0.参考
https://github.com/DormyMo/SpiderKeeper
1.Job Dashboard 页面添加 Stats 链接
python3.6/site-packages/SpiderKeeper/app/templates/job_dashboard.html
搜索 /log 定位
1.1 添加 Stats 表格列
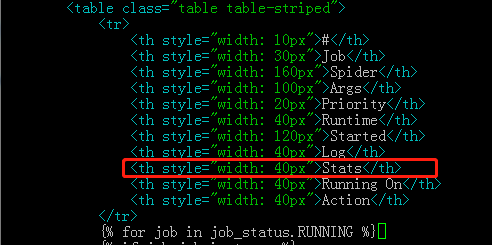
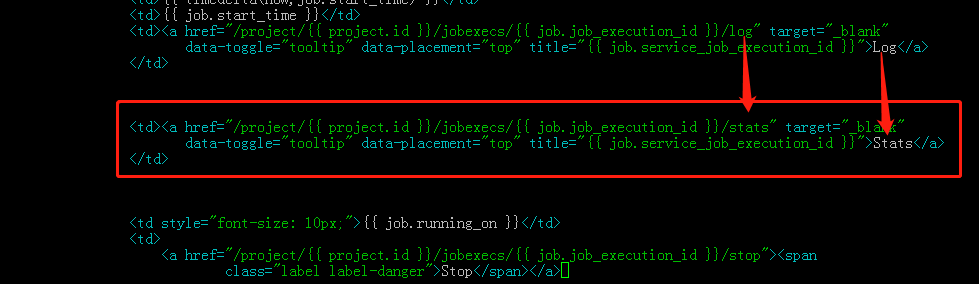
1.2 添加 Stats 链接
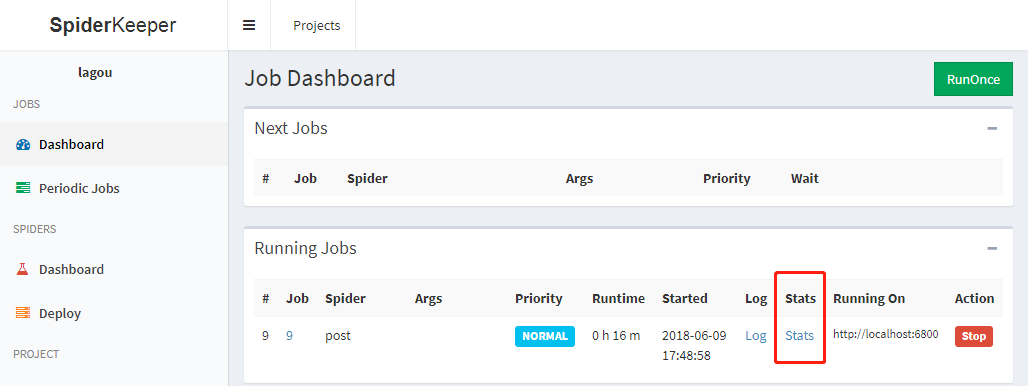
2. 页面效果
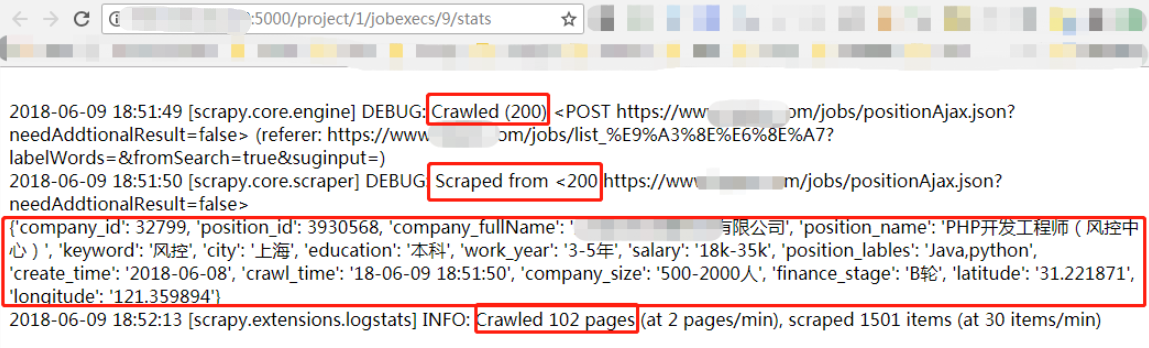
3. 过滤最新 log 信息
python3.6/site-packages/SpiderKeeper/app/spider/controller.py
本质上是通过 requests 请求 scrapyd 的 log 页面,再重新排版,注意 escape
搜索 /log 定位
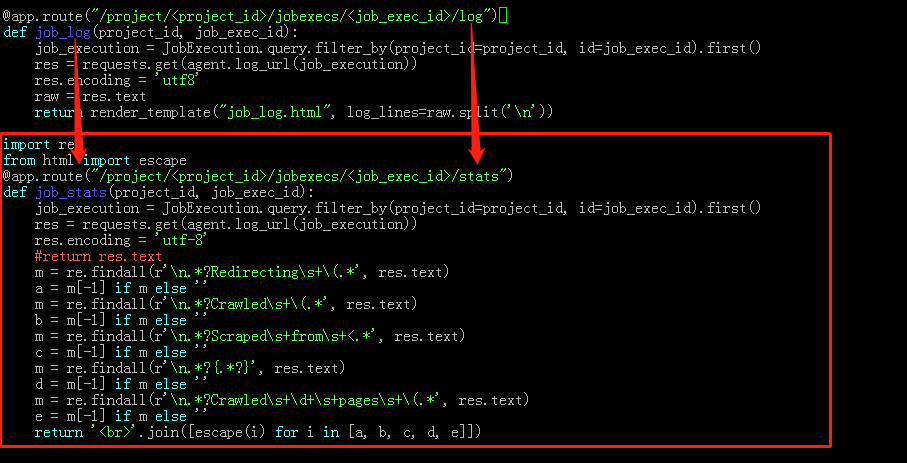
3.1 添加 python 代码
import re from html import escape @app.route("/project/<project_id>/jobexecs/<job_exec_id>/stats") def job_stats(project_id, job_exec_id): job_execution = JobExecution.query.filter_by(project_id=project_id, id=job_exec_id).first() res = requests.get(agent.log_url(job_execution)) res.encoding = 'utf-8' #return res.text m = re.findall(r'\n.*?Redirecting\s+\(.*', res.text) a = m[-1] if m else '' m = re.findall(r'\n.*?Crawled\s+\(.*', res.text) b = m[-1] if m else '' m = re.findall(r'\n.*?Scraped\s+from\s+<.*', res.text) c = m[-1] if m else '' m = re.findall(r'\n.*?{.*?}', res.text) d = m[-1] if m else '' m = re.findall(r'\n.*?Crawled\s+\d+\s+pages\s+\(.*', res.text) e = m[-1] if m else '' return '<br>'.join([escape(i) for i in [a, b, c, d, e]])
4. log 过滤结果