写在前面
- 若有图片加载失败,请科学上网 。
- 本文为对软件学院张老师提供的教学课本总结所得的复习笔记,为大量课本截图,仅供参考。不保证对考点的全覆盖,以课本为主。
目前第二本书还差 3 章没有做笔记,后面会慢慢补全。- 写的比较匆忙,有遗漏、错误之处敬请指正。
2023/6/7(又补了一章Gated RNN,怕来不及做后面两章,各位最后两章可以先看看书。)
2023/6/8 0:02 又更了一章,伙计们,暂时更不动了,我先复习了。复习的好的话更新最后一章。
2023/6/8 0:59 还是补全了,各位加油!都考个好成绩!
2023/6/8 18:00 考完了,笔记对考点全覆盖,属于有效复习。
文章目录
深度学习入门
二、感知机
感知机接收多个输入信号,输出一个信号。感知机的信号只有(1/0)两种取值。
具体地说,w1 和w2 是控制输入信号的重要性的参数,而偏置是调整神经元被激活的容易程度(输出信号为1 的程度)的参数。
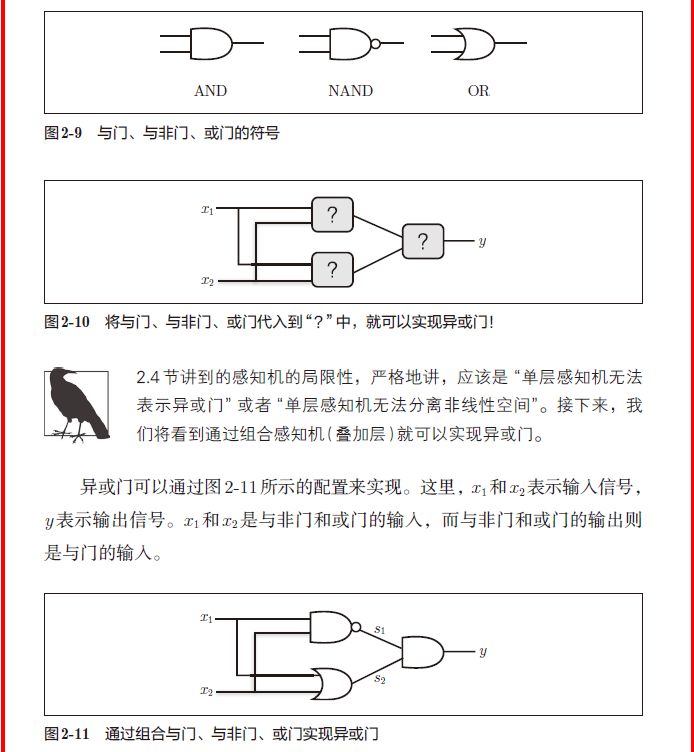
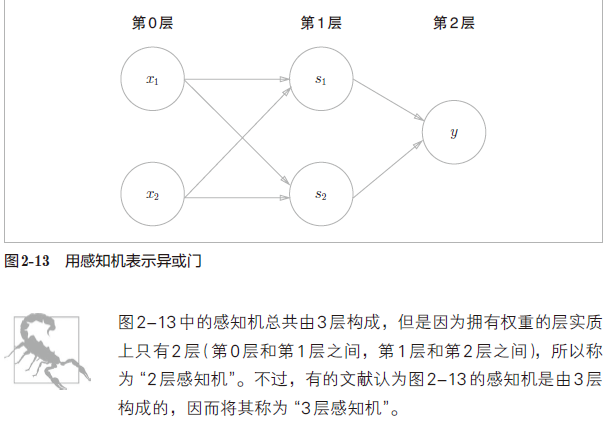
三、神经网络引入

1、激活函数

阶跃函数
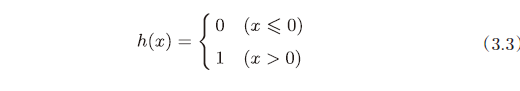
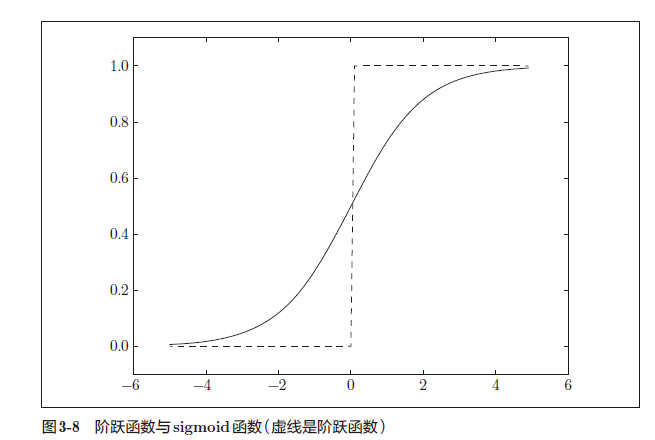
sigmoid

sigmoid与阶跃函数比较

ReLU函数

线性激活函数的问题

2、神经网络矩阵乘法
矩阵乘法示例
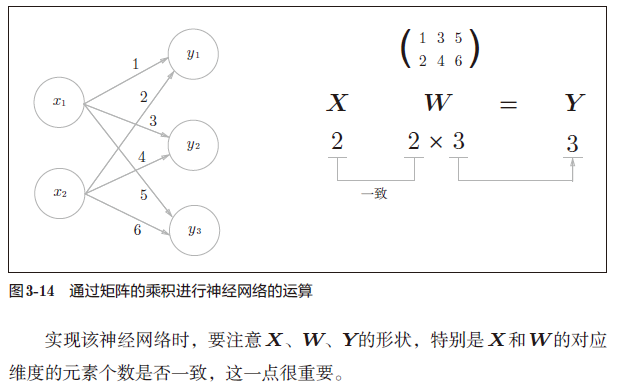
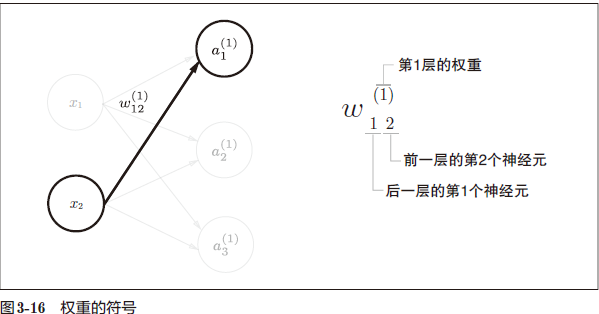
符号规范
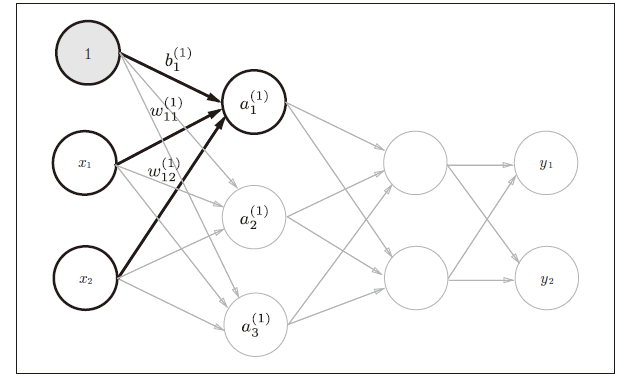
前向传播
3、输出函数
a. 恒等函数
b. softmax函数

改进
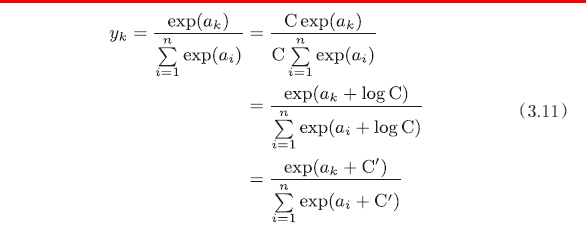
softmax特性

4、神经网络推理阶段
a. 正规化

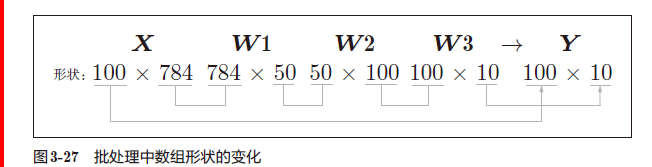
b. 批处理

四、神经网络学习
数据驱动的,从数据中学习。
1、神经网络训练的相关概念
训练数据
用来对模型进行训练学习的数据,寻找最优的参数。
测试数据
测试模型的泛化能力的数据。
泛化能力
指模型在训练数据上学习到一些知识后,处理应对未被观察(学习)过的数据的能力。
过拟合
只对某个数据集过度拟合的状态,学习到了数据的个性,忽视了共性。

损失函数
神经网路以某个指标来表示当前的态,并以此为线索来寻找最优参数,这个指标就是损失函数。
均方误差函数

交叉熵误差


mini-batch
小批量学习,一次性计算所有数据的loss太慢,需要一点一点算。
为什么需要loss函数?

微调参数,而精度不变,精度是离散的。
loss是连续的,可以对参数的微调有变化。

2、数值微分

梯度

梯度下降法

学习率


3、神经网络学习步骤


真随机,遍历一次不一定所有数据都观察到。
五、误差反向传播
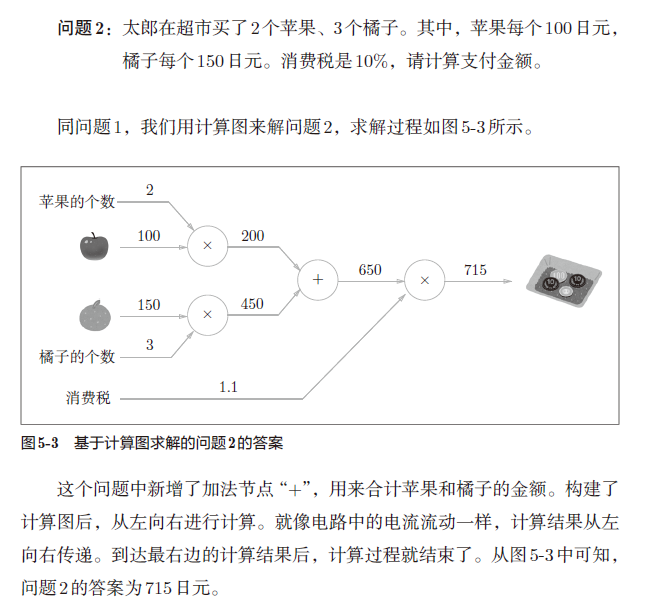
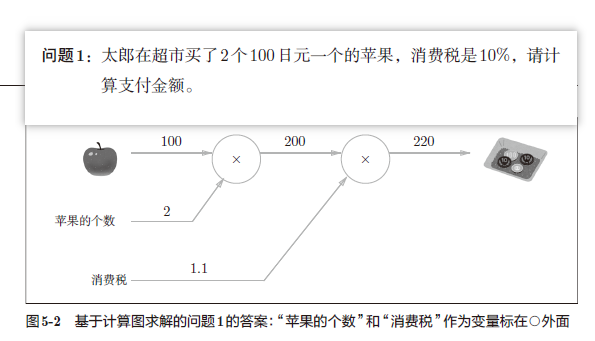
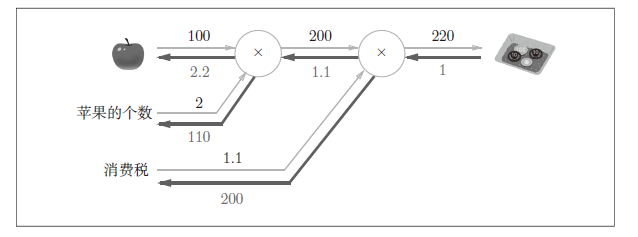
计算图求解
示例
计算图特点

可以利用它通过反向传播(链式求导法则)高效计算导数。
计算图与反向传播
其实就是从后往前链式求偏导。
这里的例子是 t = x + y , z = t 2 t = x+y, z = t^2 t=x+y,z=t2
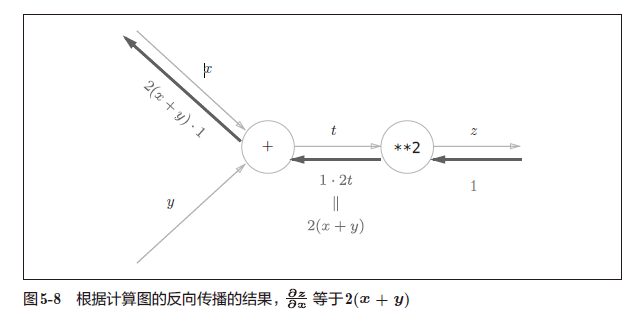
换个简单的例子:
反向传播计算:
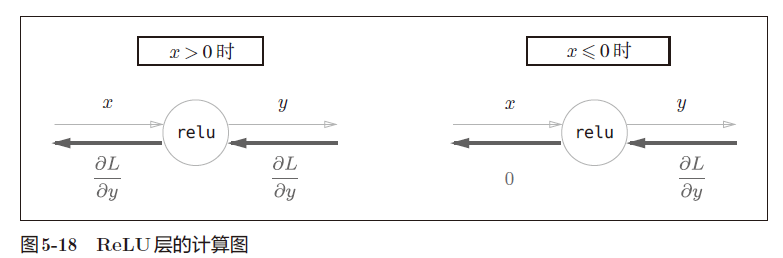
激活函数反向传播
ReLU

