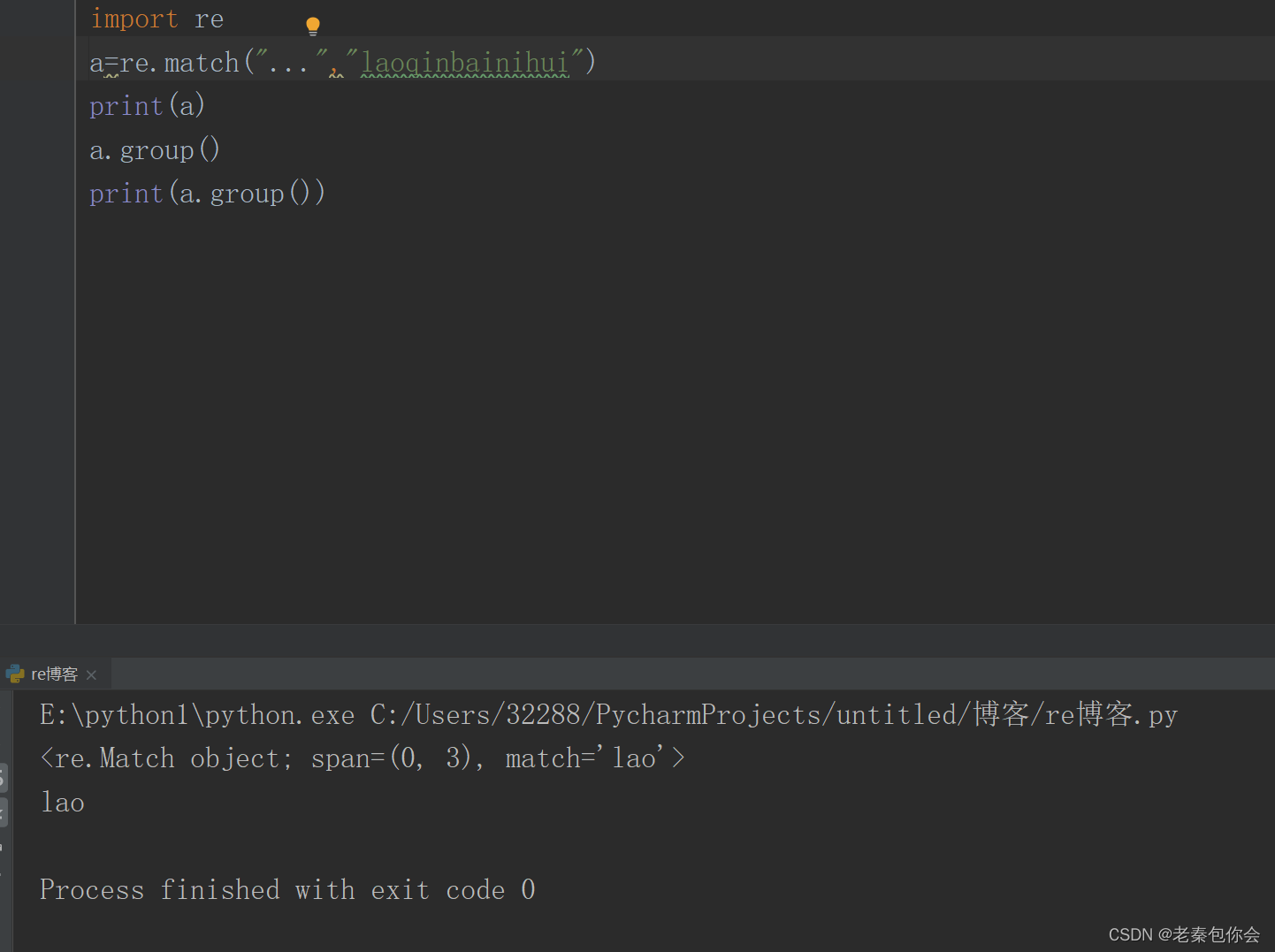
现在由我来解释
match()是re里的函数,match利用正则表达式来跟字符串匹配,从头开始匹配,
可以理解为正则表达式有啥,字符串的开头就必须有,

没有就会报错,如下图:

group()是报错的主犯,当match匹配不到时,会返回None,正因group()拿不到匹配到的字符就会报错
group()返回匹配到的字符
flag匹配模式

