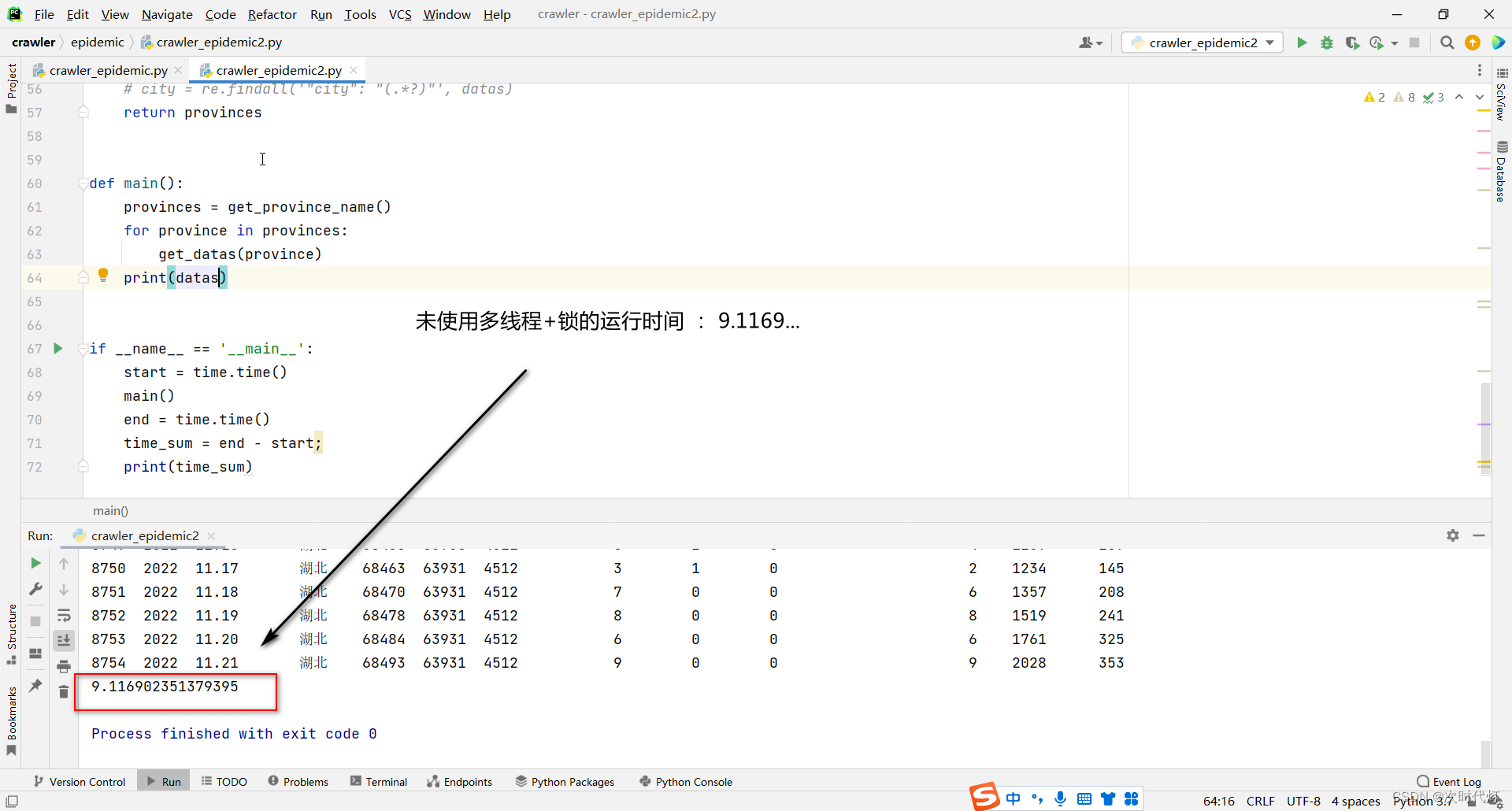
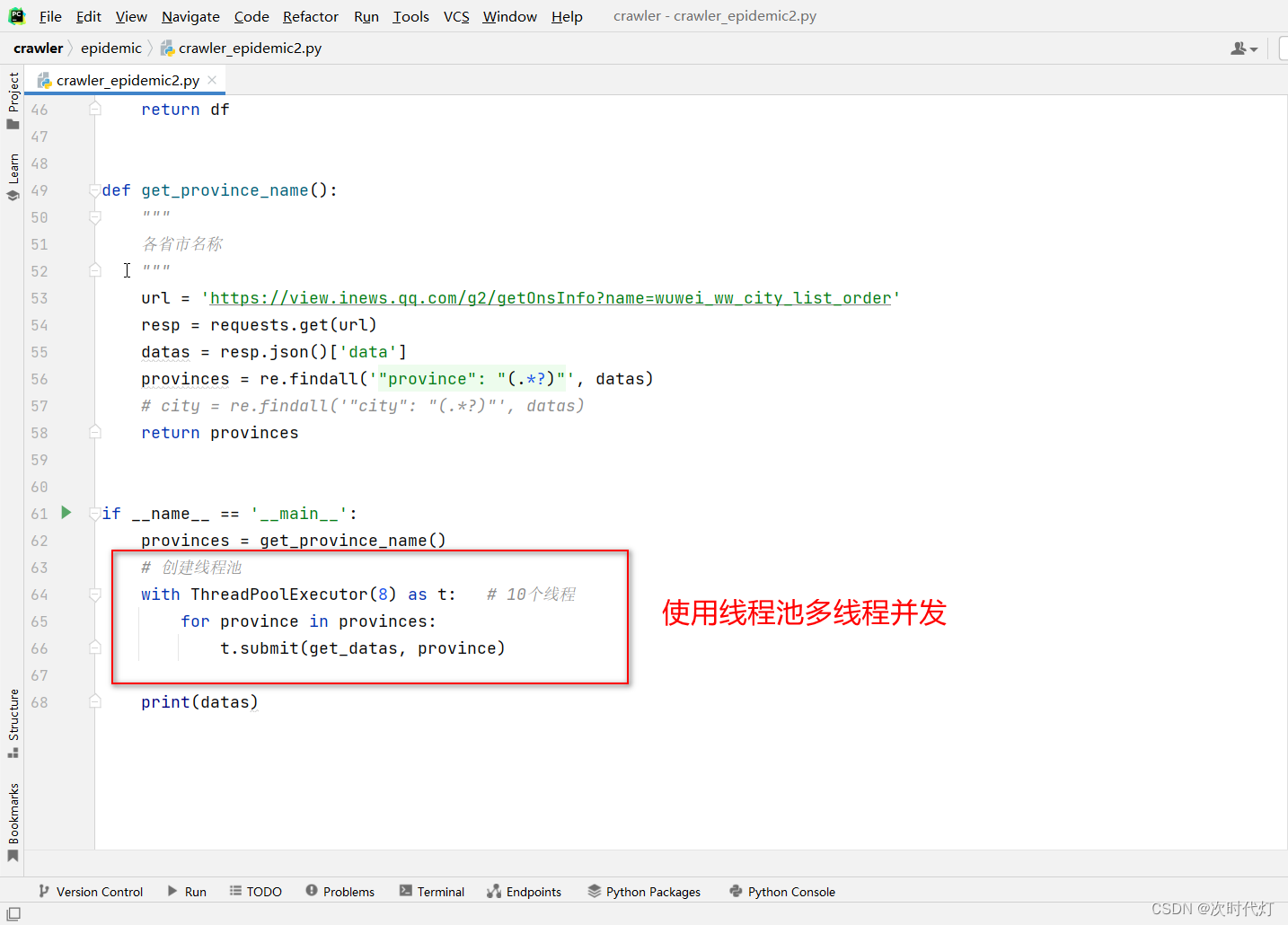
获取数据想要用一个全局的DataFrame将方法返回的多个DataFrame进行拼接,使用