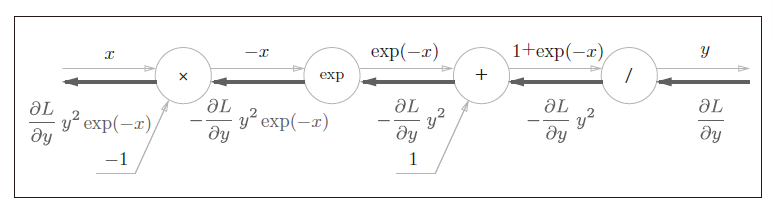
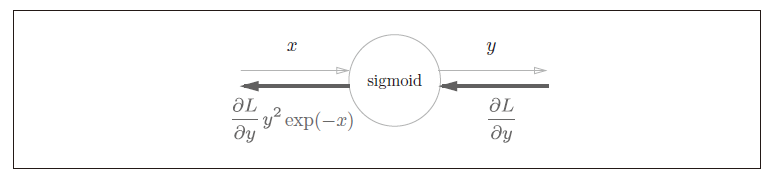
Sigmoid
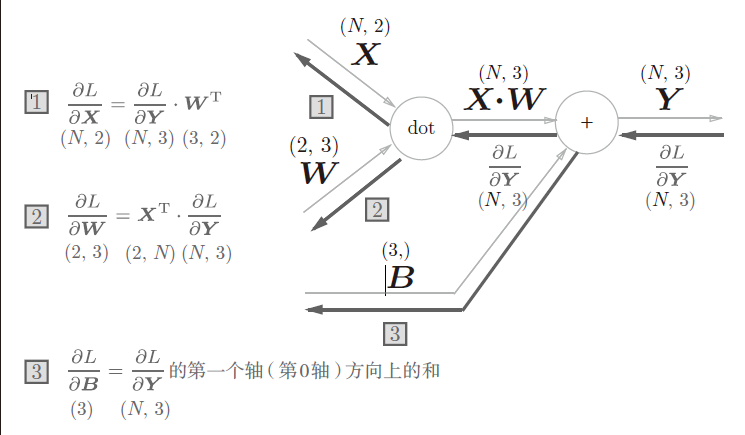
Affine层
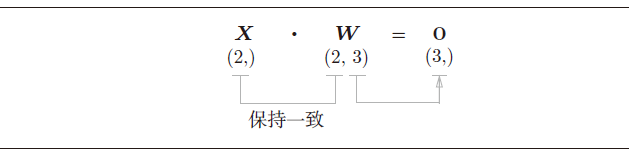
(这里矩阵乘法形状有些怪异,写的是列向量,实际计算中按行向量计算,结果写成行向量即可)
一个输入
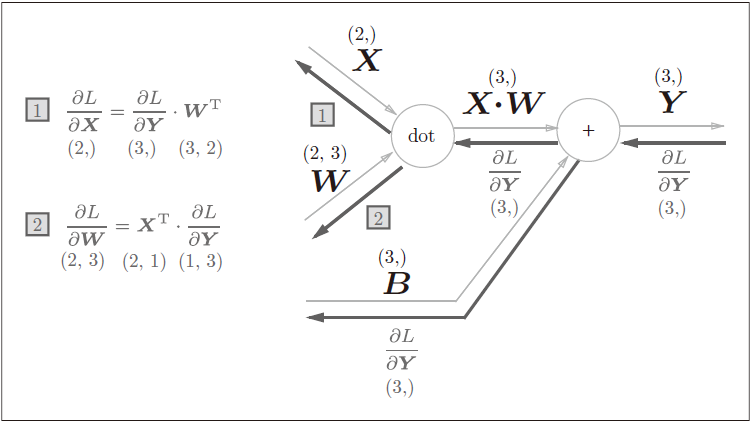
批版本计算
Softmax-with-Loss层
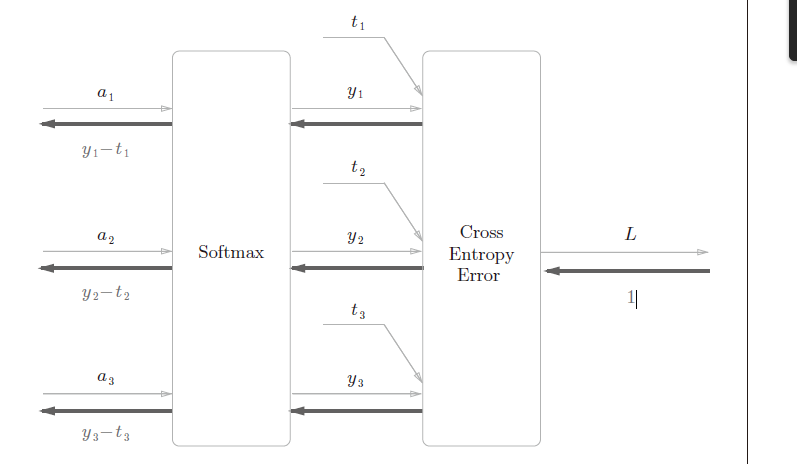
t i t_i ti 是标签, y i y_i yi 是 softmax 的输出。

梯度确认

六、与学习相关的技巧
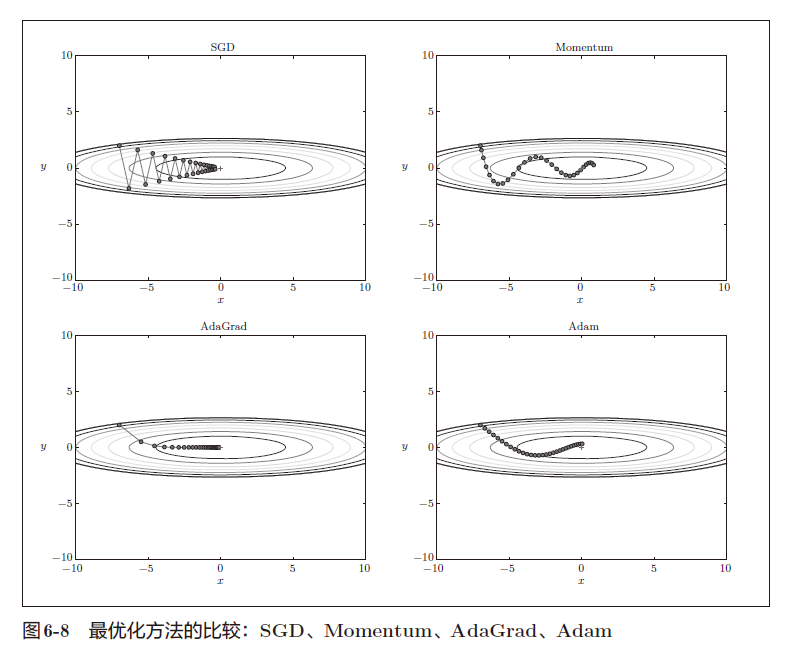
1、优化器的选取(下降方法)
a. SGD
SGD在椭圆空间下降会走之字形。
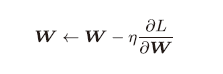
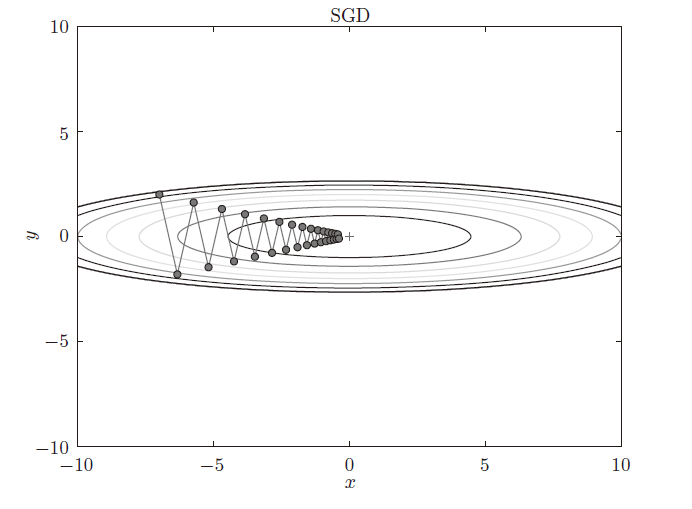
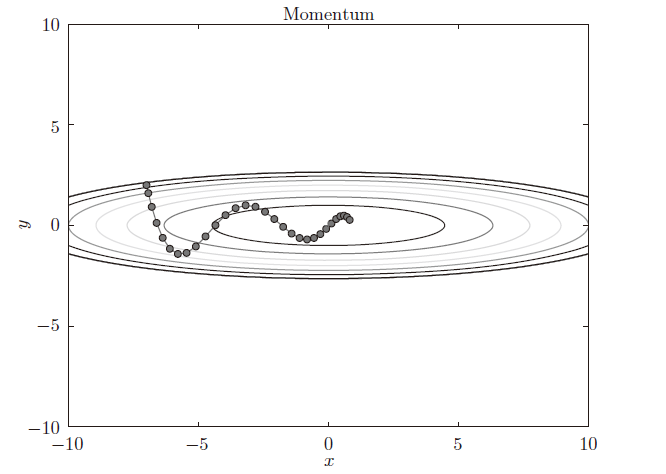
b. Momentum

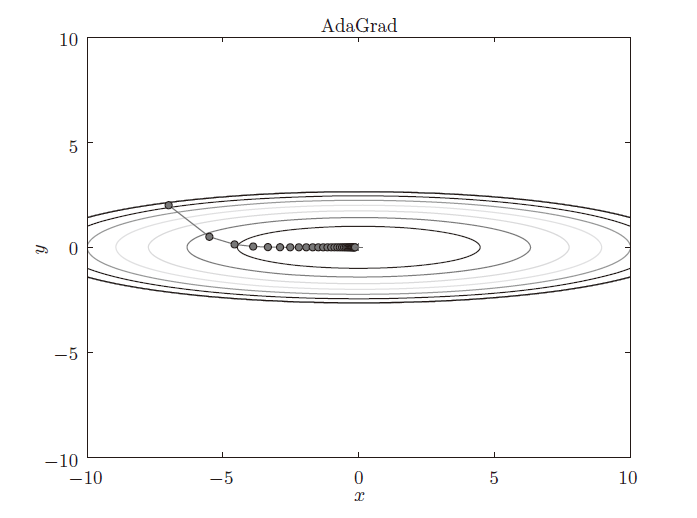
c. AdaGrad


d. Adam
融合Momentum和AdaGrad的方法。
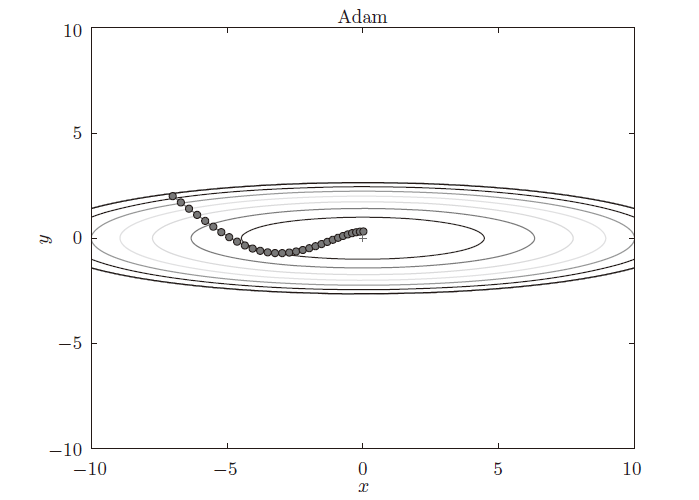
e. 多种方法比较
2、权重的初始值
不能全部初始为0,或者全部初始化相同。否则在误差反向传播法中,所有的权重值都会进行相同的更新。
如果是sigmoid函数,随着输出不断地靠近0(或者靠近1),它的导数的值逐渐接近0。偏向 0 和 1 的数据分布会造成反向传播中梯度的值不断变小,最后消失。这个问题称为梯度消失(gradient vanishing)。
a. 利用Xavier 初始值
sigmoid、tanh适用,初始化使用标准差为 1 n \sqrt {\frac{1}{n}} n1 (n为前一层节点数)的分布。
b. He 初始值
使用标准差为 2 n \sqrt {\frac{2}{n}} n2 的高斯分布,ReLU适用。
3、批归一化
batch norm 的优点:
- 可以使学习快速进行(可以增大学习率)。
- 不那么依赖初始值(对于初始值不用那么神经质)。
- 抑制过拟合(降低Dropout等的必要性)。

4、正则化
过拟合
原因

权值衰减

Dropout
学习过程中随即删除神经元。

5、超参数的验证
超参数的最优化
逐渐缩小超参数的“好值”的范围。

七、卷积神经网络
1、卷积层
a. 全连接层的问题
忽视了数据的形状(3维数据被拉伸到1维)。
卷积层的输入输出称为输入(输出)特征图。
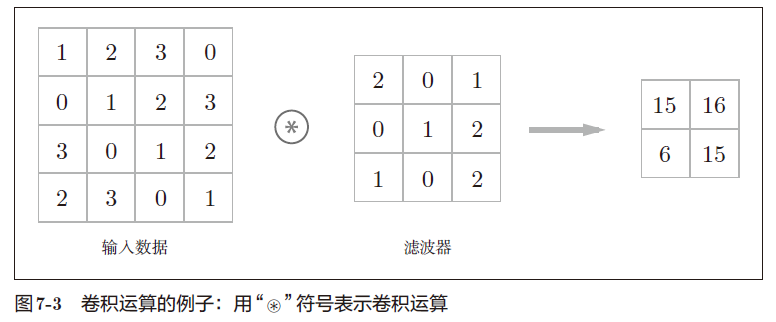
b. 卷积运算

