Faster-Lio 是智行者高博团队和清华于 2022 年初公开的工作,论文《Faster-LIO: Lightweight Tightly Coupled Lidar-inertial Odometry using Parallel Sparse Incremental Voxels》已接收于 IEEE RA-Letters,代码已经开源。
相比于港大 MaRS-Lab 的FastLio2方案,Faster-Lio 在保持精度基本不变的情况下,实现了更高的算法效率,这主要归功于使用了增量式体素结构iVox,增和查的效率比ikd-Tree更优,进一步降低了维护local map和查询近邻的耗时。
本来,高博 @半闲居士 已经在自己的知乎文章中对这篇文章的工作进行了非常好的总结(包括 iVox 的设计思路),一贯的言简意赅、直抓要害。
但想着,从本专题的初心出发,正是对 SLAM 中新出现的优秀数据结构做梳理,就权当为高博文章做个关于 iVox 的补充材料吧,可能有不对的地方,欢迎批评指正。
1. 前言:高明的算法通常根植于最朴素的思想
在这一部分,我将尝试用自己的思路重新“发明”一下 iVox,以便读者理解到设计出 iVox 是一个水到渠成的事情,以及 iVox 中的各个trick是为了解决什么问题。如下:
- 在很多SLAM方案中,都希望维护一个当前pose附近的local map,用于某种形式的scan-to-local map配准;为了控制local map不至于点数过多(浪费资源且无必要),我们还希望local map中的点保持稀疏性,不必过于密集。
- 以上两点需求,都体现了对local map点云在空间分布上的要求。
- 既然如此,为何不干脆用一个空间类型的数据结构(而非树型结构),来维护 local map?
- 提到空间,最容易想到的,正是栅格地图,比如八叉树栅格地图算是一种。
- 但是,我们并不需要像八叉树一样,把附近的空间完全体素化,毕竟,很多地方都只是空气,在这些地方维护一个始终为空的体素,是没有意义、且浪费资源的。
- 于是我们自然想到,能否维护一个稀疏的体素地图,只在有需要的地方(点打到的地方)去创建和维护体素?这当然是可以的。
- 但这样的话,每个体素的索引就没法按照空间排列关系在计算机内存里线性地给定了,因为你也不知道哪个体素先被创建、位于容器的哪个位置。
- 于是想到,可以用哈希表(Hash Table)这种离散数据结构,来统一构建和管理所有体素;因为每个体素的空间位置是唯一的,因此将空间坐标作为 key 输入到某种哈希函数(比如空间哈希),生成一个唯一的索引,并在这个索引地址上存放对应体素的指针作为 value 即可。
- 在实现上, C++ 标准模板库的 unordered_map 本身就是哈希表的封装,我们只需要将其默认哈希函数替换为自定义的空间哈希函数,就可以直接用 unordered_map 来维护 <key, value> 数据了。
- 搞定。
- 在每个体素内,所有的点是线性排列的,在这里找近邻的话需要遍历所有点,这在点数不是很多时没有问题。
- 但是,当体素的体积较大、内部的点特别多时,暴力遍历的方法显得笨拙且耗时,于是想到用伪希尔伯特空间填充曲线(Perseudo Hillbert Curve, PHC)来建立体素内所有细分空间单元的索引,以便快速地查找任意近邻。
- 彻底搞定。
下面,我们只需要在上述思路的基础上,补充一些哈希表(Hash Table)和伪希尔伯特空间填充曲线(PHC)的知识,再结合源码看一下实现,就能够掌握 iVox 啦!
2. 哈希表与空间哈希函数
什么是哈希表?