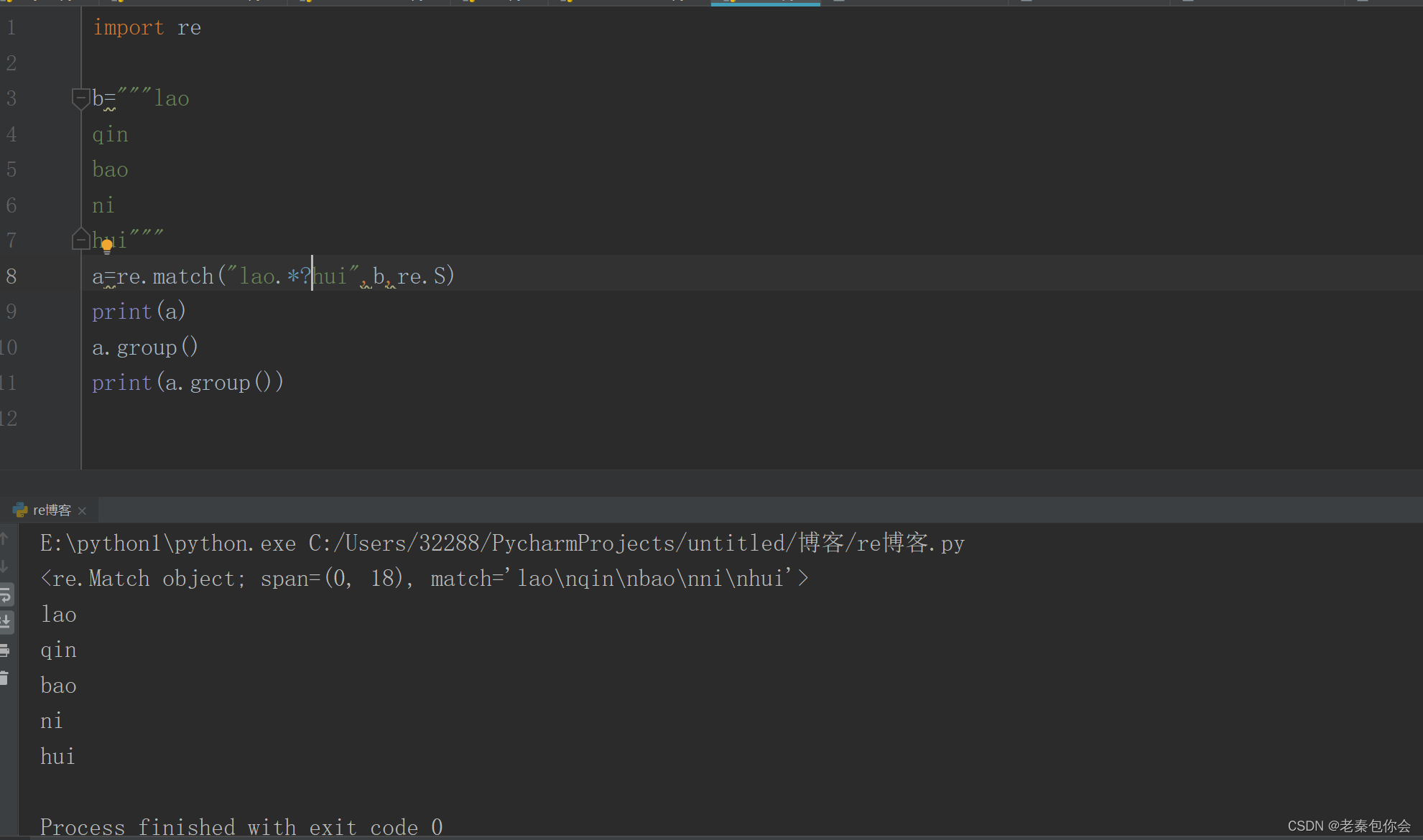
下面我们简单介绍re.S和re.I
re.I 不区分大小写

re.S 可以换行匹配
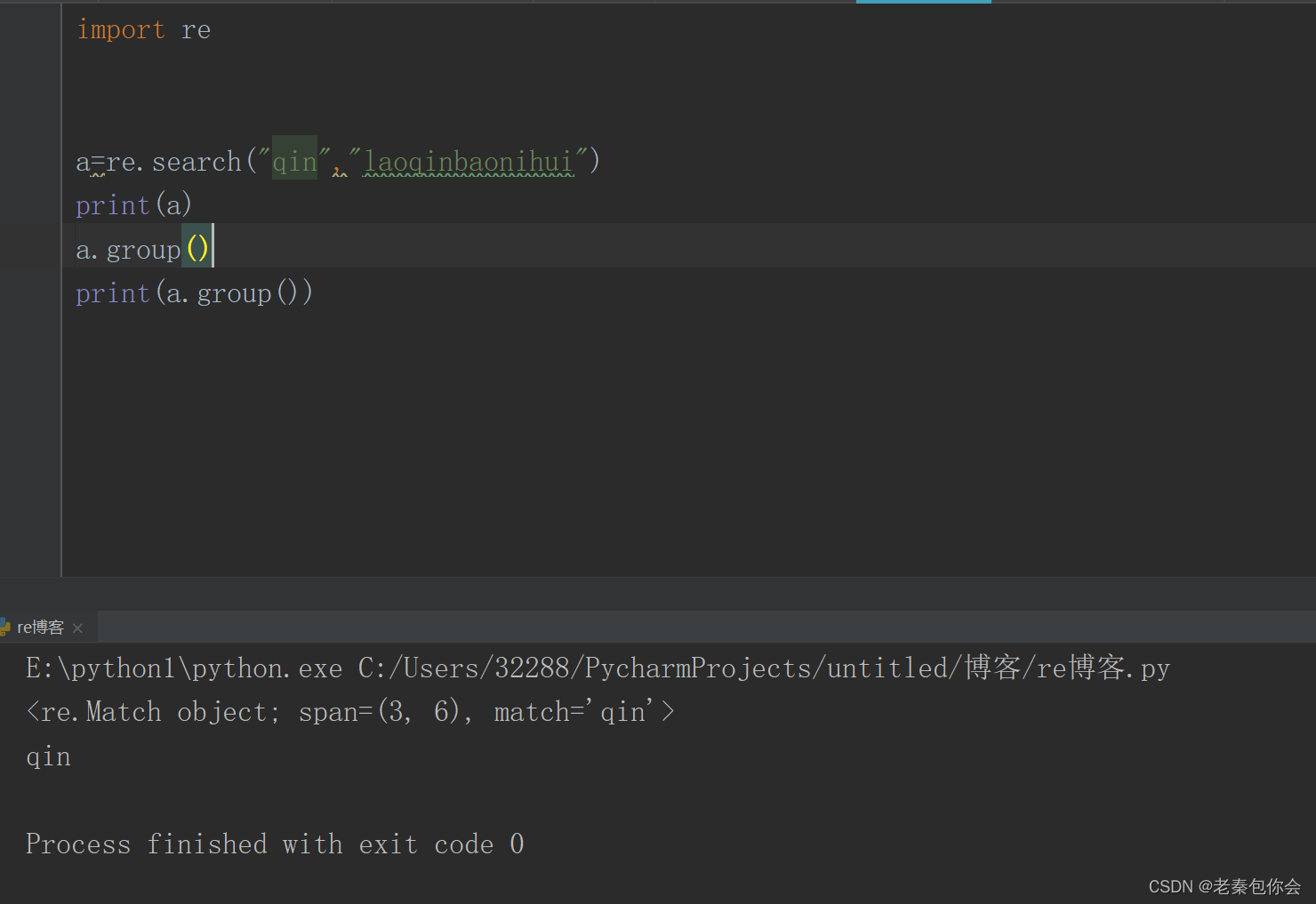
search(pattern, string, flags=0)===>search("正则表达式", 拿来匹配的字符串, 匹配方式)
search()的匹配原理是在字符串中找到符合正则表达式的字符就立刻返回,(就是找到第一个就会返回)
findall(pattern, string, flags=0)===>findall("正则表达式", 拿来匹配的字符串, 匹配方式) (直接返回所有匹配到的字符)

findall()和前面的match() search()不同,findall是直接把所有匹配到的字符以列表返回
split(pattern, string, maxsplit=0, flags=0)===>split("正则表达式", 拿来匹配的字符串,最大切割数, 匹配方式)
split就是把匹配到的字符切割(可以理解为去掉字符) ,返回切割后的字符串,和前面不同,前面是返回匹配到的,

sub(pattern, repl, string, count=0, flags=0)===>findall("正则表达式",替换的字符, 拿来匹配的字符串, 匹配方式)
sub()和findall()的匹配类似都是匹配到全部符合的,唯一不同的就是会把匹配到的字符进行替换

总结
以上的方法都是为了更好的匹配字符串,灵活性高,操作性强