引言
从内核角度看,Linux上有Buffered IO和Direct IO两种文件IO模式,Direct IO绕过内核缓存直接将数据写入后端设备,Buffered IO先将数据写到pagecache(内核中每个文件(inode)都包含一个address_space结构(内部通过一棵基数树来管理缓存页)来管理文件缓存),然后内核在合适的时候(内存不足、用户发起fsync、定期flush等)将数据回写到后端设备
BeeGFS客户端的文件缓存
BeeGFS客户端挂载后,会实例化一个名为beegfs的bdi设备,内核在合适的时候通过该设备发起文件系统脏页回写
BeeGFS内核客户端提供了Buffered和Native两种缓存模式,Native模式本质上是用pagecache来缓存文件数据,类似于引言中提到的Buffered IO,Buffered模式是BeeGFS的自定义缓存模式,核心思路:构建一个全局的buffer pool(默认每个buf 512KB,buf数量为cpu*4),构建一个全局的文件(inode)红黑树用于管理文件,每个文件(inode)构建一个 fileCache,动态从buffer pool申请buf用于满足文件的读写数据缓存需求,一个全局的flusher线程定期(默认5s)将红黑树中的文件(数据)回写到后端设备
BeeGFS客户端Buffered缓存
先说结论,Buffered缓存的特点是:1、不需要page对齐, 2、避免pagecache缓存的膨胀问题,3、需要处理mmap带来的缓存一致性问题
Buffered缓存初始化
- 加载客户端时,初始化名为beegfs-rwPgWQ的工作队列(workqueue_struct),用于系统级的脏页回写,关于Linux内核工作队列的内容,请查阅网络资料
- 加载客户端时,初始化名为beegfs-pageListVec的Slab内存,并基于此申请初始大小为8的内存池,用于系统级的脏页回写
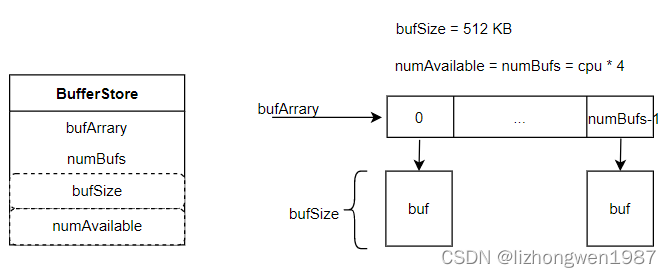