哈希表(Hash Table)是一个抽象的“表”结构,本质上是哈希函数(Hash Function)+**底层数据结构(通常是数组)**的组合;哈希表的原理如下图所示,哈希函数负责根据输入的 key 计算出一个 index(or hash index),数组负责在 index 的位置上保存 value 信息,<key, value>共同构成了哈希表中的一条数据。
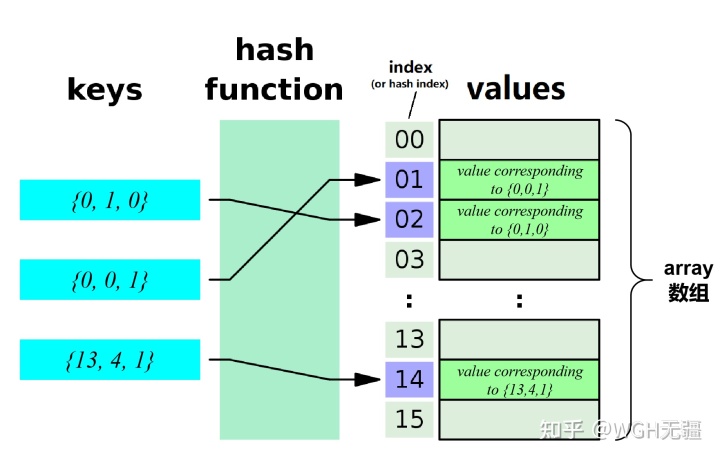
哈希表原理
新增数据时,给定<key, value>,根据 key 计算索引并在索引位置保存对应 value;查找数据时,给定 key,通过 key 计算索引并返回索引位置的 value。无论是新增还是查找,由于索引值是直接通过哈希函数对 key 计算出来的,因此复杂度始终是O(1),与存储数据的规模无关,所以哈希表是一种比较高效的数据结构,且规模越大优势越明显。C++ 标准库中的std::unordered_map是一种典型的<key, value>类型容器,其内部正是封装了哈希表(下文中我们会发现 iVox 中的哈希表实现就是用的std::unordered_map)。
由哈希表的结构可以看出,哈希函数(Hash Function) 是真正的核心角色,为什么哈希函数能够对任意的 key 直接计算出一个 index 呢?原理是什么?我们不妨举一个简单哈希函数的例子:定义整数域上的哈希函数 h a s h ( x ) = ( 1234 ∗ x + 4567 ) % ( 1 e 8 ) hash(x)=(1234*x+4567)\%(1e8) hash(x)=(1234∗x+4567)%(1e8) ,也即对输入先做一个线性运算再对 1e8 取余,该函数实质上把输入的任意整数(作为key)映射到了地址空间[0, 99,999,999]上;只需再配合一个容量不少于1e8的数组,就实现了一个哈希表。与这个简单哈希函数类似,大多数哈希函数的最后一步都是对一个很大的数(类似1e8)取余,以限制输出在有限的地址空间上。
我们再来看一下 iVox 中使用的空间哈希函数,其定义如下:以体素的空间坐标 v (是整数坐标,与物理坐标的关系是乘以体素的边长)作为 key,对 v v v 的三个维度各乘以一个很大的整数再做异或位运算,得到的结果再对哈希表的容量 N 取余,得到体素的 i n d e x —— i d v index —— id_v index——idv 。实际应用中,我们是先有点再去找体素,因此需要先把点的坐标 p p p 除以体素边长再取整算出 v 。这个空间哈希函数是由 2003 年的一篇论文“Optimized Spatial Hashing for Collision Detection of Deformable Objects”提出的,iVox 直接借鉴了这个设计。

iVox 中的空间哈希函数定义
任何哈希表都必须要考虑哈希冲突(哈希碰撞)问题,iVox 也不例外。以下是我自己的理解:在 iVox 中,算法只维护有限数量的体素,因此哈希表的负载因子(Load factor, 表示数据的规模占数组容量的比例)始终很小,再加上空间哈希函数在设计上也具备抗碰撞能力,因此 iVox 的碰撞概率应该是可以忽略不计的。再退一步讲,即使碰撞了,结果无非是得到一个距离很远的体素或空体素,这样的体素会因为查询不到近邻而被忽略掉,所以还是没关系的。
