作者 | gongyouliu
编辑 | gongyouliu
我们在上一章讲解了常用的3种基础排序算法,本章我们接着讲解2种经典的深度学习排序算法,即Google的wide & deep和YouTube的深度学习排序。这2个算法是国外大厂在真实业务场景中得到验证的、有真实业务价值的方法,并且也被中国广大互联网公司应用于自己的业务中,是得到业界一致认可的算法。
虽然这2个算法是在大约2016年左右提出的,但它们的应用到现在也不过时。这2个算法不管是在创新性、模型结构、特征工程技巧、工程实现细节打磨等各个方面都值得大家好好学习。很好地理解这2个算法的核心思想对我们学习其他更现代的排序算法也是非常有帮助的。
13.1 wide & deep排序算法
参考文献1是Google在2016年提出的一个深度学习模型,应用于Google Play应用商店上的APP推荐,该模型经过在线AB测试获得了比较好的效果。这篇文章也是最早将深度学习应用于工业界的案例之一,是一篇非常有价值的文章,对整个深度学习推荐系统有比较大的积极促进作用。基于该模型衍生出了很多其他模型(如参考文献2中的deepFM),并且很多都在工业界取得了很大的成功,在这一部分我们对该模型的思想进行简单介绍。
12.3.1 模型特性分析
wide & deep模型分为wide和deep两部分。wide部分是一个线性模型,学习特征间的简单交互,能够“记忆”用户的行为,为用户推荐感兴趣的内容,但是需要大量耗时费力的人工特征工作。deep部分是一个前馈深度神经网络模型,通过稀疏特征的低维嵌入,可以学习到训练样本中不可见的特征之间的复杂交叉组合,因此可以提升模型的泛化能力,并且也可以有效避免复杂的人工特征工程。通过将这两部分结合,联合训练,最终获得记忆和泛化两个优点。
所谓记忆特性是指模型可以记住浅层的预测因子,即模型从历史数据中,利用用户行为和物品特征的出现频次来预测用户的行为,有点类似关联规则的思想。例如,假如模型学到了“当用户安装了淘宝 APP并且被曝光过盒马APP,那么用户有15%的概率会下载盒马APP”这个规则,这种规则就会被具备记忆特性的模型记住,那么当一个应用商店的新用户安装过淘宝APP并且被曝光过盒马APP,那么模型就会在应用商店中给他推荐盒马APP。记忆特征是一类可解释性比较强的特性,这也是logistics回归这类模型的特性,本节我们讲解的模型的wide部分其实就是logistics回归模型。
所谓泛化特性是指模型可以学习深层的预测因子,即模型从历史数据中挖掘特征之间弱依赖关系、交叉关系及低频共现关系的能力。泛化特性不具备很好的解释性,超出了人的直觉可以感知的范畴,这一般也是复杂模型的特性,本节我们讲解的模型的deep部就是MLP(多层感知机)深度学习模型。
12.3.2 模型架构
wide & deep模型的网络结构图如下面图1中间(左边是对应的wide部分,右边是deep部分)。
