1.例程一
- demo地址:https://github.com/alexandru-dinu/cae
遇到的错误:

在网上看到这个错误,应该是使用tensorboard;
我是pytorch环境下,是“setuptools版本问题”,版本过高导致的问题;
第一步:pip uninstall setuptools
- 使用pip,不能使用 conda uninstall setuptools ;切记不能使用conda的命令,原因是,conda在卸载的时候,会自动分析与其相关的库,然后全部删除。
第二步:pip或者conda install setuptools==58.0.4
- 应该是tesorboard的版本没有跟上setuptools库的版本,所以导致了上述的问题,所以第二步结束后可能还会出现让你升级tensorboard版本的问题,正常升级就好。
感谢大佬,方法来源于https://zhuanlan.zhihu.com/p/556704117
数据集下载地址:https://drive.google.com/file/d/1wbwkpz38stSFMwgEKhoDCQCMiLLFVC4T/view
- train.py形参配置,test.py同理

- train.yaml文件参数
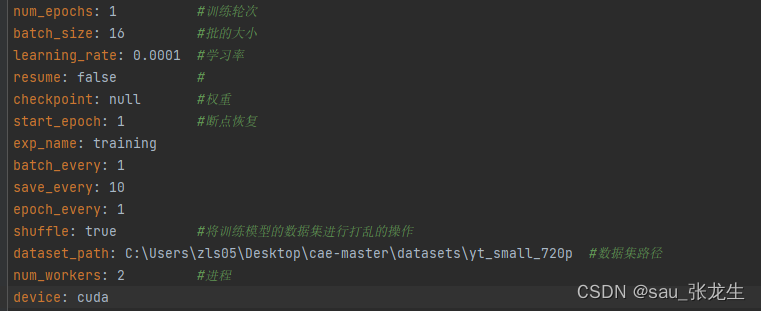
- test.yaml文件参数
- 作者训练好的权重下载地址:https://github.com/alexandru-dinu/cae/wiki
https://drive.google.com/file/d/1SSek44svPAZClmOg8xX-DLDUxQdnK22A/view
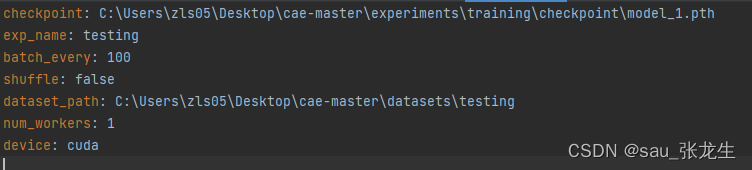
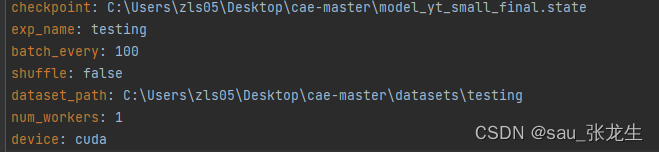
- train.py运行中
- test.py运行后效果


代码理解:
- dataloader.py(数据集加载):
from pathlib import Path
from typing import Tuple
import numpy as np
import torch as T
from PIL import Image
from torch.utils.data import Dataset
class ImageFolder720p(Dataset):
"""
Image shape is (720, 1280, 3) --> (768, 1280, 3) --> 6x10 128x128 patches
"""
def __init__(self, root: str):
self.files = sorted(Path(root).iterdir()) # 对文件名进行排序,sorted方法返回一个新的list
def __getitem__(self, index: int) -> Tuple[T.Tensor, np.ndarray, str]: # 重写getitem(self, index)方法
path = str(self.files[index % len(self.files)]) # 获取路径
img = np.array(Image.open(path)) # 读入图片转化为数组
pad = ((24, 24), (0, 0), (0, 0)) # pad是pytorch内置的tensor扩充函数,便于对数据集图像或中间层特征进行维度扩充
# img = np.pad(img, pad, 'constant', constant_values=0) / 255
img = np.pad(img, pad, mode="edge") / 255.0
# pad(array, pad_width, mode, **kwargs)图像边缘填充
# ‘edge’——表示用边缘值填充
img = np.transpose(img, (2, 0, 1)) # 转置, Pytorch中使用的数据格式与正常不一致
img = T.from_numpy(img).float() # 将数组转换为张量
patches = np.reshape(img, (3, 6, 128, 10, 128)) # 矩阵变换