至此,以上提到的内容用于理解 iVox 已经足够了。
哈希表,或者哈希算法,本身是一个有无数种实现、在不同领域都有应用的技术,因此下方整理了一些资料,供有兴趣的读者参阅。
哈希表的基础概念、哈希碰撞,负载因子、常见哈希函数的定义:
https://en.wikipedia.org/wiki/Hash_table(维基百科)
哈希表的原理 - funtrin - 博客园
哈希表原理_chirpy-dev的博客-CSDN博客_哈希表的原理
哈希函数(or 哈希算法)在计算机与网络安全领域的应用,数据加密,SHA-1/SHA-256/SHA-512加密,数据校验等:
廖雪峰的官方网站:哈希算法
Hash算法的讲解 - 爷的眼睛闪亮 - 博客园
超硬核,一文读懂 对称加密、非对称加密、公钥、私钥、签名、证书
3. 伪希尔伯特曲线(PHC)
※ 3.1 我们先从希尔伯特曲线(HC)讲起。
希尔伯特曲线 —— 全称希尔伯特空间填充曲线(Hilbert space-filling curve, or Hilbert curve),是空间填充曲线的一种。如下图所示,其基本原理是将空间分成一个个小单元,然后把这些单元的中心点用一条分段曲线(折线)连接起来,因为曲线是一维的(分段曲线拉直了不就是一维么),但被它连接起来的各个单元是位于高维空间的,这样,这个曲线就具有了将高维空间的元素映射到一维空间的能力,我们可以据此在一维空间中来索引高维空间的存在 —— 这正是 iVox 看中的能力。
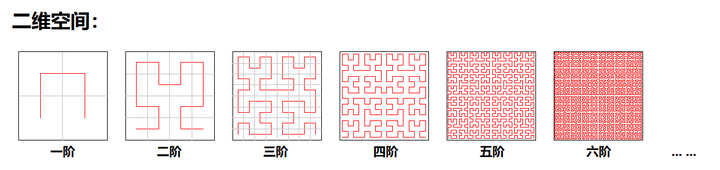
希尔伯特曲线是分“阶”的,以二维空间为例(还是看上图),一阶希尔伯特曲线把空间划分为 2 1 ∗ 2 1 = 4 2^1*2^1=4 21∗21=4 个小单元,并按特定的走位规则把4个单元的中心点连接起来;二阶希尔伯特曲线把空间划分为 2 2 ∗ 2 2 = 16 2^2*2^2=16 22∗22=16 个小单元,并按特定的走位规则把16个单元的中心点连接起来;三阶希尔伯特曲线把空间划分为 2 3 ∗ 2 3 = 64 2^3*2^3=64 23∗23=64 个单元,并按特定的走位规则把64个单元的中心点连接起来;… … N阶希尔伯特曲线把空间划分为 2 N ∗ 2 N 2^N*2^N 2N∗2N个单元,并按特定的走位规则把所有单元的中心点连接起来。如果是三维空间的话(看下图),N阶希尔伯特曲线把空间划分为 2 N ∗ 2 N ∗ 2 N 2^N*2^N*2^N 2N∗2N∗2N 个单元,并按特定的走位规则把所有单元的中心点连接起来。

然后,下面的这三点性质 —— 至关重要,请一定要理解:
- 「阶数」越高,希尔伯特曲线越逼近于把整个空间完全填满;事实上数学上可以证明,在极限情况下,希尔伯特曲线是能够把空间完全填满的 —— 换句话说,给定空间内的任意一个点,都一定存在某阶的希尔伯特曲线恰好从这个点穿过!(极限思想!极限思想!极限思想!)
