背景
近几年AI,ML,HPC大火, 针对这些场景的存储技术及方案也逐步衍生出两个分支,第一支:以Lustre,BeeGFS等为代表的分布式并行文件系统, 这些文件系统对POSIX提供了很好的支持,各种业务可以不经改造无缝运行,提供了很好的兼容性;第二支:以Gekkofs,HadaFS为代表的缓存系统Burst Buffer(BB),这些系统都提供弱(宽松)语义的POSIX支持,通过自定义的客户端对上层业务提供文件访问能力,需要对上层的业务进行针对性的改造及适配,因为专门针对这些场景进行了优化,相对的也提供了更优的性能。
HadaFS
HadaFS是国家超算中心(无锡)联合多家高校设计实现的一款专为超算打造的宽松POSIX缓存系统(BB),下文是对HadaFS的技术解读
概述
Burst Buffer(BB)根据部署位置的不同,分为本地BB和共享BB,
- 本地BB, 部署在计算节点的SSD上,专职服务于本节点,扩展性和性能要更好些,但是不适合用于N-1的共享数据场景,另外因为共享部署,不同I/O模型/负载的业务相互干扰,可能导致巨大的资源浪费,最后随着计算节点的升级,部署成本也会快速增加。代表产品有Luster的LPCC,BeeGFS的BeeOND。
- 共享BB,部署在专用的节点上,它的优势是可以实现数据共享以及具有更优的部署成本,但是在支持拥有数以万计客户端的超大规模计算集群上面临挑战。
两种BB各有优劣,而相比传统的文件系统,BB的性能都较高,但是容量较小,所以BB通常和文件系统配合使用。但随着E级超算时代的到来,并发I/O的需求急剧增加,同时超算应用的I/O也更多样,这给当前的BB系统带来了巨大的挑战,并暴露出如下的不足
- BB的扩展性与应用行为的不匹配, E级超算数以万计的并发I/O给BB系统的扩展性带来挑战,AI及ML等共享数据的应用及工作流对I/O提出新的要求,大规模数据的高速共享变得愈发的重要。如:神威太湖之光使用的Luster LPCC本地BB,在数据共享以及元数据访问密集的情况下就比较低效(为保证强语义的一致性,BB中的数据需要回写到Lustre后,才能共享)。
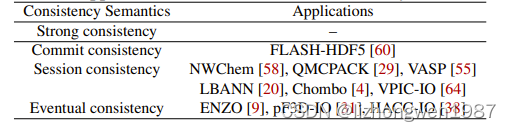
- 复杂的元数据管理与应用行为的不匹配,传统的文件系统为通用场景而设计,基于标准的目录树管理及POSIX协议实现。而HPC场景,通常只进行文件的读写,很少进行(复杂的)目录树管理。所以采用宽松的POSIX协议是一个更好的选择,但由于HPC应用的多样,如何实现“宽松”也存在很大的挑战。下表展示了典型HPC应用的POSIX语义要求,越上面的,一致性越高,性能损耗也越大。
- 低效的数据管理,由于BB的容量要远远小于后端的FS,其通常作为计算和FS间的非持久性加速缓存发挥作用,因此BB和FS间高效便捷的数据迁移就变得非常的重要,它们间的数据迁移通分为两种:透明迁移和非透明迁移,透明迁移是在软件层面实现自动的数据迁移,很方便但可能带来大量的无效数据迁移;非透明迁移,通常需要计算节点参与,过程中可能因为计算的空闲而导致资源浪费。两种方式都支持FS到BB的预加载,实现预读功能。但是两种方式都不支持计算任务运行时的数据迁移管理。
HadaFS架构
HadaFS包括客户端,服务端,数据管理工具三个主要子系统。HadaFS属于共享BB,服务端运行在部署有NVMe SSD的专有节点上,提供全局的数据及元数据服务,为每个客户端提供全局试图。HadaFS实现了宽松POSIX语义,不支持mv,rename和link操作。客户端以静态或动态库的方式部署在计算节点上,负责将对应用的POSIX I/O进行解析及转发给服务端处理。数据管理工具hadash,运行在管理节点上,用于数据迁移。
HadaFS中的每个文件与两类服务发生联系,其中文件数据存储在数据服务器上NVMe介质的本地文件系统上,文件元数据存储在元数据服务器的RocksDB上。
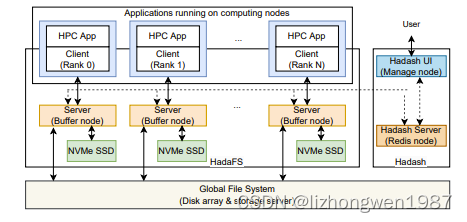
与传统的BB系统相比,HadaFS有如下特点:
本地优先架构(LTA)
文件系统的挂载通常有两种方式,第一种是内核态挂载,这种方式要求实现完整的POSIX语义,同时会带来I/O在内核态和用户态上下文切换的开销,一个挂载点可以给服务器节点上的所有应用共享;另一种是,应用直接在用户态挂载文件系统,这种方式可以规避内核态文件系统的限制,也能减少内核态和用户态切换的开销,但是太多的链接于系统的扩展性不利,也会带来稳定性风险。
HadaFS采用应用直接在用户态挂载文件系统方式为应用提供文件访问服务,为避免传统应用态挂载带来的弊端,HadaFS将一个客户端的所有链接到绑定到一个固定的服务节点(称为桥节点),该桥节点负责处理该客户端的所有I/O请求,每个用户文件对应桥节点本地NVMe SSD上的一个Ext4文件。如果客户端需要访问其他服务节点上的数据,需要通过桥节点转发(这意味着服务节点间是全互联结构)。为了提升桥节点的本地化处理(类似本地BB的模式),减小请求的转发比例,HadaFS向应用提供了三个挂载选项
- MPI_RANK, 采用round-robin的方式选择桥节点,适用于那些需要将数据提交到不同节点多次的场景。
- Node ID, 与指定的桥节点绑定,可以按照计算和BB的网络拓扑来选择就近额节点。
- 根据业务数据共享需求,自主绑定。
点评:hadafs的挂载策略为应用及存储间的最佳匹配提供了可能
命名空间及元数据管理
HadaFS舍弃了传统的目录树结构,采用全路径来索引文件。一个HadaFS文件,其数据内容存储在创建该文件的桥节点上,元数据存储在根据文件路径hash指向的K-V数据库中。HadaFS的客户端通过全路径/路径前缀来查找文件,不需要执行逐级的目录搜索。
HadaFS的文件元数据与Linux文件系统兼容,为了取得更好的扩展性和性能,HadaFS将元数据分层4个类别
- 第一类:创建文件时生成,包括:name,owner,mode等
- 第二类:访问文件时生成,包括:大小,修改时间,范围时间等
- 第三类:这类信息,HadaFS实际上不需要,包括:ino, stdev等
- 第四类:按照offset排序的文件分片位置的有序列表,包括:服务器地址,offset,size,写入时间等
每个HadaFS服务节点上包含两套元数据数据库,均基于rocksdb实现, 如下图。本地元数据库(LMDB)存储本地文件的第一类和第四类元数据(文件的本地标识LID相当于文件的本地路径),全局元数据库(GMDB)存储文件的第一类,第二类和第四类元数据,每个HadaFS文件的元数据,根据文件路径的hash只会存储到一个全局数据库。两个元数据库的键均是<UID, GID, PATH>组合的hash。UID,GID可以用来可控前缀查找的访问,提升性能。在N-N的 I/O场景下,每个客户端写独立的文件,存储在LMDB上的元数据与存储在GMDB上的第一类和第四类元数据一致,在N-1的I/O场景下,多个客户端共享访问相同文件,可能会使用不同的桥节点,GMDB负责合并多个LMDB上的元数据。
在文件读写过程中,LMDB负责记录/维护一个根据offset排序的文件分片位置列表,同时会将该元数据发送给文件所属的GMDB。GMDB负责维护文件的分片位置列表,以支持各服务节点间的全局共享。
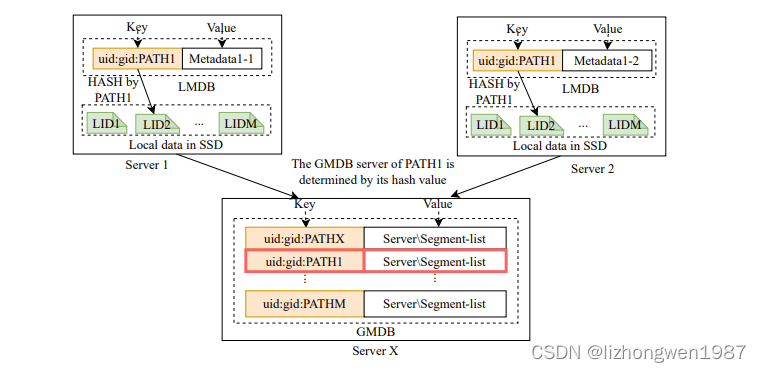
点评:通过本地LMDB存储元数据是很常规的做法,GMDB来实现全局共享是个特有的机制
I/O控制及数据流
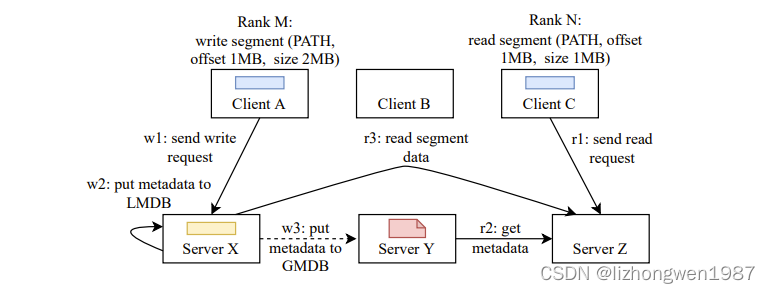
下图展示了HadaFS的数据流示例
- ClientA在ServerX上创建了一个文件,并写入数据
- ServerX将文件的第一类和第四类元数据写入LMDB
- 基于文件路径hash,ServerX将文件的元数据发送给ServerY,并存储在GMDB中
- ClientC发起读文件的请求
- ServerZ收到请求,基于文件路径hash,从ServerY获取文件的元数据
- ServerZ从ServerX读取数据,并返回给ClientC
对于那些需要经常生成checkpoint文件的应用,确保本地写和全局可读是非常有益的。对于读密集型的应用,通过挂载点控制客户端和桥节点的映射关系,尽可能减少转发I/O的可能性,从而提升性能。
点评:hadafs通过本地化提升写性能,分布式提升读性能
数据管理工具
为了避免Luster LPCC可能导致的大量临时数据的迁移,以及静态迁移的弊端,HadaFS提供了数据管理工具hadash来帮忙用户进行基于目录树的文件管理,包括:元数据查询和数据迁移
hadash通过Redis 管线将数据管理命名发送给BB节点上的数据管理模块,各节点上的数据管理模块从LMDB中获取文件,然后并行执行命令,下图显示了数据从BB迁移到GFS的流程
- 用户通过hadash UI向hadash server发起数据迁移请求
- hadash server接收请求后,将请求转发给各BB节点上的hadash agent
- hadash agent解析命令参数,从LMDB中获取文件列表,然后从本地SSD读取数据
- hadash agent将数据写入后端的GFS
- 数据写入完成后,hadash agent通过另一个redis管线返回结果,最终hadash将结果返回给用户
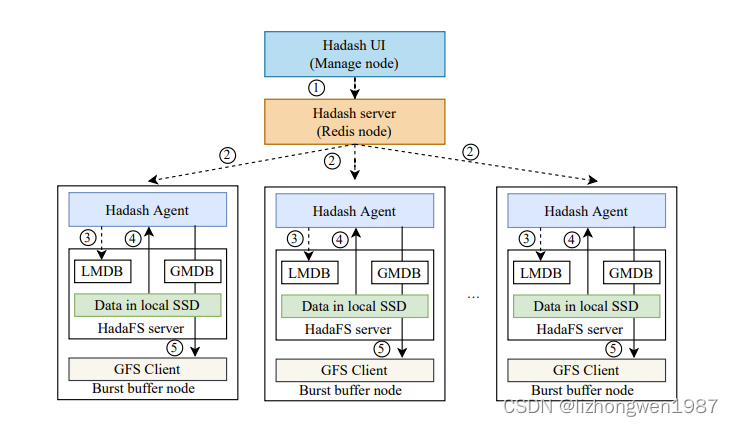
点评:hadash通过前缀匹配(消除目录树检索),以及细粒度控制和分布式迁移来提升数据迁移的准确性及效率。
一致性及元数据优化
HadaFS采用宽松POSIX语义,不提供客户端和服务端的缓存,一致性依赖于元数据的同步。HadaFS提供了三种元数据一致性语义
- 最终一致性,文件元数据先在本地LMDB更新,然后异步复制到GMDS中,可以提供最高的性能。适用于没有数据共享的场景
- 会话一致性,第一类元数据采用同步方式复制,第二类元数据采用异步方式复制
- (弱)强一致性,所有元数据同步复制到GMDS,因为不支持覆盖写一致性比强一致要弱些
由于HadaFS并不支持分布式事务,而HadaFS要求数据需要先写到本地桥节点, 在N-1的共享场景中,覆盖写也就无法支持,原子写也只在上述第三种语义才被支持。
点评:宽松POSIX语义,要求用户对应用的共享模式非常的清楚
文件共享优化
本地优先架构(LTA)对于N-N的场景非常的友好,对于N-I的共享场景,HadaFS采用后备文件的机制,每个客户端将数据写到独立的文件中,然后通过GMDB来管理各文件的元数据,并完成最终的元数据合并。这样可以将对共享文件的读写,转化为并发的读写,提升整体的性能。在没有I/O重叠的情况下,能够取得很好的效果。另外,HadaFS通过有序链表管理文件分片,读写过程中的分片管理时间复杂度为O(logN)
点评:通过降低一致性换取更高的性能
干扰避免
超算集群中,通常有很多的业务在同时运行,它们竞争争抢资源,相互干扰。得益于HadaFS的LTA架构,用户可以灵活的进行客户端和桥节点的连接管理,有效的隔离不同业务间的I/O干扰。为减轻用户使用及维护的成本,HadaFS提供了系列工具来协助完成桥节点连接管理,元数据同步等。
点评:得益于LTA架构,通过可接受的成本,隔离业务干扰
总评:HadaFS是一款融合了本地及共享BB优点,支持宽松POSIX语义的BB缓存系统,得益于其LTA架构,基于前缀的文件管理及灵活的数据迁移机制,在超大规模的超算业务中取得了很好的效果。在N-1共享场景(特别是并行场景)以及超过规模目录(特别是超过单节点scale up情况下),可能存在瓶颈。