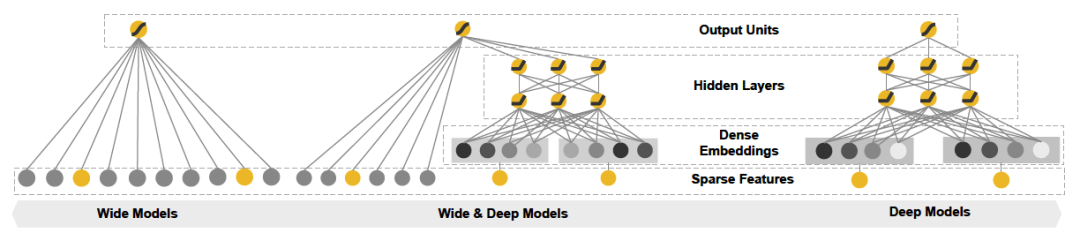
图1:wide & deep 模型网络结构
wide部分是一般线性模型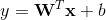 ,y是最终的预测值,这里
,y是最终的预测值,这里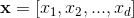 是d个特征,
是d个特征,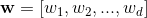 是模型参数,b是bias。这里的特征
是模型参数,b是bias。这里的特征![]() 包含两类特征:
包含两类特征:
(1) 原始输入特征;
(2) 通过变换后(交叉积)的特征;
这里的用的主要变换是交叉积(cross-product),它定义如下:
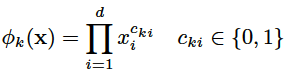
上式中![]() 是布尔型变量,如果第 i 个特征
是布尔型变量,如果第 i 个特征![]() 是第 k 个变换
是第 k 个变换![]() 的一部分,那么
的一部分,那么![]() =1,否则为0。对于交叉积And(gender=female, language=en),只有当它的成分特征都为1时(即gender=femal并且language=en时),
=1,否则为0。对于交叉积And(gender=female, language=en),只有当它的成分特征都为1时(即gender=femal并且language=en时),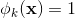 ,否则
,否则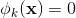 。
。
deep部分是一个前馈神经网络模型,高维类别特征通过先嵌入到低维向量空间(几十上百维)转化为稠密向量, 再灌入深度学习模型中。神经网络中每一层通过计算公式
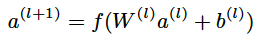
与上一层进行数据交互。上式中![]() 是层数,f 是激活函数(该模型采用了ReLU激活函数),
是层数,f 是激活函数(该模型采用了ReLU激活函数),![]() 、
、![]() 是模型需要学习的参数。
是模型需要学习的参数。
最终wide和deep部分需要加起来进行logistic变换,利用交叉熵损失函数进行联合训练。最终我们通过如下方式来预测用户的兴趣偏好(这里也是将预测看成是二分类问题,预测用户的点击概率)。
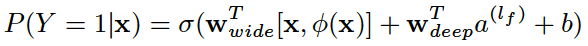
这里,![]() 是最终的二元分类变量,
是最终的二元分类变量,![]() 是sigmoid函数,
是sigmoid函数,![]() 是前面提到的交叉积特征,
是前面提到的交叉积特征,![]() 和
和![]() 分别是wide模型的权重和deep模型中对应于最后激活
分别是wide模型的权重和deep模型中对应于最后激活![]() (最后一个隐藏层进行激活函数变换后的向量)的权重。
(最后一个隐藏层进行激活函数变换后的向量)的权重。
下面图2是最终的wide & deep模型的整体结构,类别特征是嵌入到32维空间的稠密向量,数值特征归一化到0-1之间(本文中归一化采用了该变量的累积分布函数,再通过将累积分布函数分成若干个分位点,用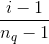 来作为该变量的归一化值,这里
来作为该变量的归一化值,这里![]() 是分位点的个数),数值特征和类别特征拼接起来形成大约1200维的向量再灌入deep模型,而wide模型是APP安装和APP曝光(impression)两类特征通过交叉积变换形成模型需要的特征。最后通过反向传播算法来训练该模型(wide模型采用FTRL优化器,deep模型采用AdaGrad优化器),并上线到APP推荐业务中做AB测试。
是分位点的个数),数值特征和类别特征拼接起来形成大约1200维的向量再灌入deep模型,而wide模型是APP安装和APP曝光(impression)两类特征通过交叉积变换形成模型需要的特征。最后通过反向传播算法来训练该模型(wide模型采用FTRL优化器,deep模型采用AdaGrad优化器),并上线到APP推荐业务中做AB测试。
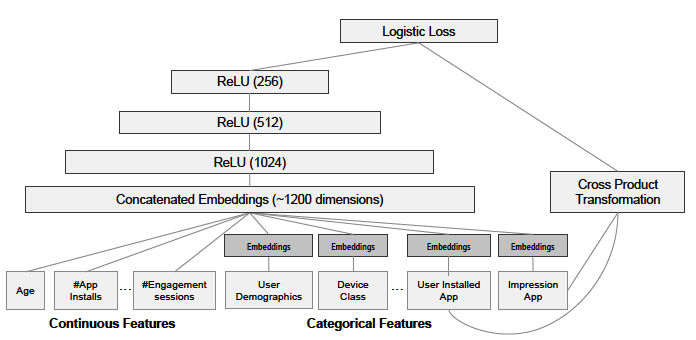
图2:wide & deep 模型的数据源与具体网络结构
上面简单介绍完了wide & deep 模型架构及实现,为了方便大家更好地理解上面的架构和公式说明,下面图3可以更好地帮助大家梳理思路。
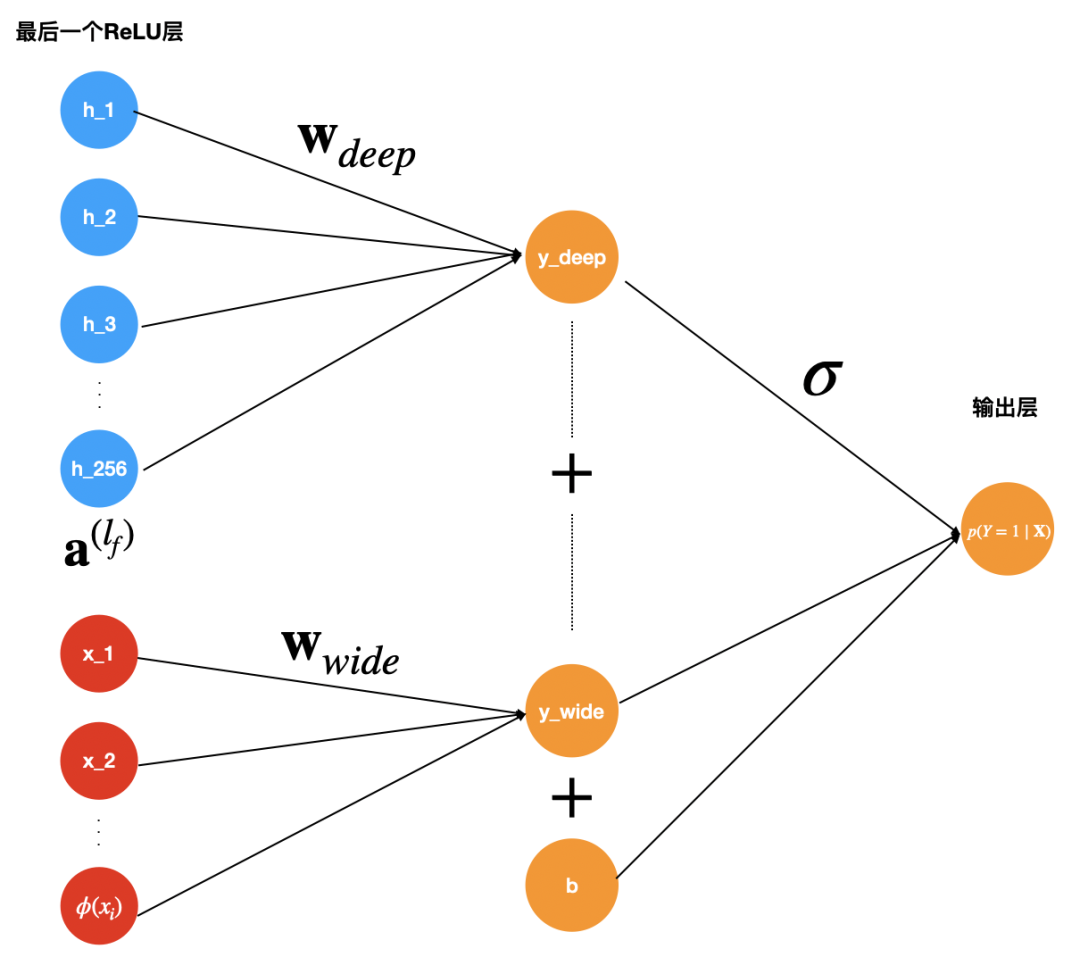
图3:wide & deep 模型的预测和训练的逻辑
借助wide & deep模型这种将简单模型跟深度学习模型联合训练,最终获得浅层模型的记忆特性及深度模型的泛化特性两大优点,有很多研究者进行了很多不同维度的尝试和探索。其中deepFM(参考文献2)就是将分解机与深度学习进行结合,部分解决了wide & deep模型中wide部分还是需要做很多人工特征工程(主要是交叉特征)的问题,并取得了非常好的效果,被国内很多公司应用于推荐系统排序及广告点击预估中,感兴趣的读者可以阅读了解。
12.3.3 wide & deep的工程实现
wide & deep的实现目前有很多开源框架,大家可以学习,下面列举几个比较有名的供大家参考一下。
1、DeepCTR
DeepCTR中有wide & deep的实现,读者可以参考https://github.com/shenweichen/DeepCTR/blob/master/deepctr/models/wdl.py。
2、英伟达