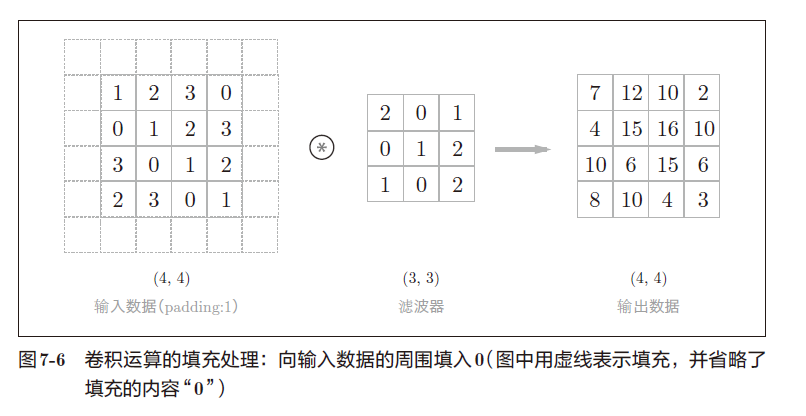
c.填充
为了调整输出的大小
d.步幅
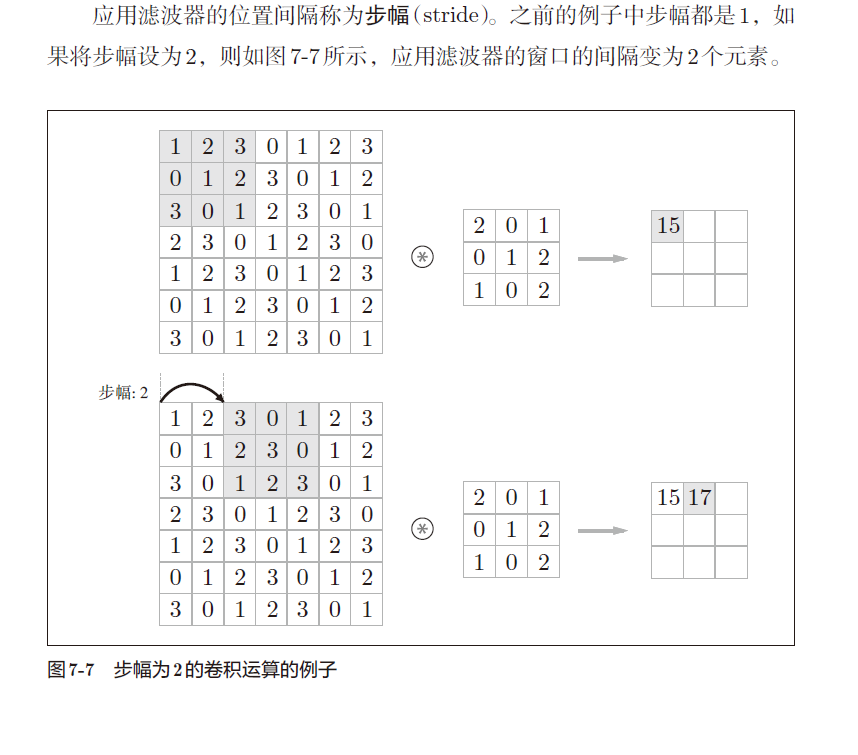
e. 根据参数计算图像大小

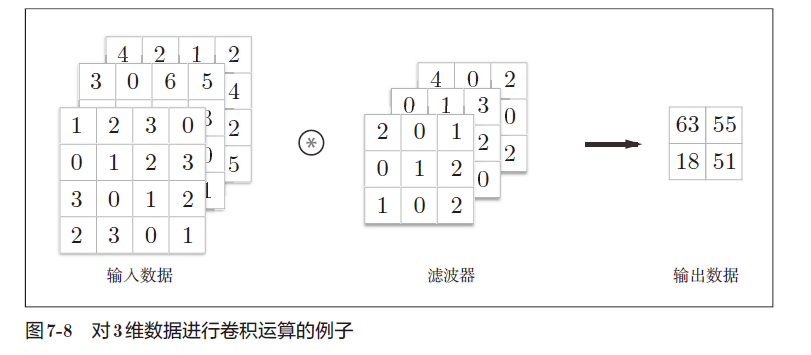
f. 三维卷积
每层通道卷积相加
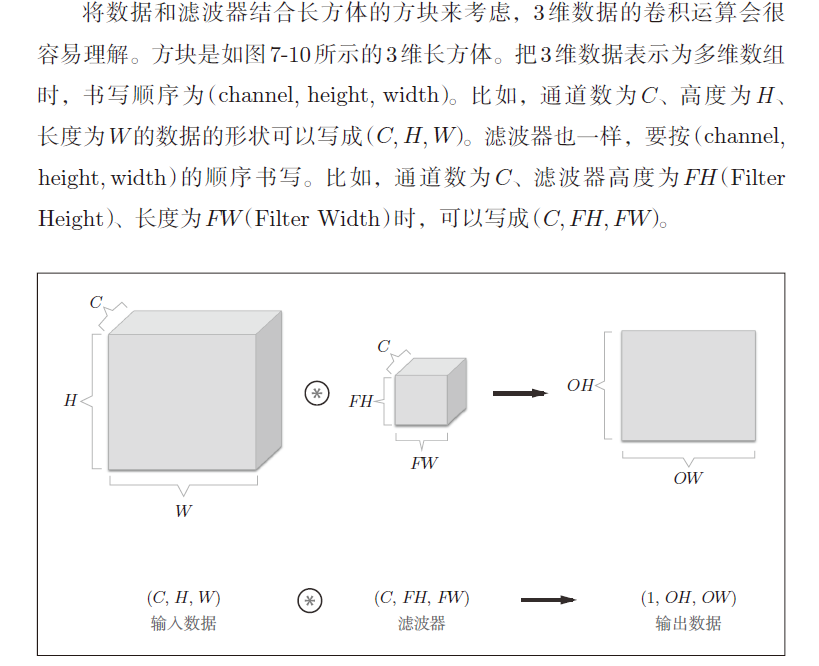
多个卷积核,在通道层面上得到多个卷积输出。
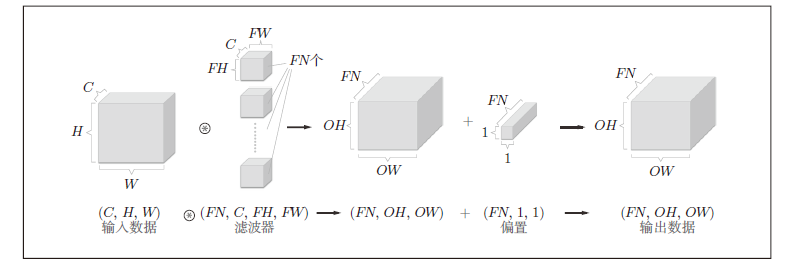
批处理卷积操作。
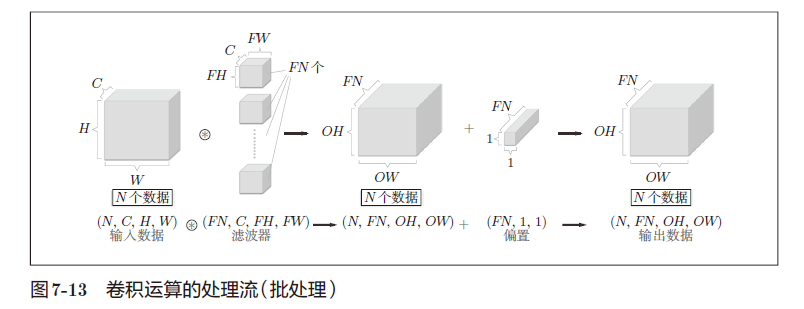
2、池化层
是为了缩小高、长方向的运算。有MAX、Average等池化方法。
a. 池化层例子
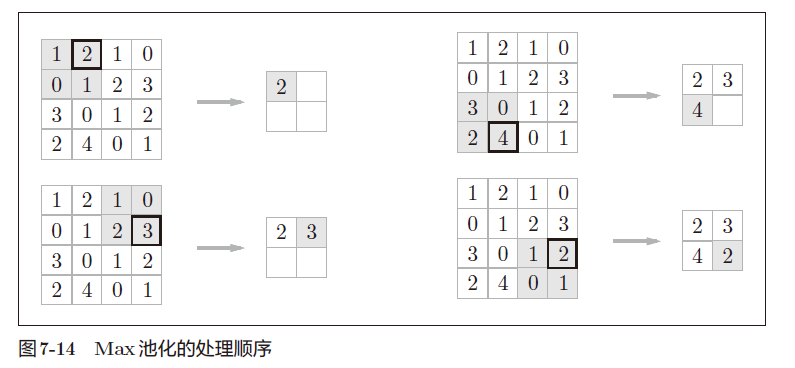
b. 池化层特征


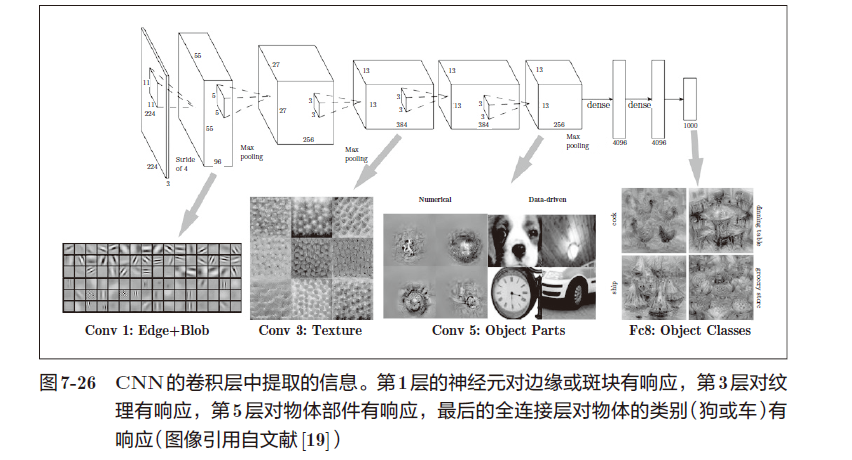
3、CNN可视化

4、具有代表性的CNN
1、LeNet
2、AlexNet
3、VGG
4、GoogleNet
5、ResNet
八、深度学习
1、加深网络
a. 动机



深度学习进阶
二、自然语言和单词的分布式表示
1、自然语言处理
我们平常使用的语言,如日语或英语,称为自然语言(natural language)。所谓自然语言处理(Natural Language Processing,NLP),顾名思义,就是处理自然语言的科学。
三种方法
- 基于同义词词典的方法
- 基于计数的方法
- 基于推理的方法(word2vec)
2、同义词词典
a. 定义
在同义词词典中,具有相同含义的单词(同义词)或含义类似的单词(近义词)被归类到同一个组中。

有时会定义更细粒度的关系:上位-下位、整体-部分……
b. 缺点
- 难以顺应时代变化
- 人力成本高
- 无法表示单词的微妙差异
3、基于计数的方法
a. 语料库
大量的文本数据。
b. 分布式表示
分布式表示将单词表示为固定长度的向量。这种向量的特征在于它是用密集向量表示的。
c. 分布式假设
猜想某个单词的含义由它周围的单词形成,这种想法就是分布式假设。
窗口大小:将上下文的大小(即周围的单词有多少个)称为窗口大小。

d. 共现矩阵
各行对应相应单词的向量,值为对应向量在该单词周围出现的次数。(滑动窗口定为某个值)
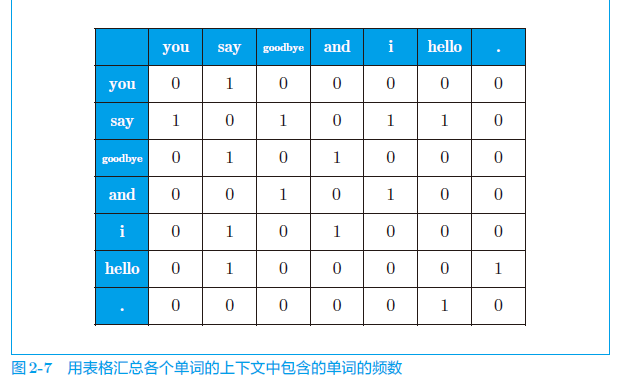
根据共现矩阵可以获得单词的向量表示。
e.向量间相似度
余弦相似度
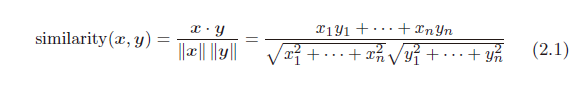
f. 向量相似度排序

4、计数方法改进
直接使用共现矩阵的缺点:the 跟 car 比 drive 跟 car 更接近,违背真实情况。
a. 点互信息
使用点互信息,即综合考虑单词在句子中出现的次数与单词与其他单词的共现次数。
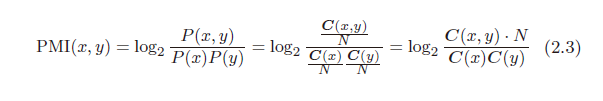
C ( x ) / C ( y ) C(x) / C(y) C(x)/C(y) 表示单词x 或 y 在句子中出现的次数。
C ( x , y ) C(x, y) C(x,y) 表示单词共现的次数。
b. 正点互信息
即对点互信息 PMI 与 0 取 max :
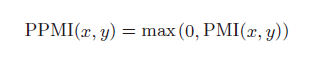

c. 降维
可以看到上述矩阵比较稀疏,容易受到噪声影响。需要对向量进行降维(保留信息的前提下)。
基于奇异值分解的降维

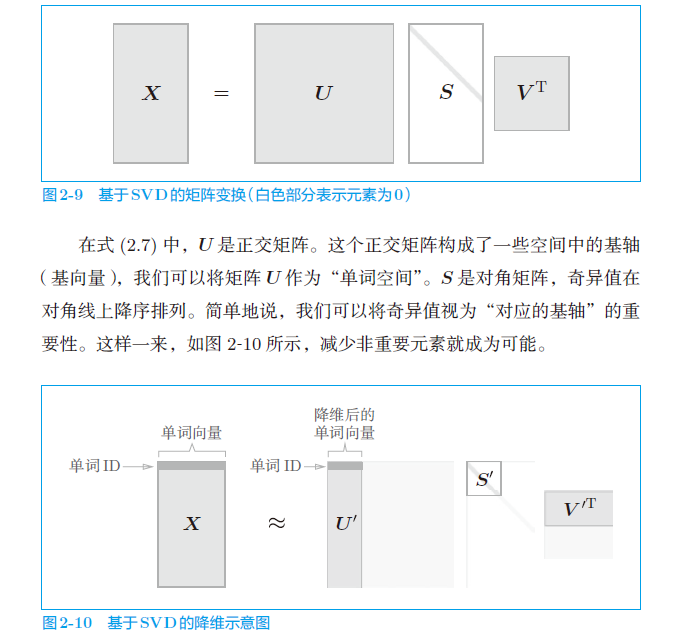
小结

三、word2vec
现实中语料库处理的单词数量相当大,若单词有100w个,则共现矩阵维度为100w×100w 的, 难以做奇异值分解。
基于推理的方法使用神经网络,面对庞大的数据只需要进行 mini-batch 学习。多机器并发。
word2vec 一词最初用来指程序或者工具,但是随着该词的流行,在某些语境下,也指神经网络的模型。正确地说,CBOW模型和skip-gram 模型是word2vec 中使用的两个神经网络。
1、基于推理的方法