- 挂载客户端时,构建一个全局的buffer pool(NoAllocBufferStore),buffer pool是由cpu*4个,大小为512KB的buffer组成的数组,大概长这样:整个缓存空间大小为numBufs * bufSize
- 挂载客户端时,构建一个全局的inode红黑树(InodeRefStore),用于管理待回写文件的inode
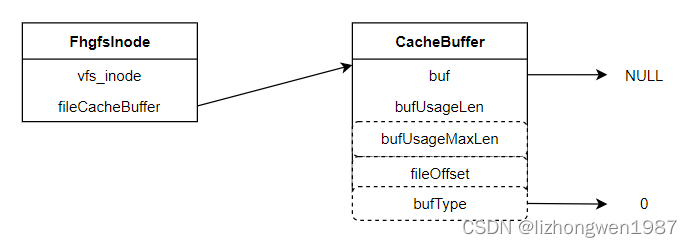
- 构建文件cache,创建文件inode时初始化fileCache(但不指向任何buffer),大概长这样:CacheBuffer包含一个指向buf的指针(也即对于每个文件而言最多只有bufSize大小的缓存),也可以很容易的推断出buffer pool,只能为numBufs个文件提供缓存
Buffered缓存的应用
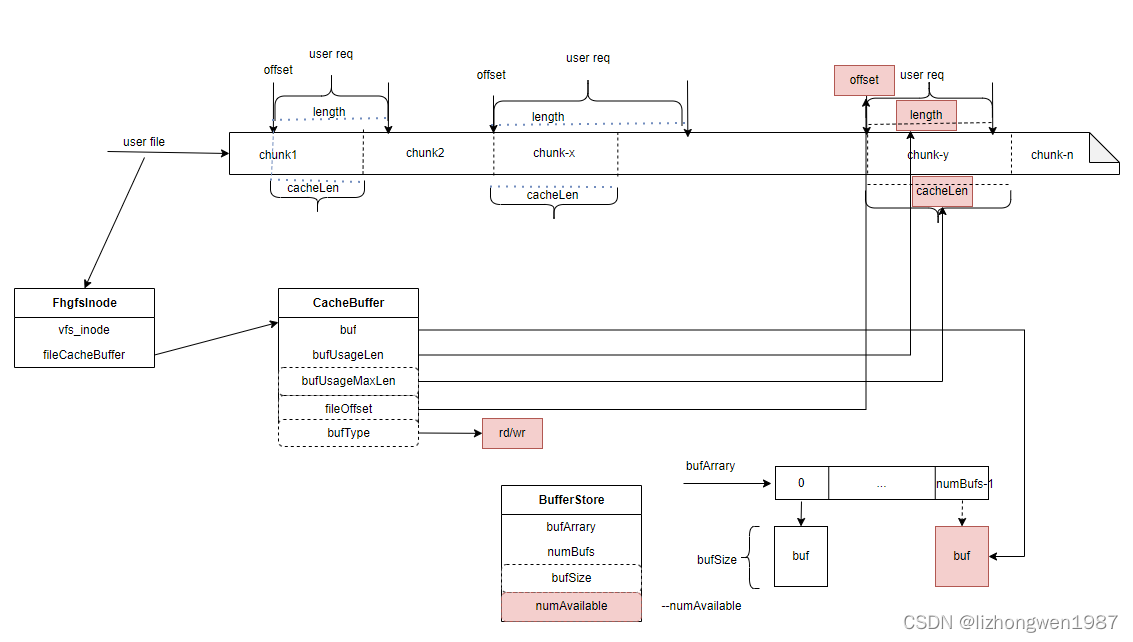
发生读写IO时,缓存的使用适用如下的原则,我们根据下图来说明:用户文件在BeeGFS中按照chunk切片存储在不同的数据节点上,假定:chunkSize == bufSize
- 左边的用户请求:用户请求<offset,length>未对齐到chunk边界,计算得到的cacheLen < length,故无法执行缓存IO
- 中间的用户请求:用户请求<offset,length>对齐到chunk边界但length大于chunkSize,计算得到cacheLen < length, 故无法执行缓存IO
- 右边的用户请求:用户请求<offset,length>对齐到chunk边界且length小于chunkSize,计算得到cacheLen > length, 故执行缓存IO:从buffer pool数组末尾获取一个buf挂接到CacheBuffer::buf, 更新CacheBuffer::fileOffset = offset, CacheBuffer:bufUsageLen = length, CacheBuffer::bufUsageMaxLen = cacheLen,并将文件inode添加到