线程池多线程操作全局变量导致数据混乱,每次运行出来的数据量都不一样。多个线程同时修改一个变量,导致数据混乱。
第一次运行:5765条数据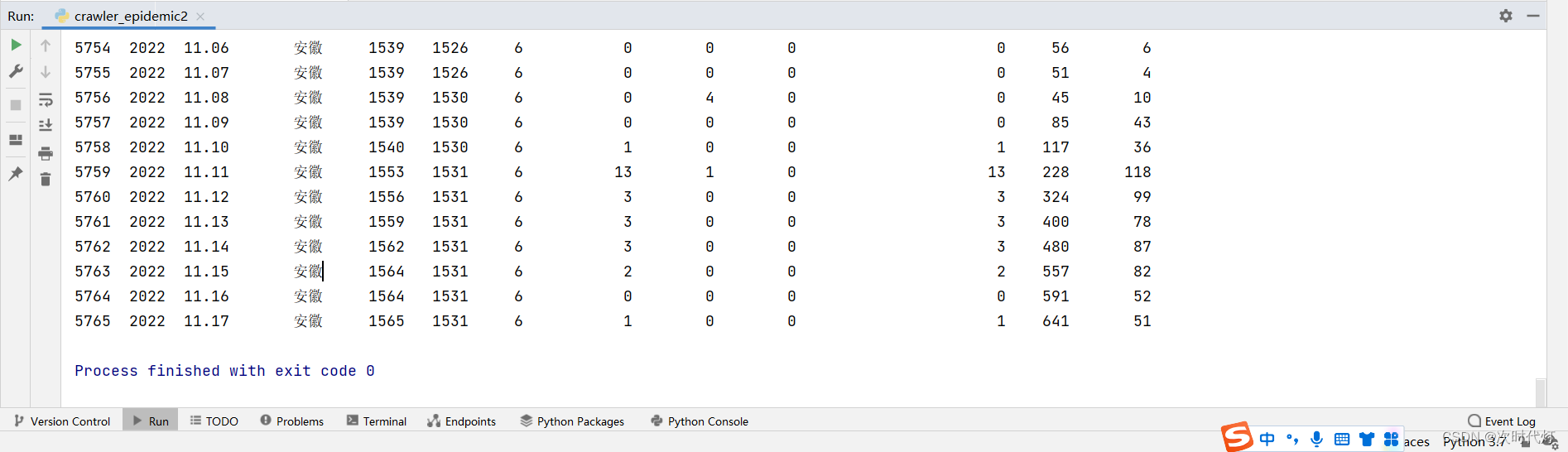