- 「走位规则」在希尔伯特曲线中是被明确和充分定义的,这个规则决定了高维索引与一维索引之间的映射函数长什么样子;但是鉴于篇幅本文不再讨论,有兴趣的可以参见下方我整理的链接。
- 希尔伯特曲线具有「保持近邻关系」的能力,也就说如果两个元素在高维空间中是邻近的,那么它们在希尔伯特曲线上也是基本邻近的。
※ 3.2 下面给出***伪希尔伯特曲线(PHC)***的概念。
首先,我们要问一个问题:理想的希尔伯特曲线应该是怎样的?上文说过,希尔伯特曲线是空间填充曲线的一种,既然是空间填充,我们希望能够完全填充,也即能够取到任意一个点,无论这个点的坐标值是有理数还是无理数。这种完全填充 —— 只有极限状态下的希尔伯特曲线能够做到。
于是可以这样理解:
上边提到的特定阶的希尔伯特曲线是「伪希尔伯特曲线」,因为它并不能真正地取遍所有的点。
而「真正的希尔伯特曲线」 —— 应当是一系列伪希尔伯特曲线的极限!(引自知乎博主Neal)
这里可能有点矛盾,因为在3.1节我已经介绍了「希尔伯特曲线」,但这里又自相矛盾地说那「不是真正的希尔伯特曲线」,而是「伪希尔伯特曲线」;之所以这样做,是为了不过早地引入「伪」的概念,防止读者迷惑。
如果您已经读到了这里,我们不妨重申一下:
「伪希尔伯特曲线」指的是特定阶的希尔伯特曲线,它不能真正地填充整个空间,但阶数较高时可以做到近似填充。
「真正的希尔伯特曲线」是一系列伪希尔伯特曲线的极限,可以真正地填充整个空间。(引自知乎博主Neal)
显然,「真正的希尔伯特曲线」是一个理论意义大过工程意义的存在,因为在工程上实现真正的希尔伯特曲线代价太大了;而「伪希尔伯特曲线」具有真正的工程意义,它在不付出过多代价的情况下实现了空间的近似表达,这种近似是工程上可以接受的。
※ 3.3 下面我们再来看一下 Faster-Lio 论文中对伪希尔伯特曲线(PHC)的描述。
论文首先引述了两篇论文来证明伪希尔伯特曲线可以用于 kNN 搜索,这两篇论文分别是*“Neighbor-finding based on space-filling curves,” Information systems*, 2005. 和*“All-nearest-neighbors finding based on the hilbert curve,” Expert Systems with Applications*, 2011,出自同一作者,来自中国台湾国立中山大学。
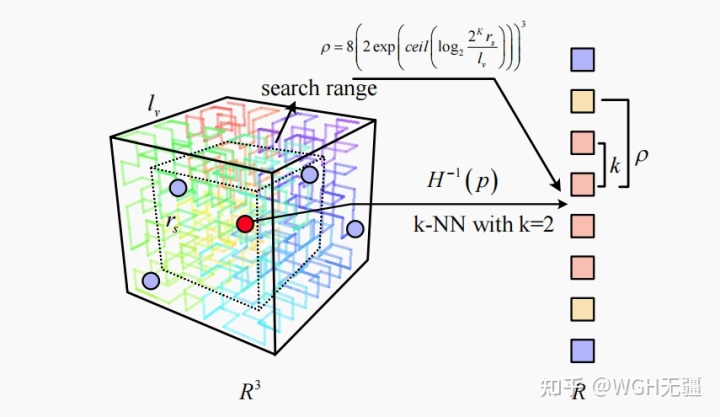
实现中,iVox 把每个体素划分为 ( 2 K ) 3 (2^K)^3 (2K)3 个空间单元, K 的取值和体素的大小相关,论文中取 K = 6 K=6 K=6 ,对应6阶 PHC 曲线。每个空间单元维护的是落在这个空间单元的所有点的质心,每次新增点时更新质心坐标。
接着,论文直接用函数 H ( t ) = x ∈ R 3 H(t)=x\in R^3 H(t)=x∈R3 来表示定义在 PHC 上的一维索引 t t t 到三维空间索引 x 的映射关系,并用 H − 1 ( x ) = t ∈ R H^{-1}(x)=t\in R H−1(x)=t∈R 来表示相反的映射,但并没有给出两者的具体含义。这个 H ( t ) H(t) H(t) 其实就是上文所说的「走位规则」的数学化描述。鉴于在没有用到的情况下,没必要为了研究而研究,眼下我们只需要理解 H ( t ) H(t) H(t) 的含义即可,具体用到时再查阅源码+参考文献+维基百科等材料也不迟。

最后,论文给出了在 PHC 空间上做近邻搜索时的搜索半径的计算方法,其含义是,已知 ranged-kNN 搜索的范围 r s r_s rs ,如何计算出在 PHC 上需要前后各搜索几个( ρ \rho ρ )相邻空间单元。最终的搜索半径是由 ρ \rho ρ 和 k k k 的较小者决定的。

本小节参考资料:
https://en.wikipedia.org/wiki/Hilbert_curve(维基百科)
希尔伯特曲线真的遍历了区间中的所有点了吗?
(伪)三维希尔伯特曲线_哔哩哔哩_bilibili
希尔伯特曲线 java_Hilbert曲线简单介绍及生成算法
4. 源码解析
本部分对faster-lio中与iVox相关的代码进行解析,我们采用剥洋葱的方式、由外及里层层解读源码。(以下所有贴出来的源码都只保留了与iVox相关的部分,以便抓住重点)
4.1 顶层类LaserMapping
稍微看过 faster-lio 源码 的都知道,其中负责SLAM的顶层类叫做 LaserMapping,该类中有一个成员变量 ivox_,正是我们关心的iVox的实体。视编译选项的不同,**ivox_**可以指向不同的IVoxType版本,如果cmake时打开了 IVOX_NODE_TYPE_PHC选项,就会指向PHC版本,否则默认指向线性版本。
// wgh注释:顶层类LaserMapping的类定义。(laser_mapping.h)
class LaserMapping {
// 略.... //
#ifdef IVOX_NODE_TYPE_PHC
using IVoxType = IVox<3, IVoxNodeType::PHC, PointType>;
#else
using IVoxType = IVox<3, IVoxNodeType::DEFAULT, PointType>;
#endif
// 略.... //
private:
/// modules
IVoxType::Options ivox_options_;
std::shared_ptr<IVoxType> ivox_ = nullptr; // localmap in ivox
// 略.... //
};
接下来我们需要知道 ** LaserMapping是怎样使用ivox_ ** 的。以下代码罗列了LaserMapping的所有成员函数中与ivox_相关的调用,其中比较重要的是AddPoints()接口和GetClosestPoint()接口,分别负责增量式新增点和最近邻查询。
// wgh注释:罗列顶层类LaserMapping对ivox_的所有调用。(laser_mapping.cc)
// wgh注释:在InitROS()或InitWithoutROS()函数中实例化ivox_。
ivox_ = std::make_shared<IVoxType>(ivox_options_);
// wgh注释:在SLAM的过程中,调用了ivox_的以下接口函数。
ivox_->AddPoints(scan_undistort_->points);
ivox_->NumValidGrids();
ivox_->AddPoints(points_to_add);
ivox_->AddPoints(point_no_need_downsample);
ivox_->GetClosestPoint(point_world, points_near, options::NUM_MATCH_POINTS);
4.2 实现类**IVox**
接下来我们看一下 iVox 的实现类 class IVox 是如何定义的、包含哪些底层结构、以及AddPoints()和GetClosestPoint()这两个接口如何实现。
由下方头文件定义可知,class IVox的核心在于底层的两个数据成员grids_map_ 和 grids_cache_:
- 前者是一个表现为
std::unordered_map的哈希表,以Eigen::Matrix<int, 3,1>类型的三维向量作为key(表示体素的三维索引),以指向std::pair<KeyType, NodeType>的指针(表现为std::list迭代器)作为value,以重载了()运算符的结构体hash_vec作为哈希函数,hash_vec结构体下文会单独讲; - 后者是一个链表(std::list),是保存所有体素实体的地方,
grids_map_中保存的value只是一个指向这里的指针,这里才是真正的数据。
从角色上来看,**grids_map_是一个索引映射地图,grids_cache_**则是体素容器。
// wgh注释:iVox类模板定义,注意模板参数有默认值。(ivox3d.h)
template <int dim = 3, IVoxNodeType node_type = IVoxNodeType::DEFAULT, typename PointType = pcl::PointXYZ>
class IVox {
public:
using KeyType = Eigen::Matrix<int, dim, 1>;
using PtType = Eigen::Matrix<float, dim, 1>;
using NodeType = typename IVoxNodeTypeTraits<node_type, PointType, dim>::NodeType;
using PointVector = std::vector<PointType, Eigen::aligned_allocator<PointType>>;
using DistPoint = typename NodeType::DistPoint;
// 略.... //
// wgh注释:增量式新增点接口。
void AddPoints(const PointVector& points_to_add);
// wgh注释:最近邻查询接口,支持 NN 和 ranged-kNN。
bool GetClosestPoint(const PointType& pt, PointType& closest_pt);
bool GetClosestPoint(const PointType& pt, PointVector& closest_pt, int max_num = 5, double max_range = 5.0);
// 略.... //
private:
// 略.... //
Options options_;
// wgh注释:哈希索引表(保存key到索引的映射关系)。
std::unordered_map<KeyType, typename std::list<std::pair<KeyType, NodeType>>::iterator, hash_vec<dim>>
grids_map_; // voxel hash map
// wgh注释:用链表存储所有的体素(真正保存体素的地方)。
std::list<std::pair<KeyType, NodeType>> grids_cache_; // voxel cache
std::vector<KeyType> nearby_grids_; // nearbys
};
再看一下**AddPoints()**函数的实现:对于每一个新增的点,首先用Pos2Grid()计算其所属体素的三维索引作为 key,然后查找此 key 是否已经存在,若存在,则向对应体素里新增点;若不存在,则先创建新体素再插入点,在新建体素时首先在 grids_cache_ 中新增一个体素,并把这个体素的 key 和迭代器指针注册到 grids_map_ 中,然后检查维护的体素数量是否超过最大值,若超过,则删除最旧的一个。
// wgh注释:核心接口函数AddPoints()的实现。(ivox3d.h)
template <int dim, IVoxNodeType node_type, typename PointType>
void IVox<dim, node_type, PointType>::AddPoints(const PointVector& points_to_add) {
std::for_each(std::execution::unseq, points_to_add.begin(), points_to_add.end(), [this](const auto& pt) {
// wgh注释:计算点所属体素的三维索引作为key。
auto key = Pos2Grid(ToEigen<float, dim>(pt));
auto iter = grids_map_.find(key);
// wgh注释:如果体素不存在,则先创建体素再插入点。
if (iter == grids_map_.end()) {
PointType center;
center.getVector3fMap() = key.template cast<float>() * options_.resolution_;
grids_cache_.push_front({
key, NodeType(center, options_.resolution_)});
grids_map_.insert({
key, grids_cache_.begin()});
grids_cache_.front().second.InsertPoint(pt);
// wgh注释:只维护有限个体素,删除最旧的一个。
if (grids_map_.size() >= options_.capacity_) {
grids_map_.erase(grids_cache_.back().first);
grids_cache_.pop_back();
}
// wgh注释:如果体素已存在,将点插入体素。
} else {
iter->second->second.InsertPoint(pt);
grids_cache_.splice(grids_cache_.begin(), grids_cache_, iter->second);
grids_map_[key] = grids_cache_.begin();
}
});
}
**GetClosestPoint()**函数的实现总共有3个版本,我们只看下边这个 ranged-kNN 的版本就好:逻辑很简单,先找点所属体素的key,再用这个key去找所有的邻居体素的key,所有这些邻居体素都是 kNN 搜索的对象,因此逐个调用kNNPointByCondition()函数,所有体素内的近邻都放在一起再做排序,取距离最近的 k 个。
// wgh注释:核心接口函数GetClosestPoint()的实现,负责ranged-kNN查询。(ivox3d.h)
template <int dim, IVoxNodeType node_type, typename PointType>
bool IVox<dim, node_type, PointType>::GetClosestPoint(const PointType& pt, PointVector& closest_pt, int max_num,
double max_range) {
std::vector<DistPoint> candidates;
candidates.reserve(max_num * nearby_grids_.size());
// wgh注释:计算所属体素的key。
auto key = Pos2Grid(ToEigen<float, dim>(pt));
// wgh注释:找到所有的邻居体素,并获得每个体素内的近邻点。
for (const KeyType& delta : nearby_grids_) {
auto dkey = key + delta;
auto iter = grids_map_.find(dkey);
if (iter != grids_map_.end()) {
auto tmp = iter->second->second.KNNPointByCondition(candidates, pt, max_num, max_range);
}
}
if (candidates.empty()) {
return false;
}
// wgh注释:对所有候选近邻排序,得到最终的k个。
if (candidates.size() <= max_num) {
} else {
std::nth_element(candidates.begin(), candidates.begin() + max_num - 1, candidates.end());
candidates.resize(max_num);
}
std::nth_element(candidates.begin(), candidates.begin(), candidates.end());
closest_pt.clear();
for (auto& it : candidates) {
closest_pt.emplace_back(it.Get());
}
return closest_pt.empty() == false;
}
4.3 空间哈希函数hash_vec
在使用std::unordered_map作为哈希表实现时,需要以仿函数形式或者函数对象形式向unordered_map提供哈希函数的实现,iVox选择了前者,提供了重载了()运算符的结构体hash_vec作为仿函数。()的函数体里就是哈希函数的实现,代码和论文公式一致,没什么好说的。
// WGH注释:空间哈希函数的代码实现(eigen_types.h)。
/// hash of vector
template <int N>
struct hash_vec {
inline size_t operator()(const Eigen::Matrix<int, N, 1>& v) const;
};
/// implementation
/// vec 3 hash
template <>
inline size_t hash_vec<3>::operator()(const Eigen::Matrix<int, 3, 1>& v) const {
return size_t(((v[0]) * 73856093) ^ ((v[1]) * 471943) ^ ((v[2]) * 83492791)) % 10000000;
}
5. 论文VS代码:差异总结
被动删除策略的差异:源码实现中有一点和论文有出入,论文中提到了一种被动删除过时体素的策略,过时的判断标准是体素近期被访问的次数;但源码中,是按照体素创建的先后顺序来判断过时的,当需要删除体素时,直接把 grids_cache_ 尾部的体素(创建时间最早)删掉。
6. 个人评价
iVox 的思想绝对是简单但实用的典范,解决什么问题以及用什么方法解决都很清晰,最大的价值在于用哈希表来管理稀疏体素。
至于伪希尔伯特曲线算法,可能论文意义大于工程意义。原因有如下两点:1.实际中不太会在一个体素内保存很多点,如果点在插入之前已经做了体素降采样控制,那么点数就不至于太多,线性查找就够用了;2.就算有需要,我们再嵌套一个子空间划分(或者八叉树)似乎也能搞定问题?实现上应该都会比 PHC 简单一些。(高博在SLAM论坛中也提到了发论文需要整花活儿哈哈[手动狗头])
------- 8月30日更新: -------
很有意思的是,在体素内嵌套八叉树并不是一个人的想法 —— 经评论区「阿飞同学」提醒(感谢),CMU 在 DAPRA地下挑战赛中的多传感器融合里程计方案 Super Odometry 正是应用了哈希表+八叉树的结构。下一篇,我们将尝试分析一下这个工作。