- 第四种情况(下图未示出):如果read/write缓存发生切换(先执行了读/写IO,再进行写/读IO),需将前一次的缓存回写/丢弃(回收后)才能再次进行缓存IO,或者在发生上述第三种情况后,新的IO与缓存数据不重叠或者IO请求大小length超过bufUsageMaxLen也无法执行缓存IO,否则执行缓存IO
注:cacheLen = MIN(对齐chunk后的length, bufSize)
Buffered缓存的回收
为实现buffered模式下的脏页回收,beegfs提供了两种方式:
- 初始化的时候,会启动一个全局的flusher线程,它定期(默认5s)遍历红黑树中的inode,将CacheBuffer中的数据回写到后端设备或丢弃,并回收buf到BufferStore。(执行的是与缓存应用相反的过程)
注:回收的buffer挂接的bufArray index不一定和分配时buffer所在的bufArrary index一致
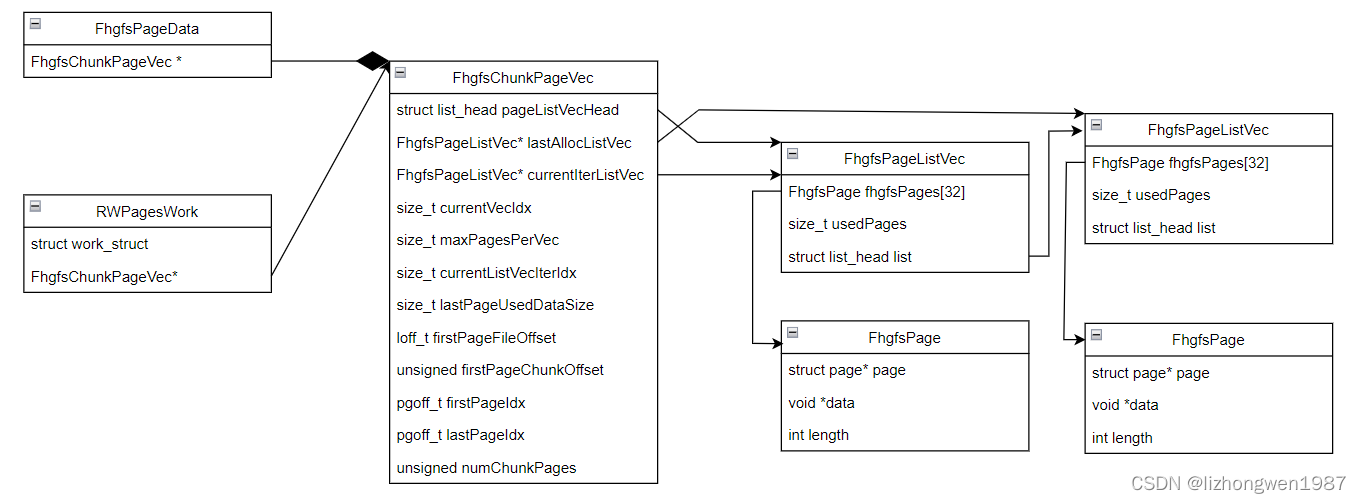
- 系统回收:系统回收发生在mmap情况下,在buffered模式下,如果有文件通过mmap映射,脏页回收由系统进行,在进行address_space页面回写过程中涉及的核心数据结构如下:FhgfsPageData是回写上下文,它包含一个可以容纳整个chunk数据的FhgfsChunkPageVec结构(页面数为numChunkPages),实际的页面由FhgfsPageListVec链表管理,每个FhgfsPageListVec包含一个FhgfsPage数组,其每个元素指向一个page页。页面收集好后,将RWpagesWork(工作项)提交到工作队列(beegfs-rwPgWQ),并绑定回调函数(RWPagesWork_process),内核工作线程从工作队列获取工作项,调用回调函数完成数据的回写
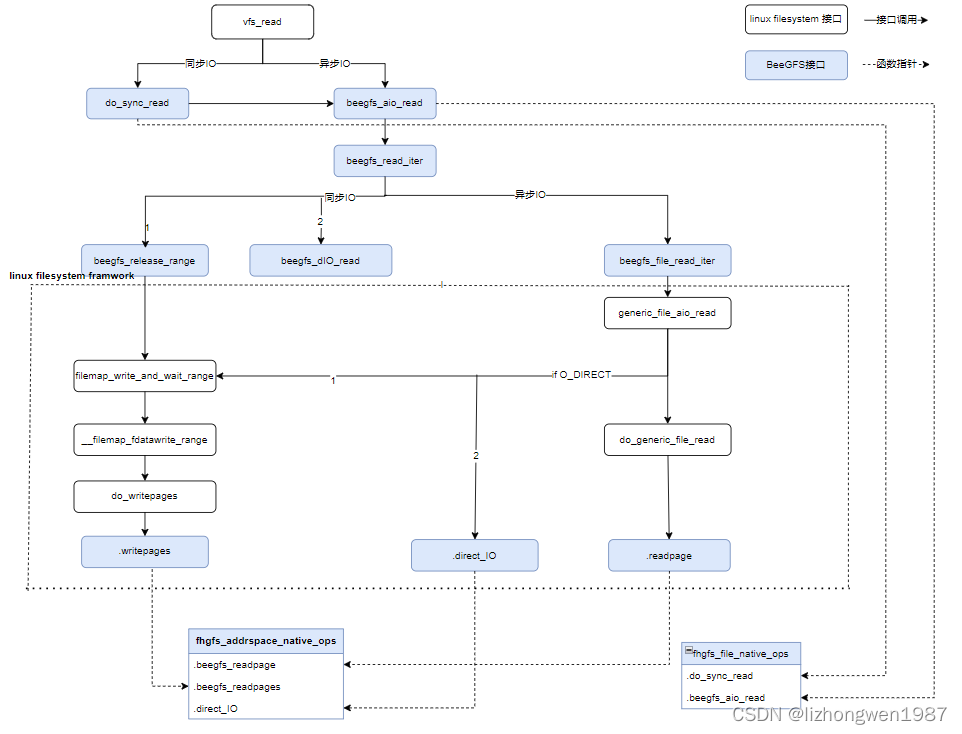
附录:下图是Buffered模式下的写IO流程简图,供参考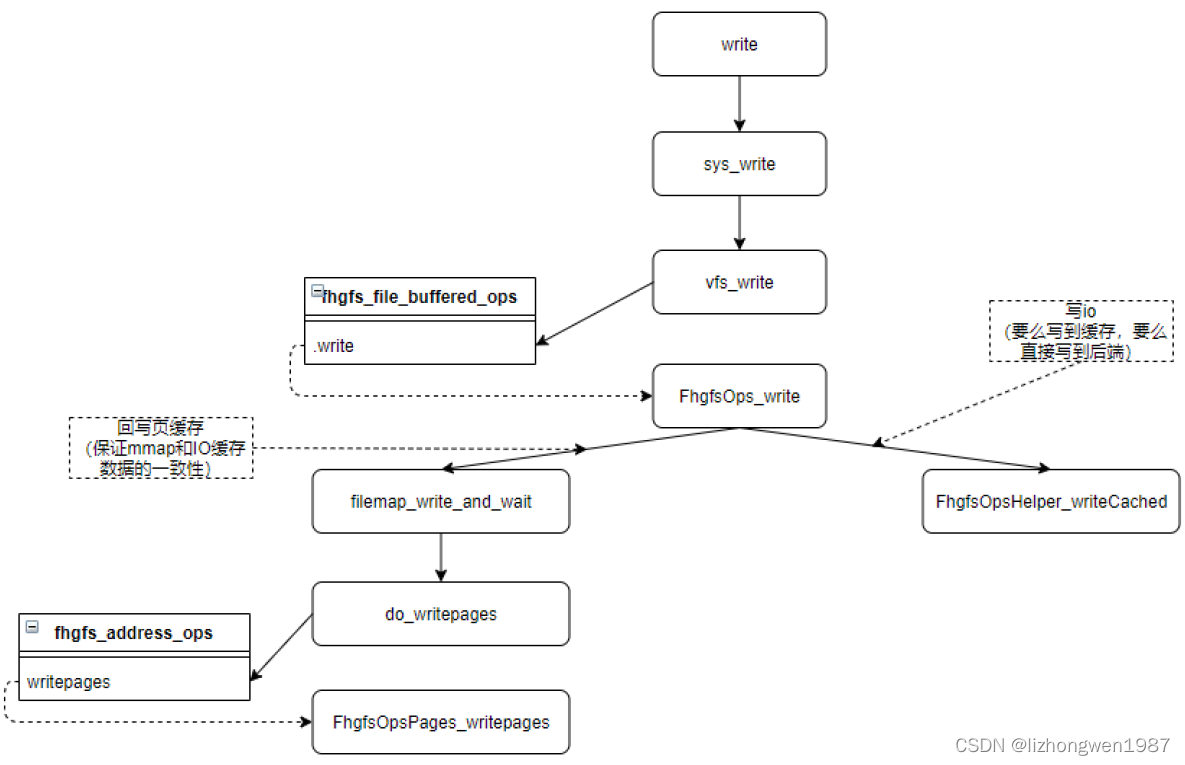