第二次运行:5122条数据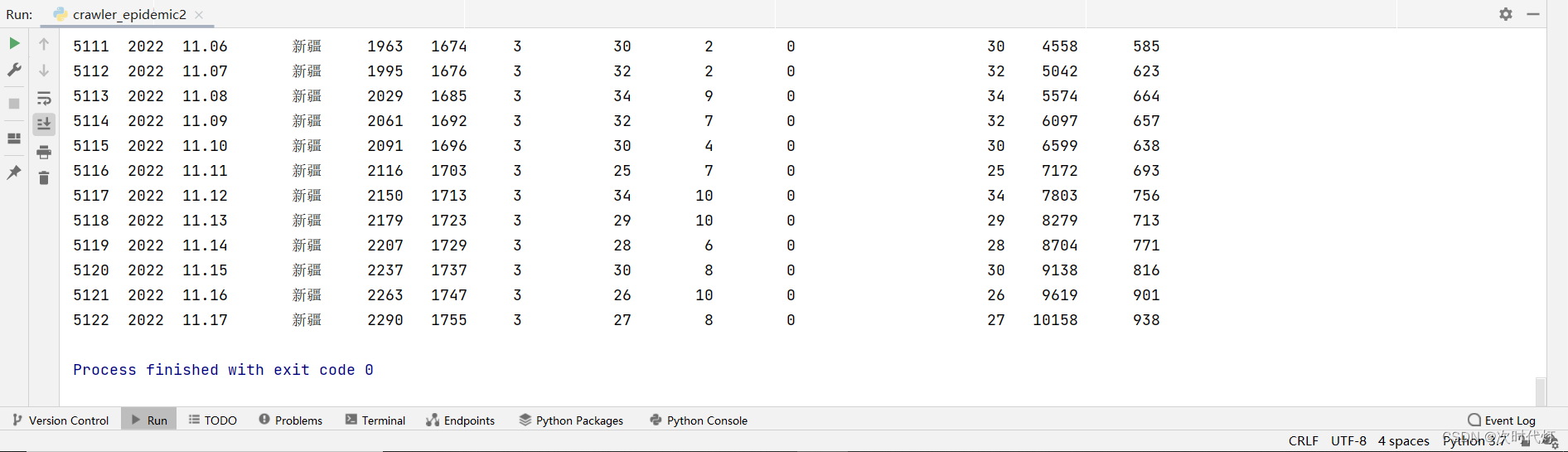
第三次运行:5128条数据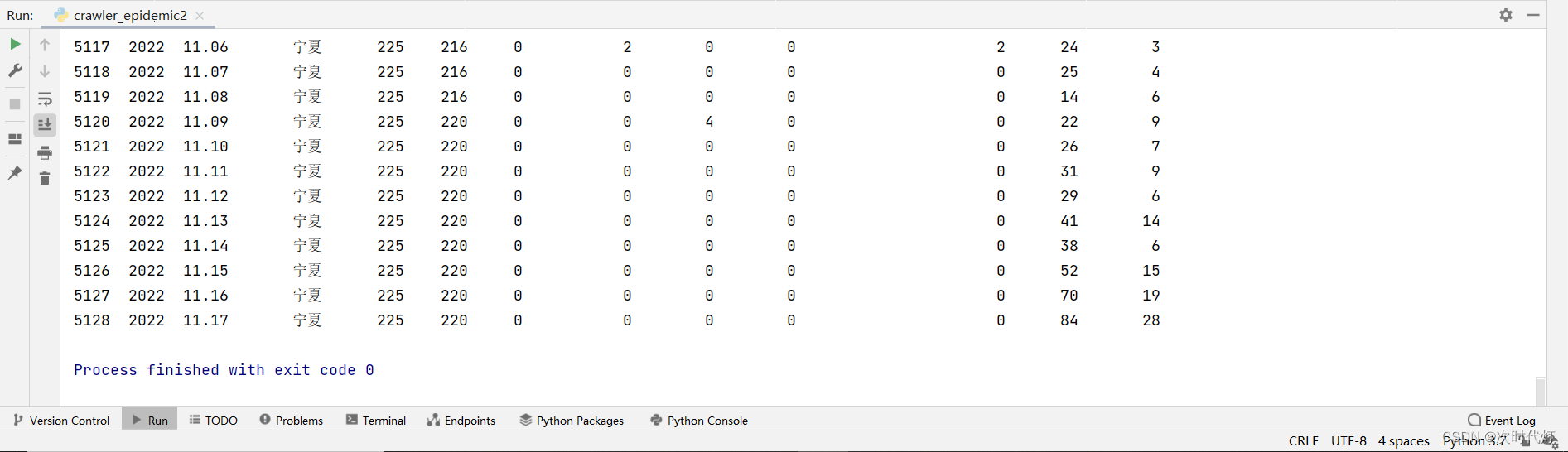
解决方法:
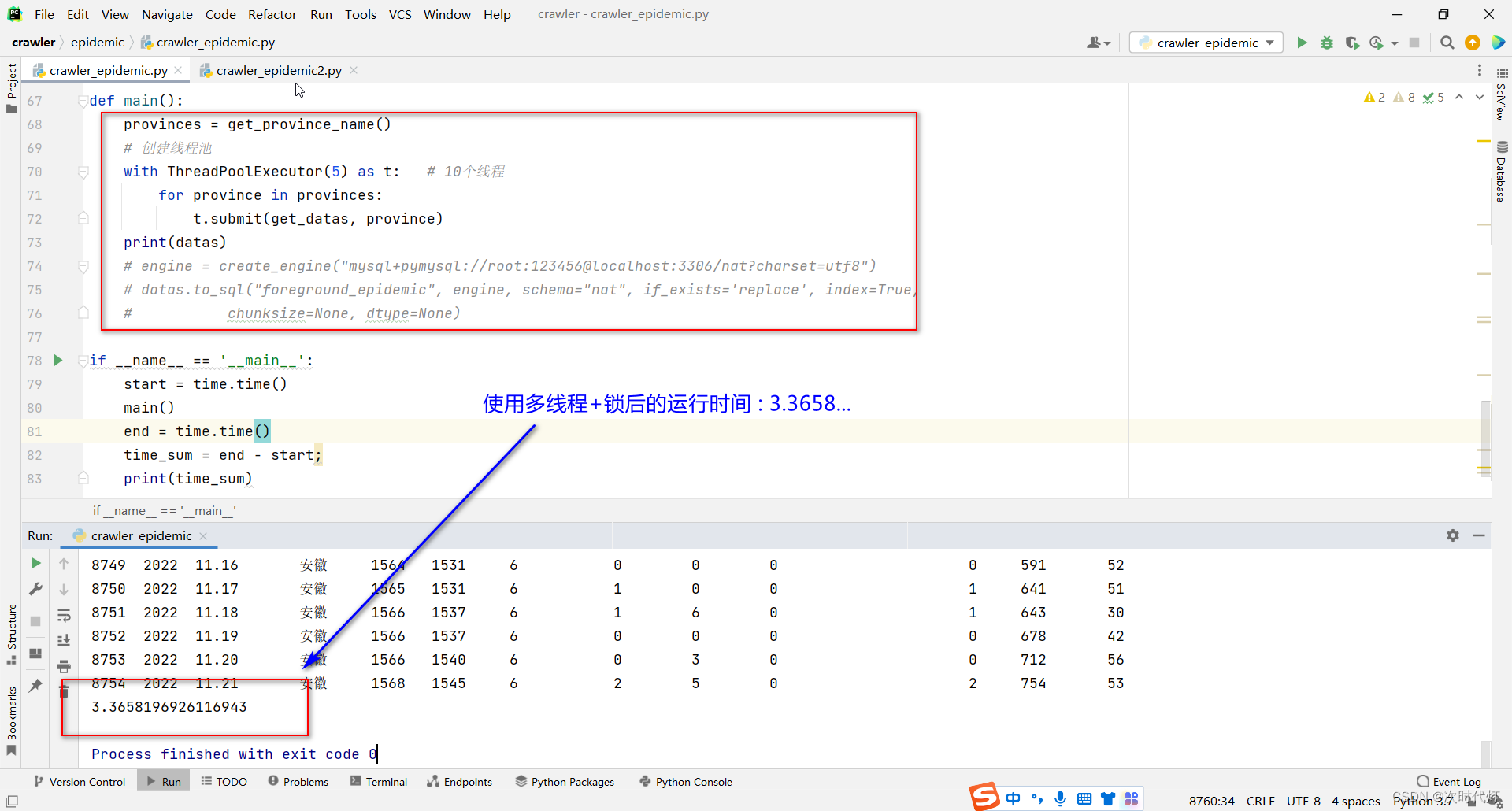
