tensorRT的Entropy Calibration的伪代码,具体流程如下:
- for循环:遍历所有可能的分割点,从128到2048
- reference_distribution_P:将原始直方图bins按照当前分割点i进行切割,得到左侧的i个bin。
- outliers_count:将原始直方图bins按照当前分割点i进行切割,得到右侧的2048-i个bin。
- reference_distribution_P[ i-1 ] += outliers_count:将outliers_count加入到reference_distribution_P中,得到新的概率分布。
- P /= sum§:将reference_distribution_P进行归一化。
- candidate_distribution_Q:将当前的i个bin分成128个level,得到candidate_distribution_Q,表示我们将reference_distribution_P进行量化。
- Q /= sum(Q):将candidate_distribution_Q进行归一化。
- KL_divergence( reference_distribution_P, candidate_distribution_Q):计算当前量化方法下的KL散度,并将其保存在divergence中。
- 循环结束后,divergence中记录了每个分割点i下的KL散度。我们选取KL散度最小的分割点i作为最优的分割点,并将其作为最终的量化参数。

总的来说,Entropy Calibration的过程就是将概率分布量化成少量的level,并寻找最优的level,使得量化后的分布和原始分布的KL散度最小。
有一个问题需要讨论,既然是INT8量化(2^8=256),为什么我们量化的是128个bins而不是256个bins?
回答:因为量化中针对的数据是激活函数ReLU后的,即经过ReLU后的值均为正数,所以负数就不用考虑了,而原来INT8的取值范围是在[-128,127]之间,因此[-128,0]就不用考虑了,而原始的分布[0,127]就能够表达,因此for循环就是从[128,2048]
完整的示例代码如下:
import random
import numpy as np
import matplotlib.pyplot as plt
def generator_P(size):
walk = []
avg = random.uniform(3.000, 600.999)
std = random.uniform(500.000, 1024.959)
for _ in range(size):
walk.append(random.gauss(avg, std))
return walk
# smooth_distribution:对概率分布 P 和 Q 进行平滑处理,避免 KL 散度计算时出现分母为0的情形
def smooth_distribution(p, eps=0.0001):
is_zeros = (p == 0).astype(np.float32)
is_nonzeros = (p != 0).astype(np.float32)
n_zeros = is_zeros.sum()
n_nonzeros = p.size - n_zeros
if not n_nonzeros:
raise ValueError('The discrete probability distribution is malformed. All entries are 0.')
eps1 = eps * float(n_zeros) / float(n_nonzeros)
assert eps1 < 1.0, 'n_zeros=%d, n_nonzeros=%d, eps1=%f' % (n_zeros, n_nonzeros, eps1)
hist = p.astype(np.float32)
hist += eps * is_zeros + (-eps1) * is_nonzeros
assert (hist <= 0).sum() == 0
return hist
import copy
import scipy.stats as stats
def threshold_distribution(distribution, target_bin=128):
# 遍历直方图分布,区间为[1:2048]
distribution = distribution[1:] # 将distribution数组的第一个元素去掉 [1:]???
# distribution = distribution[:]
length = distribution.size # distribution的长度
# 计算概率分布从target_bin位置开始的累加和,即outliers_count
outliers_count = sum(distribution[target_bin:])
# 初始化一个numpy数组,用来存放每个阈值下计算得到的所有KL散度
kl_divergence = np.zeros(length - target_bin)
# for i in range(128,2048)
for threshold in range(target_bin, length):
# 将distribution数组中前threshold个元素拷贝到sliced_nd_hist数组中。
# print(threshold)
sliced_nd_hist = copy.deepcopy(distribution[:threshold])
# generate reference distribution P
p = sliced_nd_hist.copy()
# 将后面outliers_count加到reference_distribution_P中,得到新的概率分布
p[threshold - 1] += outliers_count
# 将p进行归一化 量化前的p
p = p / np.sum(p)