patches = np.transpose(patches, (0, 1, 3, 2, 4))
return img, patches, path # 返回img图像 patches图像块补丁 path路径
def __len__(self): # 重写len(self)方法
return len(self.files) # 返回元素个数
- smoothing.py:(平滑处理)
import argparse
import os
import numpy as np
from PIL import Image
from skimage.io import imsave
def lin_interp(n, p1, p2): # 线性插值方法
x = np.zeros((n, p1.shape[0], 128, 3)) # 返回给定形状和类型的新数组,用0填充
for i in range(n):
a = (i + 1) / (n + 1)
x[i] = (1 - a) * p1 + a * p2
return x
def smooth(in_img, ws):
_name, _ext = os.path.splitext(in_img) # 分割文件名与拓展名
out_img = f"{_name}_s{ws}{_ext}"
in_img = np.array(Image.open(in_img)) / 255.0
orig_img = in_img[24:-24, :1280, :] # left image, remove borders
in_img = in_img[:, 1280:, :] # right image
# 6,10,128,128,3
patches = np.reshape(in_img, (6, 128, 10, 128, 3)) # 图像块变换
patches = np.transpose(patches, (0, 2, 1, 3, 4)) # 转置
h = ws // 2
for i in range(5):
p1 = patches[i, :, 128 - h, :, :]
p2 = patches[i + 1, :, h, :, :]
x = lin_interp(ws, p1, p2)
patches[i, :, 128 - h :, :, :] = np.transpose(x[:h, :, :, :], (1, 0, 2, 3))
patches[i + 1, :, :h, :, :] = np.transpose(x[h:, :, :, :], (1, 0, 2, 3))
for j in range(9):
p3 = patches[:, j, :, 128 - h, :]
p4 = patches[:, j + 1, :, h, :]
x = lin_interp(ws, p3, p4)
patches[:, j, :, 128 - h :, :] = np.transpose(x[:h, :, :, :], (1, 2, 0, 3))
patches[:, j + 1, :, :h, :] = np.transpose(x[h:, :, :, :], (1, 2, 0, 3))
out = np.transpose(patches, (0, 2, 1, 3, 4))
out = np.reshape(out, (768, 1280, 3))
out = out[24:-24, :, :]
out = np.concatenate((orig_img, out), axis=1)
imsave(out_img, out)
if __name__ == "__main__":
# argparse 模块可以让人轻松编写用户友好的命令行接口, 创建一个 ArgumentParser 对象, ArgumentParser
# 对象包含将命令行解析成 Python 数据类型所需的全部信息
parser = argparse.ArgumentParser()
# 添加参数
parser.add_argument("--in_img", type=str, required=True)
parser.add_argument("--window_size", type=int, required=True)
