1. ArrayList

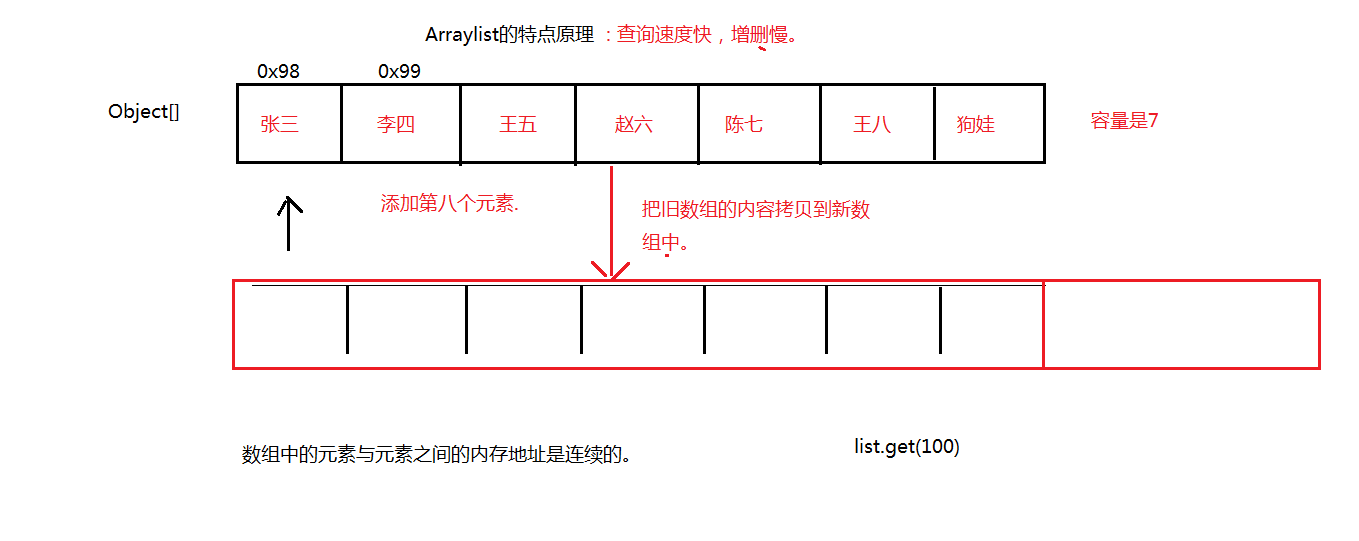
ArrayList的实现原理:数组实现, 查找快, 增删慢。
数组为什么是查询快?因为数组的内存空间地址是连续的.
ArrayList底层维护了一个Object[] 用于存储对象,默认数组的长度是10。可以通过 new ArrayList(20)显式的指定用于存储对象的数组的长度。
当默认的或者指定的容量不够存储对象的时候,容量自动增长为原来的容量的1.5倍。
由于ArrayList是数组实现, 在增和删的时候会牵扯到数组增容, 以及拷贝元素. 所以慢。数组是可以直接按索引查找, 所以查找时较快
可以考虑,假设向数组的0角标未知添加元素,那么原来的角标位置的元素需要整体往后移,并且数组可能还要增容,一旦增容,就需要要将老数组的内容拷贝到新数组中.所以数组的增删的效率是很低的.
练习:
去除ArrayList集合中重复元素: 存入字符串元素,存入自定义对象元素(如Perosn对象)
如何去做??循环遍历该集合,每取出一个放置在新的集合中,放置之前先判断新的集合是否以包含了新的元素。
import java.util.ArrayList;
public class test_1{
public static void main(String args[]) {
ArrayList arr = new ArrayList();
Person p1 = new Person("jack", 20);
Person p2 = new Person("rose", 18);
Person p3 = new Person("rose", 18);
arr.add(p1);
arr.add(p2);
arr.add(p3);
System.out.println(arr);
ArrayList arr2 = new ArrayList();
for (int i = 0; i < arr.size(); i++) {
Object obj = arr.get(i);
Person p = (Person) obj;
if (!(arr2.contains(p))) {
arr2.add(p);
}
}
System.out.println(arr2);
}
}
class Person {
private String name;
private int age;
public Person() {
}
public Person(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public int hashCode() {
return this.name.hashCode() + age * 37;
}
@Override
public boolean equals(Object obj) {
if (!(obj instanceof Person)) {
return false;
}
Person p = (Person) obj;
return this.name.equals(p.name) && this.age == p.age;
}
@Override
public String toString() {
return "Person@name:" + this.name + " age:" + this.age;
}
}思路:
存入人的对象.
1 先定义person 类
2 将该类的实例存入集合
3 将对象元素进行操作. 注意:自定义对象要进行复写toString 和 equals 方法.
为什么? 因为object 是person 的父类,object 中的toString 返回的是哈希值,object 类中equals
方法比较的是对象的地址值.
思路
1. 存入字符串对象
2. 存入自定义对象 如person
2. 创建容器,用于存储非重复元素
3 对原容器进行遍历,在遍历过程中进行判断遍历到的元素是否在容器中存在.(contains)
4 如果存在,就不存入,否则存入.
5 返回新容器
2. LinkedList
LinkedList:链表实现, 增删快, 查找慢由于LinkedList:在内存中的地址不连续,需要让上一个元素记住下一个元素.所以每个元素中保存的有下一个元素的位置.虽然也有角标,但是查找的时候,需要从头往下找,显然是没有数组查找快的.但是,链表在插入新元素的时候,只需要让前一个元素记住新元素,让新元素记住下一个元素就可以了.所以插入很快.
由于链表实现, 增加时只要让前一个元素记住自己就可以, 删除时让前一个元素记住后一个元素, 后一个元素记住前一个元素. 这样的增删效率较高。
但查询时需要一个一个的遍历, 所以效率较低。

