DINO代码学习笔记(一)中已经将输入transformer之前的参数处理给捋了一遍
DINO代码学习笔记(二)中将encoder部分给捋了一遍
本篇进入decoder,这里先对encoder做一些假设,基于DINO代码学习笔记(二)中encoder输出:
1、memory[N,9350,256];
2、enc_intermediate_output=None;
3、enc_intermediate_refpoints=None;
在输入decoder之前还需要对输入参数做一些处理,比如论文原文提到的Mixed Query Selection,总结来说就是,DETR和DN-DETR模型中的解码器查询是静态嵌入,没有使用编码器特征。而Deformable DETR和Efficient DETR则选择编码器特征来增强解码器查询,从而提高模型的性能。也就是从最后一个编码器层中选择前K个编码器特征作为先验,以增强解码器查询。
if self.two_stage_type =='standard':
if self.two_stage_learn_wh:
input_hw = self.two_stage_wh_embedding.weight[0]
else:
input_hw = None
output_memory, output_proposals = gen_encoder_output_proposals(memory, mask_flatten, spatial_shapes, input_hw)
output_memory = self.enc_output_norm(self.enc_output(output_memory)) # Linear(256,256) + Layer Norm
if self.two_stage_pat_embed > 0:
bs, nhw, _ = output_memory.shape
# output_memory: bs, n, 256; self.pat_embed_for_2stage: k, 256
output_memory = output_memory.repeat(1, self.two_stage_pat_embed, 1)
_pats = self.pat_embed_for_2stage.repeat_interleave(nhw, 0)
output_memory = output_memory + _pats
output_proposals = output_proposals.repeat(1, self.two_stage_pat_embed, 1)
if self.two_stage_add_query_num > 0:
assert refpoint_embed is not None
output_memory = torch.cat((output_memory, tgt), dim=1)
output_proposals = torch.cat((output_proposals, refpoint_embed), dim=1)
enc_outputs_class_unselected = self.enc_out_class_embed(output_memory) # Linear(256,91) [N,9350,91]
enc_outputs_coord_unselected = self.enc_out_bbox_embed(output_memory) + output_proposals # (bs, \sum{hw}, 4) unsigmoid [N,9350,4]
topk = self.num_queries # 900
topk_proposals = torch.topk(enc_outputs_class_unselected.max(-1)[0], topk, dim=1)[1] # bs, nq top900索引[N,900]
# gather boxes
refpoint_embed_undetach = torch.gather(enc_outputs_coord_unselected, 1, topk_proposals.unsqueeze(-1).repeat(1, 1, 4)) # unsigmoid 横向根据topk_proposals取值 [N,900,4]
refpoint_embed_ = refpoint_embed_undetach.detach() # refpoint_embed_ [N,900,4]
init_box_proposal = torch.gather(output_proposals, 1, topk_proposals.unsqueeze(-1).repeat(1, 1, 4)).sigmoid() # sigmoid init_box_proposal [N,900,4]
# gather tgt
tgt_undetach = torch.gather(output_memory, 1, topk_proposals.unsqueeze(-1).repeat(1, 1, self.d_model))
if self.embed_init_tgt:
tgt_ = self.tgt_embed.weight[:, None, :].repeat(1, bs, 1).transpose(0, 1) # nq, bs, d_model [N,900,256]
else:
tgt_ = tgt_undetach.detach()
if refpoint_embed is not None:
refpoint_embed=torch.cat([refpoint_embed,refpoint_embed_],dim=1) # [N,1100,4]
tgt=torch.cat([tgt,tgt_],dim=1) # [N,1100,256]
else:
refpoint_embed,tgt=refpoint_embed_,tgt_其中有个提议函数,这个函数的功能是根据编码器的输出记忆,生成相应的提议和处理后的记忆:
def gen_encoder_output_proposals(memory:Tensor, memory_padding_mask:Tensor, spatial_shapes:Tensor, learnedwh=None):
"""
Input:
- memory: bs, \sum{hw}, d_model
- memory_padding_mask: bs, \sum{hw}
- spatial_shapes: nlevel, 2
- learnedwh: 2
Output:
- output_memory: bs, \sum{hw}, d_model
- output_proposals: bs, \sum{hw}, 4
"""
N_, S_, C_ = memory.shape
base_scale = 4.0
proposals = []
_cur = 0
for lvl, (H_, W_) in enumerate(spatial_shapes):
mask_flatten_ = memory_padding_mask[:, _cur:(_cur + H_ * W_)].view(N_, H_, W_, 1) # 取出每一层的mask,并展开成[N,H,W,1]
valid_H = torch.sum(~mask_flatten_[:, :, 0, 0], 1) # 取mask中非padding部分的H
valid_W = torch.sum(~mask_flatten_[:, 0, :, 0], 1) # 取mask中非padding部分的W
# 根据每一层feature map的最大尺寸生成网格
grid_y, grid_x = torch.meshgrid(torch.linspace(0, H_ - 1, H_, dtype=torch.float32, device=memory.device),
torch.linspace(0, W_ - 1, W_, dtype=torch.float32, device=memory.device))
grid = torch.cat([grid_x.unsqueeze(-1), grid_y.unsqueeze(-1)], -1) # H_, W_, 2
scale = torch.cat([valid_W.unsqueeze(-1), valid_H.unsqueeze(-1)], 1).view(N_, 1, 1, 2)
grid = (grid.unsqueeze(0).expand(N_, -1, -1, -1) + 0.5) / scale # 归一化
if learnedwh is not None:
wh = torch.ones_like(grid) * learnedwh.sigmoid() * (2.0 ** lvl)