英伟达维护了一个wide & deep的实现,里面有非常详细的关于模型的实现及使用的说明,大家可以参考下面链接了解具体情况。
https://github.com/NVIDIA/DeepLearningExamples/tree/master/TensorFlow2/Recommendation/WideAndDeep
3、intel
intel也维护了一个wide & deep的实现版本,读者可以参考下面链接了解。
https://github.com/IntelAI/models/tree/master/benchmarks/recommendation/tensorflow/wide_deep_large_ds
4、PaddleRec
这个是百度开源的深度学习框架PaddlePaddle(飞桨)中的wide & deep模型,有对飞桨感兴趣的读者可以参考这个实现方式。
https://github.com/PaddlePaddle/PaddleRec/tree/master/models/rank/wide_deep
5、Recommenders
微软开源的recommenders推荐算法库中也有wide & deep的实现,读者可以参考下面链接了解。
https://github.com/microsoft/recommenders/blob/main/examples/00_quick_start/wide_deep_movielens.ipynb
13.2 YouTube深度学习排序算法
YouTube深度学习排序模型也非常经典,通过利用加权logistics回归作为输出层进行训练,然后在预测阶段利用指数函数![]() 进行预测,可以很好地匹配视频的播放时长这个业务指标。下面来对该模型的架构和特性进行说明。
进行预测,可以很好地匹配视频的播放时长这个业务指标。下面来对该模型的架构和特性进行说明。
13.2.1 模型架构
候选集排序阶段(参见下面图4)通过整合用户更多维度的特征,通过特征拼接获得最终的模型输入向量,灌入三层的全连接MLP神经网络,通过一个加权的logistic回归输出层获得对用户点击概率(即当做二分类问题)的预测,同样采用交叉熵作为损失函数。
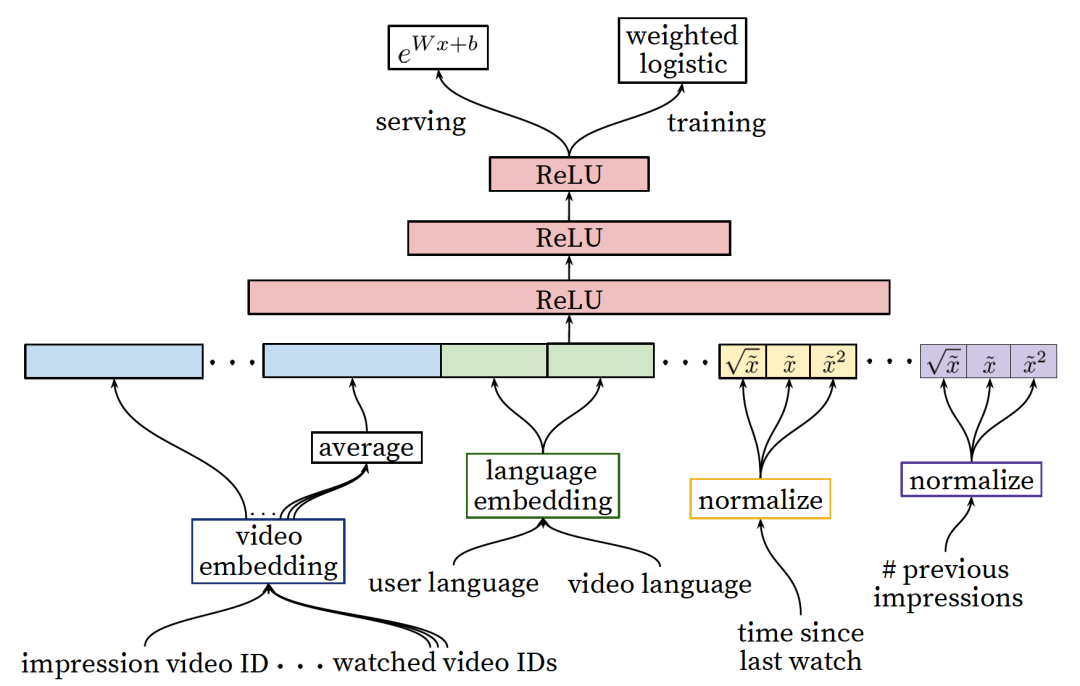
图4:候选集排序阶段深度学习模型结构
YouTube希望优化的不是点击率而是用户的播放时长,这样可以更好地满足用户需求,提升了时长也会获得更好的广告投放回报(时长增加了,投放广告的可能性也相对增加),因此在候选集排序阶段希望预测用户下一个视频的播放时长。所以才采用图4的这种输出层的加权logistic激活函数和预测的指数函数:![]() 。这里的参数
。这里的参数![]() 是图4中最后一层隐藏层到输出层的权重矩阵,
是图4中最后一层隐藏层到输出层的权重矩阵,![]() 是最后一个隐藏层激活后的向量,b是bias,参见下面图5,可以更好地理解。