2、神经网络中单词的处理方法
使用神经网络,输入值必须为向量,不能直接处理,就要先把单词进行初步向量表示。可以使用 one-hot,有多少个单词(集合,要去重),就用多少个输入神经元的神经网络。
3、CBOW模型
利用上下文预测目标此的神经网络。对上下文考虑N个单词,就有N个输入层。
当 N = 2 时,网络结构如下:
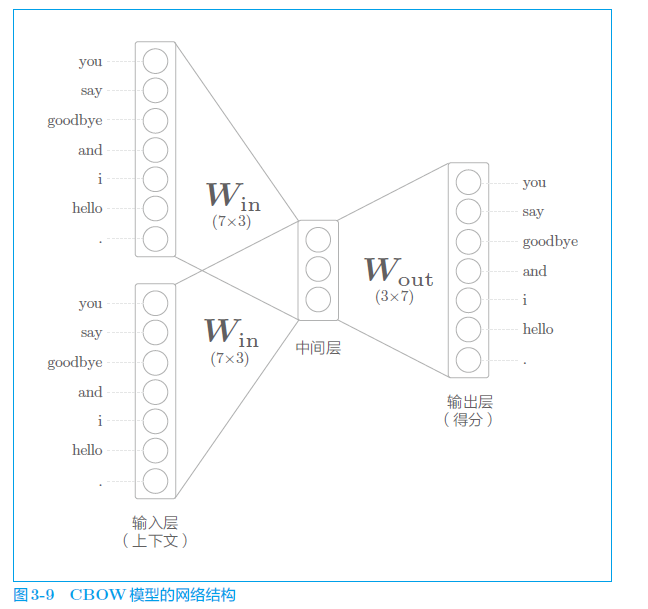
学习到的 W i n W_{in} Win 权重矩阵就是词的向量表示。
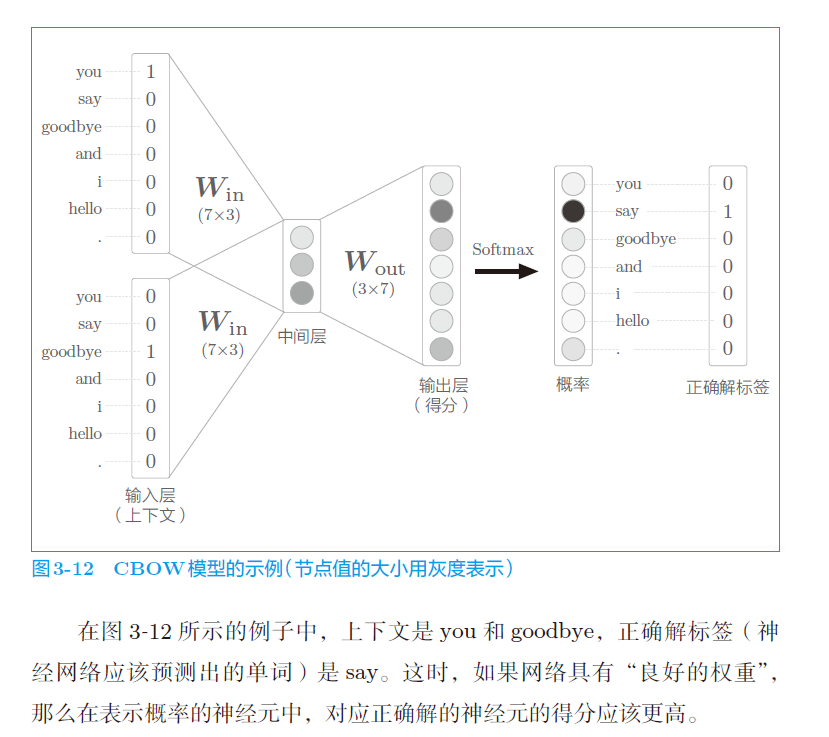
形象化表示:
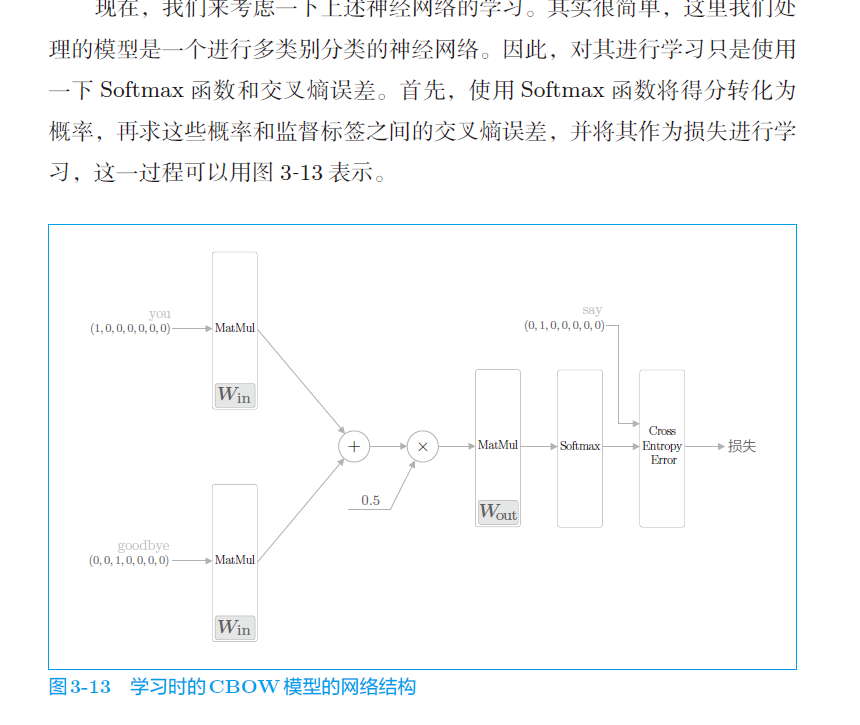
4、word2vec 的权重和分布式表示
有两个权重,都可以表示,用哪个?
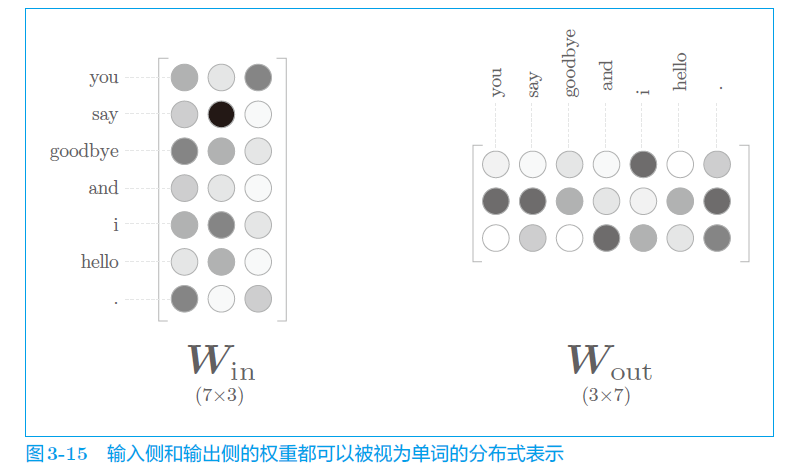
三种选择:
- 只用 W i n W_{in} Win ;
- 只用 W o u t W_{out} Wout ;
- 同时使用前两者。
一般只用 W i n W_{in} Win
5、skip-gram概率模型
可以理解成反转了的的CBOW,根据中心词预测上下文。
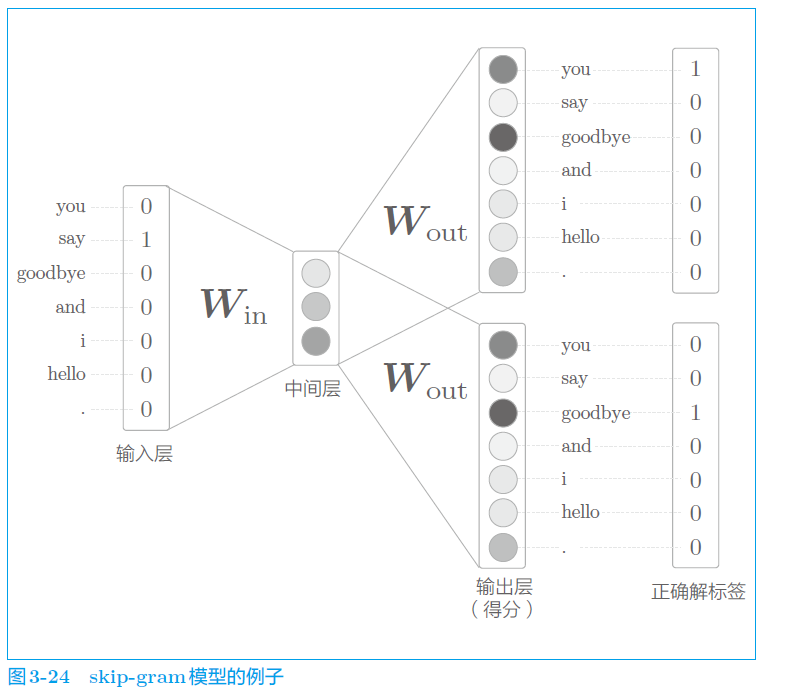

6、基于计数和基于推理的对比
- 基于计数的方法通过对整个语料库的数据进行一次学习获得单词的分布式表示,而基于推理的方法是反复利用批数据进行学习(mini-batch)。
- 若需要向词汇表添加新词,基于计数的方法需要全部从头计算,基于推理的方法允许增量学习。
- 基于计数的方法是根据单词的相似度,而基于推理的还能理解词与词之间的模式关系。
7、小结