else:
wh = torch.ones_like(grid) * 0.05 * (2.0 ** lvl)
proposal = torch.cat((grid, wh), -1).view(N_, -1, 4) # [N,H*W,4]
proposals.append(proposal)
_cur += (H_ * W_)
output_proposals = torch.cat(proposals, 1) # [N,9350,4]
output_proposals_valid = ((output_proposals > 0.01) & (output_proposals < 0.99)).all(-1, keepdim=True) # [N,9350,1]
output_proposals = torch.log(output_proposals / (1 - output_proposals)) # unsigmoid
output_proposals = output_proposals.masked_fill(memory_padding_mask.unsqueeze(-1), float('inf')) # 在output_proposals中,mask中对应元素为True的位置都用'inf'填充
output_proposals = output_proposals.masked_fill(~output_proposals_valid, float('inf')) # 生成proposals [N,9350,4]
output_memory = memory
output_memory = output_memory.masked_fill(memory_padding_mask.unsqueeze(-1), float(0))
output_memory = output_memory.masked_fill(~output_proposals_valid, float(0)) # 生成memory proposals [N,9350,256]
return output_memory, output_proposals对output_proposals进行有效性判断,即判断output_proposals的值是否在(0.01, 0.99)的范围内,并生成一个形状为[N, 9350, 1]的布尔张量。
具体功能:
1、根据编码器的输出memory、memory的mask和spatial_shapes,生成相应的proposals。proposals是通过在每个空间层级上生成网格和宽度、高度信息得到的,形状为[N, 9350, 4]。
2、对生成的proposals进行有效性判断,将proposals的值转换为logistic函数的逆运算,并将mask为True的填充位置和无效的proposals位置的元素填充为无穷大。
3、处理记忆部分,将mask为True的填充位置的元素填充为0,并将无效的proposals位置的元素填充为0。
4、返回处理后的output_memory张量和output_proposals张量作为函数的输出。
two_stage_pat_embed = two_stage_add_query_num = 0所以后面的两个if条件不会进去。生成output_memory和output_proposals之后,output_memory会经过Linear得到encoder输出的class和bbox,根据class选出top900的索引,得到refpoint_embed_
decoder
#########################################################
# Begin Decoder
#########################################################
hs, references = self.decoder(
tgt=tgt.transpose(0, 1), # [1100,N,256]
memory=memory.transpose(0, 1), # [9350,N,256]
memory_key_padding_mask=mask_flatten, # [N,9350]
pos=lvl_pos_embed_flatten.transpose(0, 1), # [9350,N,256]
refpoints_unsigmoid=refpoint_embed.transpose(0, 1), # [1100,N,4]
level_start_index=level_start_index, # [4]
spatial_shapes=spatial_shapes, # [4,2]
valid_ratios=valid_ratios,tgt_mask=attn_mask) # valid_ratios [2,4,2],attn_mask [1100,1100]
#########################################################
# End Decoder
# hs: n_dec, bs, nq, d_model [N,1100,256] * 6
# references: n_dec+1, bs, nq, query_dim [N,1100,4] * 7
#########################################################
其中
1、memory是encoder的输出,并transpose(0, 1),维度为[9350,N,256];
2、tgt中前200为cdn生成的噪声label(input_query_label),后900为nn.Embedding生成,并transpose(0, 1),维度为[1100,N,256];
3、refpoint_embed中前200为cdn生成的噪声bbox(input_query_bbox),后900为encoder输出的memory提议并Linear处理后选出的top900的bbox,并transpose(0, 1),维度为[1100,N,4];
class TransformerDecoder(nn.Module):
def __init__(self, decoder_layer, num_layers, norm=None,
return_intermediate=False,
d_model=256, query_dim=4,
modulate_hw_attn=False,
num_feature_levels=1,
deformable_decoder=False,
decoder_query_perturber=None,
dec_layer_number=None, # number of queries each layer in decoder
rm_dec_query_scale=False,
dec_layer_share=False,
dec_layer_dropout_prob=None,
use_detached_boxes_dec_out=False
):
super().__init__()
if num_layers > 0:
self.layers = _get_clones(decoder_layer, num_layers, layer_share=dec_layer_share)
else:
self.layers = []
self.num_layers = num_layers
self.norm = norm
self.return_intermediate = return_intermediate
assert return_intermediate, "support return_intermediate only"
self.query_dim = query_dim
assert query_dim in [2, 4], "query_dim should be 2/4 but {}".format(query_dim)
self.num_feature_levels = num_feature_levels
self.use_detached_boxes_dec_out = use_detached_boxes_dec_out
self.ref_point_head = MLP(query_dim // 2 * d_model, d_model, d_model, 2)
if not deformable_decoder:
self.query_pos_sine_scale = MLP(d_model, d_model, d_model, 2)
else:
self.query_pos_sine_scale = None