# 通过 parse_args() 方法解析参数
args = parser.parse_args()
# make sure an even size is used
args.window_size += args.window_size % 2
smooth(args.in_img, args.window_size) # 调用smooth方法
- train(训练脚本)、test(测试脚本)、utils(工具类)
- 神经网络模型文件
import torch
import torch.nn as nn
class CAE(nn.Module):
"""
This AE module will be fed 3x128x128 patches from the original image
Shapes are (batch_size, channels, height, width)
Latent representation: 32x32x32 bits per patch => 240KB per image (for 720p)
"""
def __init__(self):
super(CAE, self).__init__()
self.encoded = None
# ENCODER
# 64x64x64
self.e_conv_1 = nn.Sequential(
nn.ZeroPad2d((1, 2, 1, 2)),
nn.Conv2d(
in_channels=3, out_channels=64, kernel_size=(5, 5), stride=(2, 2)
),
nn.LeakyReLU(),
)
# 128x32x32
self.e_conv_2 = nn.Sequential(
nn.ZeroPad2d((1, 2, 1, 2)),
nn.Conv2d(
in_channels=64, out_channels=128, kernel_size=(5, 5), stride=(2, 2)
),
nn.LeakyReLU(),
)
# 128x32x32
self.e_block_1 = nn.Sequential(
nn.ZeroPad2d((1, 1, 1, 1)),
nn.Conv2d(
in_channels=128, out_channels=128, kernel_size=(3, 3), stride=(1, 1)
),
nn.LeakyReLU(),
nn.ZeroPad2d((1, 1, 1, 1)),
nn.Conv2d(
in_channels=128, out_channels=128, kernel_size=(3, 3), stride=(1, 1)
),
)
# 128x32x32
self.e_block_2 = nn.Sequential(
nn.ZeroPad2d((1, 1, 1, 1)),
nn.Conv2d(
in_channels=128, out_channels=128, kernel_size=(3, 3), stride=(1, 1)
),
nn.LeakyReLU(),
nn.ZeroPad2d((1, 1, 1, 1)),
nn.Conv2d(
in_channels=128, out_channels=128, kernel_size=(3, 3), stride=(1, 1)
),
)
# 128x32x32
self.e_block_3 = nn.Sequential(
nn.ZeroPad2d((1, 1, 1, 1)),
nn.Conv2d(
in_channels=128, out_channels=128, kernel_size=(3, 3), stride=(1, 1)
),
nn.LeakyReLU(),
nn.ZeroPad2d((1, 1, 1, 1)),
nn.Conv2d(
in_channels=128, out_channels=128, kernel_size=(3, 3), stride=(1, 1)
),
)
# 32x32x32
self.e_conv_3 = nn.Sequential(
nn.Conv2d(
in_channels=128,
out_channels=32,
kernel_size=(5, 5),
stride=(1, 1),
padding=(2, 2),
),