在程序中自己手动加同步锁Lock。用Lock.acquire()锁住要访问的资源,等访问资源后,用Lock.release()释放资源,确保每次只有一个线程访问该资源。
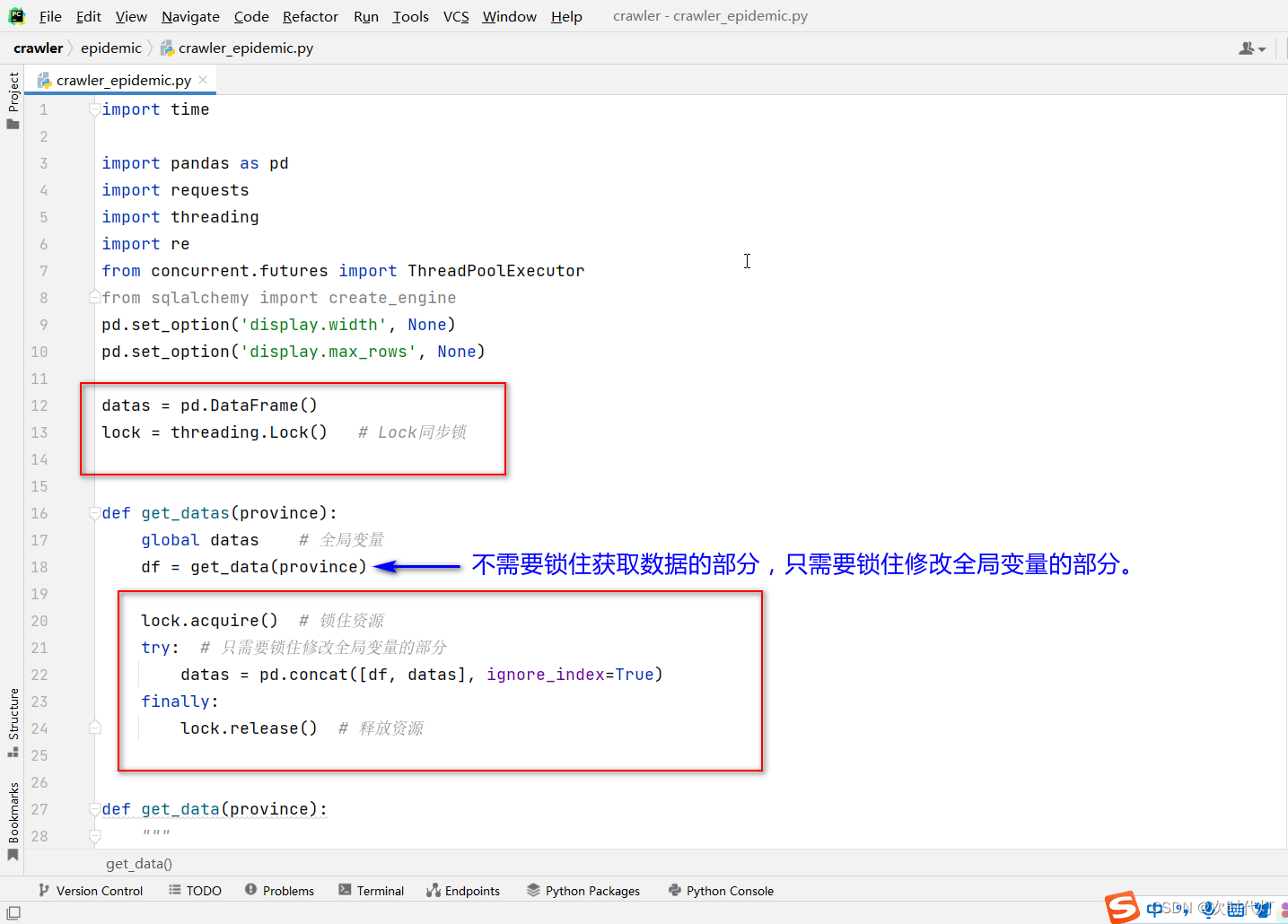