if rm_dec_query_scale:
self.query_scale = None
else:
raise NotImplementedError
self.query_scale = MLP(d_model, d_model, d_model, 2)
self.bbox_embed = None
self.class_embed = None
self.d_model = d_model
self.modulate_hw_attn = modulate_hw_attn
self.deformable_decoder = deformable_decoder
if not deformable_decoder and modulate_hw_attn:
self.ref_anchor_head = MLP(d_model, d_model, 2, 2)
else:
self.ref_anchor_head = None
self.decoder_query_perturber = decoder_query_perturber
self.box_pred_damping = None
self.dec_layer_number = dec_layer_number
if dec_layer_number is not None:
assert isinstance(dec_layer_number, list)
assert len(dec_layer_number) == num_layers
self.dec_layer_dropout_prob = dec_layer_dropout_prob
if dec_layer_dropout_prob is not None:
assert isinstance(dec_layer_dropout_prob, list)
assert len(dec_layer_dropout_prob) == num_layers
for i in dec_layer_dropout_prob:
assert 0.0 <= i <= 1.0
self.rm_detach = None
def forward(self, tgt, memory,
tgt_mask: Optional[Tensor] = None,
memory_mask: Optional[Tensor] = None,
tgt_key_padding_mask: Optional[Tensor] = None,
memory_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None,
refpoints_unsigmoid: Optional[Tensor] = None, # num_queries, bs, 2
# for memory
level_start_index: Optional[Tensor] = None, # num_levels
spatial_shapes: Optional[Tensor] = None, # bs, num_levels, 2
valid_ratios: Optional[Tensor] = None,
):
"""
Input:
- tgt: nq, bs, d_model
- memory: hw, bs, d_model
- pos: hw, bs, d_model
- refpoints_unsigmoid: nq, bs, 2/4
- valid_ratios/spatial_shapes: bs, nlevel, 2
"""
output = tgt
intermediate = []
reference_points = refpoints_unsigmoid.sigmoid()
ref_points = [reference_points]
for layer_id, layer in enumerate(self.layers):
# preprocess ref points
if self.training and self.decoder_query_perturber is not None and layer_id != 0:
reference_points = self.decoder_query_perturber(reference_points)
if self.deformable_decoder:
if reference_points.shape[-1] == 4:
reference_points_input = reference_points[:, :, None] \
* torch.cat([valid_ratios, valid_ratios], -1)[None, :] # nq, bs, nlevel, 4 [1100,N,4,4]
else:
assert reference_points.shape[-1] == 2
reference_points_input = reference_points[:, :, None] * valid_ratios[None, :]
query_sine_embed = gen_sineembed_for_position(reference_points_input[:, :, 0, :]) # nq, bs, 256*2 # 对reference_points_input[:, :, 0, :] [1100,N,4] 中的x,y,w,h分别做位置编码->[1100,N,512]
else:
query_sine_embed = gen_sineembed_for_position(reference_points) # nq, bs, 256*2
reference_points_input = None
# conditional query
raw_query_pos = self.ref_point_head(query_sine_embed) # nq, bs, 256 # Linear(512,256) Linear(256,256) [1100,N,512]->[1100,N,256]
pos_scale = self.query_scale(output) if self.query_scale is not None else 1
query_pos = pos_scale * raw_query_pos
if not self.deformable_decoder:
query_sine_embed = query_sine_embed[..., :self.d_model] * self.query_pos_sine_scale(output)
# modulated HW attentions
if not self.deformable_decoder and self.modulate_hw_attn:
refHW_cond = self.ref_anchor_head(output).sigmoid() # nq, bs, 2
query_sine_embed[..., self.d_model // 2:] *= (refHW_cond[..., 0] / reference_points[..., 2]).unsqueeze(-1)
query_sine_embed[..., :self.d_model // 2] *= (refHW_cond[..., 1] / reference_points[..., 3]).unsqueeze(-1)
# random drop some layers if needed
dropflag = False
if self.dec_layer_dropout_prob is not None:
prob = random.random()
if prob < self.dec_layer_dropout_prob[layer_id]:
dropflag = True
if not dropflag:
output = layer(
tgt = output, # [1100,N,256]
tgt_query_pos = query_pos,# [1100,N,256]
tgt_query_sine_embed = query_sine_embed,# [1100,N,512]
tgt_key_padding_mask = tgt_key_padding_mask, # None
tgt_reference_points = reference_points_input,# [1100,N,4,4]
memory = memory, # [9350,N,256]
memory_key_padding_mask = memory_key_padding_mask, #[N,9350]