nn.Tanh(),
)
# DECODER
# 128x64x64
self.d_up_conv_1 = nn.Sequential( # 反卷积
nn.Conv2d(
in_channels=32, out_channels=64, kernel_size=(3, 3), stride=(1, 1)
),
nn.LeakyReLU(),
nn.ZeroPad2d((1, 1, 1, 1)),
nn.ConvTranspose2d(
in_channels=64, out_channels=128, kernel_size=(2, 2), stride=(2, 2)
),
)
# 128x64x64
self.d_block_1 = nn.Sequential(
nn.ZeroPad2d((1, 1, 1, 1)),
nn.Conv2d(
in_channels=128, out_channels=128, kernel_size=(3, 3), stride=(1, 1)
),
nn.LeakyReLU(),
nn.ZeroPad2d((1, 1, 1, 1)),
nn.Conv2d(
in_channels=128, out_channels=128, kernel_size=(3, 3), stride=(1, 1)
),
)
# 128x64x64
self.d_block_2 = nn.Sequential(
nn.ZeroPad2d((1, 1, 1, 1)),
nn.Conv2d(
in_channels=128, out_channels=128, kernel_size=(3, 3), stride=(1, 1)
),
nn.LeakyReLU(),
nn.ZeroPad2d((1, 1, 1, 1)),
nn.Conv2d(
in_channels=128, out_channels=128, kernel_size=(3, 3), stride=(1, 1)
),
)
# 128x64x64
self.d_block_3 = nn.Sequential(
nn.ZeroPad2d((1, 1, 1, 1)),
nn.Conv2d(
in_channels=128, out_channels=128, kernel_size=(3, 3), stride=(1, 1)
),
nn.LeakyReLU(),
nn.ZeroPad2d((1, 1, 1, 1)),
nn.Conv2d(
in_channels=128, out_channels=128, kernel_size=(3, 3), stride=(1, 1)
),
)
# 256x128x128
self.d_up_conv_2 = nn.Sequential(
nn.Conv2d(
in_channels=128, out_channels=32, kernel_size=(3, 3), stride=(1, 1)
),
nn.LeakyReLU(),
nn.ZeroPad2d((1, 1, 1, 1)),
nn.ConvTranspose2d(
in_channels=32, out_channels=256, kernel_size=(2, 2), stride=(2, 2)
),
)
# 3x128x128
self.d_up_conv_3 = nn.Sequential(
nn.Conv2d(
in_channels=256, out_channels=16, kernel_size=(3, 3), stride=(1, 1)
),
nn.LeakyReLU(),
nn.ReflectionPad2d((2, 2, 2, 2)),
nn.Conv2d(
in_channels=16, out_channels=3, kernel_size=(3, 3), stride=(1, 1)
),
nn.Tanh(),
)
def forward(self, x): # 向前传播
ec1 = self.e_conv_1(x)
ec2 = self.e_conv_2(ec1)
eblock1 = self.e_block_1(ec2) + ec2
eblock2 = self.e_block_2(eblock1) + eblock1
eblock3 = self.e_block_3(eblock2) + eblock2