# 更新outliers_count的值,第一次循环的outliers_count为distribution[128:],第二次循环的outliers_count为distribution[129:],...
outliers_count = outliers_count - distribution[threshold]
# is_nonzeros[k] indicates whether hist[k] is nonzero
is_nonzeros = (p != 0).astype(np.int64) # 判断每一位是否非零
# 量化后的bins
quantized_bins = np.zeros(target_bin, dtype=np.int64)
# calculate how many bins should be merged to generate
# quantized distribution q
num_merged_bins = sliced_nd_hist.size // target_bin # 计算stride
# merge hist into num_quantized_bins bins
for j in range(target_bin):
start = j * num_merged_bins
# stop最大为127
stop = start + num_merged_bins
quantized_bins[j] = sliced_nd_hist[start:stop].sum()
# [target_bin * num_merged_bins:]:这里要注意一下
quantized_bins[-1] += sliced_nd_hist[target_bin * num_merged_bins:].sum() # 将多余位累加到最后整除的位置上
# expand quantized_bins into p.size bins
# 定义分布:q,这里的size要和p分布一致
q = np.zeros(sliced_nd_hist.size, dtype=np.float64) # 进行位扩展
for j in range(target_bin):
start = j * num_merged_bins
# 这几行代码改为stop = start + num_merged_bins
if j == target_bin - 1:
# 将多余也累加到最后整除的位置上
stop = -1
else:
stop = start + num_merged_bins
norm = is_nonzeros[start:stop].sum()
if norm != 0:
# 求q的平均值
q[start:stop] = float(quantized_bins[j]) / float(norm)
# 平滑处理,保证KLD计算出来不会无限大
# exit(1)
q = q /np.sum(q)
p = smooth_distribution(p)
q = smooth_distribution(q)
# calculate kl_divergence between p and q
kl_divergence[threshold - target_bin] = stats.entropy(p, q) # 计算KL散度
min_kl_divergence = np.argmin(kl_divergence) # 选择最小的KL散度
threshold_value = min_kl_divergence + target_bin
return threshold_value
if __name__ == '__main__':
# 获取KL最小阈值
size = 20480
# generator_P(size):生成一个大小为size的随机数列,并使用高斯分布生成其中每个数的值。
P = generator_P(size)
P = np.array(P)
# 只取大于零的数
P = P[P>0]
print("最大的激活值", max(np.absolute(P)))
# 使用np.histogram(P, bins=2048)将P划分成2048组,并返回各组数据量和区间范围。
hist, bins = np.histogram(P, bins=2048)
# print(hist)
threshold = threshold_distribution(hist, target_bin=128)
print("threshold 所在组:", threshold)
print("threshold 所在组的区间范围:", bins[threshold])
# 分成split_zie组,density表示是否要normed
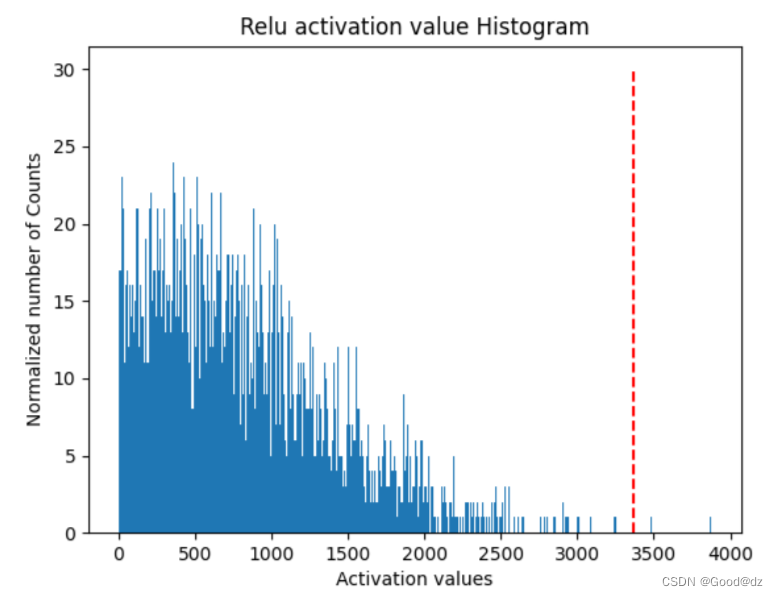
plt.title("Relu activation value Histogram")
plt.xlabel("Activation values")
plt.ylabel("Normalized number of Counts")
plt.hist(P, bins=2047)
plt.vlines(bins[threshold], 0, 30, colors='r', linestyles='dashed')
plt.show()
输出如下:
最大的激活值 3878.868170933664
threshold 所在组: 1777
threshold 所在组的区间范围: 3365.600012434412
上述示例代码主要是实现了一种量化方法——基于熵的量化(Entropy-based Quantization)。该方法的基本思路是通过统计神经网络中激活值的分布情况,并通过一些数学模型和技巧将其分解为多个区间,最终实现对神经网络模型中权重和激活值进行有损压缩的目的,从而减少模型的存储和计算开销。
参考链接:
https://blog.csdn.net/qq_40672115/article/details/129942542