是最后一个隐藏层激活后的向量,b是bias,参见下面图5,可以更好地理解。
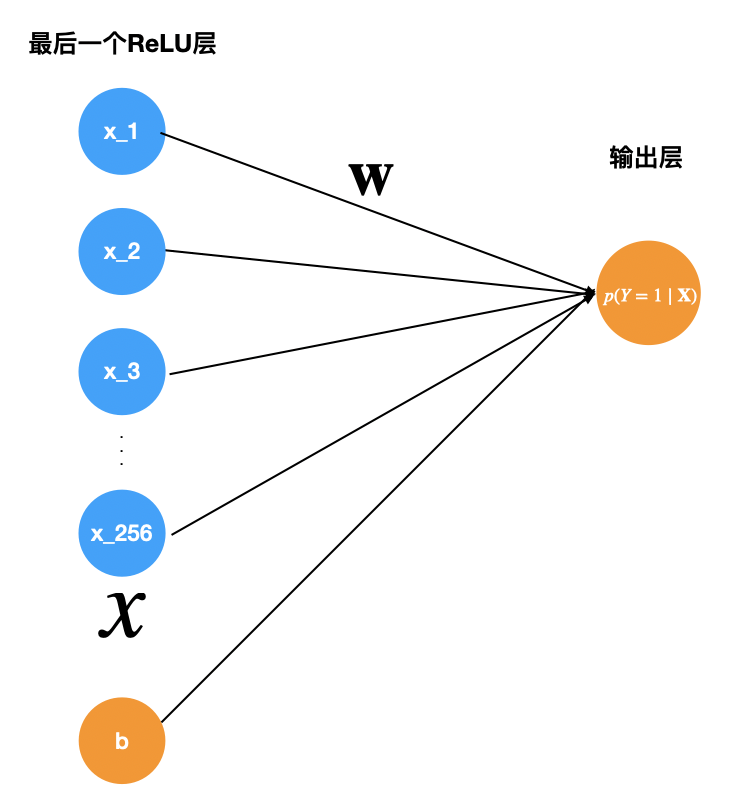
图5:![]() 中的参数的解释说明
中的参数的解释说明
由于该排序模型用的是二分类模型,因此训练样本是<用户,视频>对,所以训练样本中的特征就包含用户相关的和预测视频相关的,其中图4中的“impression video id”和“video language”是预测视频相关的特征,其它是用户相关的特征。我们预测的就是图4中左下角的“impression video id”这个视频的观看时长。
13.2.2 加权logistics回归解释
加权logistics回归是怎么做的呢?论文中没有详细说明,这一节我们简单解释一下,方便读者更好地理解。
基于交叉熵损失函数的定义:

这里的![]() 是真实的概率值,
是真实的概率值,![]() 是预测的概率值。对于正样本来说,
是预测的概率值。对于正样本来说,![]() ,
, 。对于负样本来说
。对于负样本来说![]() ,
,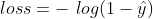 。不管样本是正负,
。不管样本是正负,![]() 是模型预测出来的,
是模型预测出来的,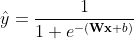 。
。
如果对于正样本,我们利用样本的播放时长![]() 来进行加权,那么上面的损失函数就是
来进行加权,那么上面的损失函数就是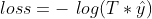 ,
,![]() 越大,损失越小,说明越“奖励”这样的正样本。由于负样本的加权参数为1,损失不变,还是
越大,损失越小,说明越“奖励”这样的正样本。由于负样本的加权参数为1,损失不变,还是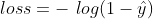 。
。
13.2.3 预测播放时长
下面我们来说明为什么这样的形式刚好是优化了用户的播放时长。模型用加权logistic回归来作为输出层的激活函数,对于正样本,权重是视频的观看时间,对于负样本权重为1。下面我们简单说明一下为什么用加权logistic回归以及serving阶段为什么要用![]() 来预测。
来预测。
logistic函数公式如下,
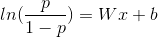
通过变换,我们得到
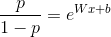
左边即是logistic回归的odds(几率),下面我们说明一下上述加权的logistic回归为什么预测的也是odds。对于正样本 i ,由于用了![]() 加权,odds可以计算为
加权,odds可以计算为
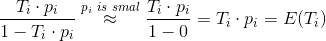