ec3 = self.e_conv_3(eblock3) # in [-1, 1] from tanh activation
# stochastic binarization
with torch.no_grad():
rand = torch.rand(ec3.shape).cuda()
prob = (1 + ec3) / 2
eps = torch.zeros(ec3.shape).cuda()
eps[rand <= prob] = (1 - ec3)[rand <= prob]
eps[rand > prob] = (-ec3 - 1)[rand > prob]
# encoded tensor
self.encoded = 0.5 * (ec3 + eps + 1) # (-1|1) -> (0|1)
return self.decode(self.encoded)
def decode(self, encoded): # 解码
y = encoded * 2.0 - 1 # (0|1) -> (-1|1)
uc1 = self.d_up_conv_1(y)
dblock1 = self.d_block_1(uc1) + uc1
dblock2 = self.d_block_2(dblock1) + dblock1
dblock3 = self.d_block_3(dblock2) + dblock2
uc2 = self.d_up_conv_2(dblock3)
dec = self.d_up_conv_3(uc2)
return dec
算法理解
- 卷积自编码器,卷积自编码器是自编码器方法的一种延伸,自编码器包括编码和解码,通过将输入的图像进行编码,特征映射到隐层空间,然后解码器对隐层空间的特征进行解码,获得输入的重建样本。自编码一般使用神经网络做编码和解码器,卷积自编码器利用卷积网络对图像特征抽取和表示的优异性能,来代替自编码器的神经网络。
- 编码器与解码器:
神经网络本质上就是一个线性变换,通过将输入的多维向量与权重矩阵相乘,得到一个新的多维向量。
当输入向量的维度高于输出向量的维度时,神经网络就相当于一个编码器,实现了对高维向量的低维特征提取。
当输入向量维度低于输出向量维度时,神经网络就相当于一个解码器,实现了低维向量到高维向量的重构。 - 实例的网络模型
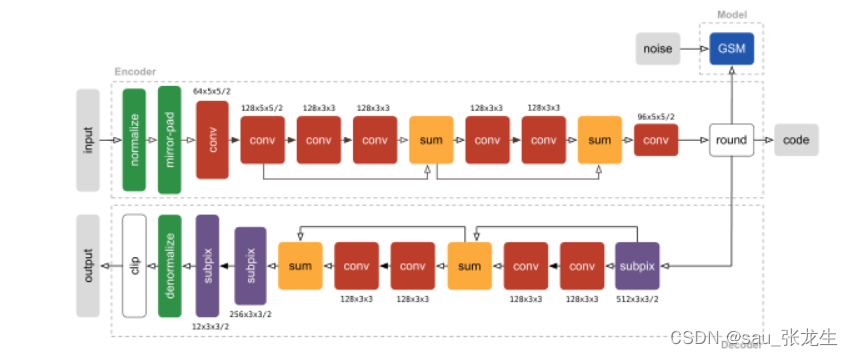
编码:输入——归一化——镜像填充——卷积——残差块——卷积——量化——GSM
解码:子像素卷积——残差块——子像素卷积——去归一化——修剪图像——输出
GSM:为了模拟系数分布并估计比特率,我们使用独立高斯尺度混合(GSMs),GSMs是很好的建立自然图像的滤波器响应建模的有用构建块(例如,Portilla et al, 2003)。我们在每个GSM中使用了6个秤。我们对GSM进行了参数化,这样它就可以很容易地与基于梯度的方法一起使用,优化对数权重和对数精度,而不是权重和方差。我们注意到GSMs的细峰性质(Andrews & Mallows, 1974)意味着速率项鼓励系数的稀疏性。
我们没有完全用平滑近似代替舍入函数,而只是用它的导数,这意味着在正向传递中仍然像往常一样执行量化。如果我们完全用平滑近似代替舍入,解码器可能会学会反转平滑近似,从而消除迫使网络压缩信息的信息瓶颈。
对于量化系数的熵编码,我们首先创建了跨训练集的系数分布的拉普拉斯平滑直方图估计。
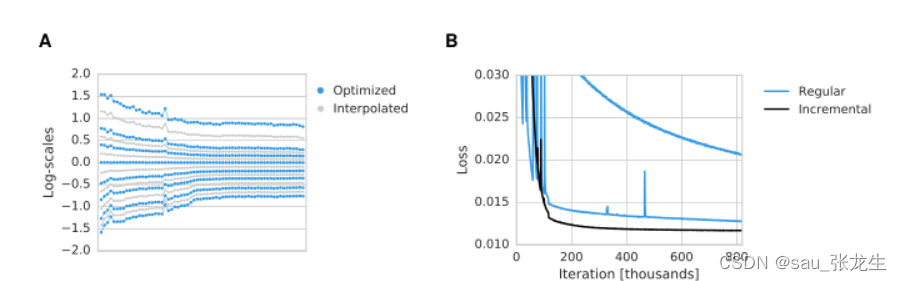
所有模型都使用Adam (Kingma & Ba, 2015)训练,并应用于大小为128×128像素的32张图像批次。我们发现以增量方式优化系数是有益的。
一些知识点
4. 图像质量评估各项指标
基于图像像素统计基础,峰值信噪比(Peak-Signal to Noise Ratio,PSNR)和均方误差(Mean Square Error,MSE),还有MAE(Mean Absolute Error,MSE)和信噪比SNR(Signal to Noise Ratio),是比较常见的几种质量评价方法。它们通过计算待评测图像和参考图像对应像素点灰度值之间的差异,从统计角度来衡量待评图像的质量优劣。
5. ConvTranspose2d转置卷积(逆卷积、反卷积)方法
