CV - 计算机视觉 | ML - 机器学习 | RL - 强化学习 | NLP 自然语言处理
Subjects: cs.CV
1.Make-A-Protagonist: Generic Video Editing with An Ensemble of Experts

标题:Make-A-Protagonist:与专家合奏的通用视频编辑
作者:Yuyang Zhao, Enze Xie, Lanqing Hong, Zhenguo Li, Gim Hee Lee
文章链接:https://arxiv.org/abs/2305.08850
项目代码:https://make-a-protagonist.github.io/

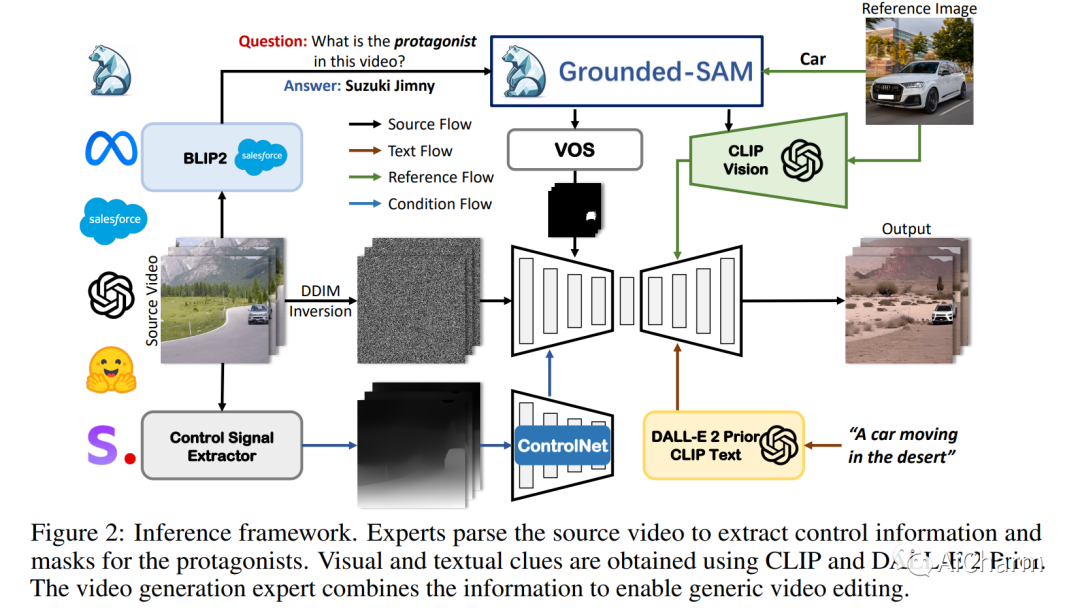
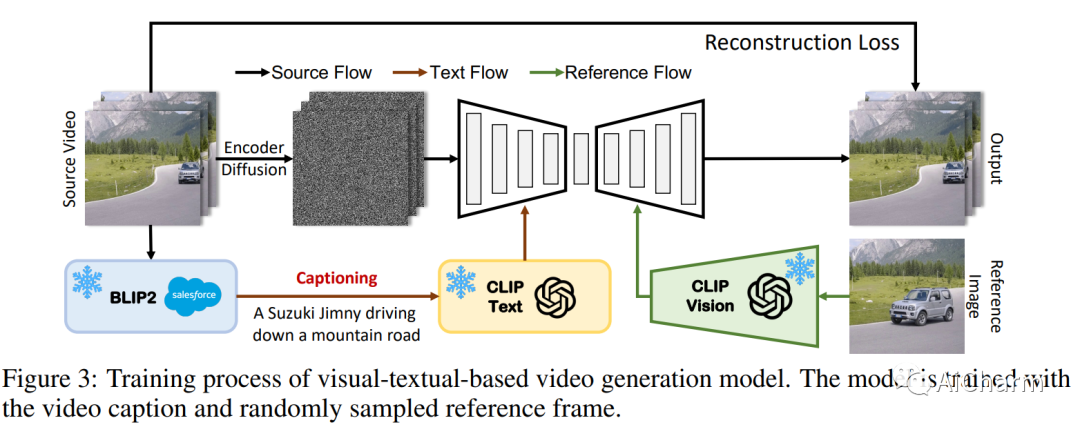
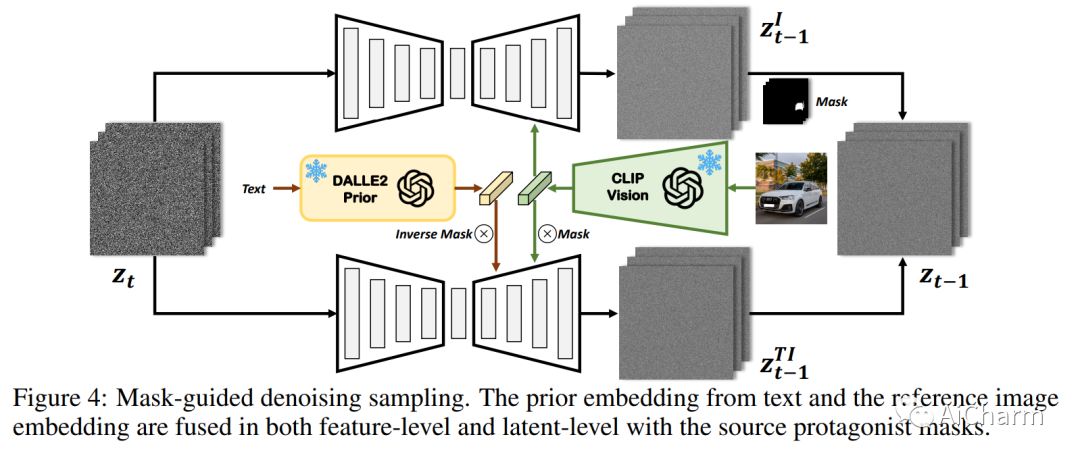
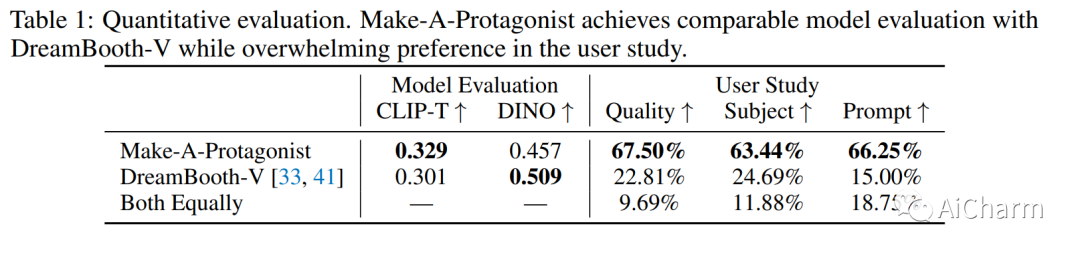

摘要:
文本驱动的图像和视频传播模型在生成逼真多样的内容方面取得了前所未有的成功。最近,基于扩散的生成模型中现有图像和视频的编辑和变化引起了广泛关注。然而,以前的作品仅限于使用文本编辑内容或使用单一视觉线索提供粗略的个性化,使其不适用于需要细粒度和详细控制的难以描述的内容。在这方面,我们提出了一个名为 Make-A-Protagonist 的通用视频编辑框架,它利用文本和视觉线索来编辑视频,目的是让个人成为主角。具体来说,我们利用多位专家来解析源视频、目标视觉和文本线索,并提出一种基于视觉文本的视频生成模型,该模型采用蒙版引导降噪采样来生成所需的输出。广泛的结果证明了 Make-A-Protagonist 的多功能和卓越的编辑能力。
Subjects: cs.CL
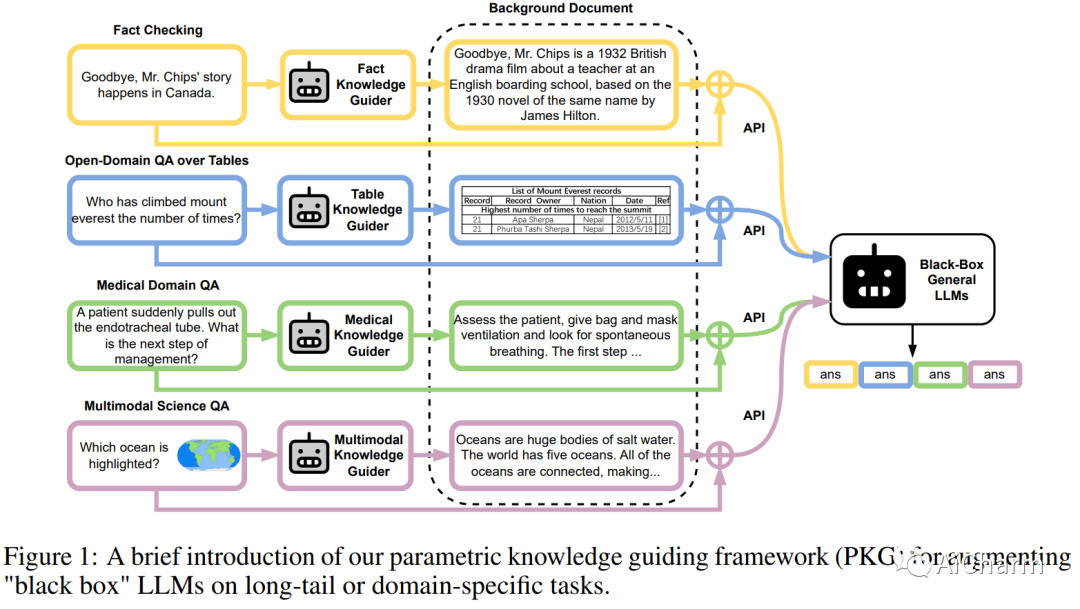
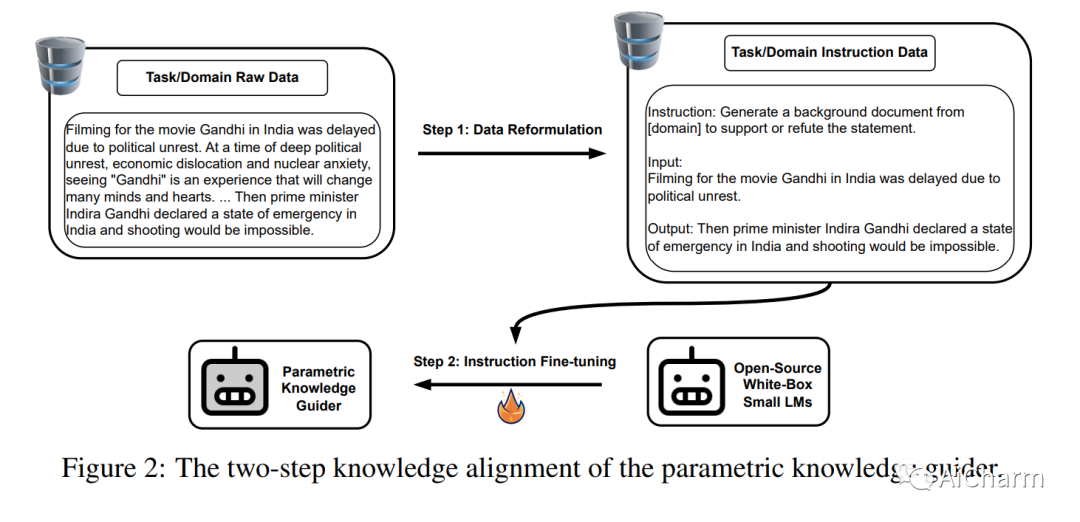
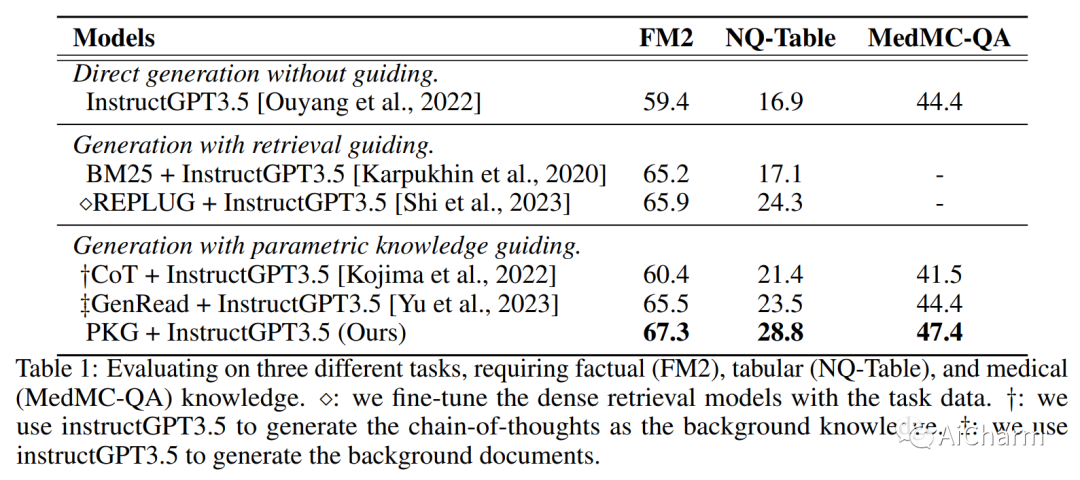
2.Augmented Large Language Models with Parametric Knowledge Guiding

标题:具有参数化知识指导的增强型大型语言模型
作者:Ziyang Luo, Can Xu, Pu Zhao, Xiubo Geng, Chongyang Tao, Jing Ma, Qingwei Lin, Daxin Jiang
