问题:
对于一个url连接例如”www.abc.cn/name=北京”这样一个链接,如果直接
用urlopen读取会报错:
UnicodeEncodeError: 'ascii' codec can't encode characters in position 37-40: ordinal not in range(128) 解决:
解决办法就是使用urllib.parse.quote()解析中文部分。
url=”www.abc.cn/name=”+urllib.parse.quote(“北京”)
也可以使用safe参数指定不解析的字符
url=urllib.parse.quote(“www.abc.cn/name=北京”,safe=’/:?=.’)
指定’/:?=.’这些符号不转换
知识拓展:
1.从字节说起:
一个字节包括八个比特位,每个比特位表示0或1,一个字节即可表示从00000000到11111111共2^8=256个数字。一个ASCII编码使用一个字节(除去字节的最高位作为作奇偶校验位),ASCII编码实际使用一个字节中的7个比特位来表示字符,共可表示2^7=128个字符。比如ASCII编码中的01000001(即十进制的65)表示字符’A’,01000001加上32之后的01100001(即十进制的97)表示字符’a’。现在打开Python,调用chr和ord函数,我们可以看到Python为我们对ASCII编码进行了转换。如图

第一个00000000表示空字符,因此ASCII编码实际上只包括了 字母、标点符号、特殊符号等共127个字符。因为ASCII是在美国出生的,对于由字母组成单词进而用单词表达的英文来说也是够了。但是中国人、日本人、 韩国人等其他语言的人不服了。中文是一个字一个字,ASCII编码用上了浑身解数256个字符都不够用。
因此后来出现了Unicode编码。Unicode编码通常由两个字节组成,共表示256*256个字符,即所谓的UCS-2。某些偏僻字还会用到四个字节,即所谓的UCS-4。也就是说Unicode标准也还在发展。但UCS-4出现的比较少,我们先记住: 最原始的ASCII编码使用一个字节编码,但由于语言差异字符众多,人们用上了两个字节,出现了统一的、囊括多国语言的Unicode编码。
在Unicode中,原本ASCII中的127个字符只需在前面补一个全零的字节即可,比如前文谈到的字符‘a’:01100001,在Unicode中变成了00000000 01100001。不久,美国人不开心了,吃上了世界民族之林的大锅饭,原本只需一个字节就能传输的英文现在变成两个字节,非常浪费存储空间和传输速度。
人们再发挥聪明才智,于是出现了UTF-8编码。因为针对的是空间浪费问题,因此这种 UTF-8编码是可变长短的 ,从英文字母的一个字节,到中文的通常的三个字节,再到某些生僻字的六个字节。解决了空间问题,UTF-8编码还有一个神奇的附加功能,那就是兼容了老大哥的ASCII编码。一些老古董软件现在在UTF-8编码中可以继续工作。
注意除了英文字母相同,汉字在Unicode编码和UTF-8编码中通常是不同的。比如汉字的‘中’字在Unicode中是01001110 00101101,而在UTF-8编码中是11100100 10111000 10101101。
我们祖国母亲自然也有自己的一套标准。那就是GB2312和GBK。当然现在挺少看到。通常都是直接使用UTF-8。
2.Python3中的默认编码
Python3中默认是UTF-8,我们通过以下代码:

3.Python3中的encode和decode
Python3中字符编码经常会使用到decode和encode函数。特别是在抓取网页中,这两个函数用的熟练非常有好处。encode的作用,使我们看到的直观的字符转换成计算机内的字节形式。decode刚好相反,把字节形式的字符转换成我们看的懂的、直观的、“人模人样”的形式。
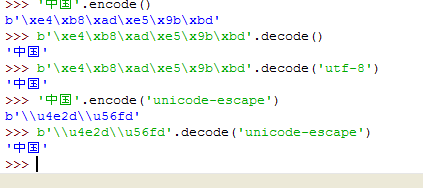
\x表示后面是十六进制, \xe4\xb8\xad即是二进制的 11100100 10111000 10101101。也就是说汉字‘中’encode成字节形式,是 11100100 10111000 10101101。同理,我们拿 11100100 10111000 10101101也就是 \xe4\xb8\xad来decode回来,就是汉字‘中’。完整的应该是 b’\xe4\xb8\xad’,在Python3中, 以字节形式表示的字符串则必须加上 前缀b,也就是写成上文的b’xxxx’形式。
前文说的Python3的默认编码是UTF-8,所以我们可以看到,Python处理这些字符的时候是以UTF-8来处理的。因此从上图可以看到,就算我们通过encode(‘utf-8’)特意把字符encode为UTF-8编码,出来的结果还是相同:b’\xe4\xb8\xad’。
明白了这一点,同时我们知道UTF-8兼容ASCII,我们可以猜想大学时经常背诵的‘A’对应ASCII中的65,在这里是不是也能正确的decode出来呢。十进制的65转换成十六进制是41,我们尝试下:
b'\x41'.decode()
4.Python3中的编码转换
据说字符在计算机的内存中统一是以Unicode编码的。只有在字符要被写进文件、存进硬盘或者从服务器发送至客户端(例如网页前端的代码)时会变成utf-8。但其实我比较关心怎么把这些字符以Unicode的字节形式表现出来,露出它在内存中的庐山正面目的。这里有个照妖镜:
xxxx.encode/decode('unicode-escape')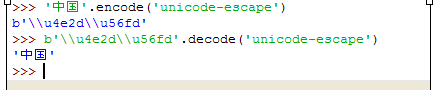
如果我们知道一个Unicode字节码,怎么变成UTF-8的字节码呢。懂了以上这些,现在我们就有思路了,先decode,再encode。代码如下:
xxx.decode('unicode-escape').encode()参考资料:博主:Dillon2015 https://blog.csdn.net/Dillon2015/article/details/53161249
网站:脚本之家 http://www.jb51.net/article/92006.htm