目录
-
前言
-
DPSS 方法概述
-
DeP 和 DDeP
- 基础网络结构
- 损失函数
- diffusion 的扩展
-
实验
-
总结
-
参考
本文首发于 GiantPandaCV,未经允许不得转载!!
前言
当前语义分割任务存在一个特别常见的问题是收集 groundtruth 的成本和耗时很高,所以会使用预训练。例如监督分类或自监督特征提取,通常用于训练模型 backbone。基于该问题,这篇文章介绍的方法被叫做 decoder denoising pretraining (DDeP),如下图所示。
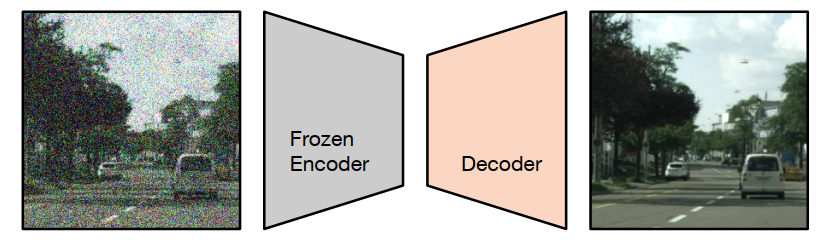
与标准的去噪自编码器类似,网络被训练用于对带有噪声的输入图像进行去噪。然而,编码器是使用监督学习进行预训练并冻结的,只有解码器的参数使用去噪目标进行优化。此外,当给定一个带有噪声的输入时,解码器被训练用于预测噪声,而不是直接预测干净图像,这也是比较常见的方式。
DPSS 方法概述
这次介绍的这篇文章叫做 Denoising Pretraining for Semantic Segmentation,为了方便,后文统一简写为 DPSS。DPSS 将基于 Transformer 的 U-Net 作为去噪自