上式中约等于号成立,是因为YouTube视频总量非常大,而正样本是很少的,因此点击率![]() 很小,相对于1可以忽略不计。上式计算的结果正好是视频的期望播放时长。因此,通过加权logistic回归来训练模型,并通过
很小,相对于1可以忽略不计。上式计算的结果正好是视频的期望播放时长。因此,通过加权logistic回归来训练模型,并通过![]() 来预测,刚好预测的正是视频的期望观看时长,预测的目标跟建模的期望保持一致,这是该模型非常巧妙的地方。
来预测,刚好预测的正是视频的期望观看时长,预测的目标跟建模的期望保持一致,这是该模型非常巧妙的地方。
候选集排序阶段为了让排序更加精准,利用了非常多的特征灌入模型(由于只需对候选集中的几百个而不是全部视频排序,这时可以选用更多的特征、相对复杂的模型),包括类别特征和连续特征,文章中讲解了很多特征处理的思想和策略,这里不细介绍,读者可以看论文深入了解。
YouTube的这篇推荐论文是非常经典的工业级深度学习推荐论文,里面有很多工程上的权衡和处理技巧,值得读者深入学习。这篇论文理解起来还是有点困难的,需要有很多工程上的经验积累才能够领悟其中的奥妙。
关于YouTube深度学习排序算法的工程实现,我没有找到比较官方的开源的代码实现,只有零星个人的作品,这里也不推荐了。
总结
本章我们介绍了在推荐系统发展史上具备里程碑作用、奠基性的2篇排序算法,即Google的wide & deep排序算法和YouTube深度学习排序算法。这2个算法的实现原理不是很复杂,工程实现业比较容易,但是确实包含了非常多的值得大家学习的思想,特别是对样本、特征的处理以及工程实现上的考量非常有技巧。
wide & deep中的将记忆和泛化能力结合的模型架构博采众长,非常有现实意义。YouTube深度学习排序中通过加权logistics回归作为输出层来训练模型,在模型服务时利用![]() 来预测视频的播放时长,完美地解决了模型与业务目标(希望用户观看更长的时间)的一致性。
来预测视频的播放时长,完美地解决了模型与业务目标(希望用户观看更长的时间)的一致性。
现在各种深度学习排序模型非常多,我们在本章也只介绍这2种最经典的方法,其它各种排序算法大家可以自行学习。到目前为止,我们的推荐系统召回、排序部分的讲解就结束了。从下一章开始,我们会介绍推荐系统工程相关的知识点。
参考文献
1、[Google 2016] Wide & Deep Learning for Recommender Systems
2、[2017 华为诺亚实验室] DeepFM- A Factorization-Machine based Neural Network for CTR Prediction
3、[YouTube 2016] Deep Neural Networks for YouTube Recommendations
大家如果想更全面学习推荐系统,可以购买作者之前出版的图书,购买链接如下:
