许多分类数据集是按照文件夹名字命名类别的,比如VOC数据集:

以我自己的数据集为例,分析各个类别之间的数据平衡情况,用以下脚本实现:
import os
import matplotlib.pyplot as plt
path = 'soybeanleaf'
dirs = os.listdir(path)
num_dir = len(dirs)
num = []
for i in range(num_dir):
file_i = os.listdir(path + '/'+ dirs[i])
num.append(len(file_i))
print(dirs)
print(num)
d = dict(zip(dirs,num))
sort_d = sorted(d.items(),key = lambda item:item[1],reverse = True)
x = []
y = []
for it in sort_d:
x.append(it[0])
y.append(it[1])
plt.barh(x[0:num_dir],y[0:num_dir])
plt.yticks(fontproperties = 'Times New Roman', size = 2)
plt.savefig('leafdir.png',dpi=300)
脚本输出子文件夹的名称,以及对应文件夹下的文件个数

同时,将该数据集进行数据分布统计,画出条形图:
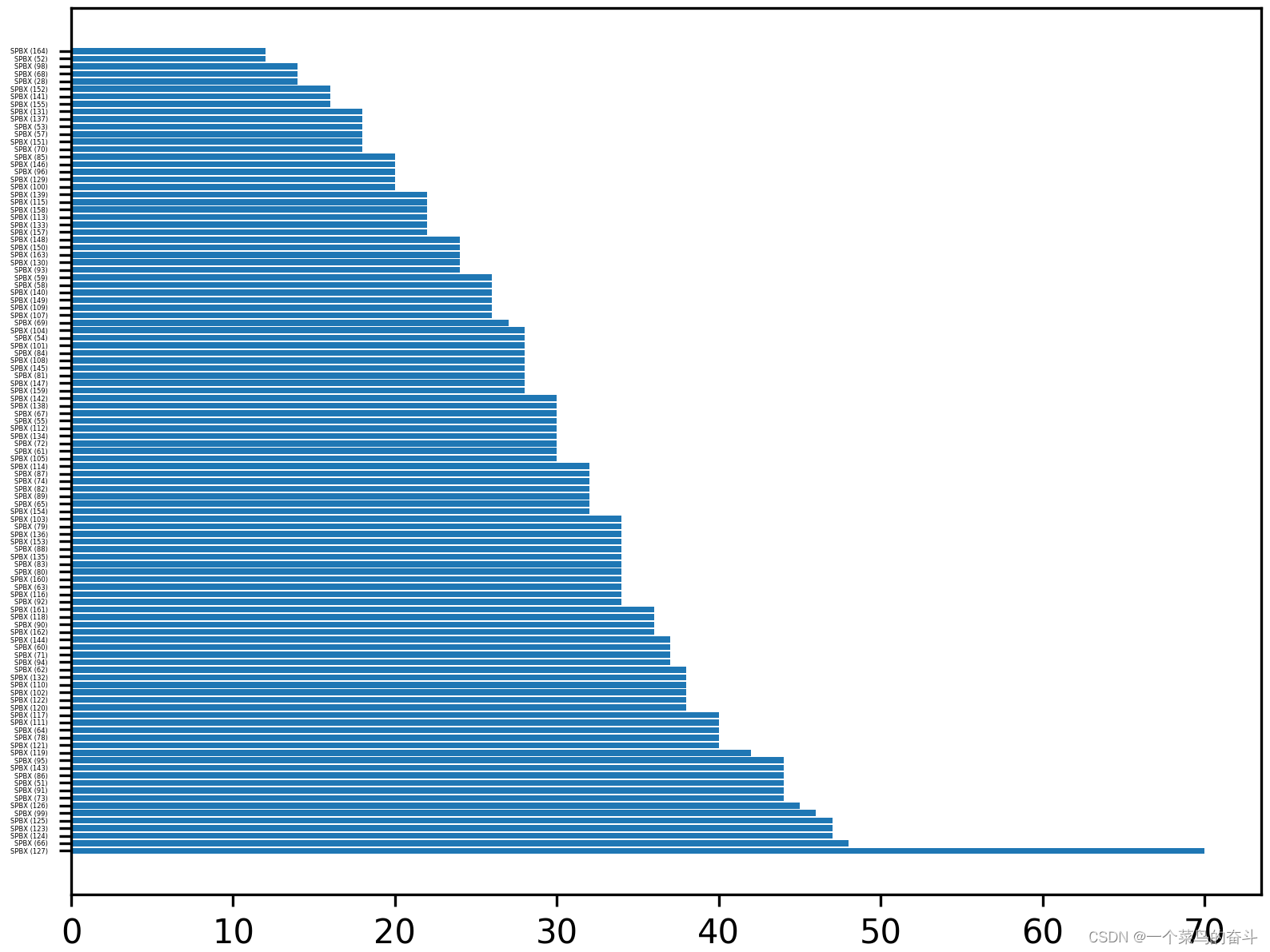
从以上结果,可以分析出该数据集各个类别的数据分布情况,哪些类别数据较多,哪些类别数据较少,可以针对该情况,对算法分类结果进行分析。