目录
环境:
Centos7 (CentOS-7-x86_64-DVD-2009.iso) [ *3 虚拟机]
JDK1.8 (jdk-8u131-linux-x64.tar.gz)
Zookeeper-3.5.7 (apache-zookeeper-3.5.7-bin.tar.gz)
Kafka3.0.0 (kafka_2.12-3.0.0.tgz)
1、集群规划
| node1-130 | node2-131 | node3-132 |
|---|---|---|
| 192.168.220.130 | 192.168.220.131 | 192.168.220.132 |
| zk | zk | zk |
| kafka | kafka | kafka |
first of all 在 node1-130/ node2-131/ node3-132 三个节点上都上配置 hosts:
vim /etc/hosts在末尾添加:
192.168.220.130 node1-130
192.168.220.131 node2-131
192.168.220.132 node3-132secondly 关闭三个节点的防火墙
#查看状态:
systemctl status firewalld.service
#关闭防火墙
systemctl stop firewalld.service
#永久关闭防火墙
systemctl disable firewalld.service2、集群部署 (!!!前提是要有 JDK 环境 !!!)
官方下载地址:kafka:Apache Kafka
zookeeper:Apache ZooKeeper
3、zookeeper 集群安装部署
1)解压安装包(下载带 bin 的包!!!apache-zookeeper-3.5.7-bin.tar.gz,否则会报错 [狗头])
# cd /software
[root@node1-130 software]# tar -zxvf apache-zookeeper-3.5.7-bin.tar.gz -C /opt/module
[root@node2-131 software]# tar -zxvf apache-zookeeper-3.5.7-bin.tar.gz -C /opt/module
[root@node3-132 software]# tar -zxvf apache-zookeeper-3.5.7-bin.tar.gz -C /opt/module2)修改解压后的文件名称
# cd /opt/module
[root@node1-130 module]# mv apache-zookeeper-3.5.7-bin/ zookeeper-3.5.7
[root@node2-131 module]# mv apache-zookeeper-3.5.7-bin/ zookeeper-3.5.7
[root@node3-132 module]# mv apache-zookeeper-3.5.7-bin/ zookeeper-3.5.73)配置 服务器编号
1. 在 /opt/module/zookeeper-3.5.7/ 目录下创建 zkData
[root@node1-130 zookeeper-3.5.7]# mkdir zkData
[root@node2-131 zookeeper-3.5.7]# mkdir zkData
[root@node3-132 zookeeper-3.5.7]# mkdir zkData 2. 在 opt/module/zookeeper-3.5.7/zkData 目录下创建一个 myid 的文件
# cd /opt/module/zookeeper-3.5.7/zkData
[root@node1-130 zkData]# vi myid
内容为:
1
[root@node2-131 zkData]# vi myid
内容为:
2
[root@node3-132 zkData]# vi myid
内容为:
3(注意:上下不要有空行,左右不要有空格,且 数字一定要从1开始,否则报错!!!)
4)配置zoo.cfg文件
1. 重命名 /opt/module/zookeeper-3.5.7/conf 这个目录下的 zoo_sample.cfg 为 zoo.cfg
cd /opt/module/zookeeper-3.5.7/conf
[root@node1-130 conf]# mv zoo_sample.cfg zoo.cfg 2. 编辑 zoo.cfg 文件
[root@node1-130 conf]# vim zoo.cfg
#修改数据存储路径配置
dataDir=/opt/module/zookeeper-3.5.7/zkData
#增加如下配置:
#######################cluster##########################
server.1=node1-130:2888:3888
server.2=node2-131:2888:3888
server.3=node3-132:2888:3888 参数解读:
server.1=node1-130:2888:3888
server.A=B:C:D
A 是一个数字,表示这个是第几号服务器;集群模式下配置一个文件 myid,这个文件在 dataDir 目录下,这个文件里面有一个数据 A 值,Zookeeper 启动时读取此文件,拿到里面的数据与 zoo.cfg 里面的配置信息比较从而判断到底是哪个 server。
B 是这个服务器的地址;
C 是这个服务器 Follower 与集群中的 Leader 服务器交换信息的端口;
D 是万一集群中的 Leader 服务器挂了,需要一个端口来重新进行选举,选出一个新的 Leader,而这个端口就是用来执行选举时服务器相互通信的端口。 3. 同步 zoo.cfg 配置文件
[root@node1-130 conf]# xsync zoo.cfg如果出现:-bash: xsync: 未找到命令
执行以下步骤,编写 xsync 脚本:
① 安装 rsync
yum -y install rsync # 启动服务与开机自启动 systemctl start rsyncd.service systemctl enable rsyncd.service② 在 /root/bin 目录下创建 xsync 文件
cd /root/bin vim xsync粘贴以下内容:
#!/bin/bash #1. 获取输入参数个数,如果没有参数,直接退出 pcount=$# if [ $pcount -lt 1 ] then echo Not Enough Arguement! exit; fi #2. 遍历集群所有机器 for host in node1-130 node2-131 node3-132 ##更改自己的服务器域名 do echo ==================== $host ==================== #3. 遍历所有目录,挨个发送 for file in $@ do #4 判断文件是否存在 if [ -e $file ] then #5. 获取父目录 pdir=$(cd -P $(dirname $file); pwd) echo pdir=$pdir #6. 获取当前文件的名称 fname=$(basename $file) echo fname=$fname #7. 通过ssh执行命令:在$host主机上递归创建文件夹(如果存在该文件夹) ssh $host "mkdir -p $pdir" #8. 远程同步文件至$host主机的$USER用户的$pdir文件夹下 rsync -av $pdir/$fname $USER@$host:$pdir else echo $file does not exists! fi done done③ 给 xsync 添加权限:
chmod 777 xsync④ 添加全局变量
vim /etc/profile # 在末尾添加: PATH=$PATH:/root/bin export PATH # 退出,执行以下命令使其生效 source /etc/profile参考:
如果想执行 xsync 脚本时不用输入密码,需要配置 root 用户免密登录。这里必须要配置,不然起集群的时候会超时,然后某些节点就会启动失败。
root 用户免密登录配置:
① 在 ~./ssh 目录下生成一对密钥(3个节点都要生成)
cd ~/.ssh ssh-keygen -t rsa # 输入该命令后会有提示,一直回车即可 # 如果提示 【-bash: cd: .ssh: 没有那个文件或目录】 直接 ssh-keygen -t rsa 生成密钥就行② node1-130 节点中将公匙保存到 authorized_keys 文件中
[root@node1-130 .ssh]# cat id_rsa.pub >> authorized_keys③ 登录 node2-131 和 node3-132 节点,将其公钥文件内容拷贝到 node1-130 节点的 authorized_keys 文件中
# node2-131 节点的公钥拷贝 [root@node2-131 .ssh]# ssh-copy-id -i node1-130 # node3-132 节点的公钥拷贝 [root@node3-132 .ssh]# ssh-copy-id -i node1-130④ 在 node1-130 节点中修改权限(~/.ssh 目录 和 authorized_keys 文件)
[root@node1-130 .ssh]# chmod 700 ~/.ssh [root@node1-130 .ssh]# chmod 644 ~/.ssh/authorized_keys⑤ 将授权文件分发到其他节点上
# 拷贝到 node2-131 节点上 [root@node1-130 .ssh]# scp /root/.ssh/authorized_keys node2-131:/root/.ssh/ # 拷贝到 node3-132 节点上 [root@node1-130 .ssh]# scp /root/.ssh/authorized_keys node3-132:/root/.ssh/至此,免密码登录已经设定完成,注意第一次ssh登录时需要输入密码,再次访问时即可免密码登录
[root@node1-130 .ssh]# ssh node2-131 [root@node1-130 .ssh]# ssh node3-132参考:
5)集群操作
执行以下步骤,编写 zk.sh 脚本:
1. 创建 zk.sh 文件:
cd /root/bin vim zk.sh2. 粘贴以下内容:
#!/bin/bash case $1 in "start"){ for i in node1-130 node2-131 node3-132 do echo ------------- zookeeper $i 启动 ------------ ssh $i "/opt/module/zookeeper-3.5.7/bin/zkServer.sh start" done } ;; "stop"){ for i in node1-130 node2-131 node3-132 do echo ------------- zookeeper $i 停止 ------------ ssh $i "/opt/module/zookeeper-3.5.7/bin/zkServer.sh stop" done } ;; "status"){ for i in node1-130 node2-131 node3-132 do echo ------------- zookeeper $i 状态 ------------ ssh $i "/opt/module/zookeeper-3.5.7/bin/zkServer.sh status" done } ;; esac3. 给 zk.sh 脚本添加权限
[root@node1-130 bin]# chmod 777 zk.sh
启动 zookeeper 集群:
[root@node1-130 module]# zk.sh start查看 zookeeper 集群状态:
[root@node1-130 module]# zk.sh status停止 zookeeper集群:
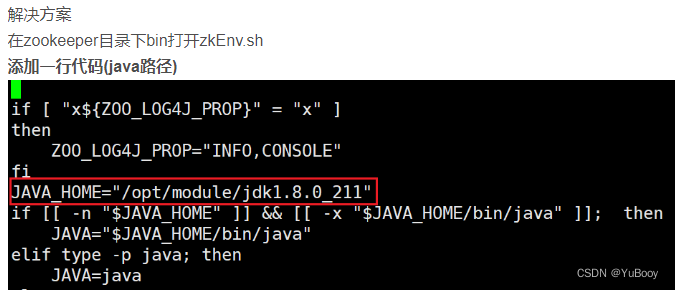
[root@node1-130 module]# zk.sh stop报错:Error: JAVA_HOME is not set and java could not be found in PATH
参考:Error: JAVA_HOME is not set and java could not be found in PATH._Knight_AL的博客-CSDN博客