四、word2vec 的高速化
1、问题
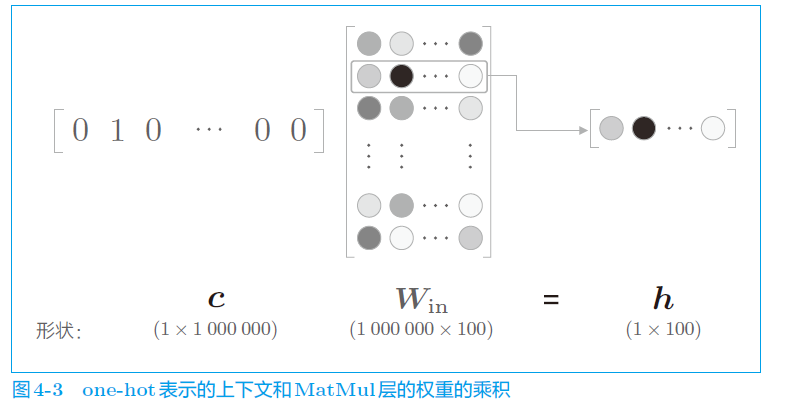
- 当词汇量增大时,输入one-hot维度巨大,输入、输出层的节点数巨大。
- 随着词汇量增大,中间层的神经元和权重矩阵 W o u t W_{out} Wout 相乘巨慢,Softmax层的计算量也增加,十分缓慢。
2、解决
a. 对第一个问题剖析
考虑如下计算,其实就是取W矩阵中的某一行,但是计算耗费资源:
插播:
单词的密集向量表示称为词嵌入或者单词的分布式表示。
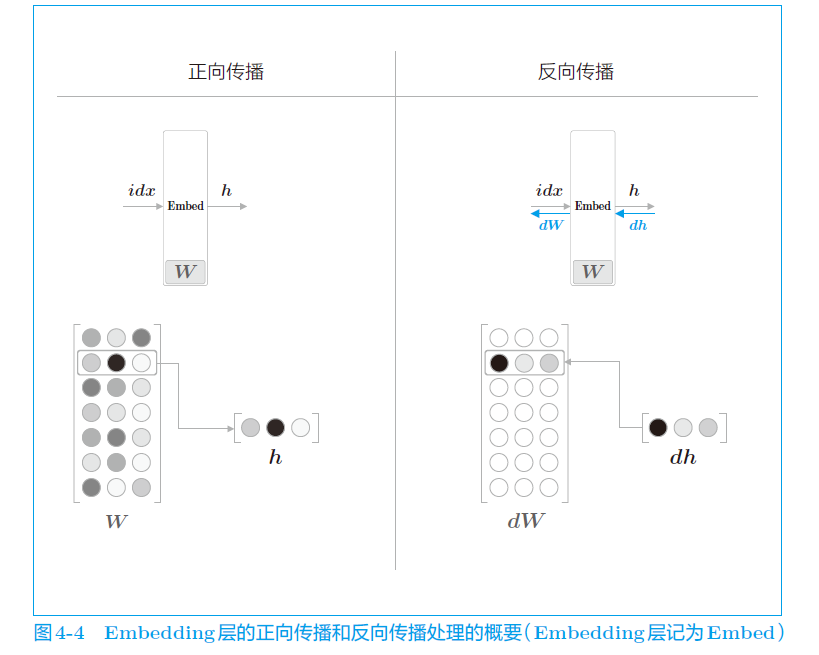
b. Embedding 层的工作
接下来,我们考虑反向传播。Embedding 层的正向传播只是从权重矩阵W 中提取特定的行,并将该特定行的神经元原样传给下一层。因此,在反向传播时,从上一层(输出侧的层)传过来的梯度将原样传给下一层(输入侧的层)。不过,从上一层传来的梯度会被应用到权重梯度dW 的特定行(idx)。
简述:正向传播时,直接提取 idx 的行传递给下一层。反向传播时,把拿到的某几行的梯度,转换成 W 形状的矩阵dW,还给上一层。当 idx 有重复的时候(比如0,2,0,3),返回梯度时把0的梯度相加,而不是覆盖。
c. 负采样
解决前面提到的第二个问题,方法就是进行**负采样**。
问题转化
把多分类问题转化成二分类问题:
-
给几个上下文,问中心词是什么?
-
转换成:给几个上下文,再给出中心词,问他是不是中心词?
-
用图来表示网络结构
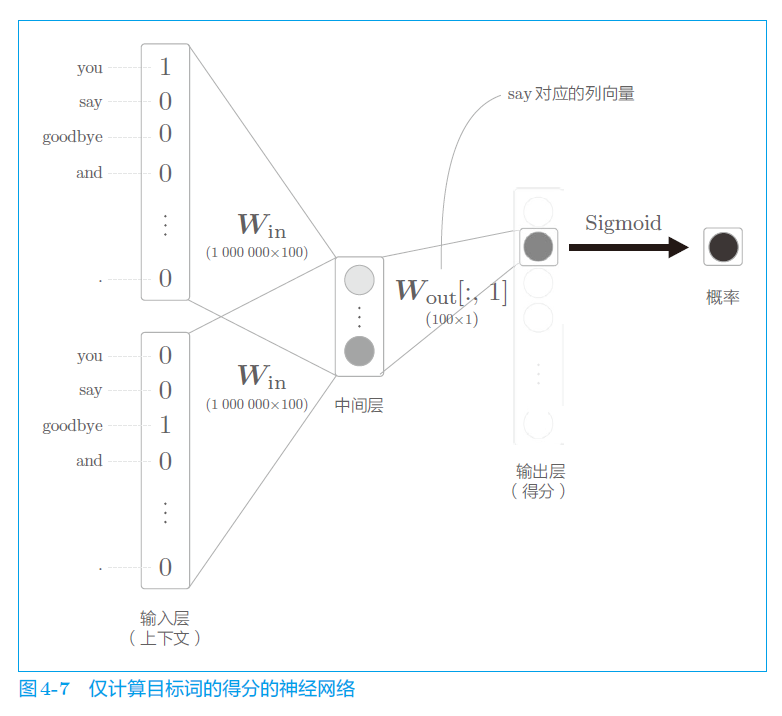
-
即直接取出 W o u t W_{out} Wout 中中心词所在的列(即表示中心词的向量),再与中间层的神经元计算内积。
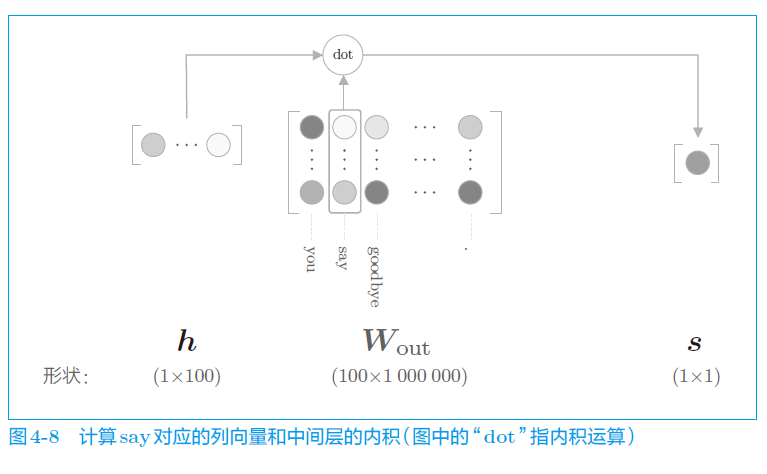
-
最后通过 sigmoid 激活函数,再经过交叉熵损失函数计算 loss。
负采样思想
前面经过把多分类转化成二分类问题,只提供了中心词,也就是说,只能保证对中心词的预测得分高,但不能保证对其他词得分低。
需提供负例,使得模型对正确的词得分高,对错误的词得分低。从而拉开差距。
不能用所有负例进行计算,否则词汇量巨大,计算困难。需要提供少许(5个或10个)负例来提供训练。将正样本的损失与负样本的损失相加,得到最终的 loss.
负采样方法
对语料库的单词进行词频计算,将其表示为概率分布。然后利用概率分布进行负采样,保证常用的词被抽到的概率大,稀有的词难被抽到。
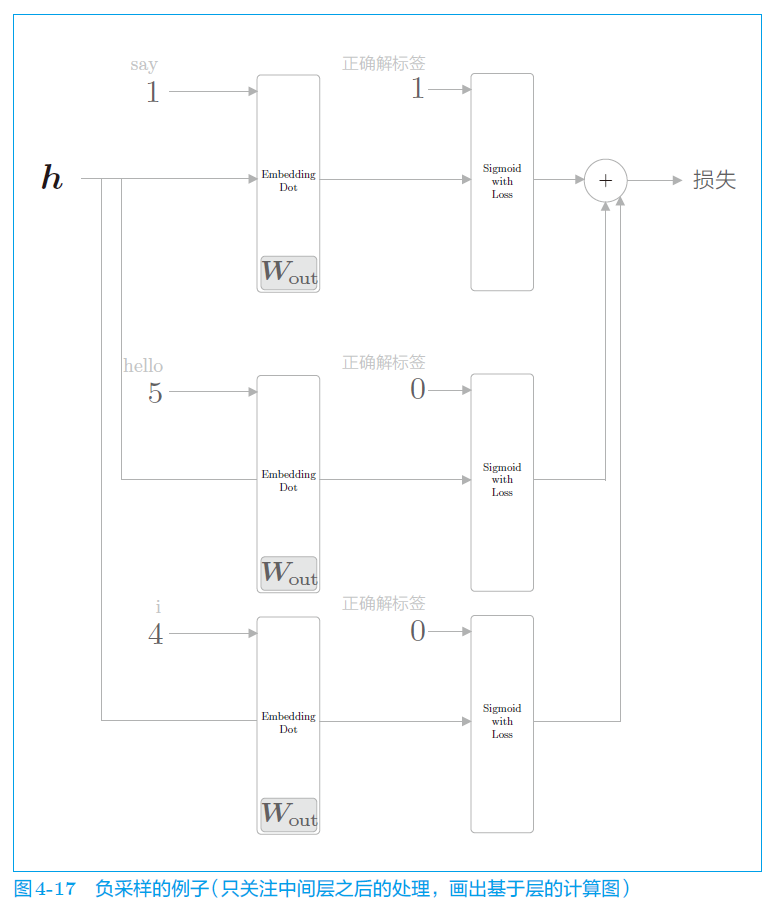
3、word2vec的应用
迁移学习:利用word2vec学到的单词分布式表示,可以用来文本分类、文本聚类、词性标注、情感分析等其他任务中。
4、word2vec评价指标
a. 相似度
cat 和 animal 的相似度、cat 跟 car 的相似度
b. 类推问题
king : queen = man : ?
5、小结

五、RNN
1、语言模型
语言模型给出了单词序列发生的概率。就是使用概率来评估一个单词序列的可能性。

2、RNN模型
a. 结构图
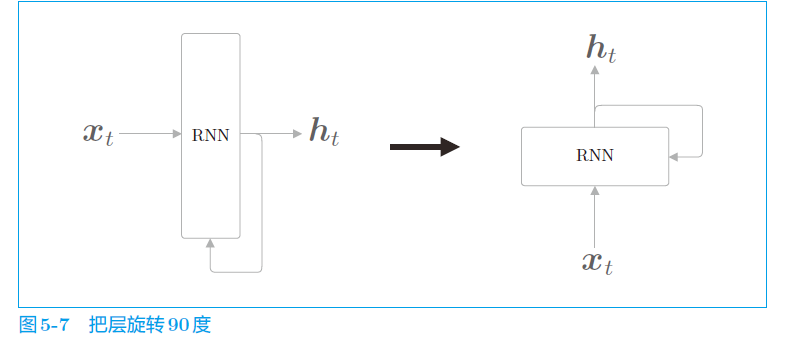
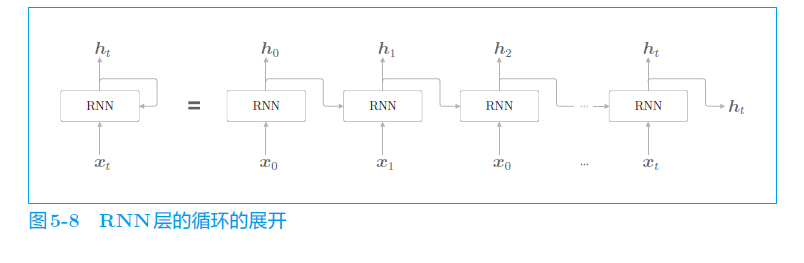
b. 计算公式
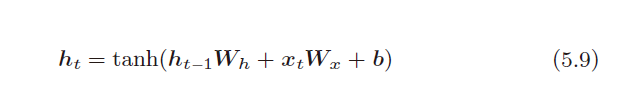

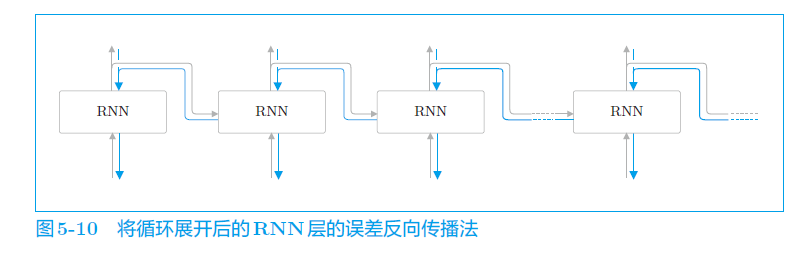
c. 反向传播
基于时间的反向传播,BPTT
后面的RNN层链式求导要求到第一层。(这么大计算量?可以重复利用前面的导数值?)
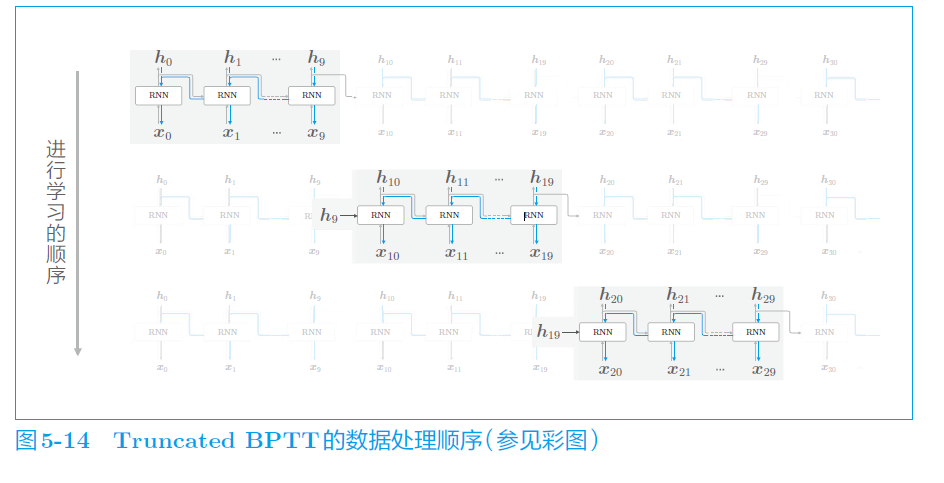
d.截断的BPTT
当处理较长的时序数据时,需要横向展开较长的层网络,对反向传播不利(梯度消失),可以在适当长度上进行截断,在各个子网络上进行反向传播。
正向传播不截断。对切开的每个块,先对第一个快进行正向传播,再反向传播;接着对第二个块……
学习顺序:
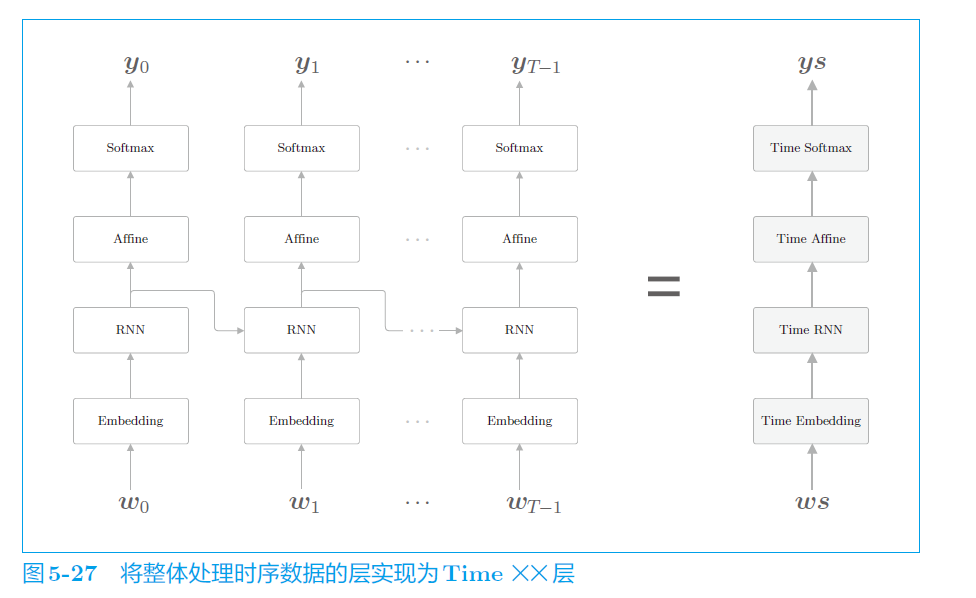
e. 训练示例
每个词按顺序输入网络,先进行embedding,获取分布式表示;再进入RNN层,RNN向上方输出隐藏状态,向下一时刻的RNN输出隐藏状态。本层RNN经过Affine给Softmax