memory_level_start_index = level_start_index, # [4]
memory_spatial_shapes = spatial_shapes, # [4,2]
memory_pos = pos,# [9350,N,256]
self_attn_mask = tgt_mask, #[1100,1100]
cross_attn_mask = memory_mask # None
)
# iter update
if self.bbox_embed is not None:
reference_before_sigmoid = inverse_sigmoid(reference_points)
delta_unsig = self.bbox_embed[layer_id](output) # Linear(256,256) Linear(256,256) Linear(256,4) [1100,N,256] -> [1100,N,4]
outputs_unsig = delta_unsig + reference_before_sigmoid
new_reference_points = outputs_unsig.sigmoid()
# select # ref points
if self.dec_layer_number is not None and layer_id != self.num_layers - 1:
nq_now = new_reference_points.shape[0]
select_number = self.dec_layer_number[layer_id + 1]
if nq_now != select_number:
class_unselected = self.class_embed[layer_id](output) # nq, bs, 91
topk_proposals = torch.topk(class_unselected.max(-1)[0], select_number, dim=0)[1] # new_nq, bs
new_reference_points = torch.gather(new_reference_points, 0, topk_proposals.unsqueeze(-1).repeat(1, 1, 4)) # unsigmoid
if self.rm_detach and 'dec' in self.rm_detach:
reference_points = new_reference_points
else:
reference_points = new_reference_points.detach() # [1100,N,4]
if self.use_detached_boxes_dec_out:
ref_points.append(reference_points)
else:
ref_points.append(new_reference_points)
intermediate.append(self.norm(output))
if self.dec_layer_number is not None and layer_id != self.num_layers - 1:
if nq_now != select_number:
output = torch.gather(output, 0, topk_proposals.unsqueeze(-1).repeat(1, 1, self.d_model)) # unsigmoid
return [
[itm_out.transpose(0, 1) for itm_out in intermediate],
[itm_refpoint.transpose(0, 1) for itm_refpoint in ref_points]
]N个batch上1100个4维的位置信息,分别代表x,y,w,h,通过gen_sineembed_for_position()分别对他们进行位置编码,query_sine_embed的维度由reference_points_input[:, :, 0, :]的[1100,N,4]变为[1100,N,512]。直接把DETR的postional query显示地建模为四维的框(x,y,w,h),同时每一层的decoder都会去预测相对偏移量 (Δx,Δy,Δw,Δh) ,并去更新检测框,得到更加精确的检测框预测: (x',y'w',h') =(x,y,w,h)+ (Δx,Δy,Δw,Δh),动态更新这个检测框,并用它来帮助decoder的cross-attention来抽取feature。
query_sine_embed再经过两个Linear层得到query_pos维度由[1100,N,512]->[1100,N,256]。
if self.deformable_decoder:
if reference_points.shape[-1] == 4:
reference_points_input = reference_points[:, :, None] \
* torch.cat([valid_ratios, valid_ratios], -1)[None, :] # nq, bs, nlevel, 4 [1100,N,4,4]
else:
assert reference_points.shape[-1] == 2
reference_points_input = reference_points[:, :, None] * valid_ratios[None, :]
query_sine_embed = gen_sineembed_for_position(reference_points_input[:, :, 0, :]) # nq, bs, 256*2 # 对reference_points_input[:, :, 0, :] [1100,N,4] 中的x,y,w,h分别做位置编码->[1100,N,512]
else:
query_sine_embed = gen_sineembed_for_position(reference_points) # nq, bs, 256*2
reference_points_input = None
# conditional query
raw_query_pos = self.ref_point_head(query_sine_embed) # nq, bs, 256 # Linear(512,256) Linear(256,256) [1100,N,512]->[1100,N,256]
pos_scale = self.query_scale(output) if self.query_scale is not None else 1
query_pos = pos_scale * raw_query_pos
class DeformableTransformerDecoderLayer(nn.Module):
def __init__(self, d_model=256, d_ffn=1024,
dropout=0.1, activation="relu",
n_levels=4, n_heads=8, n_points=4,
use_deformable_box_attn=False,
box_attn_type='roi_align',
key_aware_type=None,
decoder_sa_type='ca',
module_seq=['sa', 'ca', 'ffn'],
):
super().__init__()
self.module_seq = module_seq
assert sorted(module_seq) == ['ca', 'ffn', 'sa']
# cross attention
if use_deformable_box_attn:
self.cross_attn = MSDeformableBoxAttention(d_model, n_levels, n_heads, n_boxes=n_points, used_func=box_attn_type)
else:
self.cross_attn = MSDeformAttn(d_model, n_levels, n_heads, n_points)
self.dropout1 = nn.Dropout(dropout)
self.norm1 = nn.LayerNorm(d_model)
# self attention
self.self_attn = nn.MultiheadAttention(d_model, n_heads, dropout=dropout)
self.dropout2 = nn.Dropout(dropout)
self.norm2 = nn.LayerNorm(d_model)