.............//////

例子: 使用LinkedList集合去模拟出队列(先进先出) 或者堆栈(后进先出) 数据结构。
class StackList{
LinkedList list;
public StackList(){
list = new LinkedList();
}
//进栈
public void add(Object o){
list.push(o);
}
//弹栈 : 把元素删除并返回。
public Object pop(){
return list.pop();
}
//获取元素个数
public int size(){
return list.size();
}
}
//使用LinkedList模拟队列的存储方式
class TeamList{
LinkedList list;
public TeamList(){
list = new LinkedList();
}
public void add(Object o){
list.offer(o);
}
public Object remove(){
return list.poll();
}
//获取元素个数
public int size(){
return list.size();
}
}
public class test_1 {
public static void main(String[] args) {
TeamList list= new TeamList();
list.add("李嘉诚");
list.add("马云");
list.add("王健林");
int size = list.size();
for(int i = 0 ; i<size ; i++){
System.out.println(list.remove());
}
}
}

ArrayList 和 LinkedList的存储查找的优缺点:
1、ArrayList 是采用动态数组来存储元素的,它允许直接用下标号来直接查找对应的元素。但是,但是插入元素要涉及数组元素移动及内存的操作。总结:查找速度快,插入操作慢。
2、LinkedList 是采用双向链表实现存储,按序号索引数据需要进行前向或后向遍历,但是插入数据时只需要记录本项的前后项即可,所以插入速度较快。
3. Vector
Vector: 描述的是一个线程安全的ArrayList。 多线程安全的,所以效率低
ArrayList: 单线程效率高。

public static void main(String[] args)
{
Vector v = new Vector();
v.addElement("aaa");
v.addElement("bbb");
v.addElement("ccc");
System.out.println( v );
System.out.println( v.elementAt(2) ); // ccc
// 遍历Vector遍历
Enumeration ens = v.elements();
while ( ens.hasMoreElements() )
{
System.out.println( ens.nextElement() );
}
}