f. 整合成time层
g. 批处理
对位置进行偏移,将时序长度为1000的网络每10个切分一块的情况下,mini-batch示例:
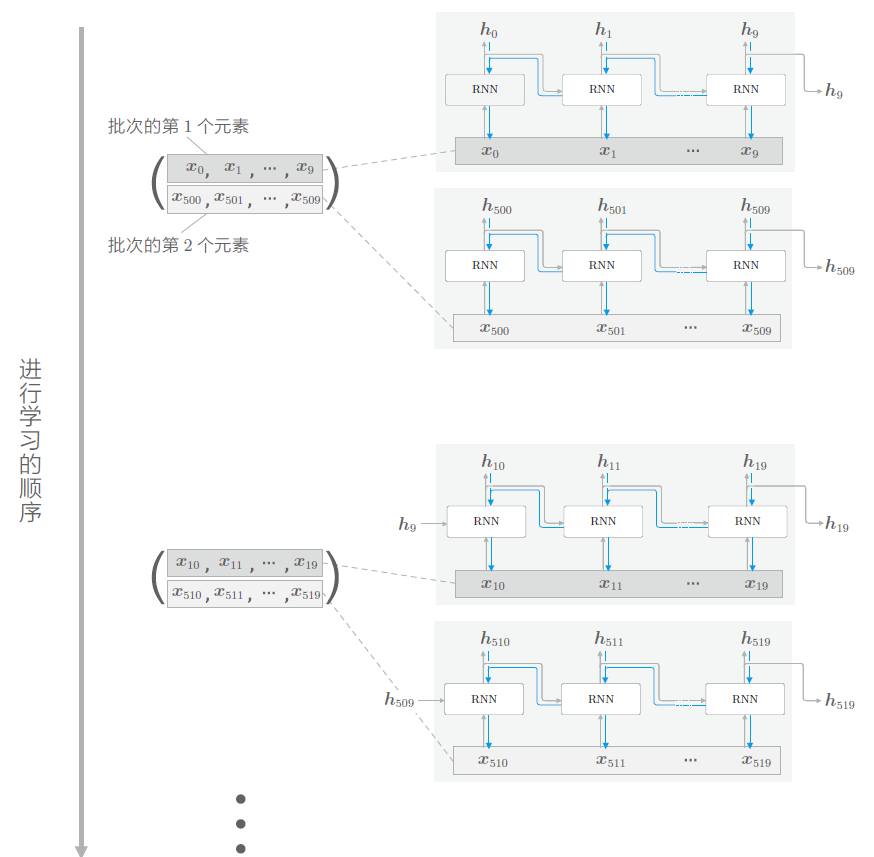
h. 模型评价指标
困惑度/分叉度:
表示标签所对应的预测出来的概率的倒数,概率越大,倒数越小,困惑度/分叉度越小。
3、简单RNN的缺点
- 反向传播的时候标量 W h T W_h^T WhT 被连乘了T次,导致梯度消失或者梯度爆炸,训练无法继续。导致其无法记住长时间序列的信息。
- 如果 W h T W_h^T WhT 是矩阵,则需要判断 W h T W_h^T WhT 的奇异值的最大值,如果大于1,则很可能会出现梯度爆炸;而若其小于1,则会出现梯度消失。
4、小结

六、Gated RNN
上面说了简单 RNN 可能存在梯度消失和梯度爆炸的问题,本章对以上两个问题进行讨论解决。
1、简单RNN问题分析解决
a. 梯度爆炸
解决梯度爆炸既定的方法:梯度裁剪。简单来说,梯度裁剪方法设定了一个阈值 t h r e s h o l d threshold threshold , 算法把神经网络用到的参数的梯度整合成一个 g ^ \hat g g^ (将参数的梯度按一定方式进行组合)。当 g ^ \hat g g^ 的 L2 范数 ∣ ∣ g ^ ∣ ∣ || \hat g || ∣∣g^∣∣ 达到阈值时,就对其进行修正。伪代码如下:
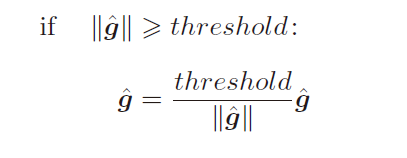
b. 梯度消失
针对梯度消失,可以将 tanh 激活函数替换为 ReLU 函数,因为 ReLU 函数的导函数在 x > 0 的时候为1,可以一定程度地减缓梯度爆炸问题。本章主要介绍对简单 RNN 结构的改变,来缓解梯度消失问题—— LSTM (一种Gated RNN).
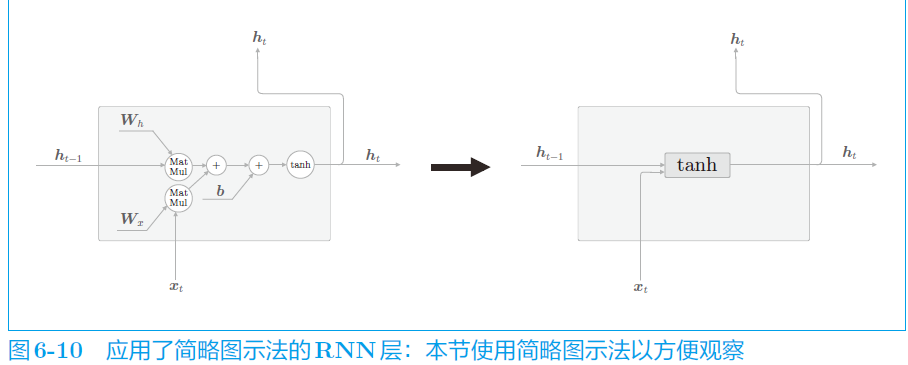
为了方便表达,引入简略图示法,如下图:
2、LSTM
a. 结构
先看 LSTM 的结构与RNN有何不同。
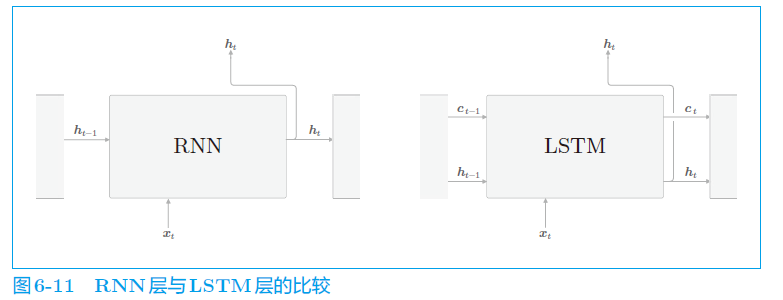
可以看到,LSTM 增加了一个 c t c_t ct ,用来存储t时刻的 LSTM的记忆,其保存了从过去到时刻 t 的所有信息的记忆。
而 c t c_t ct 怎么算呢?
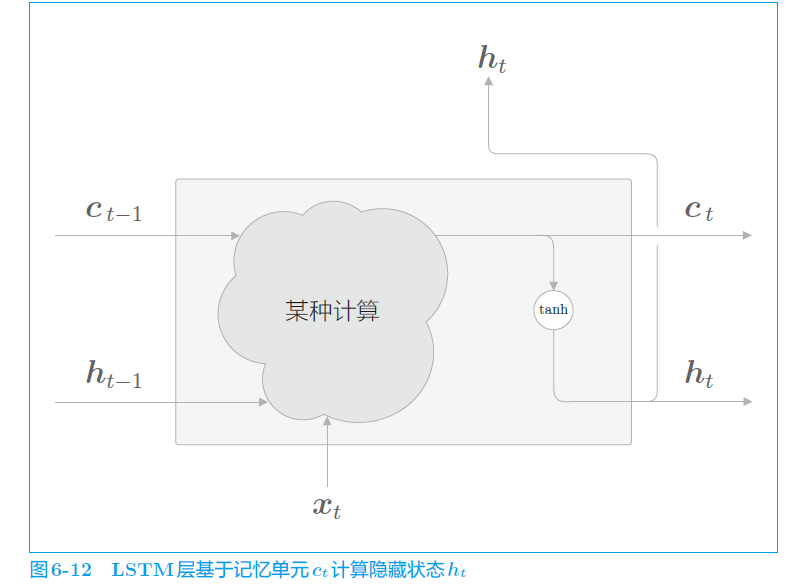
可以看到, c t c_t ct 是根据上一个时刻的 c t − 1 c_{t-1} ct−1 和 h t − 1 h_{t-1} ht−1 和当前输入 x t x_t xt 经过某种计算所得。而且 h t h_{t} ht 是由 c t c_t ct 经过 tanh 所得。
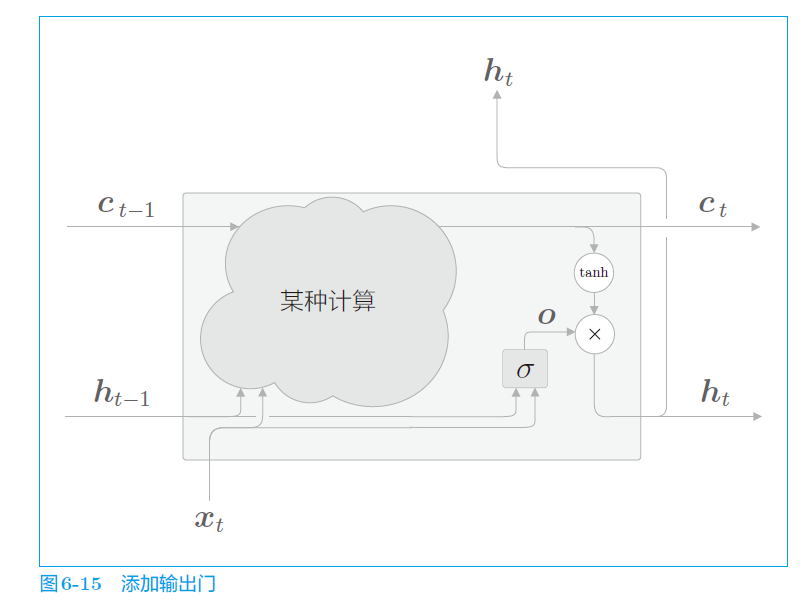
b. 输出门
而如何体现出 LSTM 中 “门” 的概念?
该“门”称为 “输出门” 会求出来流出比例向量,与 h t h_{t} ht 进行哈达玛乘积(对应位置相乘),体现了对 h t − 1 h_{t-1} ht−1 中各元素的“限流”输出。
将此门运用到计算图中:
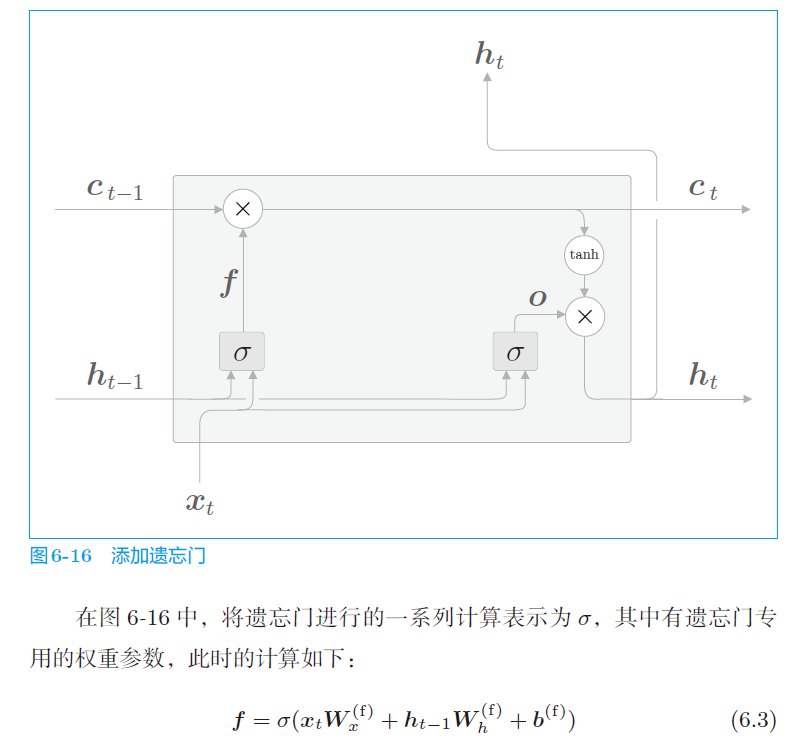
c. 遗忘门
遗忘门,用于遗忘不需要记住的记忆。
d. 新记忆单元
若只有遗忘门,则只会忘记记忆。故而要添加新的记忆单元,向网络里添加记忆。
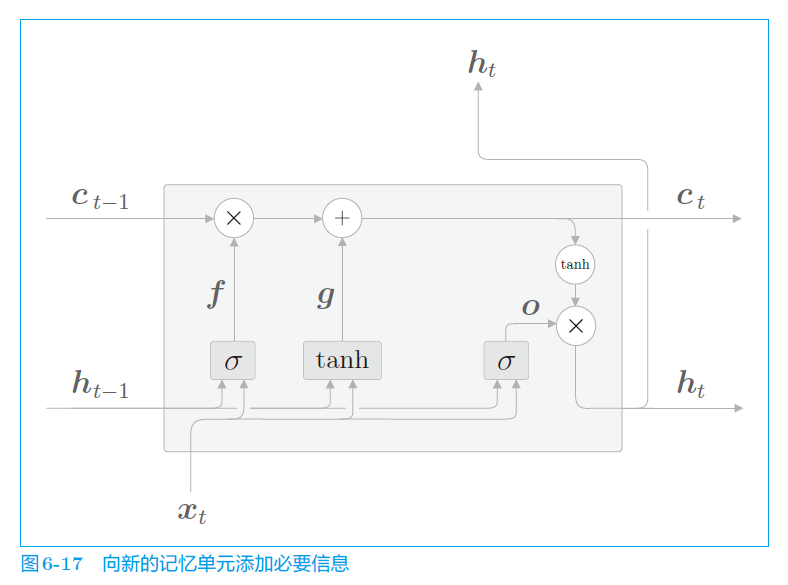