# ffn
self.linear1 = nn.Linear(d_model, d_ffn)
self.activation = _get_activation_fn(activation, d_model=d_ffn, batch_dim=1)
self.dropout3 = nn.Dropout(dropout)
self.linear2 = nn.Linear(d_ffn, d_model)
self.dropout4 = nn.Dropout(dropout)
self.norm3 = nn.LayerNorm(d_model)
self.key_aware_type = key_aware_type
self.key_aware_proj = None
self.decoder_sa_type = decoder_sa_type
assert decoder_sa_type in ['sa', 'ca_label', 'ca_content']
if decoder_sa_type == 'ca_content':
self.self_attn = MSDeformAttn(d_model, n_levels, n_heads, n_points)
def rm_self_attn_modules(self):
self.self_attn = None
self.dropout2 = None
self.norm2 = None
@staticmethod
def with_pos_embed(tensor, pos):
return tensor if pos is None else tensor + pos
def forward_ffn(self, tgt):
tgt2 = self.linear2(self.dropout3(self.activation(self.linear1(tgt))))
tgt = tgt + self.dropout4(tgt2)
tgt = self.norm3(tgt)
return tgt
def forward_sa(self,
# for tgt
tgt: Optional[Tensor], # nq, bs, d_model
tgt_query_pos: Optional[Tensor] = None, # pos for query. MLP(Sine(pos))
tgt_query_sine_embed: Optional[Tensor] = None, # pos for query. Sine(pos)
tgt_key_padding_mask: Optional[Tensor] = None,
tgt_reference_points: Optional[Tensor] = None, # nq, bs, 4
# for memory
memory: Optional[Tensor] = None, # hw, bs, d_model
memory_key_padding_mask: Optional[Tensor] = None,
memory_level_start_index: Optional[Tensor] = None, # num_levels
memory_spatial_shapes: Optional[Tensor] = None, # bs, num_levels, 2
memory_pos: Optional[Tensor] = None, # pos for memory
# sa
self_attn_mask: Optional[Tensor] = None, # mask used for self-attention
cross_attn_mask: Optional[Tensor] = None, # mask used for cross-attention
):
# self attention
if self.self_attn is not None:
if self.decoder_sa_type == 'sa':
q = k = self.with_pos_embed(tgt, tgt_query_pos)
tgt2 = self.self_attn(q, k, tgt, attn_mask=self_attn_mask)[0]
tgt = tgt + self.dropout2(tgt2)
tgt = self.norm2(tgt)
elif self.decoder_sa_type == 'ca_label':
bs = tgt.shape[1]
k = v = self.label_embedding.weight[:, None, :].repeat(1, bs, 1)
tgt2 = self.self_attn(tgt, k, v, attn_mask=self_attn_mask)[0]
tgt = tgt + self.dropout2(tgt2)
tgt = self.norm2(tgt)
elif self.decoder_sa_type == 'ca_content':
tgt2 = self.self_attn(self.with_pos_embed(tgt, tgt_query_pos).transpose(0, 1),
tgt_reference_points.transpose(0, 1).contiguous(),
memory.transpose(0, 1), memory_spatial_shapes, memory_level_start_index, memory_key_padding_mask).transpose(0, 1)
tgt = tgt + self.dropout2(tgt2)
tgt = self.norm2(tgt)
else:
raise NotImplementedError("Unknown decoder_sa_type {}".format(self.decoder_sa_type))
return tgt
def forward_ca(self,
# for tgt
tgt: Optional[Tensor], # nq, bs, d_model
tgt_query_pos: Optional[Tensor] = None, # pos for query. MLP(Sine(pos))
tgt_query_sine_embed: Optional[Tensor] = None, # pos for query. Sine(pos)
tgt_key_padding_mask: Optional[Tensor] = None,
tgt_reference_points: Optional[Tensor] = None, # nq, bs, 4
# for memory
memory: Optional[Tensor] = None, # hw, bs, d_model
memory_key_padding_mask: Optional[Tensor] = None,
memory_level_start_index: Optional[Tensor] = None, # num_levels
memory_spatial_shapes: Optional[Tensor] = None, # bs, num_levels, 2
memory_pos: Optional[Tensor] = None, # pos for memory
# sa
self_attn_mask: Optional[Tensor] = None, # mask used for self-attention
cross_attn_mask: Optional[Tensor] = None, # mask used for cross-attention
):
# cross attention
if self.key_aware_type is not None:
if self.key_aware_type == 'mean':
tgt = tgt + memory.mean(0, keepdim=True)
elif self.key_aware_type == 'proj_mean':
tgt = tgt + self.key_aware_proj(memory).mean(0, keepdim=True)
else:
raise NotImplementedError("Unknown key_aware_type: {}".format(self.key_aware_type))
tgt2 = self.cross_attn(self.with_pos_embed(tgt, tgt_query_pos).transpose(0, 1),
tgt_reference_points.transpose(0, 1).contiguous(),