转自链接:https://blog.csdn.net/qq_27261889/article/details/86304061
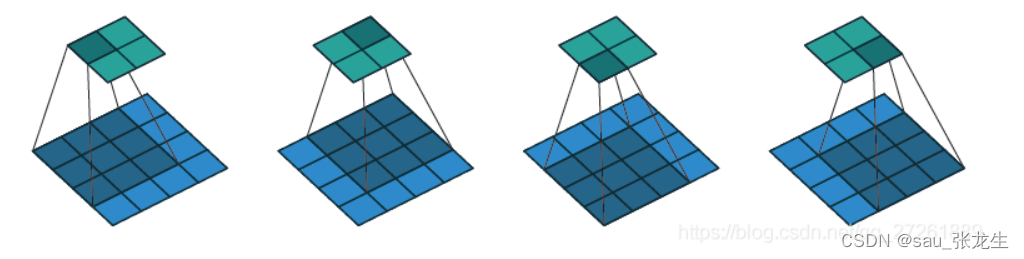
上面这个是一个卷积操作。我们输入的特征图为:x:(4,4,channels_in),channels_in表示通道数。卷积核设置:无padding, kernel size为3*3, 步长stride 为1,输出的特征图为y,2 * 2 * channels_out,channels_out也是通道数。如果是逆卷积操作,输入输出就正好相反(绿色是输入,蓝色是输出)。输入变为特征图y, 卷积核设置同上。输出是上面的特征图x。

下面的图片我们可以这样想,蓝色的特征图是经过encoder不断卷积后的图片,我们现在要做的是将其尺寸放大,channel数量也变大。这时,就需要用到nn.ConvTranspose2d了。
但是当给一个特征图a, 以及给定的卷积核设置,我们要分为三步进行逆卷积操作:
第一步:对输入的特征图a进行一些变换,得到新的特征图a’
新的特征图是怎么得到的:我们在输入的特征图基础加上一些东西,专业名词叫做interpolation,也就是插值。在原先高度方向的每两个相邻中间插上"Stride−1"列 0
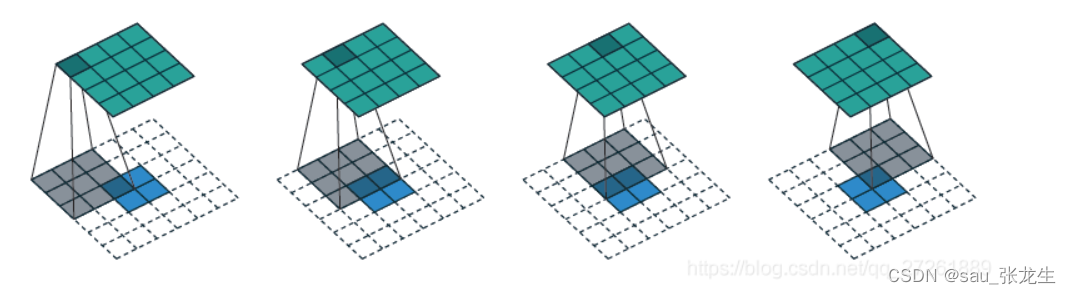
第二步:求新的卷积核设置,得到新的卷积核设置
新的卷积核:S t r i d e ′ =1,这个数不变,无论你输入是什么。kernel 的size 也不变,padding′ 为Size−padding−1.
第三步:用新的卷积核在新的特征图上做常规的卷积,得到的结果就是逆卷积的结果,就是我们要求的结果。
下图蓝色为输入,绿色为输出:
输入特征图A:(3,3,in_channel)
输入卷积核K:kernel为3 ∗ 3 3*33∗3, stride为2, padding为1
新的特征图B: 3 + ( 3 − 1 ) ∗ ( 2 − 1 ) = 3 + 2 = 5
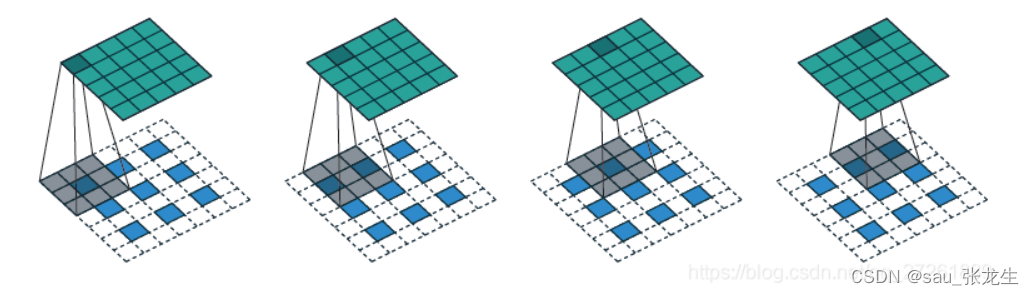
3. 子像素卷积(sub-pixel convolutions),是一种正常卷积的简化形式,并加了很强的假设,结果就是去除了大量的卷积运算。子像素卷积的结果一般是一张更大的图片,可用作超分辨率。
subpixel作者认为,正常反卷积的填0区域,是无效信息,甚至对求梯度优化有害处,明明可以直接从原图得到信息
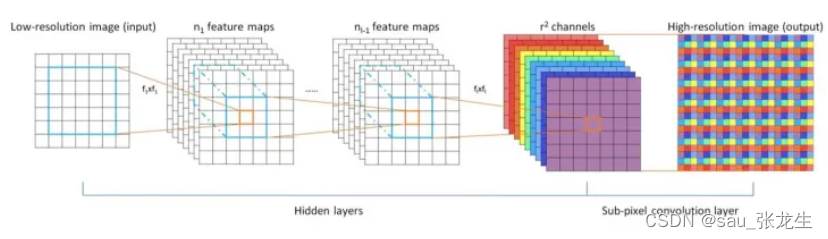 第一个白色矩阵图片是输入层。第二个、第三个白色张量是隐藏层,做步长为1的正常卷积。第四个彩色图片,经过子像素卷积,得到最后一张斑斓的大图。
第一个白色矩阵图片是输入层。第二个、第三个白色张量是隐藏层,做步长为1的正常卷积。第四个彩色图片,经过子像素卷积,得到最后一张斑斓的大图。
2.例程二
- celeba数据集
http://mmlab.ie.cuhk.edu.hk/projects/CelebA.html - 网盘地址:
https://pan.baidu.com/s/1CRxxhoQ97A5qbsKO7iaAJg#list/path=%2F
(rp0s)
celeba数据集分类代码:(代码来源于这个大佬https://blog.csdn.net/free_hard/article/details/106042811)
# -*- coding: utf-8 -*-
# !/usr/bin/env python3
'''
Divide face accordance CelebA Id type.
'''
import shutil
import os
output_path_train = r"D:\Program Files\Image Coding\dplc-master\train"
output_path_valid = r"D:\Program Files\Image Coding\dplc-master\valid"
output_path_test = r"D:\Program Files\Image Coding\dplc-master\test"
image_path = r"D:\Program Files\Image Coding\dplc-master\CelebA\Img\img_align_celeba" #原始图片文件夹的路径
CelebA_Id_file = r"D:\Program Files\Image Coding\dplc-master\CelebA\Anno\identity_CelebA.txt" #identity_CelebA.txt文件的路径
def main():
count_N = 0
with open(CelebA_Id_file, "r") as Id_file:
Id_info = Id_file.readlines()
for line in Id_info:
count_N += 1 #计数
info = line.split()
filename = info[0]
file_Id = info[1]
Id_dir_train = os.path.join(output_path_train,file_Id)
Id_dir_valid = os.path.join(output_path_valid, file_Id)
Id_dir_test = os.path.join(output_path_test, file_Id)
filepath_old = os.path.join(image_path,filename) #原始照片所在的位置
if count_N<=170000: #这里170000是我随便写的一个数字,具体可以去文件中查看,大该16万多,不影响
if not os.path.isdir(Id_dir_train):
os.makedirs(Id_dir_train)
else:
pass
train = os.path.join(Id_dir_train,filename)
shutil.copyfile(filepath_old,train) #这句代码是复制的意思
elif count_N>170000 and count_N<182636: #在这区间的都是valid
if not os.path.isdir(Id_dir_valid):
os.makedirs(Id_dir_valid)
else:
pass
valid = os.path.join(Id_dir_valid, filename)
shutil.copyfile(filepath_old, valid)
else : #这里的是test
if not os.path.isdir(Id_dir_test):
os.makedirs(Id_dir_test)
else:
pass
test = os.path.join(Id_dir_test, filename)
shutil.copyfile(filepath_old, test)
Id_file.close()
print(" have %d images!" % count_N)
if __name__ == "__main__":
main()
学习记录
-
dplc:一种分布保持的有损压缩系统
-
本文使用的生成模型 G 通过最小化 P_X 和 P_G(Z) 之间的 Wasserstein 距离来学习,学习的方法有两种(i)通过 Wasserstein 自动编码器(WAE),其中 GoF 参数化 P_X 和 P_G(Z) 之间的耦合,或者(ii)通过 Wasserstein GAN(WGAN)。本文提出 Wasserstein++,将 WAE 和 WGAN 结合起来。将经过训练的生成模型 G 与利用速率约束编码器 E 和随机函数 B 来实现本文提出的 DPLC 系统,从而在保证 P_X 和 P_X^ 在所有速率下都相似的同时,将 X 和 X^之间的失真减至最小。完整的 DPLC 见图 1。
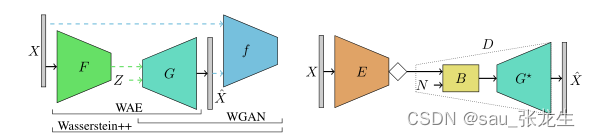
压缩过程为了从原始数据中学习 G、B 和 E,将每个分量参数化为深度神经网络,并通过随机梯度下降(SGD)求解相应的优化问题。如前所述,G*可以通过 WGAN 或 WAE 学习。由于 WAE 框架自然的包含了一个编码器,它能保证潜在空间 Z 的结构易于编码,而使用 WGAN 则不具有这样的特性。在本文的实验中,我们观察到使用 WAE 的图像中边缘的锐化程度弱于 WGAN。另一方面,由于 WAE 目标由于重建误差项而严重惩罚了模式丢失,因此 WAE 比 WGAN 更不容易发生模式丢失。为了结合这两种方法的优点,我们通过 Wd 的凸组合,提出了 Wd 的原形式和对偶形式的新的优化组合:
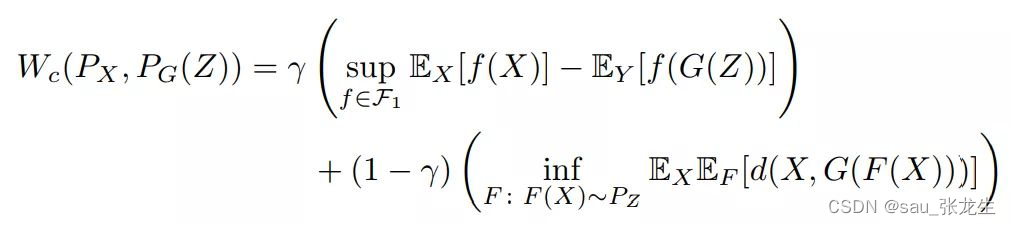
我们将WGAN算法和W AE-MMD算法的步骤结合起来,并将这种组合算法称为Wasserstein++。其次,可以在G(Z)或G(f (X))的假样本上训练f,由于f (X)和PZ之间的不匹配,它们通常不会遵循相同的分布,这在优化过程的开始更为明显。因此需要做下面的调整:- 基于 G(~ Z)的样本训练 f,其中~ Z=UZ+(1-U)F(X),U~Uniform(0,1)。
- 基于 F(X) 中的样本训练 G,计算 WGAN 和 WAE 的损失项。
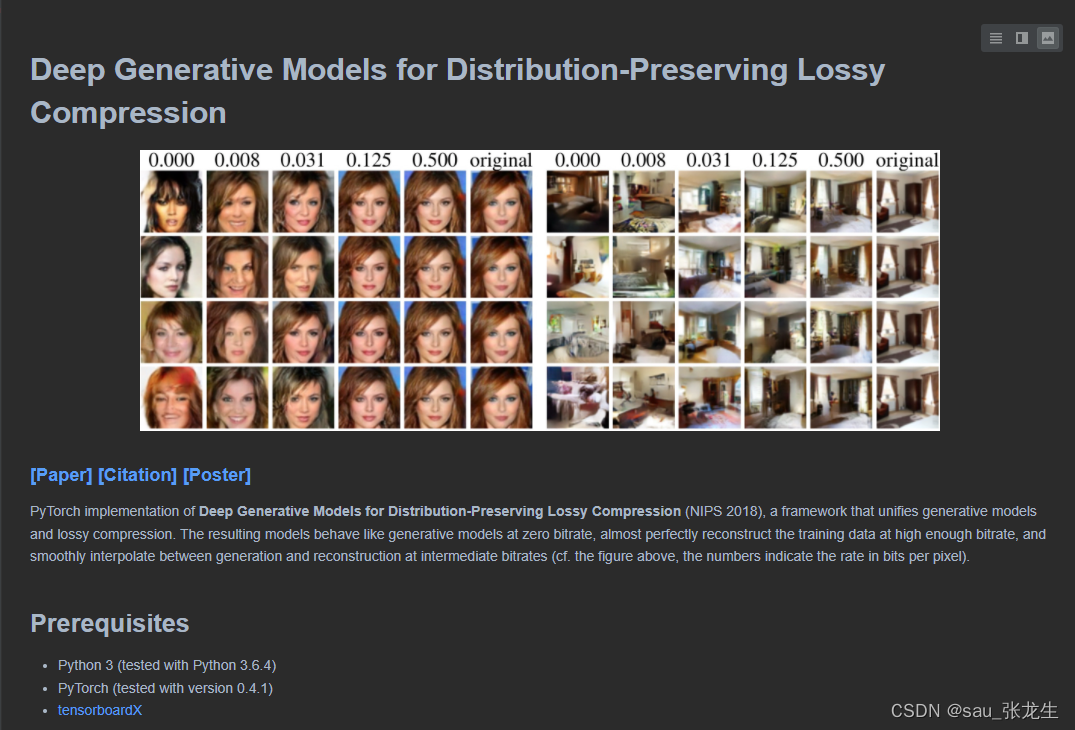
本文在两个标准的生成性建模基准图像数据集上完成实验,CelebA 和 LSUN 卧室,其中图像都缩小到 64x64 分辨率。图 2 给出了不同方法的测试 MSE(越小越好)、重建 FID(越小越好)和条件像素方差 PV(越大越好)。CelebA 的结果显示在最上面一行,LSUN 卧室的结果显示在最下面一行。与GC相比,我们的DPLC模型的PV以递减的速率稳步增加,即它们生成的图像内容逐渐增多。

-
GAN生成对抗网络:GAN包含有两个模型,一个是生成模型(generative model),一个是判别模型(discriminative model)。
算法简单来说:初始化生成器和鉴别器在每次训练迭代中:1.固定生成器G,并更新鉴别器D。鉴别器学习将高分分配给真实对象,将低分分配给生成对象。2.固定鉴别器D,并更新生成器G,希望生成器学会 "欺骗"鉴别器
原始GAN存在着:(转自https://zhuanlan.zhihu.com/p/25071913)
(1) 判别器越好,生成器梯度消失越严重的问题。根据原始GAN定义的判别器loss,我们可以得到最优判别器的形式;在(近似)最优判别器下,最小化生成器的loss等价于最小化与之间的JS散度,而由于与几乎不可能有不可忽略的重叠,所以无论它们相距多远JS散度都是常数,最终导致生成器的梯度(近似)为0,梯度消失。

(2) 最小化第二种生成器loss函数,会等价于最小化一个不合理的距离衡量,导致两个问题,一是梯度不稳定,二是collapse mode即多样性不足。
而WGAN从第一点根源出发,用Wasserstein距离代替JS散度,同时完成了稳定训练和进程指标的问题。Wasserstein距离相比KL散度、JS散度的优越性在于,即便两个分布没有重叠,Wasserstein距离仍然能够反映它们的远近。WGAN与原始GAN第一种形式相比,只改了四点:
- 判别器最后一层去掉sigmoid
- 生成器和判别器的loss不取log
- 每次更新判别器的参数之后把它们的绝对值截断到不超过一个固定常数c
- 不要用基于动量的优化算法(包括momentum和Adam),推荐RMSProp,SGD也行
-
AutoEncoder自编码器,属于神经网络范畴,AutoEncoder 重点关注的是 Hidden Layer,而它通常只有一层 Hidden Layer。AutoEncoder包含encoder与decoder两部分:通过encoder将输入x映射到特征空间z,再通过decoder将抽象表示z映射回原始空间,通常记作x’,是对样本的重构。

-
WAE-Wasserstein自编码器,最小化模型生成分布与真实数据分布之间的Wasserstein距离,从而构造一种具有新正则化器形式的VAE。实验表明WAE具有VAE的良好特性(训练稳定、良好的隐空间结构),同时能够生成质量更好的样本。
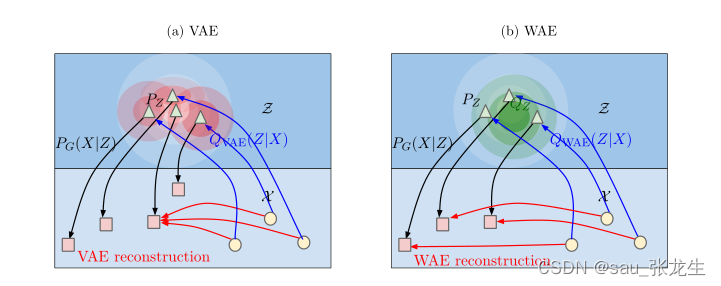
VAE和W AE都最小化了两个项:重构成本和正则化子惩罚编码器Q引起的PZ和分布之间的差异。VAE迫使Q(Z|X = X)匹配所有从PX中提取的不同输入示例X的PZ。如图(a)所示,其中每个红球都被迫与描绘为白色形状的PZ相匹配。红球开始相交,这就导致了重建的问题。
而WAE则使连续的混合QZ:= R Q(Z|X)dPX与PZ匹配,如图(b)中的绿球所示,使得不同样例的潜码有机会远离彼此,促进了更好的重构。