e. 输入门
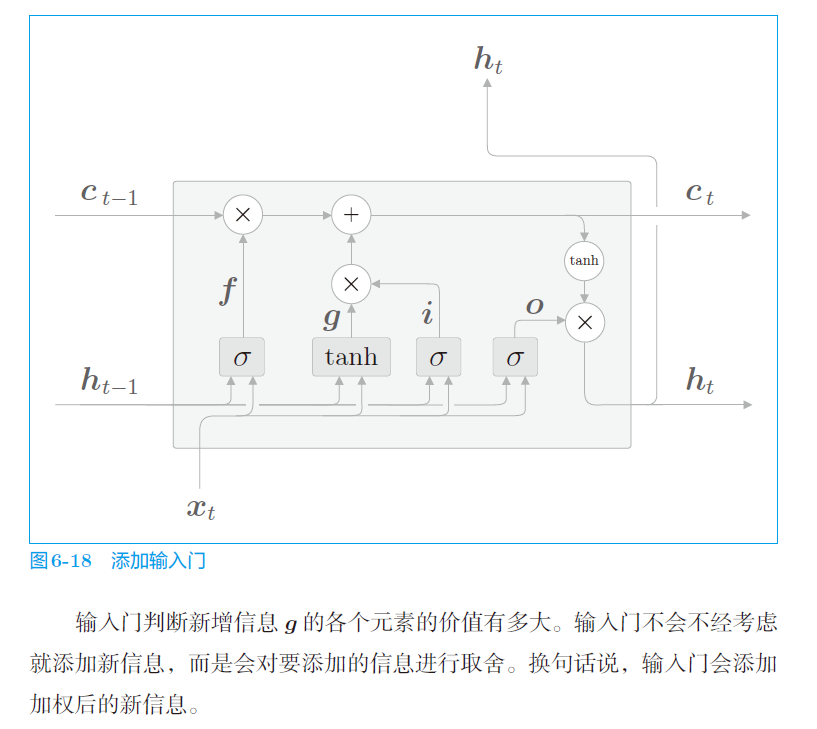
不能随意向网络内添加新的记忆,需要对添加的信息进行取舍(即加权),使得新加的记忆信息是经过输入门加权过的。

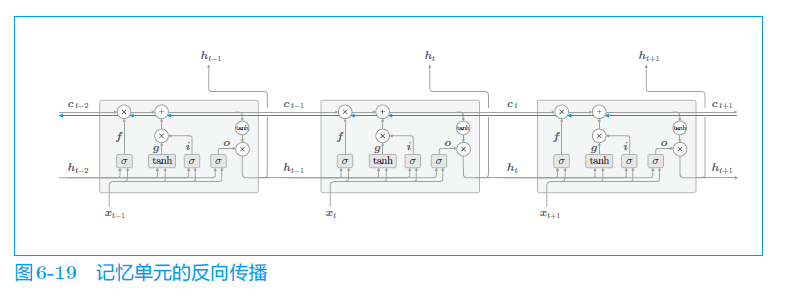
f. LSTM 反向传播
介绍完所有的门,来看看 LSTM 反向传播的结构
g. 为什么不会梯度消失?
观察记忆单元 c 来解析如何解决了梯度消失的问题。首先看到 c 在反向传播过程中会经过 + 和 × 两种计算节点。而经过 + 节点时,梯度是不变的。而这里的 × 节点不是矩阵成绩,而是哈达玛乘积(对应位置元素相乘)。故在传播过程中,反向传播时,都会对不同的值进行成绩运算。而遗忘门对于该忘记的元素,梯度会变小;反之梯度变大。故可以期待,记忆单元的梯度能在不发生梯度消失的情况下得到传播。
(妙啊)
h. 整合计算
跟前面的简单 RNN 不同,LSTM 的权重矩阵 W 整合了四个门的权重。(整合后可以加速运算)
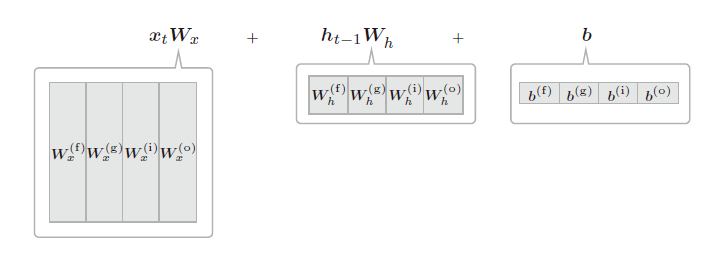
看看形状的问题:

i. Time LSTM
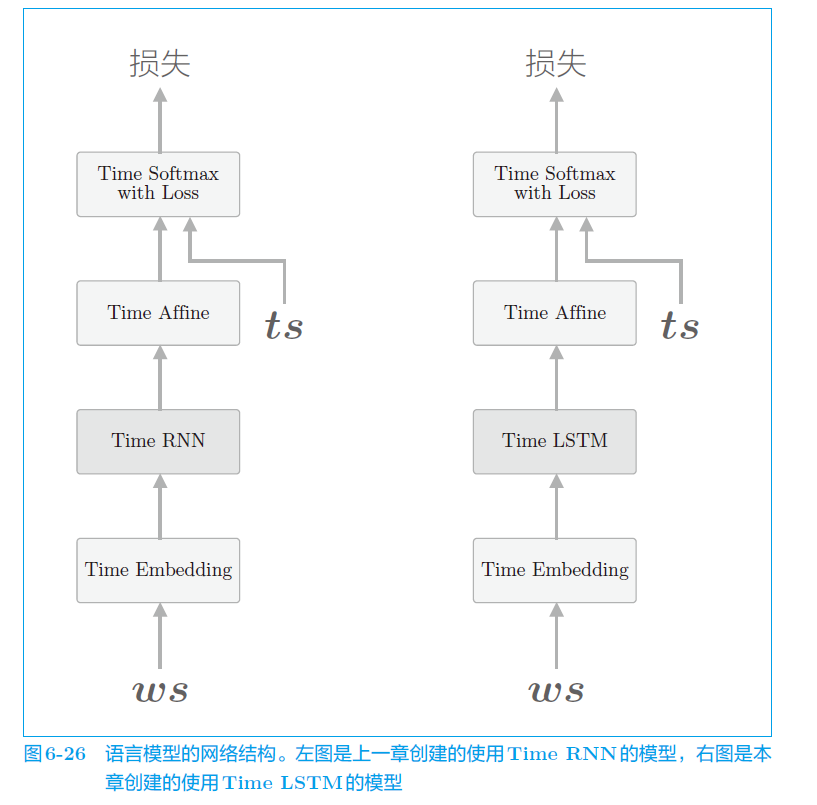
j. LSTM 多层化
一般,叠加多个 LSTM 层,可以使 RNNLM 的精度提高。
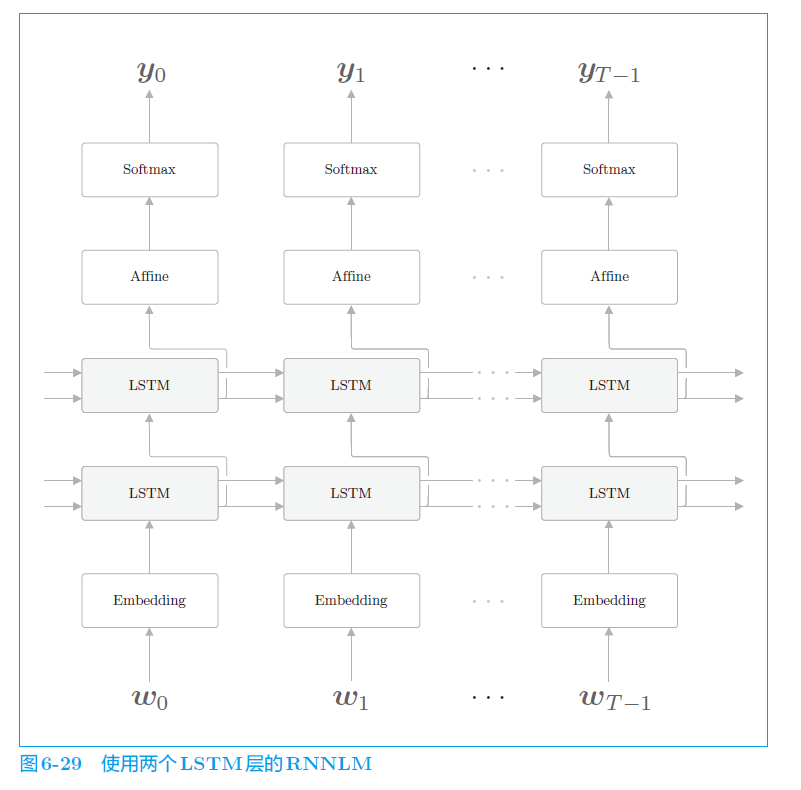
k. 抑制过拟合问题
一般随着网络层数加深,容易造成过拟合现象。可以对叠加的 LSTM 进行 dropout 抑制过拟合。但是如果将 dropout 层加入到 LSTM 的时序方向(横向)上,随着时间的推移,记忆将丢失严重。因此,选择在纵深方向上加入 dropout 。
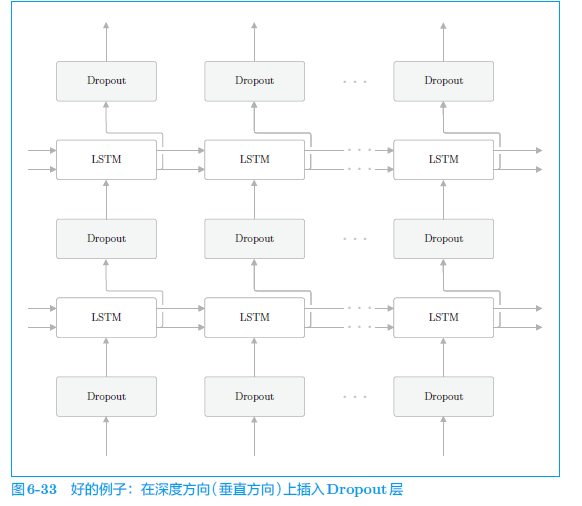
除了 dropout,还可以,进行权重共享。假设词汇量是V,Embedding 层的权重形状就是 V × H V \times H V×H ,Affine 层权重形状就是 H × V H \times V H×V ,故可以直接将 Embedding 层的权重进行转置,应用到 Affine 层上面去。二者进行绑定。即可实现抑制过拟合的效果。为什么? 因为这样可以减少训练参数,抑制了过拟合,也提升了模型的精度。
3、小结

