论文阅读:Dual Supervised Learning
概述:
介绍:
 到
到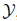 的映射以及到的映射。使用概率语言描述,原有的任务(primary task)学习一个参数为
的映射以及到的映射。使用概率语言描述,原有的任务(primary task)学习一个参数为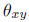 的条件
的条件
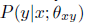 ,它的对偶的任务(dual task)学习一个参数为
,它的对偶的任务(dual task)学习一个参数为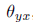 的条件分布
的条件分布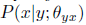 ,其中
,其中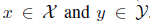 。
。
 有
有
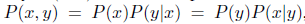 ,其中 。所以最初任务和对偶的任务满足:
,其中 。所以最初任务和对偶的任务满足: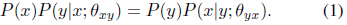 和。这样做的话,和的固有的概率的联系得到了加强,有助于推动学习得过程
和。这样做的话,和的固有的概率的联系得到了加强,有助于推动学习得过程
为了说明DSL的实用性,本文举例说明了DSL应用的三个方面:
(1)神经机器翻译(NMT)
(2)图像处理(Image Processing)
(3)情感分析(Sentiment Analysis)
这些应用体现了DSL的优越性
问题定义:
假定我们在空间
以下两个任务:
(1)最初(原始)的学习任务(primary task)是寻找一个函数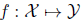
(2)对偶的学习任务(dual task)是寻找一个函数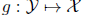
给定任意一个(x,y),令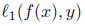
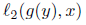
基于条件概率来对函数f 和函数 g做出定义:
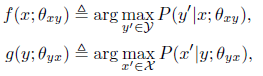
从上式看出,我们的目的就是求这样的参数
对于标准的有监督学习,通过在空间
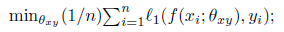
同理对于对偶的模型 g ,在空间
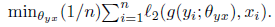
考虑着两个模型,如果他们学习的都很完美的话,那么有:
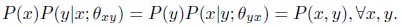
我们把这种特性称之为概率对偶性(probabilistic duality),这对于我们优化两个对偶的模型的学习过程是一个必备的条件。
对于标准的有监督学习,在训练中并没有考虑概率对偶性,最初的(原始的primary)模型和对偶的模型分别进行训练,因此
无法保证这两个具有对偶关系的模型满足概率对偶性。为了解决这个问题,我们提出通过解决下面的多目标优化问题(multi-objective optimization problem)
来明确强调了概率对偶性:

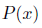
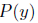
算法描述:
在实际的人工智能应用中,边缘分布的确切的值通常是不能直接获得的,于是我们使用经验上的边缘分布 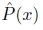
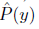
满足公式(2)的限制条件。为了解决DSL问题,使用常见的约束优化方法,引入拉格朗日数乘法,对目标函数增加概率对偶性的等式约束。
首先,将概率对偶性的约束转化为下面的正则项(包含经验上的边缘分布):
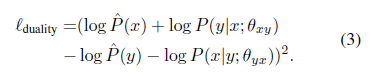
接下来,我们使用原来的损失函数结合这个正则项来不断学习这两个模型,算法如下:

在这个算法中,优化方法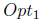
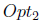
接下来本文分别在机器翻译,图像处理以及情感计算三个方面使用该模型(DSL)进行了与其他baseline的对比,说明了DSL的有效性。这里不再详述。
总结:
本文提出的DSL模型更像是一套解决存在对偶问题的机器学习问题的模版(一种新的范式?),根据本文的实验结果可以看出该模型确实具有很明确的优点。对偶学习这个概念是否能够很好的应用于更多的实际问题还有待实验论证。(学尚浅,没能力给出评论。。。)