本教程操作: 通过 vim /etc/profile 查看 jdk 的安装路径:JAVA_HOME=/usr/local/java/jdk1.8.0_131 cd /opt/module/zookeeper-3.5.7/bin [root@node1-130 bin]# vim zkEnv.sh # 在上图位置插入以下内容: JAVA_HOME=/usr/local/java/jdk1.8.0_131 # 分发到其它节点 [root@node1-130 bin]# xsync zkEnv.sh
集群启动出现问题的参考:【已解决】zookeeper显示Error contacting service. It is probably not running等问题_暴走的Mine的博客-CSDN博客
4、kafka 集群安装部署
1)解压安装包
# cd /software
[root@node1-130 software]# tar -zxvf kafka_2.12-3.0.0.tgz -C /opt/module/
[root@node2-131 software]# tar -zxvf kafka_2.12-3.0.0.tgz -C /opt/module/
[root@node3-132 software]# tar -zxvf kafka_2.12-3.0.0.tgz -C /opt/module/2)修改解压后的文件名称
# cd /opt/module
[root@node1-130 module]# mv kafka_2.12-3.0.0/ kafka
[root@node2-131 module]# mv kafka_2.12-3.0.0/ kafka
[root@node3-132 module]# mv kafka_2.12-3.0.0/ kafka3)进入到 /opt/module/kafka 目录,修改配置文件
# cd /opt/module/kafka/config
[root@node1-130 config]# vim server.properties修改以下内容:
#broker 的全局唯一编号,不能重复,只能是数字。
broker.id=0
#kafka 运行日志(数据)存放的路径
log.dirs=/opt/module/kafka/datas
#配置连接 Zookeeper 集群地址(在 zk 根目录下创建/kafka,方便管理 zk 文件)
zookeeper.connect=node1-130:2181,node2-131:2181,node3-132:2181/kafka4)分发安装包
[root@node1-130 module]# xsync kafka/5)分别在 node2-131 和 node2-132 上修改配置文件 /opt/module/kafka/config/server.properties 中的 broker.id=1、broker.id=2
注:broker.id 不得重复,整个集群中唯一
[root@node2-131 module]# vim kafka/config/server.properties
修改:
# The id of the broker. This must be set to a unique integer for each broker.
broker.id=1
[root@node3-132 module]# vim kafka/config/server.properties
修改:
# The id of the broker. This must be set to a unique integer for each broker.
broker.id=26)配置环境变量
① 在 /etc/profile.d/my_env.sh 文件中增加 kafka 环境变量配置
[root@node1-130 ~]# vim /etc/profile.d/my_env.sh 添加如下内容:
#KAFKA_HOME
export KAFKA_HOME=/opt/module/kafka
export PATH=$PATH:$KAFKA_HOME/bin ② 刷新一下环境变量
[root@node1-130 ~]# source /etc/profile ③ 分发环境变量文件到其他节点,并 source
[root@node1-130 ~]# xsync /etc/profile.d/my_env.sh
# 在另外两个节点生效环境变量:
[root@node2-131 ~]# source /etc/profile
[root@node3-132 ~]# source /etc/profile7)启动集群
① 启动 zookeeper 集群
[root@node1-130 module]# zk.sh start ② 启动 kafka 集群
[root@node1-130 module]# kf.sh start执行以下步骤,编写 kf.sh 脚本:
创建 kf.sh 文件:
cd /root/bin vim kf.sh2. 粘贴以下内容:
#!/bin/bash case $1 in "start"){ for i in node1-130 node2-131 node3-132 do echo ------------- zookeeper $i 启动 ------------ ssh $i "/opt/module/kafka/bin/kafka-server-start.sh -daemon /opt/module/kafka/config/server.properties" done } ;; "stop"){ for i in node1-130 node2-131 node3-132 do echo ------------- zookeeper $i 停止 ------------ ssh $i "/opt/module/kafka/bin/kafka-server-stop.sh" done } ;; esac3. 给 kf.sh 脚本添加权限
[root@node1-130 bin]# chmod 777 kf.sh
kafka 集群启动遇到了问题:可以去 cat kafka/logs 看看报什么错
我遇到的问题是:执行 kf.sh start ,node1-130 节点 kafka 节点能启动,但是另外两个节点起不来,去另外两个节点看日志 cat /opt/module/kafka/logs/kafkaServer.out 显示:
nohup: 无法运行命令"java": 没有那个文件或目录
解决方法:上面的 kf.sh 脚本中,启动和停止语句加上:source /etc/profile && 即:
ssh $i "source /etc/profile && /opt/module/kafka/bin/kafka-server-start.sh -daemon /opt/module/kafka/config/server.properties"
ssh $i "source /etc/profile && /opt/module/kafka/bin/kafka-server-stop.sh"
③ 验证 kafka 集群是否安装启动成功
# 创建一个 topic 分 3 个区
[root@node1-130 kafka]# /opt/module/kafka/bin/kafka-topics.sh --bootstrap-server node1-130:9092 --create --partitions 3 --replication-factor 3 --topic first
# 然后 3 个节点都看看有没有 first 这个 topic,有则恭喜你,排除万难集群安装部署成功了
[root@node1-130 kafka]# /opt/module/kafka/bin/kafka-topics.sh --bootstrap-server node1-130:9092 --list
[root@node1-131 kafka]# /opt/module/kafka/bin/kafka-topics.sh --bootstrap-server node2-131:9092 --list
[root@node1-132 kafka]# /opt/module/kafka/bin/kafka-topics.sh --bootstrap-server node2-132:9092 --list④ 停止 kafka 集群
[root@node1-130 module]# kf.sh stop⑤ 停止 Zookeeper 集群
[root@node1-130 module]# zk.sh stop注意:停止 Kafka 集群时,一定要等 Kafka 所有节点进程全部停止后再停止 Zookeeper 集群。因为 Zookeeper 集群当中记录着 Kafka 集群相关信息,Zookeeper 集群一旦先停止,Kafka 集群就没有办法再获取停止进程的信息,只能手动杀死 Kafka 进程了。
5、Centos7 单节点部署 kafka
① 配置 JDK
# 下载 jkd8
wget --no-check-certificate --no-cookies --header "Cookie: oraclelicense=accept-securebackup-cookie" http://download.oracle.com/otn-pub/java/jdk/8u131-b11/d54c1d3a095b4ff2b6607d096fa80163/jdk-8u131-linux-x64.tar.gz
# 创建安装目录
mkdir /usr/local/java
# 解压至安装目录
tar -zxvf jdk-8u131-linux-x64.tar.gz -C /usr/local/java/
# 设置环境变量
vim /etc/profile
# 在末尾添加
export JAVA_HOME=/usr/local/java/jdk1.8.0_131
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
# 使环境变量生效
source /etc/profile
# 检查
java -version② 安装配置 kafka
# 解压安装包
cd /software
[root@centos70 software]# tar -zxvf kafka_2.12-3.0.0.tgz -C /opt/module/
# 修改解压后的名称
cd /opt/module
[root@centos7 module]# mv kafka_2.12-3.0.0/ kafka
# 修改 kafka 配置文件 /opt/module/kafka/config/server.properties
cd /opt/module/kafka/config
vim server.properties
# 配置:
# 1.删除此行注释,并加上本机 ip 地址
listeners=PLAINTEXT://192.168.220.129:9092
# 2.zookeeper 添加本机 ip 地址
zookeeper.connect=192.168.220.129:2181
# 启动 zookeeper (kafka 自身包含了 zookeeper ,所以在 bin 目录下有 zookeeper 的启动脚本)
cd /opt/module/kafka
[root@centos7 kafka]# bin/zookeeper-server-start.sh -daemon config/zookeeper.properties
# 启动 kafka
cd /opt/module/kafka
[root@centos7 kafka]# bin/kafka-server-start.sh -daemon config/server.properties
# 可以使用 jps 查看 zookeeper 和 kafka 是否正常运行
[root@centos7 kafka]# jps
1924 QuorumPeerMain # 说明 zookeeper 正常运行
2265 Kafka # 说明 kafka 正常运行
2377 Jps
# 添加一个 topic
[root@centos7 kafka]# /opt/module/kafka/bin/kafka-topics.sh --bootstrap-server 192.168.220.129:9092 --create --partitions 1 --replication-factor 3 --topic test
# 查看 topic 列表
[root@centos7 kafka]# /opt/module/kafka/bin/kafka-topics.sh --bootstrap-server 192.168.220.129:9092 --list