注意:不需要整个方法上锁,只需要在会造成数据出错的地方上锁,比如修改全局变量时。
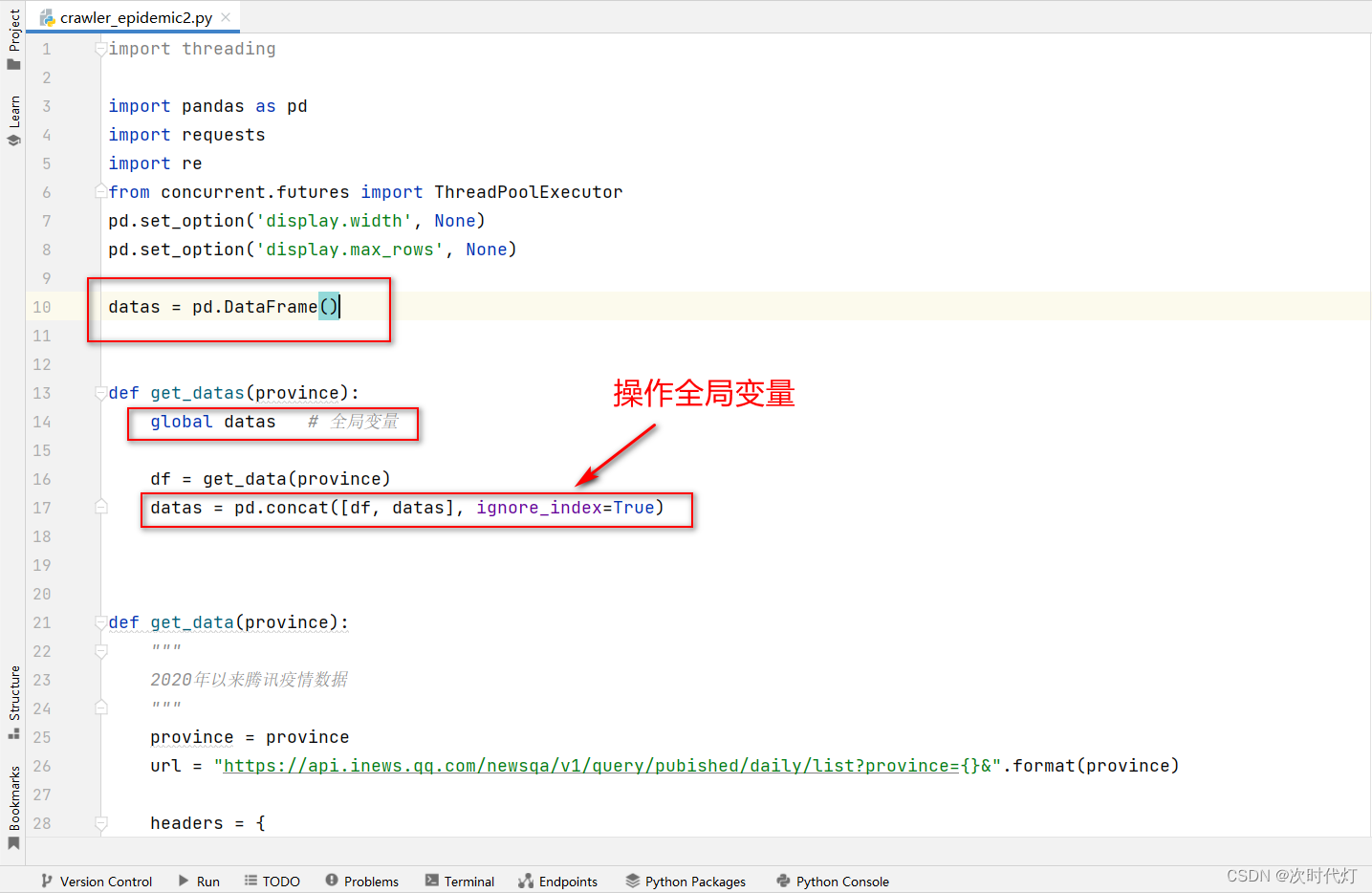
datas = pd.DataFrame()
lock = threading.Lock() # Lock同步锁
def get_datas(province):
global datas # 全局变量
df = get_data(province)
lock.acquire() # 锁住资源
try: # 只需要锁住修改全局变量的部分
datas = pd.concat([df, datas], ignore_index=True)
finally:
lock.release() # 释放资源比较普通方式和使用多线程+锁后的运行时间,明显使用多线程+锁后的程序运行快了许多。