BeeGFS客户端Native缓存
Native缓存实际上就是传统意义上的pagecache缓存,它通过文件的address_space来管理文件的缓存页(一棵基数树来管理页面,是一棵基为6,最大层高为11的基数),与上文的Buffered缓存相比,1、容量更大,性能会更好些, 2、存在pagecache膨胀的问题
具体的实现(就是基于vfs接口编程),本文就不分析了,读写IO的流程参考文末的流程图(代码基于CentOS7.9/3.10.0-1160,BeeGFS 7.2.2),接下来我们来看看Native模式下BeeGFS是如何进行页面管理的。
Native缓存初始化
- 加载客户端模块时,初始化名为beegfs/flush的内核工作队列(workqueue_struct),用于脏页的回写,关于Linux内核工作队列的内容,请查阅网络资料
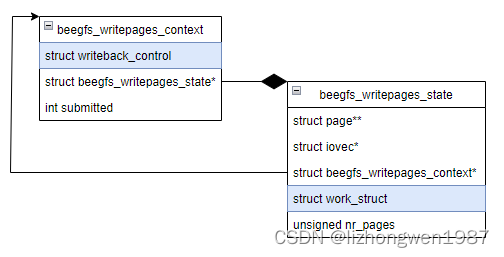
- 加载客户端模块时,初始化回写内存池,用于暂存待回写的(连续)脏页及读缓存页,beegfs_writepages_state和beegfs_writepages_context是两个很重要的结构,用于表示回写状态及上下文,它们的关系如下(结构成员未完全示出),beegfs_writepages_state内嵌一个work_struct,作为加入到上述队列的连接件,其中page指向连续的内存页,iovec用于io回写gather
非Append IO
- 两个标志:使用struct page的flages(PG_private和PG_check)来标识页面状态,PG_private = 1 && PG_check = 0, 页面有数据但未回写,页面回写后清除private标志PG_private = 0
- 一个偏移:使用struct page的private(unsigned long变量)来标识IO<offset, length>, offset为起始偏移,offset+length为结束偏移,private低12位(0-11位)为页内起始偏移,private中间12位(12-23位)为页内结束偏移