文章链接:https://arxiv.org/abs/2305.04757
摘要:
大型语言模型 (LLM) 具有显着先进的自然语言处理 (NLP) 及其令人印象深刻的语言理解和生成能力。然而,由于对特定领域的知识和词汇的接触有限,它们的性能对于长尾或特定领域的任务可能不是最佳的。此外,大多数最先进的 (SOTA) LLM 缺乏透明度,只能通过 API 访问,这阻碍了对自定义数据的进一步微调。此外,数据隐私是一个重要问题。为了应对这些挑战,我们提出了新颖的参数化知识指导 (PKG) 框架,该框架为 LLM 配备了知识指导模块,以便在运行时访问相关知识,而无需更改 LLM 的参数。我们的 PKG 基于开源“白盒”小型语言模型,允许离线存储 LLM 所需的任何知识。我们证明我们的 PKG 框架可以提高“黑盒”LLM 在一系列需要事实、表格、医学和多模式知识的长尾和特定领域下游任务上的性能。
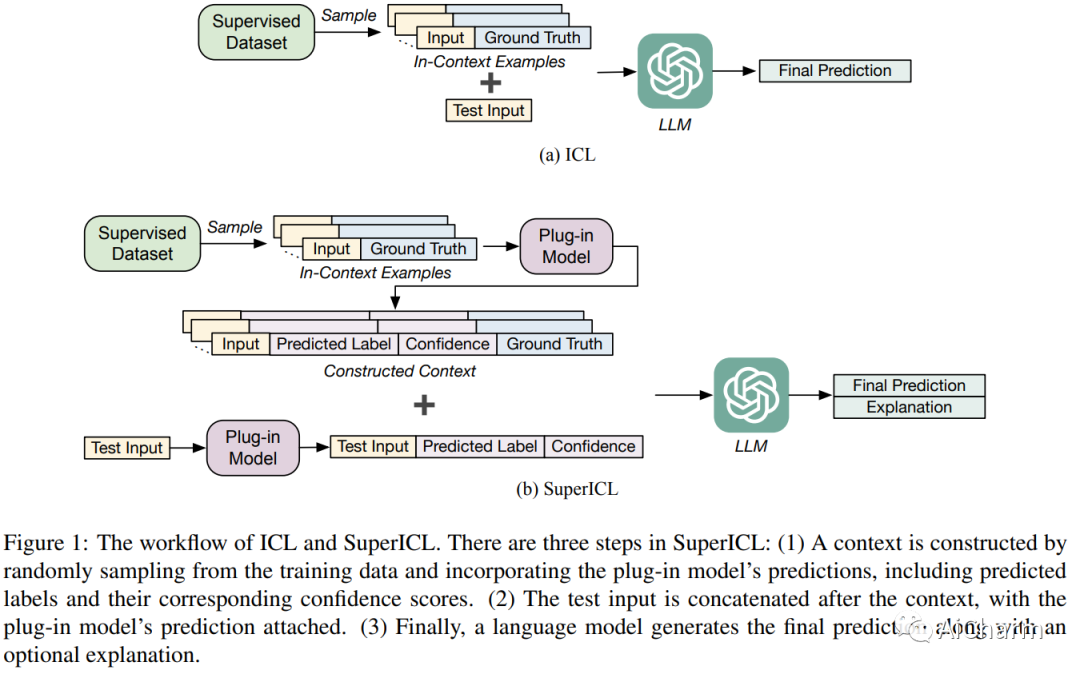
3.Small Models are Valuable Plug-ins for Large Language Models

标题:小型模型是大型语言模型的宝贵插件
作者:Canwen Xu, Yichong Xu, Shuohang Wang, Yang Liu, Chenguang Zhu, Julian McAuley
文章链接:https://arxiv.org/abs/2305.04757

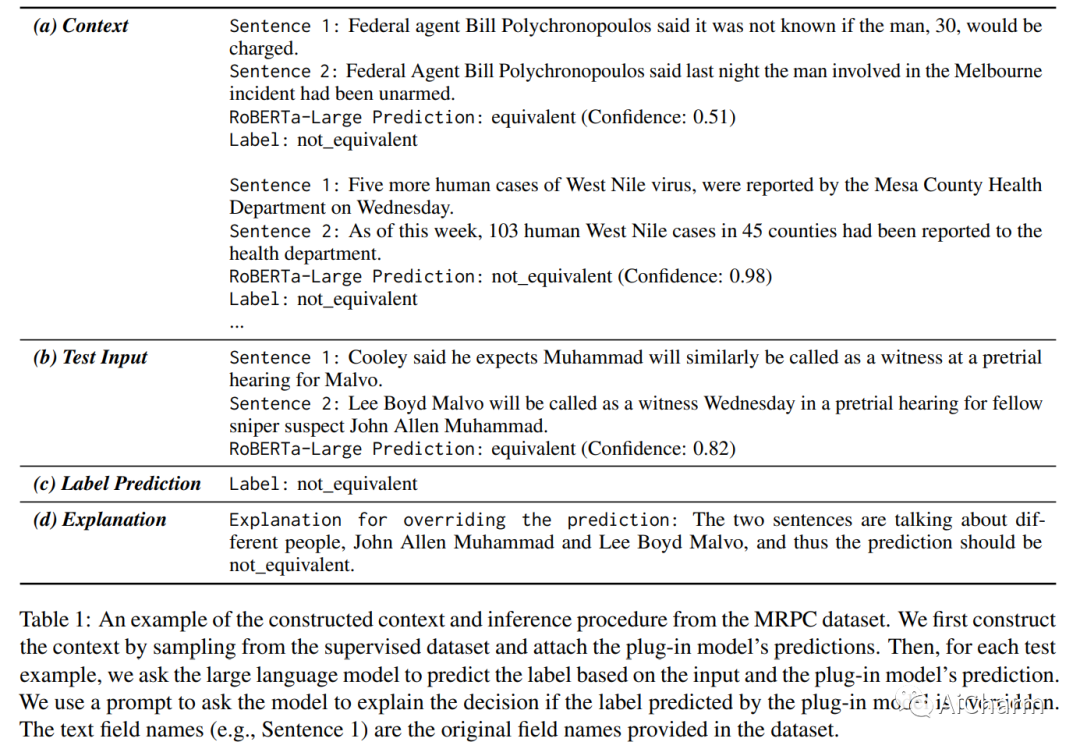
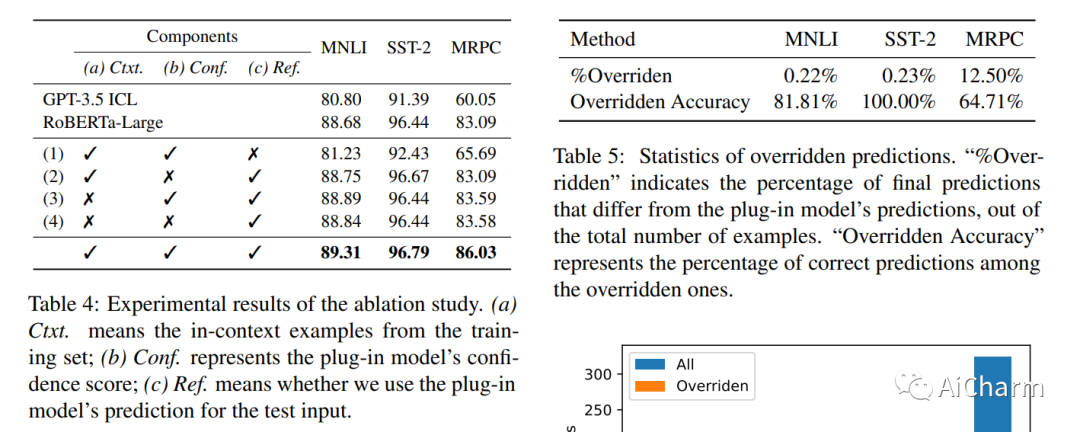
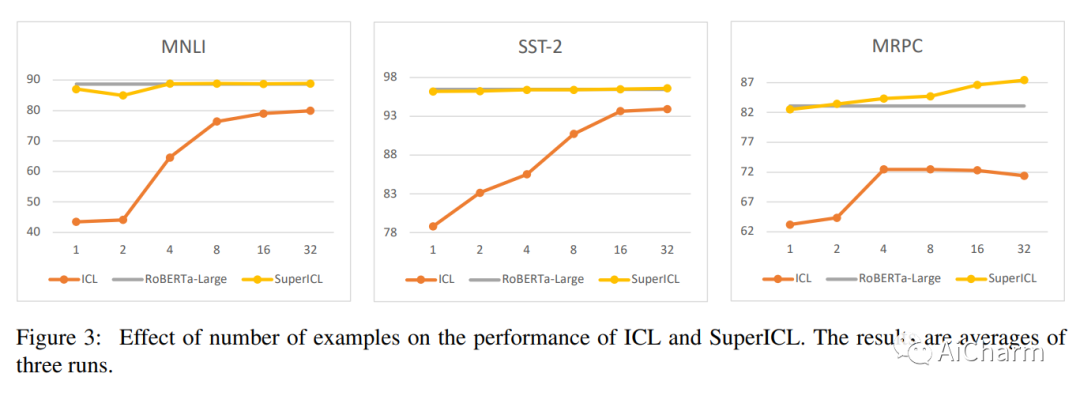
摘要:
GPT-3 和 GPT-4 等大型语言模型 (LLM) 功能强大,但它们的权重通常是公开不可用的,而且它们的巨大尺寸使得模型难以使用通用硬件进行调整。因此,使用大规模监督数据有效地调整这些模型可能具有挑战性。作为替代方案,由于上下文长度限制,上下文学习 (ICL) 只能使用少量监督示例。在本文中,我们提出了超级上下文学习 (SuperICL),它允许黑盒 LLM 与局部微调的较小模型一起工作,从而在监督任务上获得卓越的性能。我们的实验表明,SuperICL 可以提高性能,超越最先进的微调模型,同时解决上下文学习的不稳定问题。此外,SuperICL 可以增强较小模型的能力,例如多语言性和可解释性。
更多Ai资讯:公主号AiCharm