七、基于RNN的文本生成
1、基于RNN/LSTM的文本生成
前面运用 RNNLM 进行各种应用:机器翻译等。RNN也能用于文本生成。
如果直接用简单 RNN 或者 LSTM,在网络输出的最后一层softmax后,利用概率分布进行输出单词(不是取最有可能的值,而是以概率地进行取值),虽然也能进行文本生成,但是可能效果比较差。
2、seq2seq
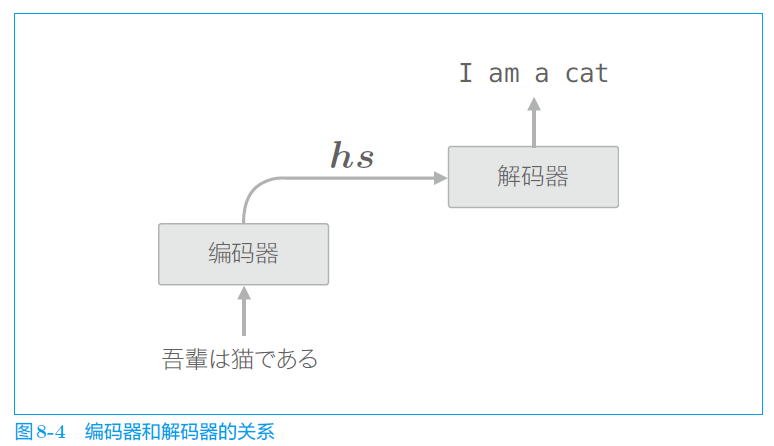
下面就介绍很牛的文本生成的模型——seq2seq,也称为 Encoder——Decoder 模型,即编码器——解码器模型。编码是基于某种规则进行信息转换的过程。解码时还原信息的过程。比如将字符 “A” 可以编码成1000001,然后可以将1000001解码成字符 “A”。 这个模型比较简单,可以快速学习。
长话短说,看下面的网络结构:
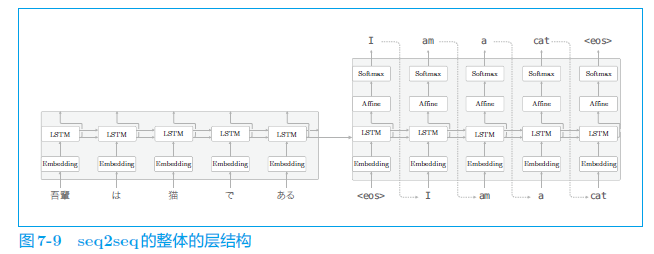
左边就是编码器,就是 LSTM 层,跟前面学过的 LSTM 类似。不过编码器不在乎向上方向的输出,主要是获取时序数据的隐藏状态 h,即最右边的输出 h。
右边就是解码器,是一整个 LSTM,跟前面的 LSTM 基本一致,就是多接收了一个初始的隐藏状态 h(就是左边解码器送过来的 h)。
训练的时候,编码器解码器同时输入数据,编码器输入日语的“我是猫”,解码器输入一个开始符号+英语的“我是猫”。
测试模型的时候,编码器输入日语的“我是猫”,解码器就输入一个开始符。然后就看编码器来输出,如果训练的好的话,它可以输出英语的“我是猫”。简单理解就是,我给你日语,和一个开始符,你就接着我给的开始符往下,给我输出英语。
如果句子中的单词数目不一样怎么办?那就用空白字符填充,具体的细节不讲了,明白这个就行。
解码器生成字符串的时候如果是需要精确的值,就取概率最大的那个结果;如果想要增加一些随机性,就对每个结果基于概率地出来一个数。
到这里模型地结构就结束了,还算简单哈。
3、seq2seq的改进
如果训练seq2seq进行加法计算,由于他是语言模型,不是计算器,所以可能性能不是很好。
对其进行改进的办法有两个:
a. 反转数据
比如数据如果有 5 + 75 反转之后就是 75 + 5
利用反转数据进行训练,可以提升精确度。
b. Peeky (偷窥)
对于解码器,他的输入只有编码器送过来的 h,直接输入到 LSTM 层中。那能不能更加充分地利用上这个 h 呢?
改进前:
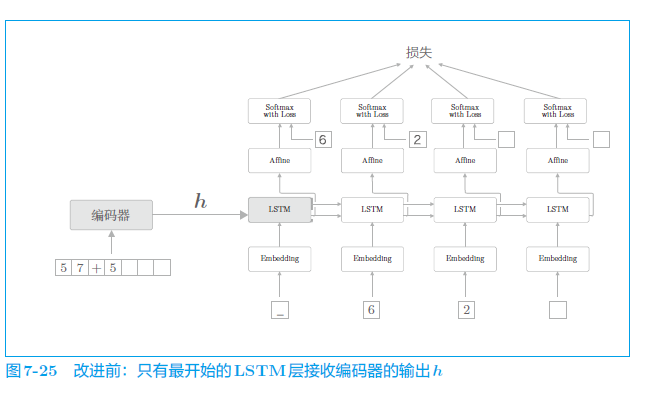
改进后:
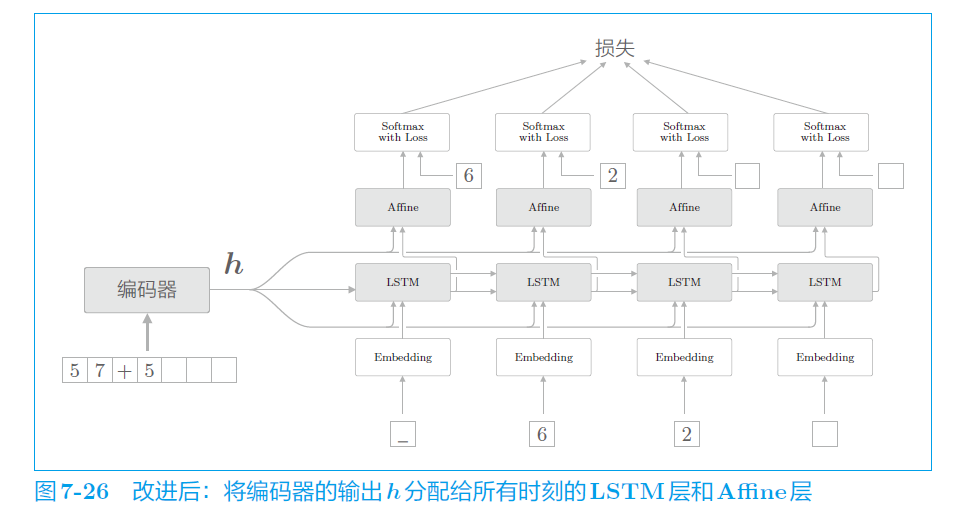
其实就是把 h 不单单作为隐藏状态传入 LSTM,它将与 LSTM 的输入、Affine 层的输入进行向量拼接,然后作为输入。
就是把 h 多层共享,而非私有。或许能做出更加正确的判断。
4、LSTM 的应用
-
机器翻译
-
自动摘要
-
问答系统
-
邮件自动回复
5、小结

八、Attention
即注意力机制。
1、seq2seq的不足
前面介绍了两种改进 seq2seq 的方法。一个是反转数据,一个是 h 共享(peeky)。其实提升都不是很大。
考虑机器翻译的场景,编码器输入中文的“我是猫”的时候,其实 seq2seq 做的事就是接着开始符往下写“i am a cat”,其实在翻译的时候,可以多考虑一下词与词的对应关系,比如“我”对应“I”,“是”对应“am”……这样会极大的提高翻译精度。那么怎么实现呢? 注意力机制就是做了这件事情,让每个时刻的的 LSTM 多多关注对应的那个词语,提高翻译精度。
2、注意力机制
由于 seq2seq 的编码器是将最后时刻的隐藏状态 h 输入到解码器中,所以导致最后那个词“猫”所含的信息占比比较大。为了让传输到解码器中的每个词的信息量均衡一些,就将每个时刻的隐藏状态,拼接成矩阵 hs,一同输入到解码器中。如下图:
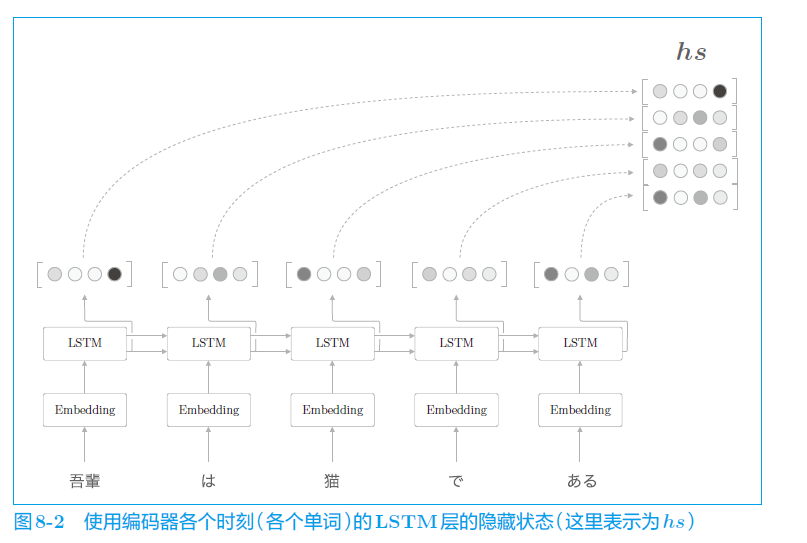
那么,解码器中的 LSTM ,怎么样才能结合 hs 的信息,多多关注对应的词呢?
可以这样操作,将 LSTM 的输出 r ,跟 hs 的各个向量做一次内积,得到的是一个初始的权重向量(hs 中 跟 r 越接近的词语所对应的向量,跟 r 做内积后得到的值越大)。初始的权重向量进行正规化(softmax),使每个数都是正的,得到一个能体现出跟 r 的相似度的,概率和相加为1的权重向量。如下图:从参差不齐 到(.8, .1, .03, .05, .02)
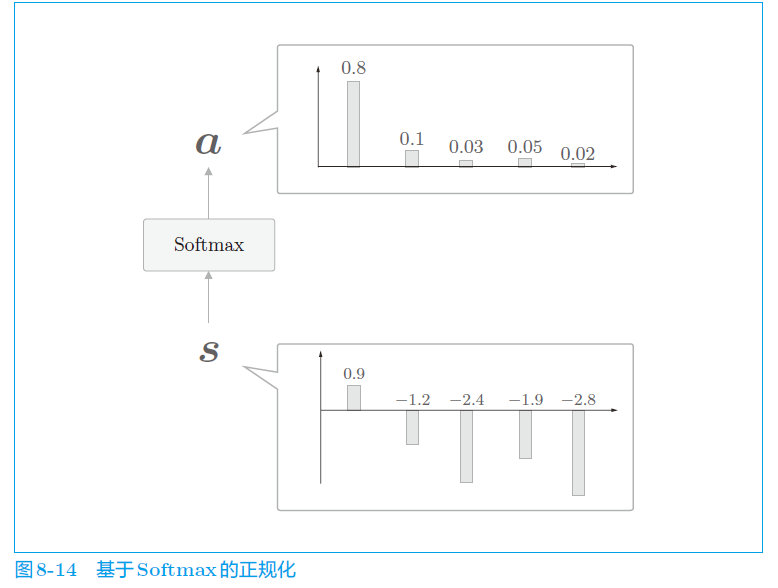
然后,利用得到的权重向量与 hs 矩阵相乘,就实现了将 hs 中与本层该翻译的对应的词的信息,更多地提取出来。
比如说,如果权重向量是(.8, .1, .03, .05, .02),我要翻译的句子是“我是一只猫”,则第一个时刻的 LSTM 将把“我”这个词的信息乘 0.8 的权重提取出来(再加上0.8权重的其他的信息的和)(这里不是很严谨,因为不是双向LSTM,但是先这么理解,不耽误事儿)。这样就更能关注到“我这个词”,就可以更准确地翻译出"I"。
加了attention的seq2seq的解码器:
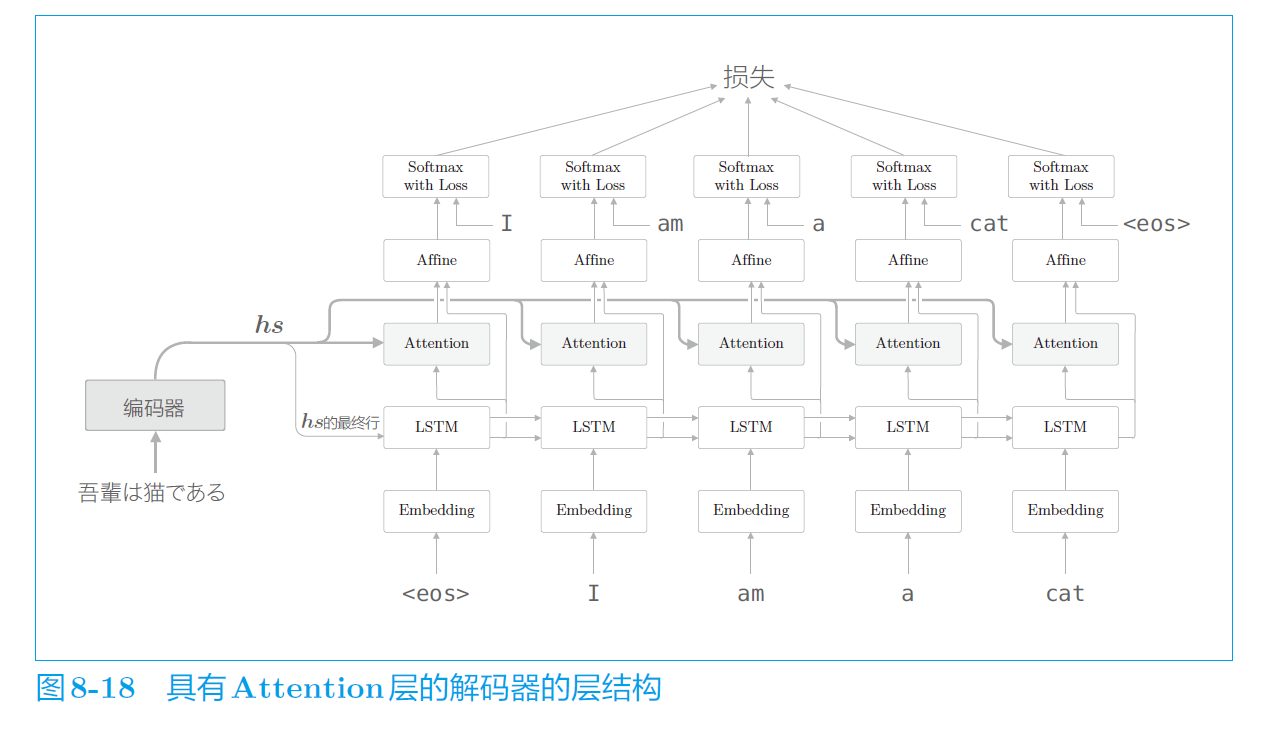
注意,LSTM经过 Attention 层的输出还要与 LSTM 自身的输出进行拼接,输入到 Affine 层。
后面还有双向 LSTM 和 seq2seq的深化,就不写了,感觉不会考(想看的同学去看书)。
3、注意力机制的应用
-
NMT :神经机器翻译
-
Transformer
-
等等