- 脏页回写:系统在合适的时候发起页面(一个或多个页面)的回写,beegfs从回写内存池分配beegfs_writepages_state工作项(work),其page结构包含待回写的连续脏页,然后提交到工作队列(绑定一个回调函数),系统工作线程(worker)执行回调函数(将beegfs_writepages_state page结构中的页面gather到iovec结构中,一次性提交)进行脏数据回写,并等待回写结束返回
Append IO
-
两个标志:使用struct page的flages(PG_private和PG_check)来标识页面状态,PG_private = 1 && PG_check = 1, 页面有数据但未回写,页面回写后清除private标志PG_private = 0
-
一个结构:使用struct page的private地址作为追加写结构append_range_descriptor的地址,记录了追加写(起始)的信息:firstPageIndex首个页地址,firstPageStart首个页内偏移。(连续的追加写操作中,各page将包含相同的append_range_descriptor结构信息)

-
脏页回写:系统在合适的时候发起页面(一个或多个页面)的回写,beegfs从回写内存池分配beegfs_writepages_state工作项(work),其page结构包含待回写的连续脏页,然后提交到工作队列(绑定一个回调函数),系统工作线程(worker)执行回调函数(将beegfs_writepages_state page结构中的各页面gather到iovec结构中,一次性提交,与非Append IO不同的是,在拼接iovec前,需要先去后端获取文件的写入偏移fileOffset)进行脏数据回写,并等待回写结束返回
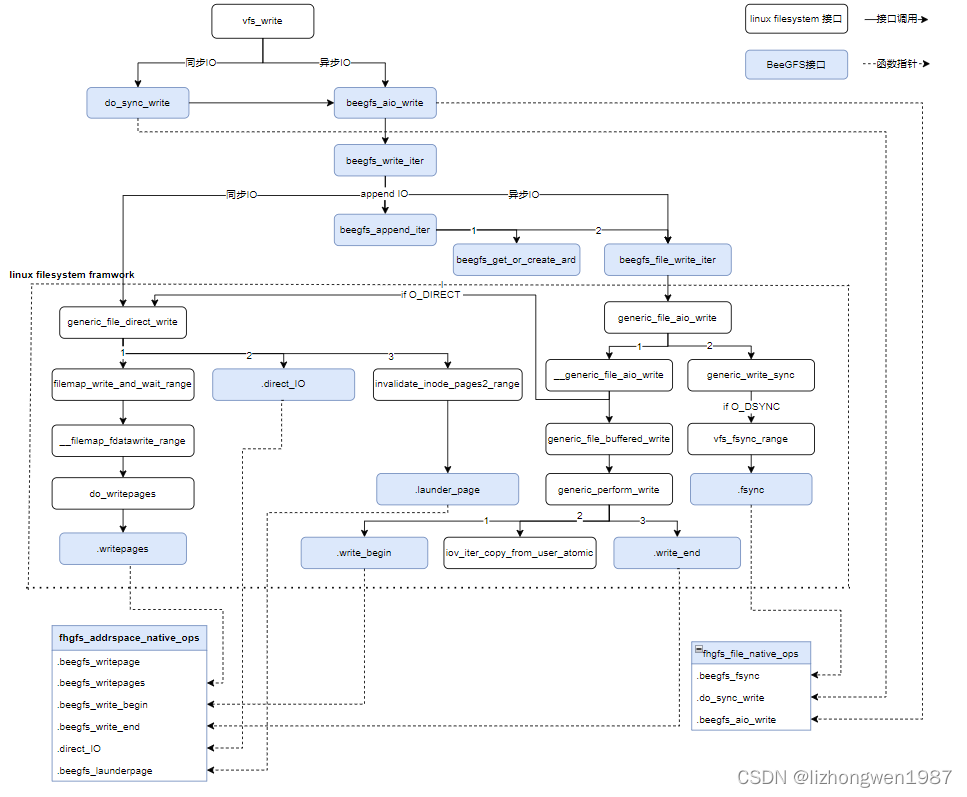
本文对BeeGFS客户端中的两种文件缓存的实现机制进行了总结,希望能够给进行Posix内核客户端开发的同学在文件缓存的实现上提供一点思路。
附录: