说到图搜索算法,首先想到的就是深度优先搜索与广度优先搜索,深度优先一探到底,不到底不回头。广度优先搜索步步为营,你探一步我探一步,均匀往外搜索。注:本文就不仔细讲这两种算法的细节了,如果不熟悉的话建议看一看《算法 第4版》 [美] Robert Sedgewick / [美] Kevin Wayne,图算法是我看过的最有意思的算法,强烈建议去看一看。
今天想分享的是在如何在图像上从一点开始往外(四周)遍历像素,并且是按照一个圆来遍历,比如就像下面这样,黄点是起始点,蓝色是遍历了10000步后覆盖到的像素。

你可能会问,这不就是画个圆吗?自然不是画圆啦,遍历是一个一个像素去遍历(搜索),是在特定任务条件要下用到的一种方法。比如我想搜索图像上离起始点最近的点,并且要符合一定条件的点,可能就要用到搜索算法。
首先这个基本上就用广优先算法啦,因为如果要按圆向外搜索,肯定就是步步为营,但是具体怎么搜索呢,每一个点的邻居像素怎么定呢?
一。上下左右
上下左右肯定是邻居像素麻,那就按广度优先搜索的思路,从起始点开始,看看上下左右4个点是否被访问过了,如果没访问过就标记为已访问,并且把它们加到队列中。然后从队列中取出下一个点,再看看它的上下左右4个点是否被访问过了,如果没访问过就标记为已访问,并且把它们加到队列中。然后从队列中取出下一个点,再看看它的上下左右4个点是否被访问过了。。。如此循环
先上代码(注,这里面用到的概率先忽略,在后面才会用到),细节看注释
import numpy as np
import cv2 as cv
from collections import deque
import random
import time
def get_circle_p():
# 获取邻居9宫格,这里只有上下左右是邻居
return np.array([[1, 1, 1], [1, 1, 1], [1, 1, 1]], dtype=np.float32).tolist()
class Area:
"""
搜索实例类
"""
def __init__(self, total_area, label_v, p_img, start_point):
self.total_area = total_area # 这就是要遍历的整个图像,这里用list是因为,遍历numpy.ndarray的速度会更慢
self.label_v = label_v # 标记像素被访问的时候用的标记值
self.p_img = p_img # 定义邻居用的9宫格图像,1表示必然是邻居,0-1之间表示民邻居的概率,0自然就肯定不是邻居啦(中心点忽略,它就是自己啦)
self.grow_count = 1 # 遍历次数,暂时没什么用
self.grow_edges = deque([start_point]) # 这就是文中说的队列,先把起始点加进去
x, y = start_point
total_area[y][x] = label_v # 标记起始点被访问了
def grow(self):
if not self.grow_edges:
return
px, py = self.grow_edges.popleft() # 取出下一个点,准备遍历它的邻居
r = len(self.p_img) // 2 # 9宫格邻居,半径就是1啦(不含中心点)
p_img = self.p_img
total_area = self.total_area
h = len(total_area)
w = len(total_area[0])
for x_add in range(-r, r + 1): # 遍历邻居像素
for y_add in range(-r, r + 1):
if x_add == 0 and y_add == 0: # 忽略自己
continue
tmp_x = px + x_add # 得到邻居的x,y坐标
tmp_y = py + y_add
if 0 <= tmp_x < w and 0 <= tmp_y < h and total_area[tmp_y][tmp_x] == 0 \
and random.random() <= p_img[y_add + r][x_add + r]: # 见上面p_img的说明
total_area[tmp_y][tmp_x] = self.label_v
self.grow_edges.append((tmp_x, tmp_y)) # 遍历了这个邻居,把它加到队列中,等待后面再遍历这个邻居的邻居
self.grow_count += 1
def grow_test():
img = np.zeros((400, 400, 3), dtype=np.uint8)
start_p1 = (200, 200)
label_v1 = 1
color1 = (255, 0, 0)
total_area = np.zeros((400, 400), dtype=np.uint8).tolist()
p_img = get_circle_p()
area1 = Area(total_area, label_v1, p_img, start_p1)
start_time = time.time()
for _ in range(10000):
area1.grow()
end_time = time.time()
print(f'耗时{end_time - start_time}毫秒')
total_area = np.array(total_area, dtype=np.uint8)
img[total_area == label_v1] = color1
cv.circle(img, start_p1, 10, (0, 255, 255), -1, cv.LINE_AA)
cv.imshow('img', img)
cv.waitKey(0)
cv.destroyAllWindows()
if __name__ == '__main__':
grow_test()
不对啊,是个棱形。em.....看来光是遍历上下左右肯定不行
二。8领域行不?
就是把左上左下右上右下也都算邻居,其实肯定不行啦,那肯定遍历出一个方形。完整代码就不贴了,直接用如下函数替换就行了
def get_circle_p():
# 获取邻居9宫格,这里只有上下左右是邻居
return np.array([[1, 1, 1], [1, 1, 1], [1, 1, 1]], dtype=np.float32).tolist()
果然是方的。
三。带概率的8邻域行不?
比如我在9宫格像素上画个抗剧齿的圆,得到的像素值都除以255,以这个为概率9宫格,这样4个角就不是每一次都必选了,会不会好一点。
用下面的函数替换
def get_circle_p(r=1):
w = r * 2 + 1
p_img = np.zeros((w, w), dtype=np.uint8)
cv.circle(p_img, (r, r), r, 255, -1, cv.LINE_AA)
p_img = np.array(p_img, np.float32)
p_img /= 255
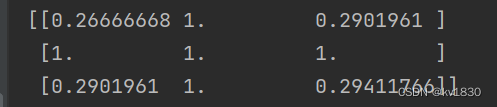
print(p_img)
return p_img.tolist()得到的概率值如下:
遍历图像如下:

好像是好了一点,但离圆还是差的有点远啊。当然还可以尝试一些别的概率,比如不是在9宫格上画圆来计算概率,而是在九九八十一个格子上画圆,然后把它们按9宫格求和,看起来这个概率是不是会更准一点?然后效果更差,就不试了。
四。按距圆心的远近来遍历
既然是想按圆来遍历,那肯定是先遍历最里面一圈,再遍历大一点的圈,再遍历大大一点的圈,同一个圈它们离圆心的距离肯定是相同的。当然你可能说你说的这是理论场景,现在是一格一格的像素,哪有一个真的圆圈,哪有一圈的距离都是相同的。但是只要我们按照由近再远的规则来遍历,那看上去就是近似一个圆。不信往下看!
直接上代码,细节看注释
import numpy as np
import cv2 as cv
import time
from heapq import heappop, heappush
def calc_distance(p1, p2):
return (p1[0] - p2[0]) ** 2 + (p1[1] - p2[1]) ** 2
class Area:
"""
搜索实例类
"""
def __init__(self, total_area, label_v, start_point):
self.total_area = total_area # 这就是要遍历的整个图像,这里用list是因为,遍历numpy.ndarray的速度会更慢
self.label_v = label_v # 标记像素被访问的时候用的标记值
self.grow_count = 1 # 遍历次数,暂时没什么用
self.grow_edges = []
# 这边用的是一个最小堆,放到最小堆里面的就是(distance, p),distance就是p点离起始点(圆心)的距离,p就是(x, y),
# 最小堆会以元组第1个值即distance来判断谁最小
heappush(self.grow_edges, (0, start_point))
self.start_point = start_point
x, y = start_point
total_area[y][x] = label_v # 标记起始点被访问了
def grow(self):
if not self.grow_edges:
return
distance, (px, py) = heappop(self.grow_edges) # 取出离起始点最近的候选点,准备遍历它的邻居,这边跟普通的队列可不一样了哦
r = 1
total_area = self.total_area
h = len(total_area)
w = len(total_area[0])
for x_add in range(-r, r + 1): # 遍历邻居像素
for y_add in range(-r, r + 1):
if x_add == 0 and y_add == 0: # 忽略自己
continue
tmp_x = px + x_add # 得到邻居像素的坐标
tmp_y = py + y_add
if 0 <= tmp_x < w and 0 <= tmp_y < h and total_area[tmp_y][tmp_x] == 0:
total_area[tmp_y][tmp_x] = self.label_v
distance = calc_distance((tmp_x, tmp_y), self.start_point)
heappush(self.grow_edges, (distance, (tmp_x, tmp_y))) # 把邻居加入最小堆
self.grow_count += 1
def grow_test():
img = np.zeros((400, 400, 3), dtype=np.uint8)
start_p1 = (200, 200)
label_v1 = 1
color1 = (255, 0, 0)
total_area = np.zeros((400, 400), dtype=np.uint8).tolist()
area1 = Area(total_area, label_v1, start_p1)
start_time = time.time()
for _ in range(10000):
area1.grow()
end_time = time.time()
print(f'耗时{end_time - start_time}毫秒')
total_area = np.array(total_area, dtype=np.uint8)
img[total_area == label_v1] = color1
cv.circle(img, start_p1, 10, (0, 255, 255), -1, cv.LINE_AA)
cv.imshow('img', img)
cv.waitKey(0)
cv.destroyAllWindows()
if __name__ == '__main__':
grow_test()肯定是一个圆了!

说明一下:
这里是通过最小堆这个数据结构来找距离圆心最近的下一个候选点。
最小堆的用法很简单,可以直接参考python官方文档里的示例

每往堆里放一个值,以及每从堆中获取一个最小值的算法复杂度都是log(n),而我们堆中存的都是遍历的边界点,所以其实点并不多,性能还是OK的(就算点多,log(n)也是能接受的)
关于最小堆的实现原理,还是建议看《算法 第4版》哦,里面有非常详细的解释。
五。我到底是啥具体场景用到这个算法了
其实是有朋友讨论了一个问题,一个图上有3个起始点,如何从3个起始点出发,把图像3等分。我就想到了这么个办法。就是搞3个Area实例,大家依次轮流遍历,我走一步,你走一步,最终不就是3等分了麻。不过我觉得这多半不是最好的办法,而且在部分情况下甚至有些失衡(做不到3分),最好的办法我也母鸡了,如果哪位高人知道,欢迎指点!但是在尝试的过程中,我对如何按圆遍历产生了兴趣,所以就做了各种尝试。
下面放几张用上面的方法3分的图像,3个黄点就是起始点,仅供娱乐~~
六。最后问一句,你觉得我这个算广度优先搜索吗?
![]()
![]()
![]()