memory.transpose(0, 1), memory_spatial_shapes, memory_level_start_index, memory_key_padding_mask).transpose(0, 1)
tgt = tgt + self.dropout1(tgt2)
tgt = self.norm1(tgt)
return tgt
def forward(self,
# for tgt
tgt: Optional[Tensor], # nq, bs, d_model
tgt_query_pos: Optional[Tensor] = None, # pos for query. MLP(Sine(pos))
tgt_query_sine_embed: Optional[Tensor] = None, # pos for query. Sine(pos)
tgt_key_padding_mask: Optional[Tensor] = None,
tgt_reference_points: Optional[Tensor] = None, # nq, bs, 4
# for memory
memory: Optional[Tensor] = None, # hw, bs, d_model
memory_key_padding_mask: Optional[Tensor] = None,
memory_level_start_index: Optional[Tensor] = None, # num_levels
memory_spatial_shapes: Optional[Tensor] = None, # bs, num_levels, 2
memory_pos: Optional[Tensor] = None, # pos for memory
# sa
self_attn_mask: Optional[Tensor] = None, # mask used for self-attention
cross_attn_mask: Optional[Tensor] = None, # mask used for cross-attention
):
# tgt [1100,N,256],tgt_query_pos [1100,N,256],tgt_query_sine_embed [1100,N,512],tgt_reference_points [1100,N,4,4],memory [9350,N,256],memory_key_padding_mask [N,9350],memory_level_start_index [4],memory_spatial_shapes [4,2],memory_pos [9350,N,256],self_attn_mask [1100,1100]
for funcname in self.module_seq:
if funcname == 'ffn':
tgt = self.forward_ffn(tgt)
elif funcname == 'ca':
tgt = self.forward_ca(tgt, tgt_query_pos, tgt_query_sine_embed, \
tgt_key_padding_mask, tgt_reference_points, \
memory, memory_key_padding_mask, memory_level_start_index, \
memory_spatial_shapes, memory_pos, self_attn_mask, cross_attn_mask)
elif funcname == 'sa':
tgt = self.forward_sa(tgt, tgt_query_pos, tgt_query_sine_embed, \
tgt_key_padding_mask, tgt_reference_points, \
memory, memory_key_padding_mask, memory_level_start_index, \
memory_spatial_shapes, memory_pos, self_attn_mask, cross_attn_mask)
else:
raise ValueError('unknown funcname {}'.format(funcname))
return tgt图解:
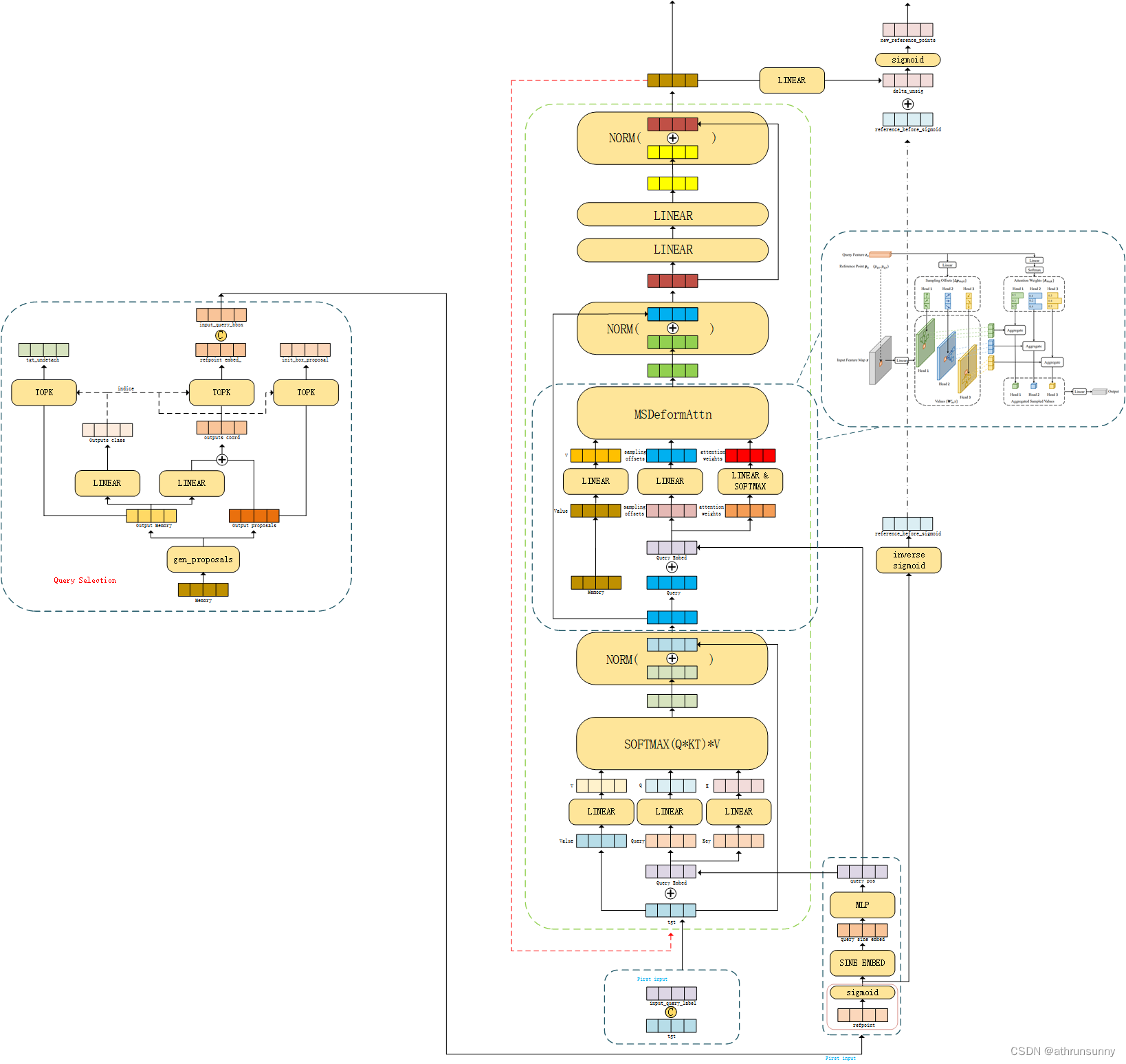
MSDeformAttn:
class MSDeformAttn(nn.Module):
def __init__(self, d_model=256, n_levels=4, n_heads=8, n_points=4):
"""
Multi-Scale Deformable Attention Module
:param d_model hidden dimension
:param n_levels number of feature levels
:param n_heads number of attention heads
:param n_points number of sampling points per attention head per feature level
"""
super().__init__()
if d_model % n_heads != 0:
raise ValueError('d_model must be divisible by n_heads, but got {} and {}'.format(d_model, n_heads))
_d_per_head = d_model // n_heads
# you'd better set _d_per_head to a power of 2 which is more efficient in our CUDA implementation
if not _is_power_of_2(_d_per_head):
warnings.warn("You'd better set d_model in MSDeformAttn to make the dimension of each attention head a power of 2 "
"which is more efficient in our CUDA implementation.")
self.im2col_step = 64
self.d_model = d_model
self.n_levels = n_levels
self.n_heads = n_heads
self.n_points = n_points
self.sampling_offsets = nn.Linear(d_model, n_heads * n_levels * n_points * 2)
self.attention_weights = nn.Linear(d_model, n_heads * n_levels * n_points)
self.value_proj = nn.Linear(d_model, d_model)
self.output_proj = nn.Linear(d_model, d_model)
self._reset_parameters()
def _reset_parameters(self):
constant_(self.sampling_offsets.weight.data, 0.)
thetas = torch.arange(self.n_heads, dtype=torch.float32) * (2.0 * math.pi / self.n_heads)
grid_init = torch.stack([thetas.cos(), thetas.sin()], -1)
grid_init = (grid_init / grid_init.abs().max(-1, keepdim=True)[0]).view(self.n_heads, 1, 1, 2).repeat(1, self.n_levels, self.n_points, 1)
for i in range(self.n_points):
grid_init[:, :, i, :] *= i + 1
with torch.no_grad():
self.sampling_offsets.bias = nn.Parameter(grid_init.view(-1))
constant_(self.attention_weights.weight.data, 0.)
constant_(self.attention_weights.bias.data, 0.)
xavier_uniform_(self.value_proj.weight.data)
constant_(self.value_proj.bias.data, 0.)
xavier_uniform_(self.output_proj.weight.data)
constant_(self.output_proj.bias.data, 0.)
def forward(self, query, reference_points, input_flatten, input_spatial_shapes, input_level_start_index, input_padding_mask=None):
"""
:param query (N, Length_{query}, C)
:param reference_points (N, Length_{query}, n_levels, 2), range in [0, 1], top-left (0,0), bottom-right (1, 1), including padding area
or (N, Length_{query}, n_levels, 4), add additional (w, h) to form reference boxes
:param input_flatten (N, \sum_{l=0}^{L-1} H_l \cdot W_l, C)
:param input_spatial_shapes (n_levels, 2), [(H_0, W_0), (H_1, W_1), ..., (H_{L-1}, W_{L-1})]
:param input_level_start_index (n_levels, ), [0, H_0*W_0, H_0*W_0+H_1*W_1, H_0*W_0+H_1*W_1+H_2*W_2, ..., H_0*W_0+H_1*W_1+...+H_{L-1}*W_{L-1}]
:param input_padding_mask (N, \sum_{l=0}^{L-1} H_l \cdot W_l), True for padding elements, False for non-padding elements
:return output (N, Length_{query}, C)
"""
N, Len_q, _ = query.shape # Len_q9350/1100
N, Len_in, _ = input_flatten.shape # Len_in9350
assert (input_spatial_shapes[:, 0] * input_spatial_shapes[:, 1]).sum() == Len_in
value = self.value_proj(input_flatten) # 输入经过一个Linear层,维度由[N,Len_in,256] -> [N,Len_in,256],得到value
if input_padding_mask is not None:
value = value.masked_fill(input_padding_mask[..., None], float(0)) # 在value中,mask中对应元素为True的位置都用0填充
value = value.view(N, Len_in, self.n_heads, self.d_model // self.n_heads) # value的shape由[N,Len_in,256] -> [N,Len_in,8,32]
sampling_offsets = self.sampling_offsets(query).view(N, Len_q, self.n_heads, self.n_levels, self.n_points, 2) # 每个query产生对应不同head不同level的偏置,sampling_offsets的shape由[N,Len_q,256] -> [N,Len_q,8,4,4,2]
attention_weights = self.attention_weights(query).view(N, Len_q, self.n_heads, self.n_levels * self.n_points) # 每个偏置向量的权重,经过Linear(256,128),attention_weights的shape由[N,Len_q,256] -> [N,Len_q,8,16]
attention_weights = F.softmax(attention_weights, -1).view(N, Len_q, self.n_heads, self.n_levels, self.n_points) # 对属于同一个query的来自与不同level的offset后向量权重在每个head分别归一化,softmax后attention_weights的shape由[N,Len_q,8,16] -> [N,Len_q,8,4,4]
# N, Len_q, n_heads, n_levels, n_points, 2
if reference_points.shape[-1] == 2:
offset_normalizer = torch.stack([input_spatial_shapes[..., 1], input_spatial_shapes[..., 0]], -1) # offset_normalizer 将input_spatial_shapes中[H,W]的形式转化为[W,H],input_spatial_shapes的shape还是[4,2]
sampling_locations = reference_points[:, :, None, :, None, :] \
+ sampling_offsets / offset_normalizer[None, None, None, :, None, :] # 采样点的坐标[N,Len_q,8,4,4,2]
elif reference_points.shape[-1] == 4:
sampling_locations = reference_points[:, :, None, :, None, :2] \
+ sampling_offsets / self.n_points * reference_points[:, :, None, :, None, 2:] * 0.5
else:
raise ValueError(
'Last dim of reference_points must be 2 or 4, but get {} instead.'.format(reference_points.shape[-1]))
# for amp
if value.dtype == torch.float16:
# for mixed precision
output = MSDeformAttnFunction.apply(
value.to(torch.float32), input_spatial_shapes, input_level_start_index, sampling_locations.to(torch.float32), attention_weights, self.im2col_step)
output = output.to(torch.float16)
output = self.output_proj(output)
return output
output = MSDeformAttnFunction.apply(
value, input_spatial_shapes, input_level_start_index, sampling_locations, attention_weights, self.im2col_step)
output = self.output_proj(output) # 输出经过一个Linear层,维度由[N,Len_q,256] -> [N,Len_q,256]
return output源码中n_head设置为8,d_model为256,n_levels为4,n_points为4。
MSDeformAttn函数就是将加了pos_embeds的srcs作为query传入,每一个query在特征图上对应一个reference_point,基于每个reference_point再选取n = 4个keys,根据Linear生成的attention_weights进行特征融合(注意力权重不是Q * k算来的,而是对query直接Linear得到的)。sampling_offsets,attention_weights的具体信息在上面的代码段中有标注
deformable transformer的图解(来自Deformable-DETR):

MSDeformAttnFunction调用的是cuda编程,不过代码里头有一个pytorch的实现:
def ms_deform_attn_core_pytorch(value, value_spatial_shapes, sampling_locations, attention_weights):
# for debug and test only,
# need to use cuda version instead
N_, S_, M_, D_ = value.shape # value shpae [N,len_q,8,32]
_, Lq_, M_, L_, P_, _ = sampling_locations.shape # shape [N,len_q,8,4,4,2]
value_list = value.split([H_ * W_ for H_, W_ in value_spatial_shapes], dim=1) # 区分每个feature map level
sampling_grids = 2 * sampling_locations - 1
sampling_value_list = []
for lid_, (H_, W_) in enumerate(value_spatial_shapes):
# N_, H_*W_, M_, D_ -> N_, H_*W_, M_*D_ -> N_, M_*D_, H_*W_ -> N_*M_, D_, H_, W_
value_l_ = value_list[lid_].flatten(2).transpose(1, 2).reshape(N_*M_, D_, H_, W_) # [N,H_*W_,8,32] -> [N*8,32,H_,W_]
# N_, Lq_, M_, P_, 2 -> N_, M_, Lq_, P_, 2 -> N_*M_, Lq_, P_, 2
sampling_grid_l_ = sampling_grids[:, :, :, lid_].transpose(1, 2).flatten(0, 1)
# N_*M_, D_, Lq_, P_
# F.grid_sample这个函数的作用就是给定输入input和网格grid,根据grid中的像素位置从input中取出对应位置的值(可能需要插值)得到输出output。
sampling_value_l_ = F.grid_sample(value_l_, sampling_grid_l_,
mode='bilinear', padding_mode='zeros', align_corners=False)
sampling_value_list.append(sampling_value_l_)
# (N_, Lq_, M_, L_, P_) -> (N_, M_, Lq_, L_, P_) -> (N_, M_, 1, Lq_, L_*P_)
attention_weights = attention_weights.transpose(1, 2).reshape(N_*M_, 1, Lq_, L_*P_) # shape [N,len_q,8,4,4] -> [N*8,1,len_q,16]
output = (torch.stack(sampling_value_list, dim=-2).flatten(-2) * attention_weights).sum(-1).view(N_, M_*D_, Lq_) # 对应上论文中的公式
return output.transpose(1, 2).contiguous()
#########################################################
# Begin postprocess
#########################################################
if self.two_stage_type == 'standard':
if self.two_stage_keep_all_tokens:
hs_enc = output_memory.unsqueeze(0)
ref_enc = enc_outputs_coord_unselected.unsqueeze(0)
init_box_proposal = output_proposals
else:
hs_enc = tgt_undetach.unsqueeze(0) # [1,N,900,256]
ref_enc = refpoint_embed_undetach.sigmoid().unsqueeze(0) # [1,N,900,4]
else:
hs_enc = ref_enc = None
#########################################################
# End postprocess
# hs_enc: (n_enc+1, bs, nq, d_model) or (1, bs, nq, d_model) or (n_enc, bs, nq, d_model) or None
# ref_enc: (n_enc+1, bs, nq, query_dim) or (1, bs, nq, query_dim) or (n_enc, bs, nq, d_model) or None
#########################################################
decoder输出:
1、hs [N,1100,256]*6,
2、reference [N,1100,4]*7,
3、hs_enc [1,N,900,256],
4、ref_enc [1,N,900,4],
5、init_box_proposal [N,900,4]
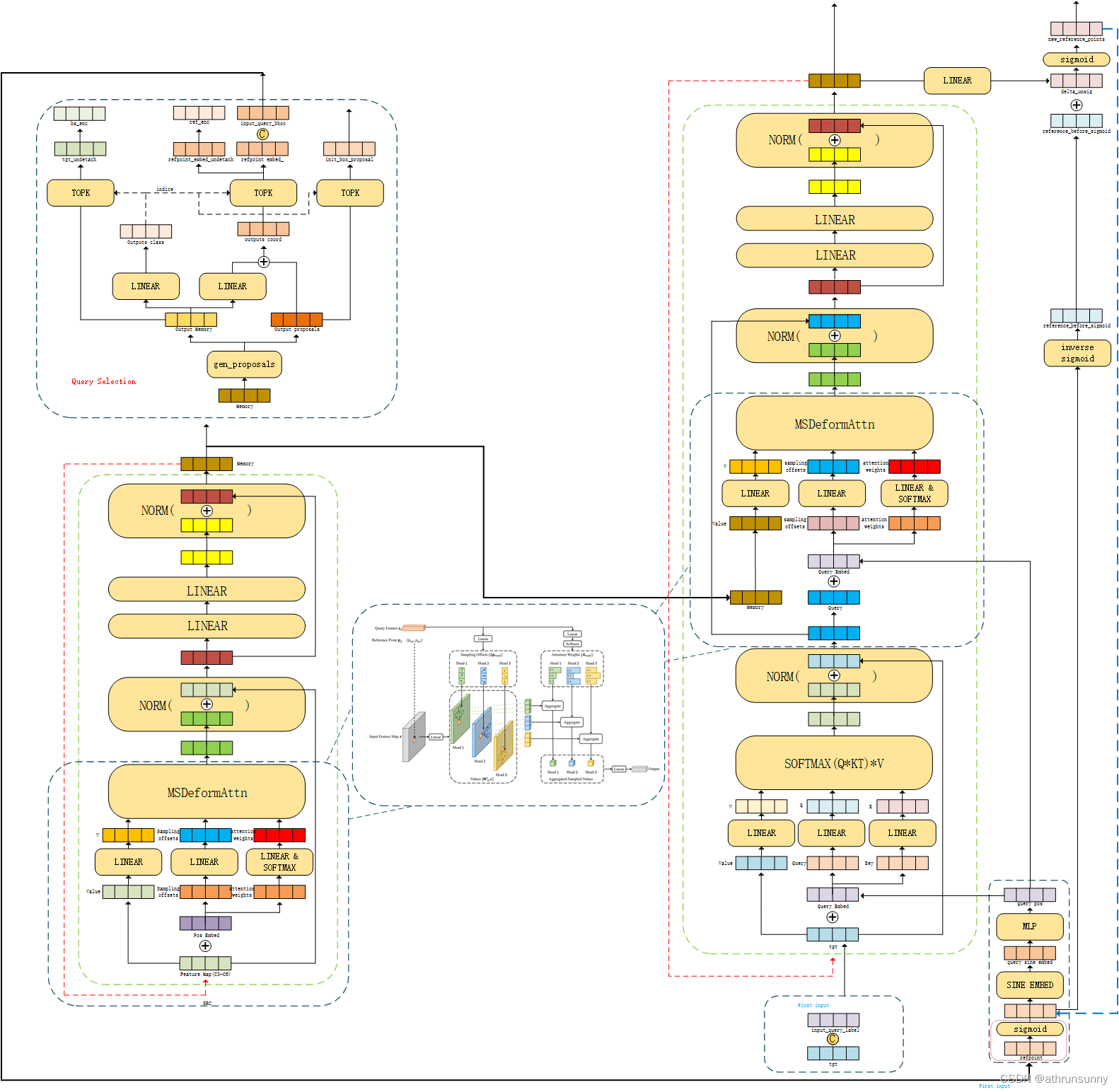
完整流程图解:
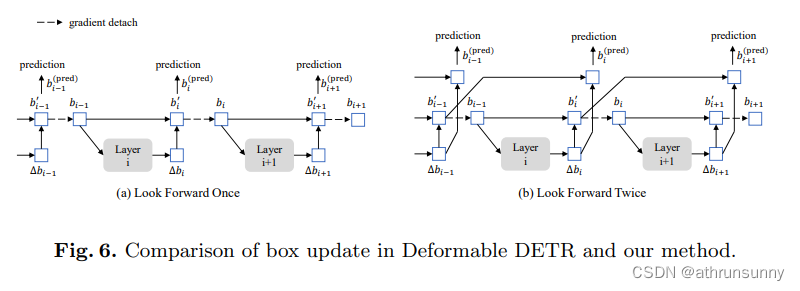
还有一个点,论文中提到的Look Forward Twice,在Deformable DETR中的迭代边界框精化方法会阻止梯度反向传播,以稳定训练过程。我们将该方法命名为look forward once,因为第i层的参数仅基于辅助损失函数bi的更新,如图6 (a)所示。然而,我们猜想,来自后续层的改进的边界框信息可能对纠正相邻的早期层的边界框预测更有帮助。因此,我们提出了另一种称为look forward twice的方法来进行边界框更新,其中第i层的参数受到第i层和第(i + 1)层损失的影响,如图6 (b)所示。对于每个预测的偏移量∆bi,它将用于更新边界框两次
hs, reference, hs_enc, ref_enc, init_box_proposal = self.transformer(srcs, masks, input_query_bbox, poss,input_query_label,attn_mask)
# In case num object=0 hs [N,1100,256]*6, reference [N,1100,4]*7, hs_enc [1,N,900,256], ref_enc [1,N,900,4], init_box_proposal [N,900,4]
hs[0] += self.label_enc.weight[0,0]*0.0
# deformable-detr-like anchor update
# reference_before_sigmoid = inverse_sigmoid(reference[:-1]) # n_dec, bs, nq, 4
outputs_coord_list = []
for dec_lid, (layer_ref_sig, layer_bbox_embed, layer_hs) in enumerate(zip(reference[:-1], self.bbox_embed, hs)):
layer_delta_unsig = layer_bbox_embed(layer_hs) # layer_bbox_embed Linear(256,256) Linear(256,256) Linear(256,4) [N,1100,4]
layer_outputs_unsig = layer_delta_unsig + inverse_sigmoid(layer_ref_sig)
layer_outputs_unsig = layer_outputs_unsig.sigmoid()
outputs_coord_list.append(layer_outputs_unsig)
outputs_coord_list = torch.stack(outputs_coord_list) # [6,N,1100,4]这里将当前层的输出经过Linear后加上前一层输出的refence points